 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Elicitation Meets Clustering
Oct 03, 2021

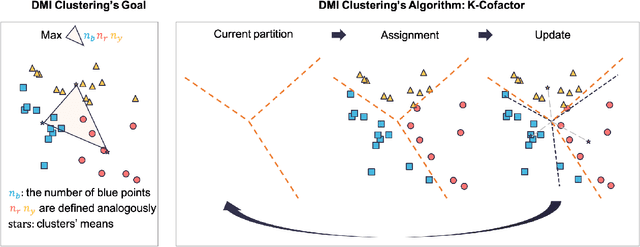
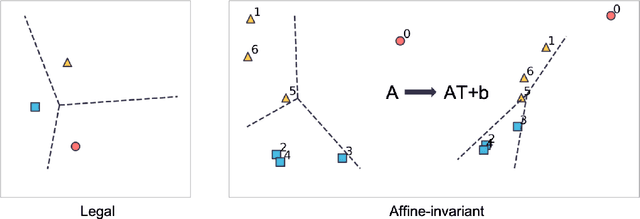
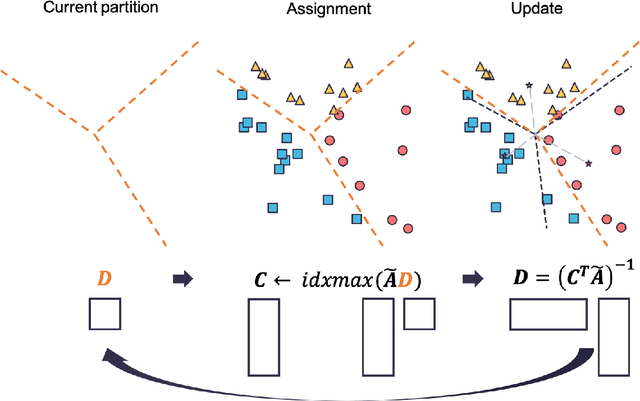
In the setting where we want to aggregate people's subjective evaluations, plurality vote may be meaningless when a large amount of low-effort people always report "good" regardless of the true quality. "Surprisingly popular" method, picking the most surprising answer compared to the prior, handle this issue to some extent. However, it is still not fully robust to people's strategies. Here in the setting where a large number of people are asked to answer a small number of multi-choice questions (multi-task, large group), we propose an information aggregation method that is robust to people's strategies. Interestingly, this method can be seen as a rotated "surprisingly popular". It is based on a new clustering method, Determinant MaxImization (DMI)-clustering, and a key conceptual idea that information elicitation without ground-truth can be seen as a clustering problem. Of independent interest, DMI-clustering is a general clustering method that aims to maximize the volume of the simplex consisting of each cluster's mean multiplying the product of the cluster sizes. We show that DMI-clustering is invariant to any non-degenerate affine transformation for all data points. When the data point's dimension is a constant, DMI-clustering can be solved in polynomial time. In general, we present a simple heuristic for DMI-clustering which is very similar to Lloyd's algorithm for k-means. Additionally, we also apply the clustering idea in the single-task setting and use the spectral method to propose a new aggregation method that utilizes the second-moment information elicited from the crowds.
