 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gaussian Comparison Theorem for Training Dynamics in Machine Learning
Mar 10, 2026We study training algorithms with data following a Gaussian mixture model. For a specific family of such algorithms, we present a non-asymptotic result, connecting the evolution of the model to a surrogate dynamical system, which can be easier to analyze. The proof of our result is based on the celebrated Gordon comparison theorem. Using our theorem, we rigorously prove the validity of the dynamic mean-field (DMF) expressions in the asymptotic scenarios. Moreover, we suggest an iterative refinement scheme to obtain more accurate expressions in non-asymptotic scenarios. We specialize our theory to the analysis of training a perceptron model with a generic first-order (full-batch) algorithm and demonstrate that fluctuation parameters in a non-asymptotic domain emerge in addition to the DMF kernels.
Full-Duplex Millimeter Wave MIMO Channel Estimation: A Neural Network Approach
Feb 06, 2024



Millimeter wave (mmWave) multiple-input-multi-output (MIMO) is now a reality with great potential for further improvement. We study full-duplex transmissions as an effective way to improve mmWave MIMO systems. Compared to half-duplex systems, full-duplex transmissions may offer higher data rates and lower latency. However, full-duplex transmission is hindered by self-interference (SI) at the receive antennas, and SI channel estimation becomes a crucial step to make the full-duplex systems feasible. In this paper, we address the problem of channel estimation in full-duplex mmWave MIMO systems using neural networks (NNs). Our approach involves sharing pilot resources between user equipments (UEs) and transmit antennas at the base station (BS), aiming to reduce the pilot overhead in full-duplex systems and to achieve a comparable level to that of a half-duplex system. Additionally, in the case of separate antenna configurations in a full-duplex BS, providing channel estimates of transmit antenna (TX) arrays to the downlink UEs poses another challenge, as the TX arrays are not capable of receiving pilot signals. To address this, we employ an NN to map the channel from the downlink UEs to the receive antenna (RX) arrays to the channel from the TX arrays to the downlink UEs. We further elaborate on how NNs perform the estimation with different architectures, (e.g., different numbers of hidden layers), the introduction of non-linear distortion (e.g., with a 1-bit analog-to-digital converter (ADC)), and different channel conditions (e.g., low-correlated and high-correlated channels). Our work provides novel insights into NN-based channel estimators.
Precise Asymptotic Analysis of Deep Random Feature Models
Feb 13, 2023


We provide exact asymptotic expressions for the performance of regression by an $L-$layer deep random feature (RF) model, where the input is mapped through multiple random embedding and non-linear activation functions. For this purpose, we establish two key steps: First, we prove a novel universality result for RF models and deterministic data, by which we demonstrate that a deep random feature model is equivalent to a deep linear Gaussian model that matches it in the first and second moments, at each layer. Second, we make use of the convex Gaussian Min-Max theorem multiple times to obtain the exact behavior of deep RF models. We further characterize the variation of the eigendistribution in different layers of the equivalent Gaussian model, demonstrating that depth has a tangible effect on model performance despite the fact that only the last layer of the model is being trained.
FsaNet: Frequency Self-attention for Semantic Segmentation
Nov 28, 2022



Considering the spectral properties of images, we propose a new self-attention mechanism with highly reduced computational complexity, up to a linear rate. To better preserve edges while promoting similarity within objects, we propose individualized processes over different frequency bands. In particular, we study a case where the process is merely over low-frequency components. By ablation study, we show that low frequency self-attention can achieve very close or better performance relative to full frequency even without retraining the network. Accordingly, we design and embed novel plug-and-play modules to the head of a CNN network that we refer to as FsaNet. The frequency self-attention 1) takes low frequency coefficients as input, 2) can be mathematically equivalent to spatial domain self-attention with linear structures, 3) simplifies token mapping ($1\times1$ convolution) stage and token mixing stage simultaneously. We show that the frequency self-attention requires $87.29\% \sim 90.04\%$ less memory, $96.13\% \sim 98.07\%$ less FLOPs, and $97.56\% \sim 98.18\%$ in run time than the regular self-attention. Compared to other ResNet101-based self-attention networks, FsaNet achieves a new state-of-the-art result ($83.0\%$ mIoU) on Cityscape test dataset and competitive results on ADE20k and VOCaug.
