 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Reliably Correct Errors in Low-Resource ASR? A Contamination-Aware Case Study on West Frisian
May 19, 2026Automatic speech recognition (ASR) has improved substantially in recent years, yet performance remains limited for low-resource languages. Large language models (LLMs) have shown promise for improving ASR through generative error correction (GER), but their effectiveness in low-resource settings remains underexplored. In addition, it remains unclear to what extent data contamination influences the reported improvements in LLM-based GER. This study investigates LLM-based GER for low-resource Frisian. In addition to a public corpus, we construct and use a Frisian offline dataset with non-public texts for evaluation to control for potential data contamination. Results show that GER improves ASR performance in most settings, with the best GPT-5.1 results surpassing oracle WERs. Comparable gains on the offline dataset indicate that improvements reflect true correction ability. We further provide a detailed error analysis revealing model correction patterns.
Evaluating Standard and Dialectal Frisian ASR: Multilingual Fine-tuning and Language Identification for Improved Low-resource Performance
Feb 07, 2025



Automatic Speech Recognition (ASR) performance for low-resource languages is still far behind that of higher-resource languages such as English, due to a lack of sufficient labeled data. State-of-the-art methods deploy self-supervised transfer learning where a model pre-trained on large amounts of data is fine-tuned using little labeled data in a target low-resource language. In this paper, we present and examine a method for fine-tuning an SSL-based model in order to improve the performance for Frisian and its regional dialects (Clay Frisian, Wood Frisian, and South Frisian). We show that Frisian ASR performance can be improved by using multilingual (Frisian, Dutch, English and German) fine-tuning data and an auxiliary language identification task. In addition, our findings show that performance on dialectal speech suffers substantially, and, importantly, that this effect is moderated by the elicitation approach used to collect the dialectal data. Our findings also particularly suggest that relying solely on standard language data for ASR evaluation may underestimate real-world performance, particularly in languages with substantial dialectal variation.
An explainable approach to detect case law on housing and eviction issues within the HUDOC database
Oct 03, 2024



Case law is instrumental in shaping our understanding of human rights, including the right to adequate housing. The HUDOC database provides access to the textual content of case law from the European Court of Human Rights (ECtHR), along with some metadata. While this metadata includes valuable information, such as the application number and the articles addressed in a case, it often lacks detailed substantive insights, such as the specific issues a case covers. This underscores the need for detailed analysis to extract such information. However, given the size of the database - containing over 40,000 cases - an automated solution is essential. In this study, we focus on the right to adequate housing and aim to build models to detect cases related to housing and eviction issues. Our experiments show that the resulting models not only provide performance comparable to more sophisticated approaches but are also interpretable, offering explanations for their decisions by highlighting the most influential words. The application of these models led to the identification of new cases that were initially overlooked during data collection. This suggests that NLP approaches can be effectively applied to categorise case law based on the specific issues they address.
Quantifying the effect of speech pathology on automatic and human speaker verification
Jun 10, 2024



This study investigates how surgical intervention for speech pathology (specifically, as a result of oral cancer surgery) impacts the performance of an automatic speaker verification (ASV) system. Using two recently collected Dutch datasets with parallel pre and post-surgery audio from the same speaker, NKI-OC-VC and SPOKE, we assess the extent to which speech pathology influences ASV performance, and whether objective/subjective measures of speech severity are correlated with the performance. Finally, we carry out a perceptual study to compare judgements of ASV and human listeners. Our findings reveal that pathological speech negatively affects ASV performance, and the severity of the speech is negatively correlated with the performance. There is a moderate agreement in perceptual and objective scores of speaker similarity and severity, however, we could not clearly establish in the perceptual study, whether the same phenomenon also exists in human perception.
