 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Clean Text and Full-Body Transformer: Microsoft's Submission to the WMT22 Shared Task on Sign Language Translation
Oct 24, 2022
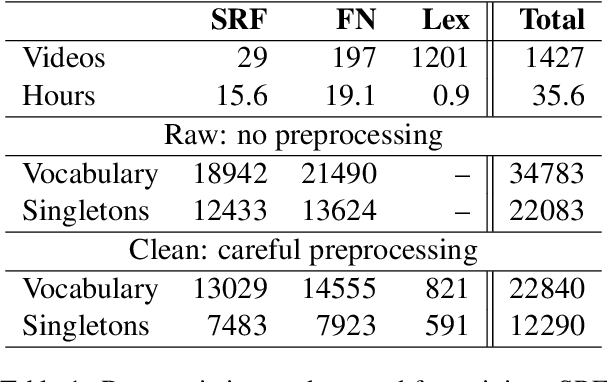

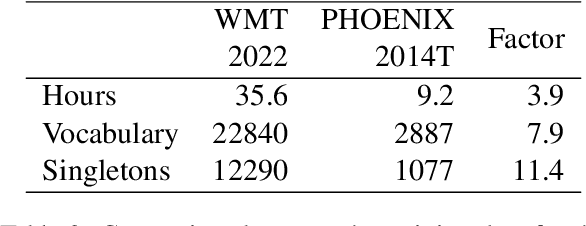
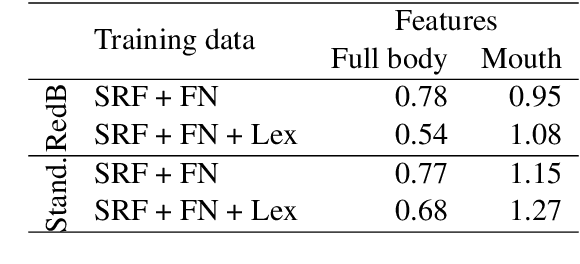
This paper describes Microsoft's submission to the first shared task on sign language translation at WMT 2022, a public competition tackling sign language to spoken language translation for Swiss German sign language. The task is very challenging due to data scarcity and an unprecedented vocabulary size of more than 20k words on the target side. Moreover, the data is taken from real broadcast news, includes native signing and covers scenarios of long videos. Motivated by recent advances in action recognition, we incorporate full body information by extracting features from a pre-trained I3D model and applying a standard transformer network. The accuracy of the system is further improved by applying careful data cleaning on the target text. We obtain BLEU scores of 0.6 and 0.78 on the test and dev set respectively, which is the best score among the participants of the shared task. Also in the human evaluation the submission reaches the first place. The BLEU score is further improved to 1.08 on the dev set by applying features extracted from a lip reading model.
Enhancing Label Consistency on Document-level Named Entity Recognition
Oct 24, 2022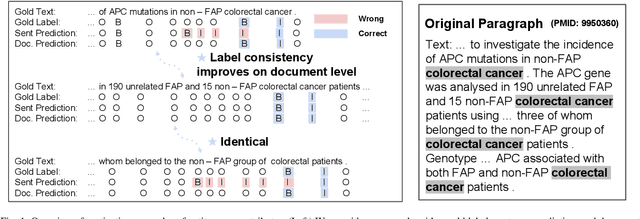
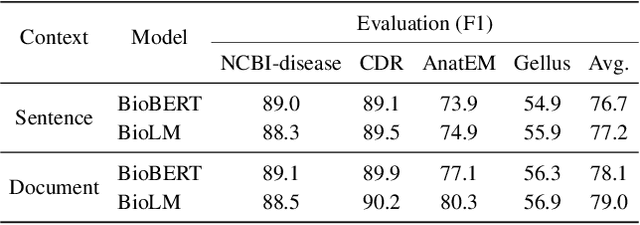
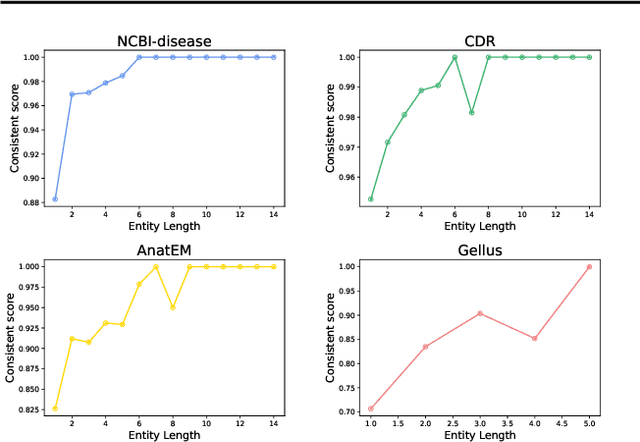
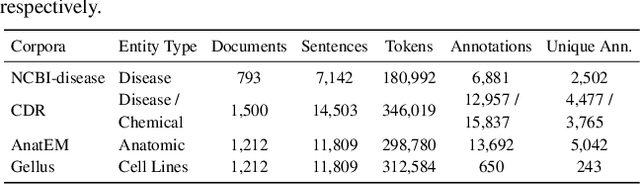
Named entity recognition (NER) is a fundamental part of extracting information from documents in biomedical applications. A notable advantage of NER is its consistency in extracting biomedical entities in a document context. Although existing document NER models show consistent predictions, they still do not meet our expectations. We investigated whether the adjectives and prepositions within an entity cause a low label consistency, which results in inconsistent