Fast OT for Latent Domain Adaptation
Oct 02, 2022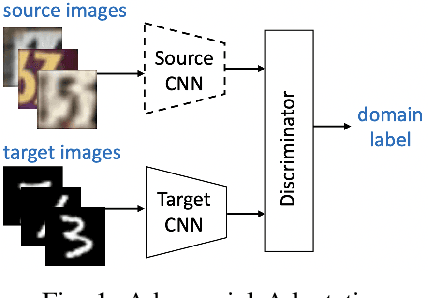
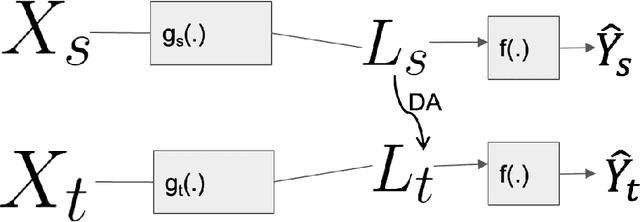
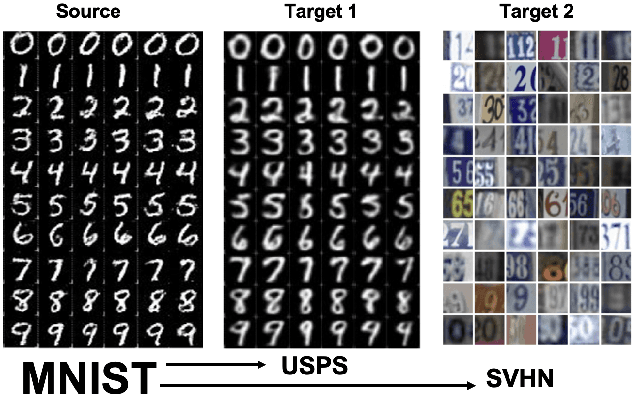
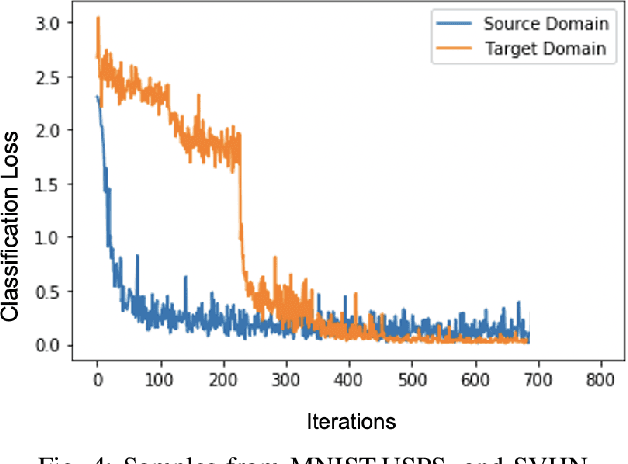
In this paper, we address the problem of unsupervised Domain Adaptation. The need for such an adaptation arises when the distribution of the target data differs from that which is used to develop the model and the ground truth information of the target data is unknown. We propose an algorithm that uses optimal transport theory with a verifiably efficient and implementable solution to learn the best latent feature representation. This is achieved by minimizing the cost of transporting the samples from the target domain to the distribution of the source domain.