DUMB: A Benchmark for Smart Evaluation of Dutch Models
May 22, 2023



We introduce the Dutch Model Benchmark: DUMB. The benchmark includes a diverse set of datasets for low-, medium- and high-resource tasks. The total set of eight tasks include three tasks that were previously not available in Dutch. Instead of relying on a mean score across tasks, we propose Relative Error Reduction (RER), which compares the DUMB performance of models to a strong baseline which can be referred to in the future even when assessing different sets of models. Through a comparison of 14 pre-trained models (mono- and multi-lingual, of varying sizes), we assess the internal consistency of the benchmark tasks, as well as the factors that likely enable high performance. Our results indicate that current Dutch monolingual models under-perform and suggest training larger Dutch models with other architectures and pre-training objectives. At present, the highest performance is achieved by DeBERTaV3 (large), XLM-R (large) and mDeBERTaV3 (base). In addition to highlighting best strategies for training larger Dutch models, DUMB will foster further research on Dutch. A public leaderboard is available at https://dumbench.nl.
Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation
May 19, 2023



The performance of automatic speech recognition (ASR) systems has advanced substantially in recent years, particularly for languages for which a large amount of transcribed speech is available. Unfortunately, for low-resource languages, such as minority languages, regional languages or dialects, ASR performance generally remains much lower. In this study, we investigate whether data augmentation techniques could help improve low-resource ASR performance, focusing on four typologically diverse minority languages or language variants (West Germanic: Gronings, West-Frisian; Malayo-Polynesian: Besemah, Nasal). For all four languages, we examine the use of self-training, where an ASR system trained with the available human-transcribed data is used to generate transcriptions, which are then combined with the original data to train a new ASR system. For Gronings, for which there was a pre-existing text-to-speech (TTS) system available, we also examined the use of TTS to generate ASR training data from text-only sources. We find that using a self-training approach consistently yields improved performance (a relative WER reduction up to 20.5% compared to using an ASR system trained on 24 minutes of manually transcribed speech). The performance gain from TTS augmentation for Gronings was even stronger (up to 25.5% relative reduction in WER compared to a system based on 24 minutes of manually transcribed speech). In sum, our results show the benefit of using self-training or (if possible) TTS-generated data as an efficient solution to overcome the limitations of data availability for resource-scarce languages in order to improve ASR performance.
Preregistered protocol for: Articulatory changes in speech following treatment for oral or oropharyngeal cancer: a systematic review
Sep 14, 2022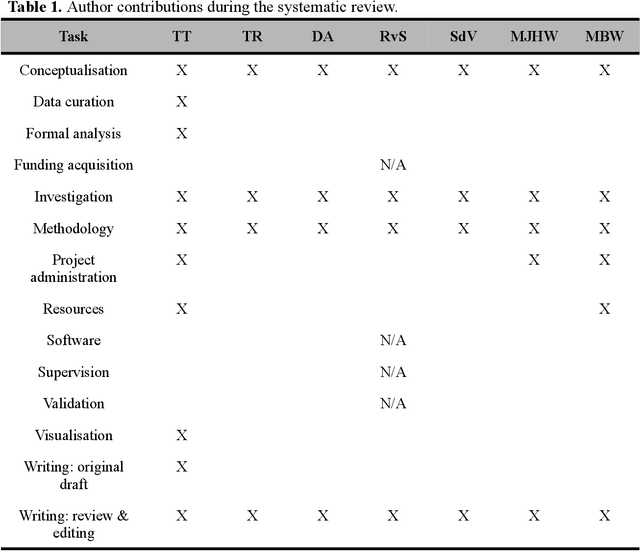


This document outlines a PROSPERO pre-registered protocol for a systematic review regarding articulatory changes in speech following oral or orophayrngeal cancer treatment. Treatment of tumours in the oral cavity may result in physiological changes that could lead to articulatory difficulties. The tongue becomes less mobile due to scar tissue and/or potential (postoperative) radiation therapy. Moreover, tissue loss may create a bypass for airflow or limit constriction possibilities. In order to gain a better understanding of the nature of the speech problems, information regarding the movement of the articulators is needed since perceptual or acoustic information provide only indirect evidence of articulatory changes. Therefore, this systematic review will review studies that directly measured the articulatory movements of the tongue, jaw, and lips following treatment for oral or oropharyngeal cancer.