predictions. In this paper, we present our method, ConNER, which enhances the label dependency of modifiers (e.g., adjectives and prepositions) to achieve higher label agreement. ConNER refines the draft labels of the modifiers to improve the output representations of biomedical entities. The effectiveness of our method is demonstrated on four popular biomedical NER datasets; in particular, its efficacy is proved on two datasets with 7.5-8.6% absolute improvements in the F1 score. We interpret that our ConNER method is effective on datasets that have intrinsically low label consistency. In the qualitative analysis, we demonstrate how our approach makes the NER model generate consistent predictions. Our code and resources are available at https://github.com/dmis-lab/ConNER/.
Visualizing the Obvious: A Concreteness-based Ensemble Model for Noun Property Prediction
Oct 24, 2022
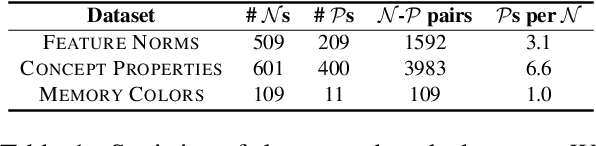


Neural language models encode rich knowledge about entities and their relationships which can be extracted from their representations using probing. Common properties of nouns (e.g., red strawberries, small ant) are, however, more challenging to extract compared to other types of knowledge because they are rarely explicitly stated in texts. We hypothesize this to mainly be the case for perceptual properties which are obvious to the participants in the communication. We propose to extract these properties from images and use them in an ensemble model, in order to complement the information that is extracted from language models. We consider perceptual properties to be more concrete than abstract properties (e.g., interesting, flawless). We propose to use the adjectives' concreteness score as a lever to calibrate the contribution of each source (text vs. images). We evaluate our ensemble model in a ranking task where the actual properties of a noun need to be ranked higher than other non-relevant properties. Our results show that the proposed combination of text and images greatly improves noun property prediction compared to powerful text-based language models.