Double Descent in Random Feature Models: Precise Asymptotic Analysis for General Convex Regularization
Apr 06, 2022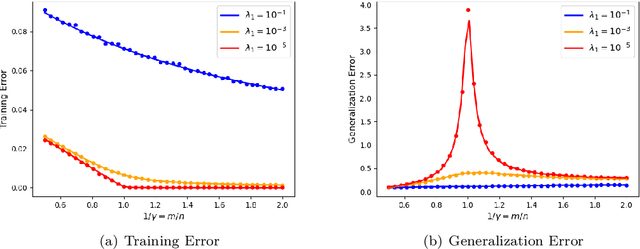
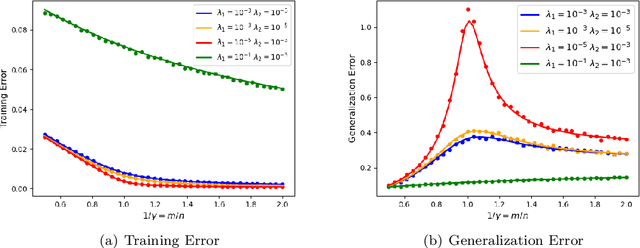
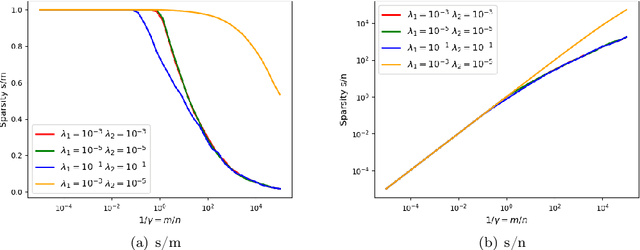
We prove rigorous results on the double descent phenomenon in random features (RF) model by employing the powerful Convex Gaussian Min-Max Theorem (CGMT) in a novel multi-level manner. Using this technique, we provide precise asymptotic expressions for the generalization of RF regression under a broad class of convex regularization terms including arbitrary separable functions. We further compute our results for the combination of $\ell_1$ and $\ell_2$ regularization case, known as elastic net, and present numerical studies about it. We numerically demonstrate the predictive capacity of our framework, and show experimentally that the predicted test error is accurate even in the non-asymptotic regime.
Robust Group Subspace Recovery: A New Approach for Multi-Modality Data Fusion
Jun 18, 2020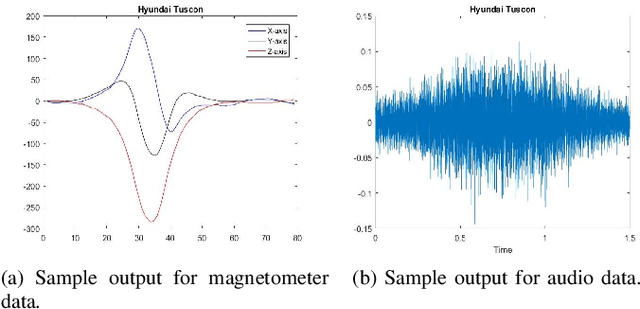
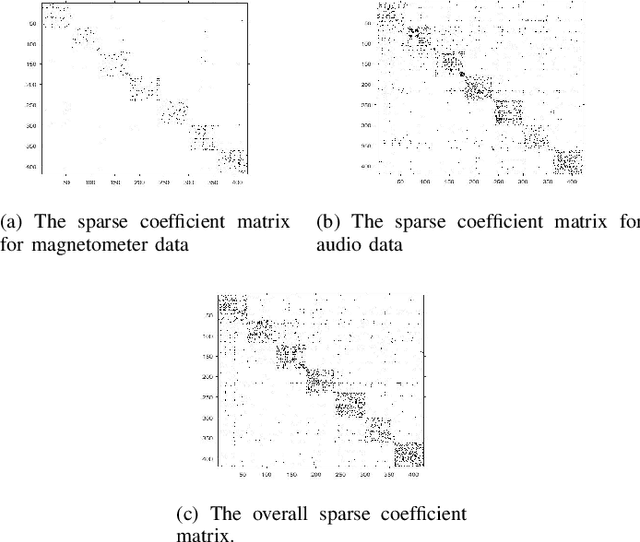
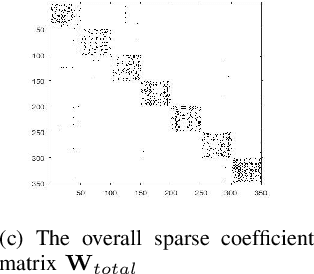
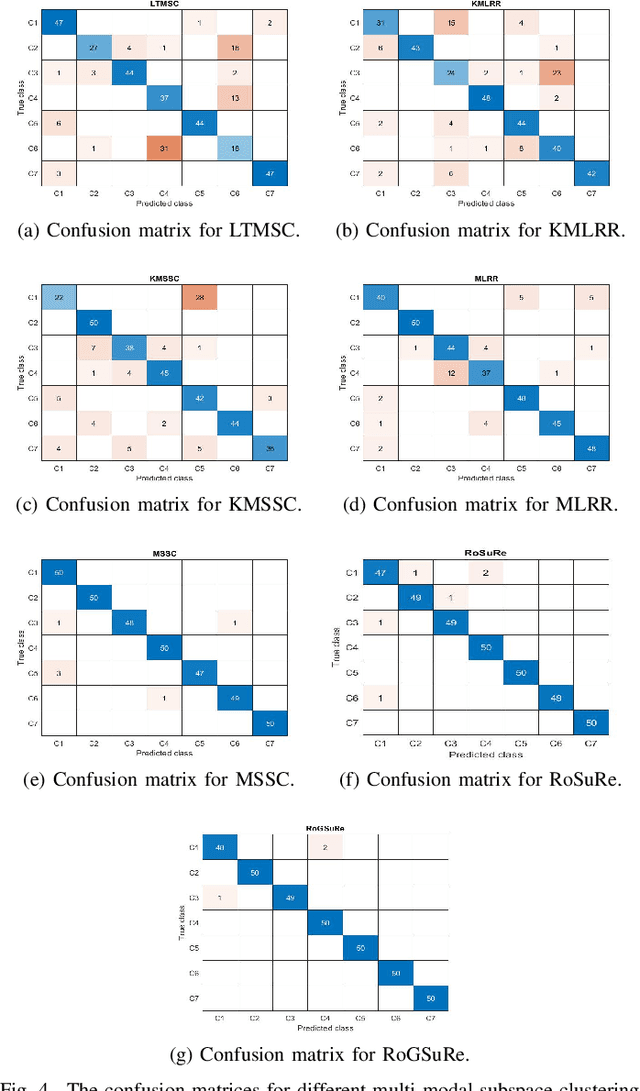
Robust Subspace Recovery (RoSuRe) algorithm was recently introduced as a principled and numerically efficient algorithm that unfolds underlying Unions of Subspaces (UoS) structure, present in the data. The union of Subspaces (UoS) is capable of identifying more complex trends in data sets than simple linear models. We build on and extend RoSuRe to prospect the structure of different data modalities individually. We propose a novel multi-modal data fusion approach based on group sparsity which we refer to as Robust Group Subspace Recovery (RoGSuRe). Relying on a bi-sparsity pursuit paradigm and non-smooth optimization techniques, the introduced framework learns a new joint representation of the time series from different data modalities, respecting an underlying UoS model. We subsequently integrate the obtained structures to form a unified subspace structure. The proposed approach exploits the structural dependencies between the different modalities data to cluster the associated target objects. The resulting fusion of the unlabeled sensors' data from experiments on audio and magnetic data has shown that our method is competitive with other state of the art subspace clustering methods. The resulting UoS structure is employed to classify newly observed data points, highlighting the abstraction capacity of the proposed method.