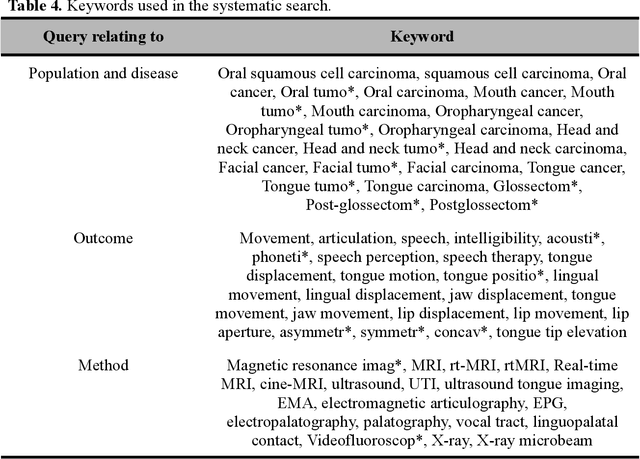
Quantifying Language Variation Acoustically with Few Resources
May 05, 2022
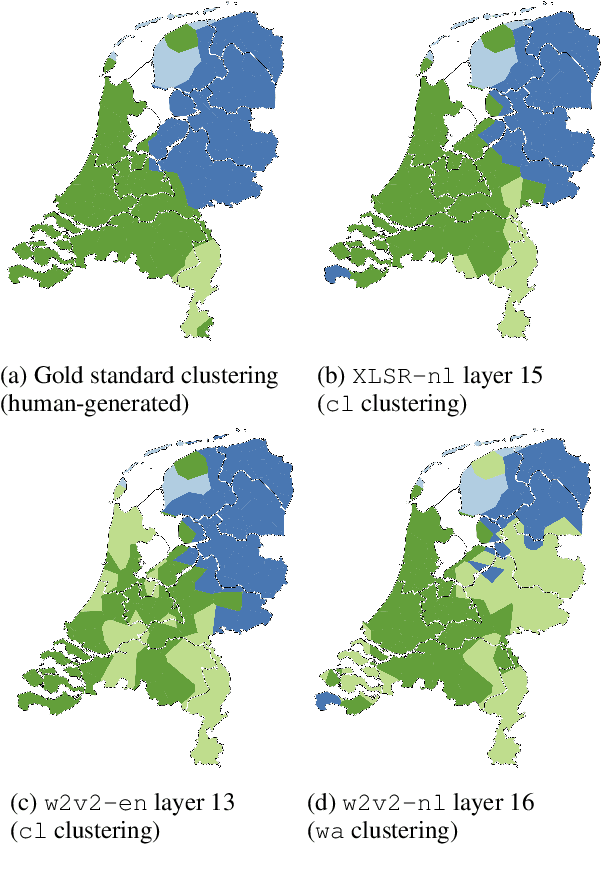
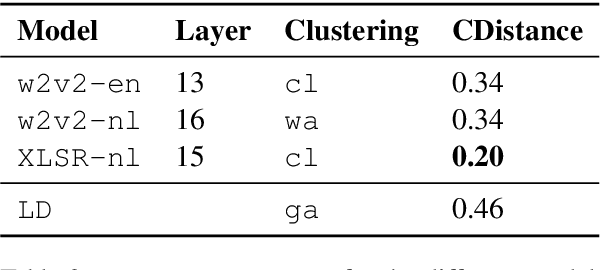
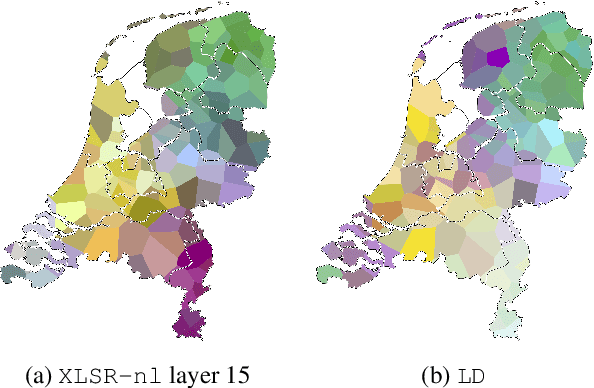
Deep acoustic models represent linguistic information based on massive amounts of data. Unfortunately, for regional languages and dialects such resources are mostly not available. However, deep acoustic models might have learned linguistic information that transfers to low-resource languages. In this study, we evaluate whether this is the case through the task of distinguishing low-resource (Dutch) regional varieties. By extracting embeddings from the hidden layers of various wav2vec 2.0 models (including new models which are pre-trained and/or fine-tuned on Dutch) and using dynamic time warping, we compute pairwise pronunciation differences averaged over 10 words for over 100 individual dialects from four (regional) languages. We then cluster the resulting difference matrix in four groups and compare these to a gold standard, and a partitioning on the basis of comparing phonetic transcriptions. Our results show that acoustic models outperform the (traditional) transcription-based approach without requiring phonetic transcriptions, with the best performance achieved by the multilingual XLSR-53 model fine-tuned on Dutch. On the basis of only six seconds of speech, the resulting clustering closely matches the gold standard.