* Findings of EMNLP 2022; The first two authors contributed equally
Semantic Image Segmentation with Deep Learning for Vine Leaf Phenotyping
Oct 24, 2022
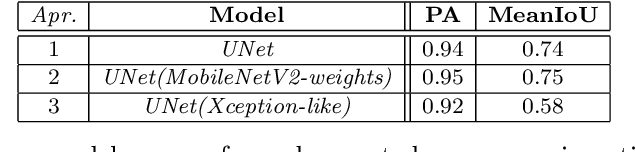
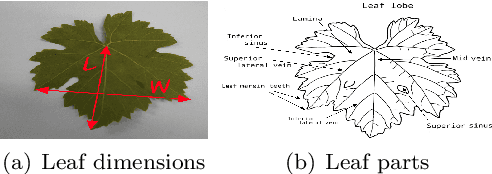
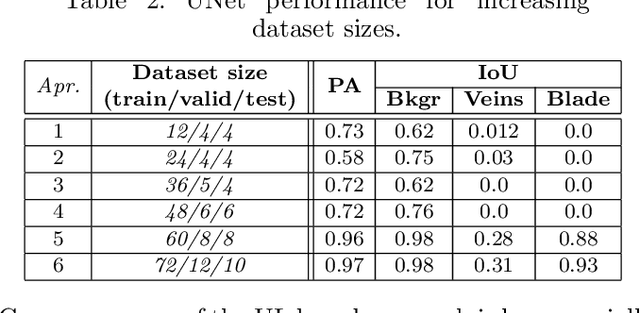
Plant phenotyping refers to a quantitative description of the plants properties, however in image-based phenotyping analysis, our focus is primarily on the plants anatomical, ontogenetical and physiological properties.This technique reinforced by the success of Deep Learning in the field of image based analysis is applicable to a wide range of research areas making high-throughput screens of plants possible, reducing the time and effort needed for phenotypic characterization.In this study, we use Deep Learning methods (supervised and unsupervised learning based approaches) to semantically segment grapevine leaves images in order to develop an automated object detection (through segmentation) system for leaf phenotyping which will yield information regarding their structure and function.In these directions we studied several deep learning approaches with promising results as well as we reported some future challenging tasks in the area of precision agriculture.Our work contributes to plant lifecycle monitoring through which dynamic traits such as growth and development can be captured and quantified, targeted intervention and selective application of agrochemicals and grapevine variety identification which are key prerequisites in sustainable agriculture.
Optimizing Crop Management with Reinforcement Learning and Imitation Learning
Sep 20, 2022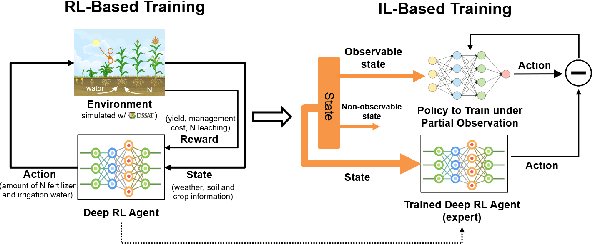
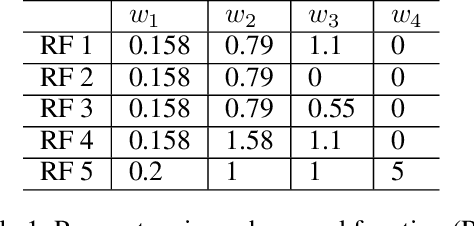
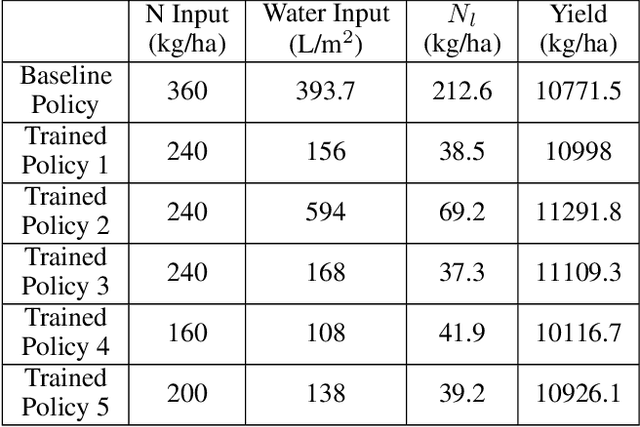
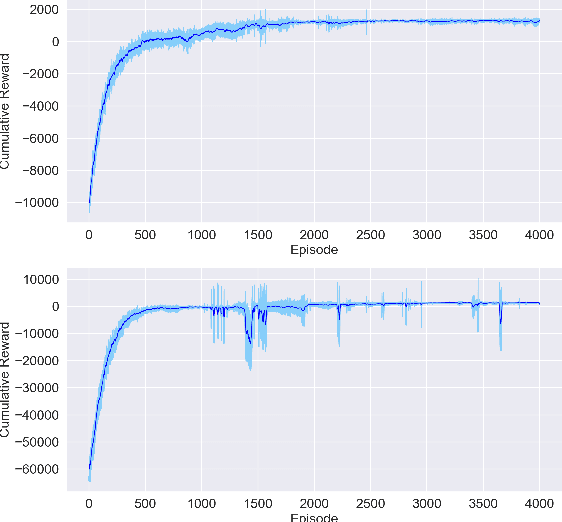
Crop management, including nitrogen (N) fertilization and irrigation management, has a significant impact on the crop yield, economic profit, and the environment. Although management guidelines exist, it is challenging to find the optimal management practices given a specific planting environment and a crop. Previous work used reinforcement learning (RL) and crop simulators to solve the problem, but the trained policies either have limited performance or are not deployable in the real world. In this paper, we present an intelligent crop management system which optimizes the N fertilization and irrigation simultaneously via RL, imitation learning (IL), and crop simulations using the Decision Support System for Agrotechnology Transfer (DSSAT). We first use deep RL, in particular, deep Q-network, to train management policies that require all state information from the simulator as observations (denoted as full observation). We then invoke IL to train management policies that only need a limited amount of state information that can be readily obtained in the real world (denoted as partial observation) by mimicking the actions of the previously RL-trained policies under full observation. We conduct experiments on a case study using maize in Florida and compare trained policies with a maize management guideline in simulations. Our trained policies under both full and partial observations achieve better outcomes, resulting in a higher profit or a similar profit with a smaller environmental impact. Moreover, the partial-observation management policies are directly deployable in the real world as they use readily available information.