On the Unreasonable Effectiveness of Knowledge Distillation: Analysis in the Kernel Regime
Mar 30, 2020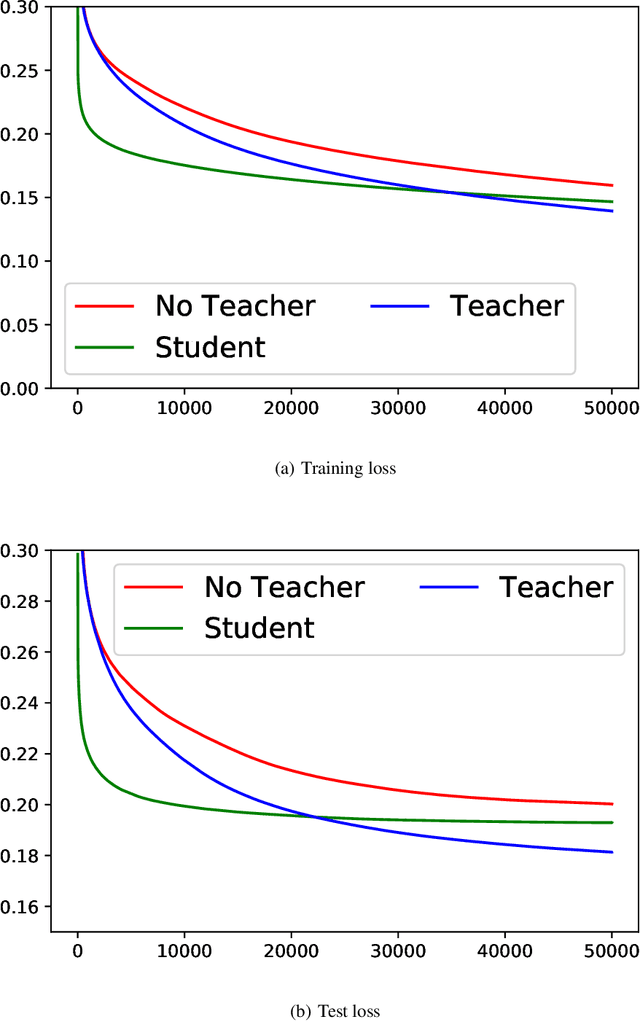
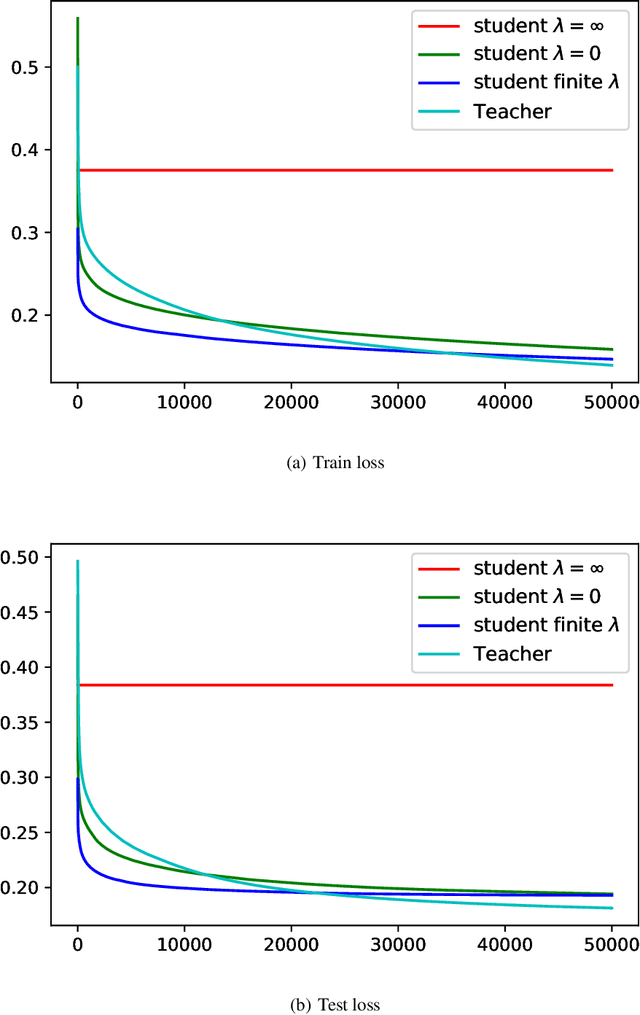
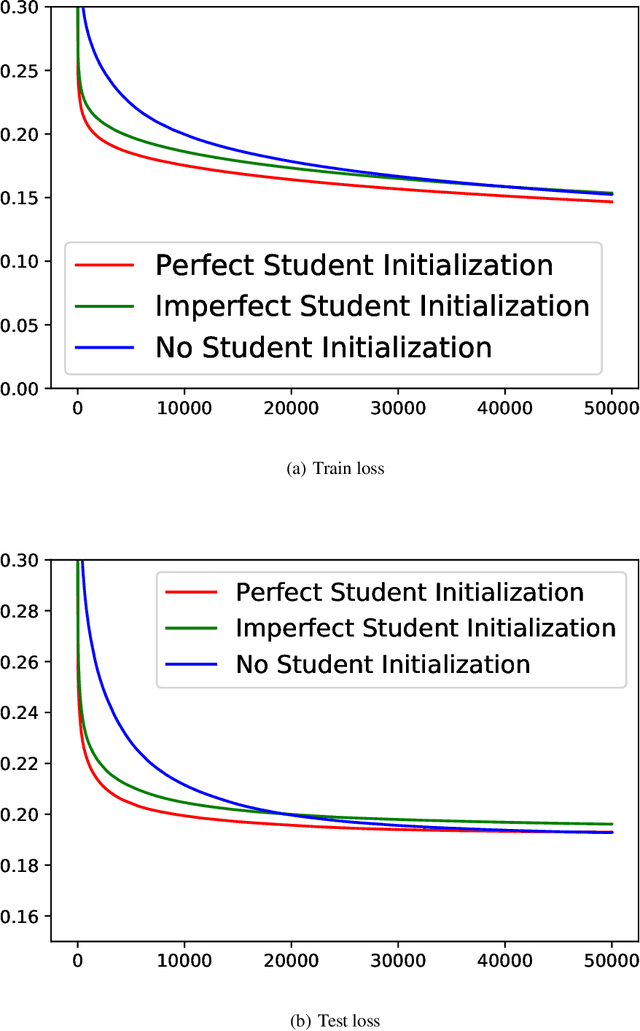
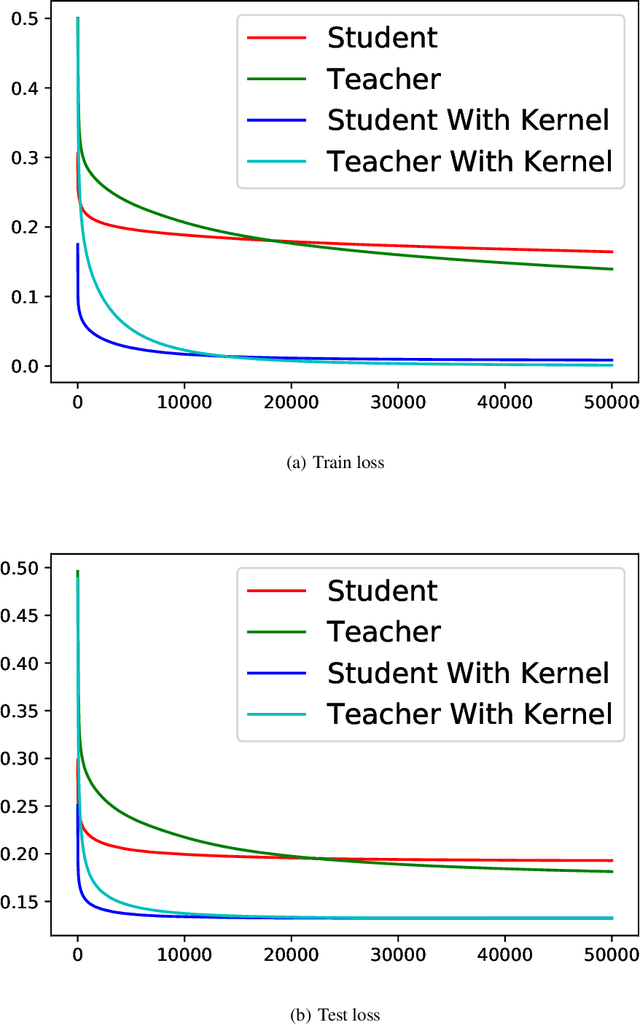
Knowledge distillation (KD), i.e. one classifier being trained on the outputs of another classifier, is an empirically very successful technique for knowledge transfer between classifiers. It has even been observed that classifiers learn much faster and more reliably if trained with the outputs of another classifier as soft labels, instead of from ground truth data. However, there has been little or no theoretical analysis of this phenomenon. We provide the first theoretical analysis of KD in the setting of extremely wide two layer non-linear networks in model and regime in (Arora et al., 2019; Du & Hu, 2019; Cao & Gu, 2019). We prove results on what the student network learns and on the rate of convergence for the student network. Intriguingly, we also confirm the lottery ticket hypothesis (Frankle & Carbin, 2019) in this model. To prove our results, we extend the repertoire of techniques from linear systems dynamics. We give corresponding experimental analysis that validates the theoretical results and yields additional insights.