Manipulation of oral cancer speech using neural articulatory synthesis
Mar 31, 2022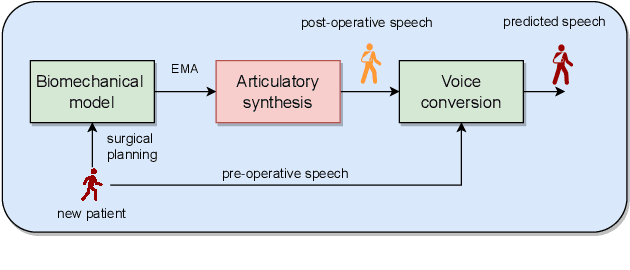
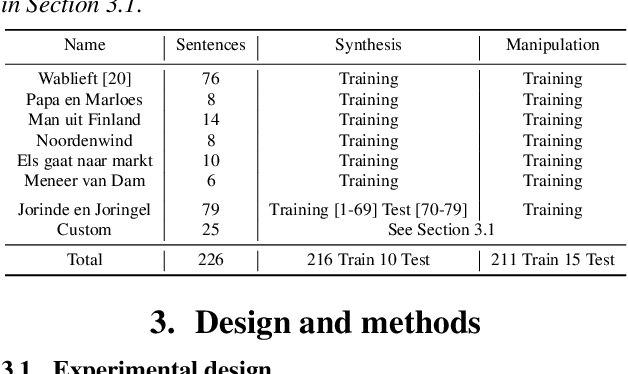
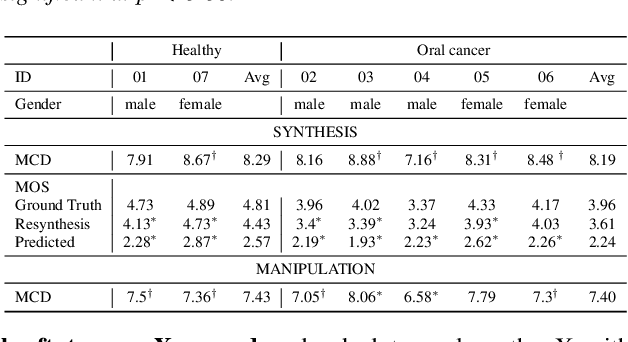
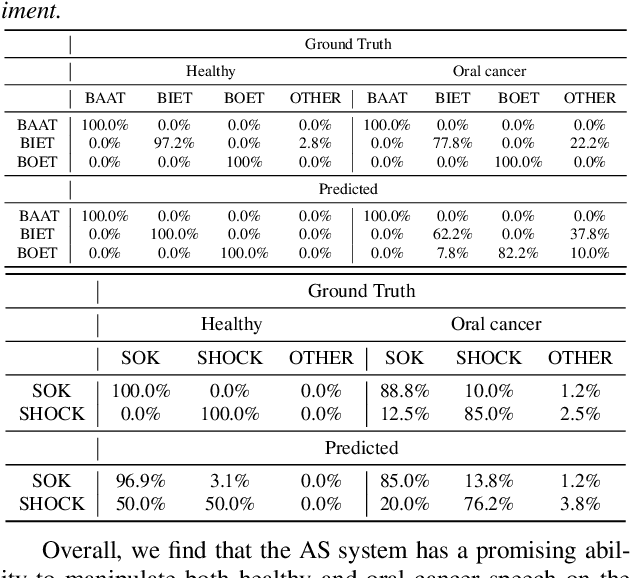
We present an articulatory synthesis framework for the synthesis and manipulation of oral cancer speech for clinical decision making and alleviation of patient stress. Objective and subjective evaluations demonstrate that the framework has acceptable naturalness and is worth further investigation. A subsequent subjective vowel and consonant identification experiment showed that the articulatory synthesis system can manipulate the articulatory trajectories so that the synthesised speech reproduces problems present in the ground truth oral cancer speech.