Unifying the Discrete and Continuous Emotion labels for Speech Emotion Recognition
Oct 29, 2022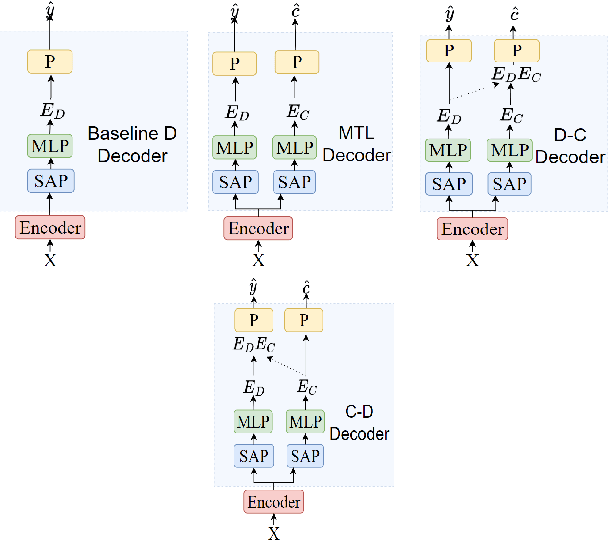
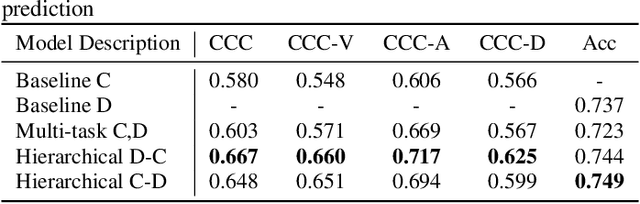
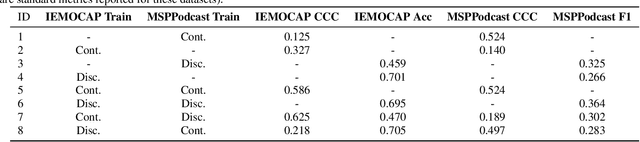
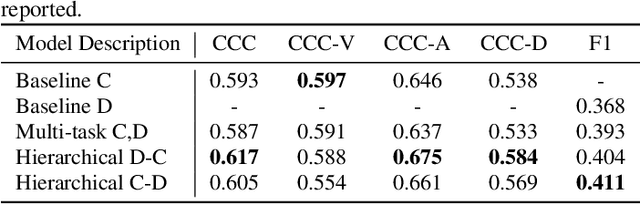
Traditionally, in paralinguistic analysis for emotion detection from speech, emotions have been identified with discrete or dimensional (continuous-valued) labels. Accordingly, models that have been proposed for emotion detection use one or the other of these label types. However, psychologists like Russell and Plutchik have proposed theories and models that unite these views, maintaining that these representations have shared and complementary information. This paper is an attempt to validate these viewpoints computationally. To this end, we propose a model to jointly predict continuous and discrete emotional attributes and show how the relationship between these can be utilized to improve the robustness and performance of emotion recognition tasks. Our approach comprises multi-task and hierarchical multi-task learning frameworks that jointly model the relationships between continuous-valued and discrete emotion labels. Experimental results on two widely used datasets (IEMOCAP and MSPPodcast) for speech-based emotion recognition show that our model results in statistically significant improvements in performance over strong baselines with non-unified approaches. We also demonstrate that using one type of label (discrete or continuous-valued) for training improves recognition performance in tasks that use the other type of label. Experimental results and reasoning for this approach (called the mismatched training approach) are also presented.