Deep Adversarial Belief Networks
Sep 25, 2019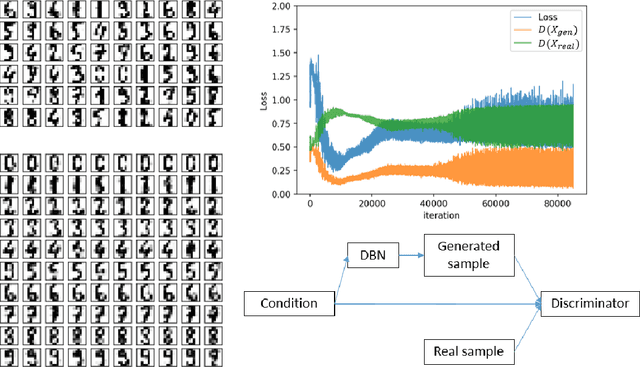

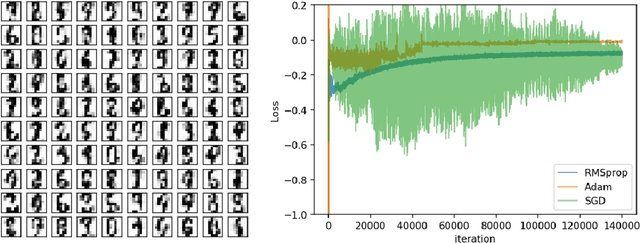
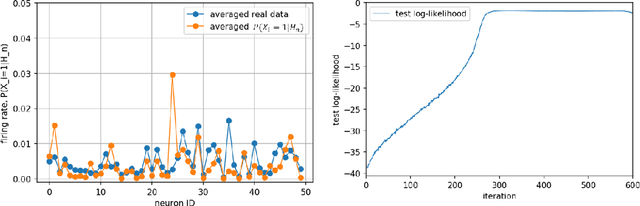
We present a novel adversarial framework for training deep belief networks (DBNs), which includes replacing the generator network in the methodology of generative adversarial networks (GANs) with a DBN and developing a highly parallelizable numerical algorithm for training the resulting architecture in a stochastic manner. Unlike the existing techniques, this framework can be applied to the most general form of DBNs with no requirement for back propagation. As such, it lays a new foundation for developing DBNs on a par with GANs with various regularization units, such as pooling and normalization. Foregoing back-propagation, our framework also exhibits superior scalability as compared to other DBN and GAN learning techniques. We present a number of numerical experiments in computer vision as well as neurosciences to illustrate the main advantages of our approach.