Estimating the Level and Direction of Phonetic Dialect Change in the Northern Netherlands
Oct 15, 2021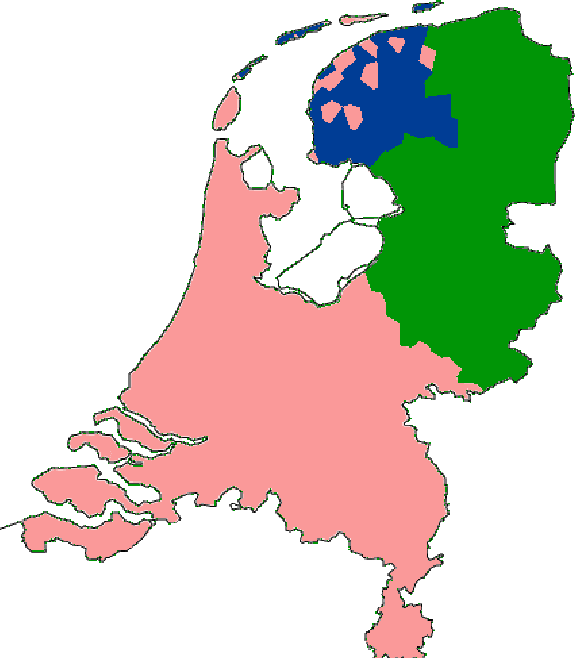

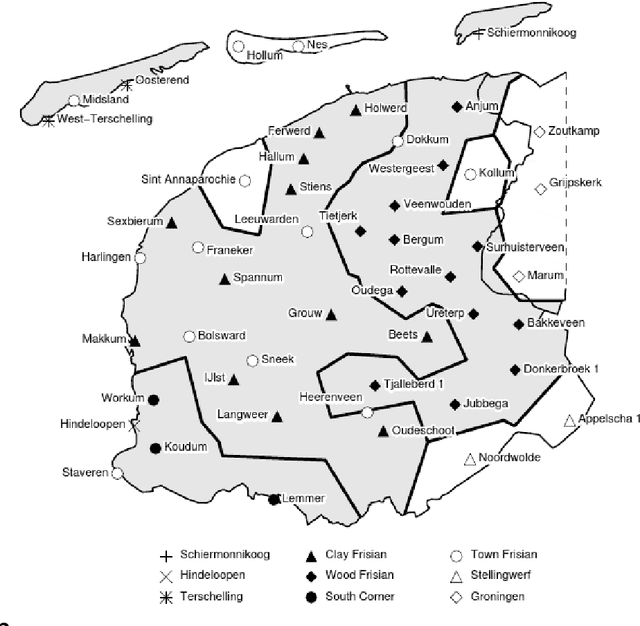

This article reports ongoing investigations into phonetic change of dialect groups in the northern Netherlandic language area, particularly the Frisian and Low Saxon dialect groups, which are known to differ in vitality. To achieve this, we combine existing phonetically transcribed corpora with dialectometric approaches that allow us to quantify change among older male dialect speakers in a real-time framework. A multidimensional variant of the Levenshtein distance, combined with methods that induce realistic phonetic distances between transcriptions, is used to estimate how much dialect groups have changed between 1990 and 2010, and whether they changed towards Standard Dutch or away from it. Our analyses indicate that language change is a slow process in this geographical area. Moreover, the Frisian and Groningen dialect groups seem to be most stable, while the other Low Saxon varieties (excluding the Groningen dialect group) were shown to be most prone to change. We offer possible explanations for our findings, while we discuss shortcomings of the data and approach in detail, as well as desiderata for future research.