Structure-Preserving Spectral Reflectance Estimation using Guided Filtering
Sep 16, 2022

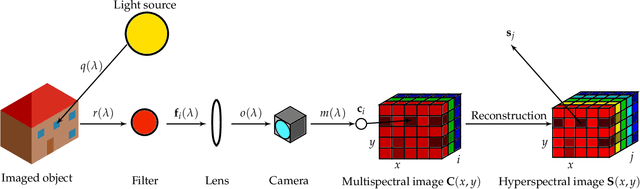
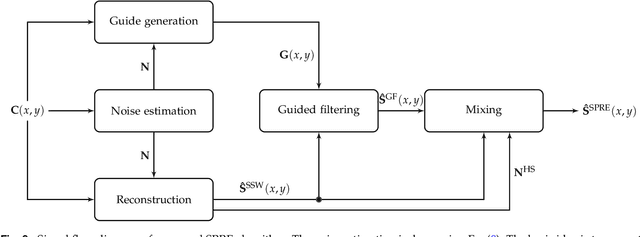
Light spectra are a very important source of information for diverse classification problems, e.g., for discrimination of materials. To lower the cost for acquiring this information, multispectral cameras are used. Several techniques exist for estimating light spectra out of multispectral images by exploiting properties about the spectrum. Unfortunately, especially when capturing multispectral videos, the images are heavily affected by noise due to the nature of limited exposure times in videos. Therefore, models that explicitly try to lower the influence of noise on the reconstructed spectrum are highly desirable. Hence, a novel reconstruction algorithm is presented. This novel estimation method is based on the guided filtering technique which preserves basic structures, while using spatial information to reduce the influence of noise. The evaluation based on spectra of natural images reveals that this new technique yields better quantitative and subjective results in noisy scenarios than other state-of-the-art spatial reconstruction methods. Specifically, the proposed algorithm lowers the mean squared error and the spectral angle up to 46% and 35% in noisy scenarios, respectively. Furthermore, it is shown that the proposed reconstruction technique works out-of-the-box and does not need any calibration or training by reconstructing spectra from a real-world multispectral camera with nine channels.
Very Low-Resolution Iris Recognition Via Eigen-Patch Super-Resolution and Matcher Fusion
Oct 18, 2022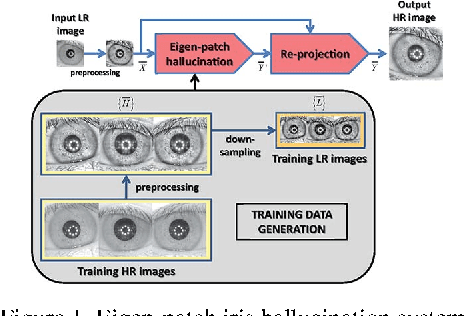
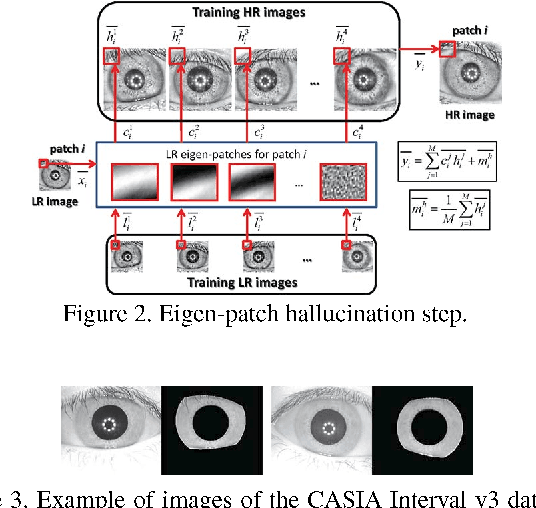
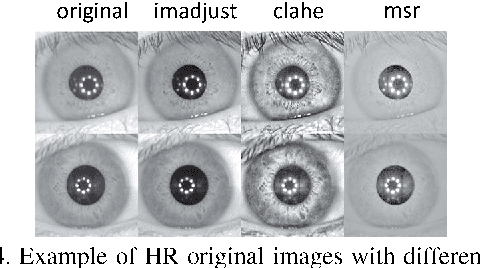
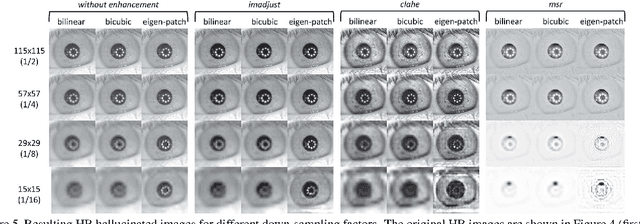
Current research in iris recognition is moving towards enabling more relaxed acquisition conditions. This has effects on the quality of acquired images, with low resolution being a predominant issue. Here, we evaluate a super-resolution algorithm used to reconstruct iris images based on Eigen-transformation of local image patches. Each patch is reconstructed separately, allowing