Community Detection and Improved Detectability in Multiplex Networks
Sep 23, 2019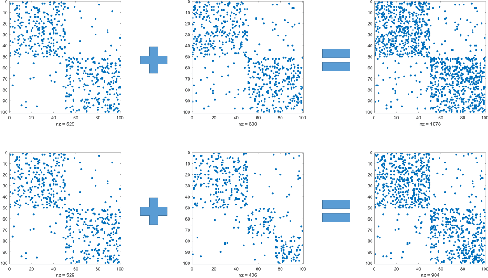
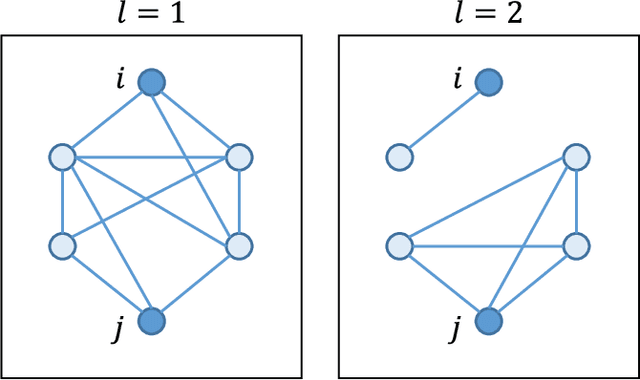
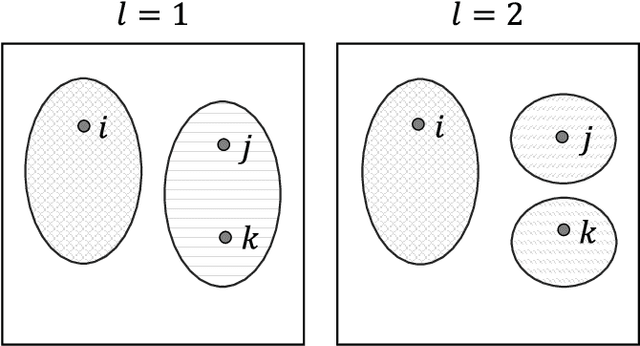
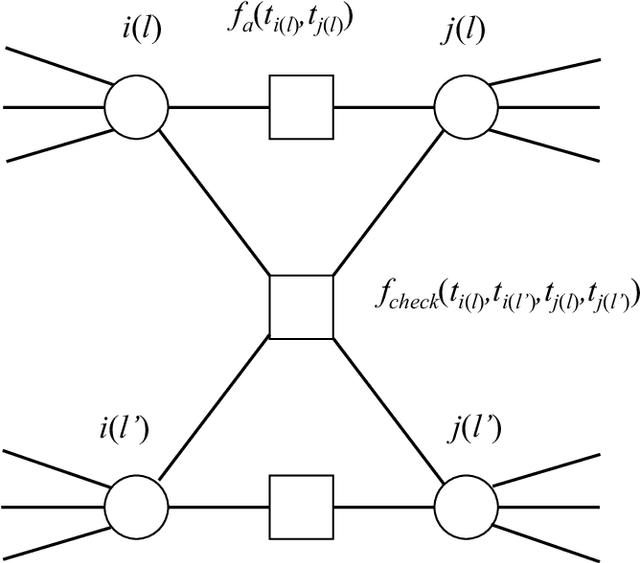
We investigate the widely encountered problem of detecting communities in multiplex networks, such as social networks, with an unknown arbitrary heterogeneous structure. To improve detectability, we propose a generative model that leverages the multiplicity of a single community in multiple layers, with no prior assumption on the relation of communities among different layers. Our model relies on a novel idea of incorporating a large set of generic localized community label constraints across the layers, in conjunction with the celebrated Stochastic Block Model (SBM) in each layer. Accordingly, we build a probabilistic graphical model over the entire multiplex network by treating the constraints as Bayesian priors. We mathematically prove that these constraints/priors promote existence of identical communities across layers without introducing further correlation between individual communities. The constraints are further tailored to render a sparse graphical model and the numerically efficient Belief Propagation algorithm is subsequently employed. We further demonstrate by numerical experiments that in the presence of consistent communities between different layers, consistent communities are matched, and the detectability is improved over a single layer. We compare our model with a "correlated model" which exploits the prior knowledge of community correlation between layers. Similar detectability improvement is obtained under such a correlation, even though our model relies on much milder assumptions than the correlated model. Our model even shows a better detection performance over a certain correlation and signal to noise ratio (SNR) range. In the absence of community correlation, the correlation model naturally fails, while ours maintains its performance.