better quality of enhanced images by preserving local information. Contrast enhancement is used to improve the reconstruction quality, while matcher fusion has been adopted to improve iris recognition performance. We validate the system using a database of 1,872 near-infrared iris images. The presented approach is superior to bilinear or bicubic interpolation, especially at lower resolutions, and the fusion of the two systems pushes the EER to below 5% for down-sampling factors up to a image size of only 13x13.
MODNet: Multi-offset Point Cloud Denoising Network Customized for Multi-scale Patches
Sep 01, 2022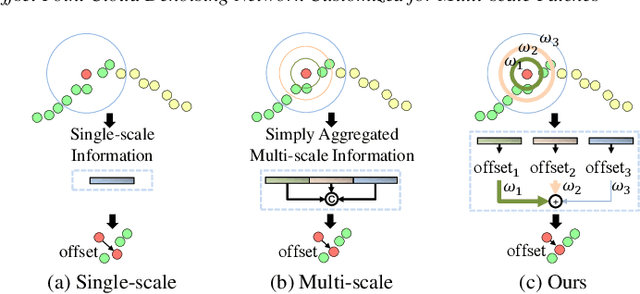
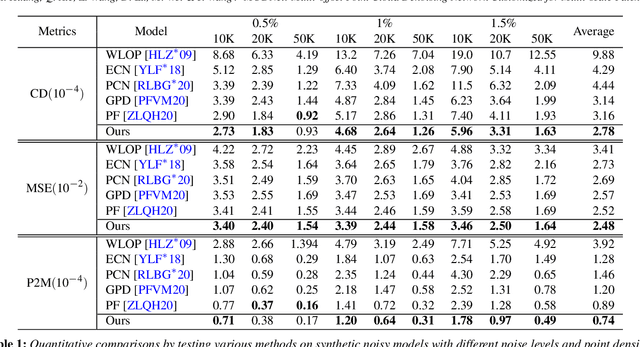
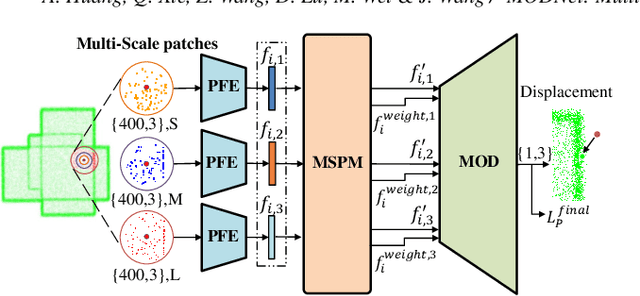
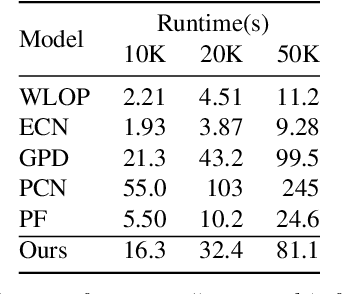
The intricacy of 3D surfaces often results cutting-edge point cloud denoising (PCD) models in surface degradation including remnant noise, wrongly-removed geometric details. Although using multi-scale patches to encode the geometry of a point has become the common wisdom in PCD, we find that simple aggregation of extracted multi-scale features can not adaptively utilize the appropriate scale information according to the geometric information around noisy points. It leads to surface degradation, especially for points close to edges and points on complex curved surfaces. We raise an intriguing question -- if employing multi-scale geometric perception information to guide the network to utilize multi-scale information, can eliminate the severe surface degradation problem? To answer it, we propose a Multi-offset Denoising Network (MODNet) customized for multi-scale patches. First, we extract the low-level feature of three scales patches by patch feature encoders. Second, a multi-scale perception module is designed to embed multi-scale geometric information for each scale feature and regress multi-scale weights to guide a multi-offset denoising displacement. Third, a multi-offset decoder regresses three scale offsets, which are guided by the multi-scale weights to predict the final displacement by weighting them adaptively. Experiments demonstrate that our method achieves new state-of-the-art performance on both synthetic and real-scanned datasets.
CycleFlow: Purify Information Factors by Cycle Loss
Oct 18, 2021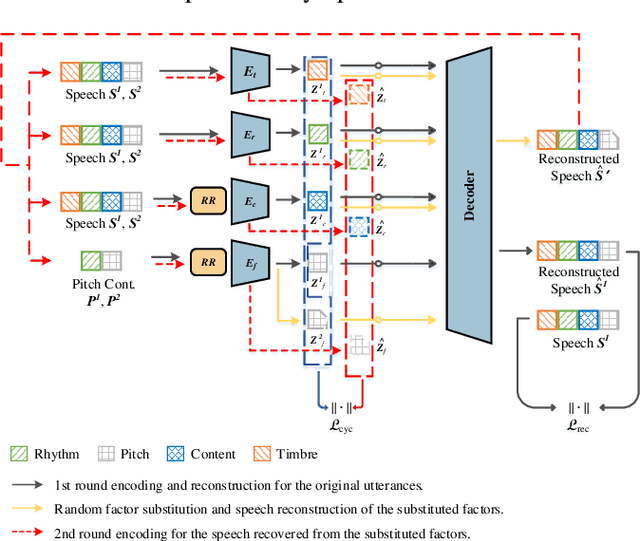
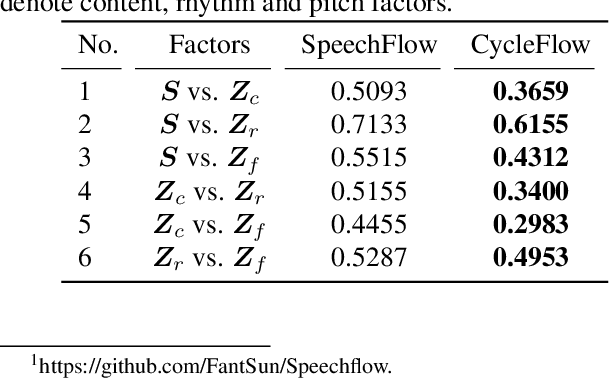
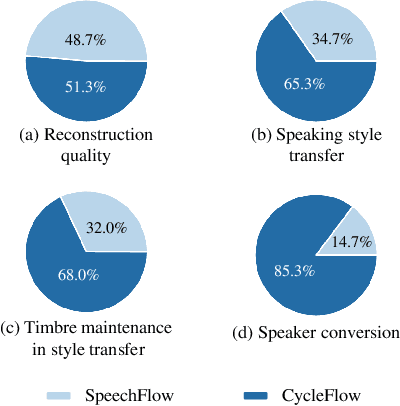
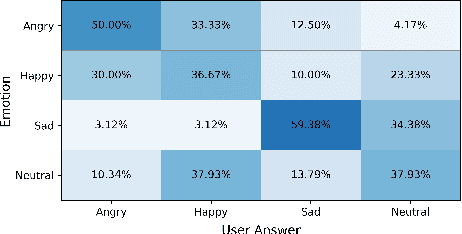
SpeechFlow is a powerful factorization model based on information bottleneck (IB), and its effectiveness has been reported by several studies. A potential problem of SpeechFlow, however, is that if the IB channels are not well designed, the resultant factors cannot be well disentangled. In this study, we propose a CycleFlow model that combines random factor substitution and cycle loss to solve this problem. Experiments on voice conversion tasks demonstrate that this simple technique can effectively reduce mutual information among individual factors, and produce clearly better conversion than the IB-based SpeechFlow. CycleFlow can also be used as a powerful tool for speech editing. We demonstrate this usage by an emotion perception experiment.