Graph Filters for Signal Processing and Machine Learning on Graphs
Nov 16, 2022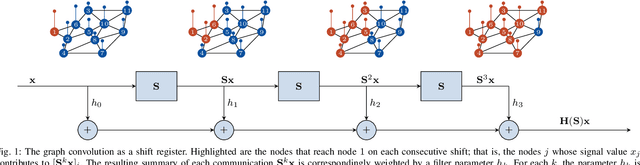

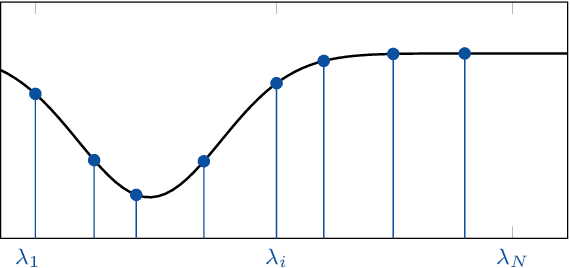
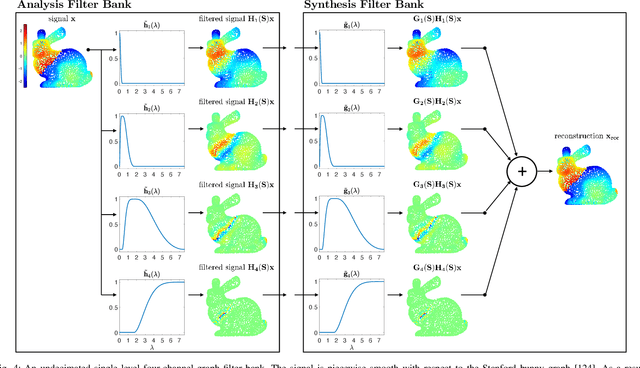
Filters are fundamental in extracting information from data. For time series and image data that reside on Euclidean domains, filters are the crux of many signal processing and machine learning techniques, including convolutional neural networks. Increasingly, modern data also reside on networks and other irregular domains whose structure is better captured by a graph. To process and learn from such data, graph filters account for the structure of the underlying data domain. In this article, we provide a comprehensive overview of graph filters, including the different filtering categories, design strategies for each type, and trade-offs between different types of graph filters. We discuss how to extend graph filters into filter banks and graph neural networks to enhance the representational power; that is, to model a broader variety of signal classes, data patterns, and relationships. We also showcase the fundamental role of graph filters in signal processing and machine learning applications. Our aim is that this article serves the dual purpose of providing a unifying framework for both beginner and experienced researchers, as well as a common understanding that promotes collaborations between signal processing, machine learning, and application domains.
Few-shot Learning for Multi-modal Social Media Event Filtering
Nov 16, 2022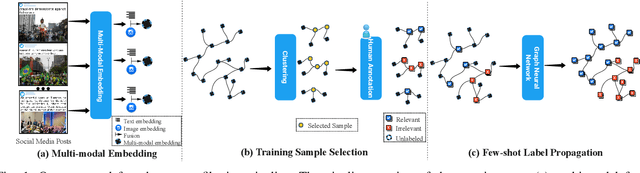
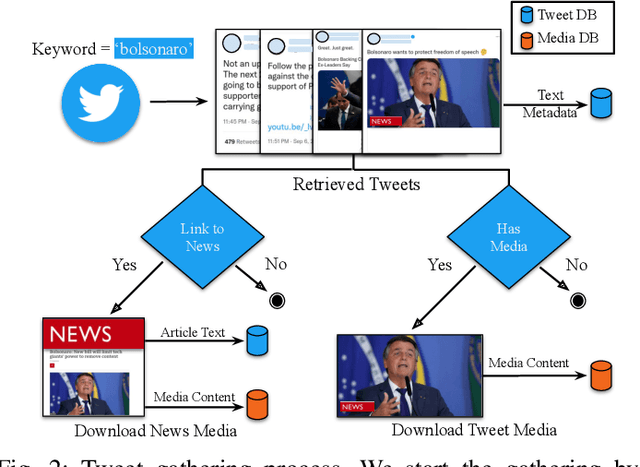
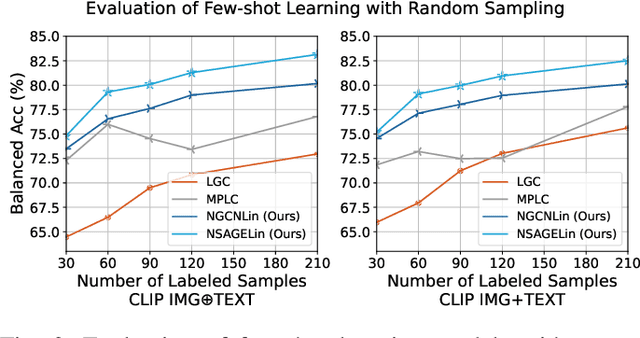
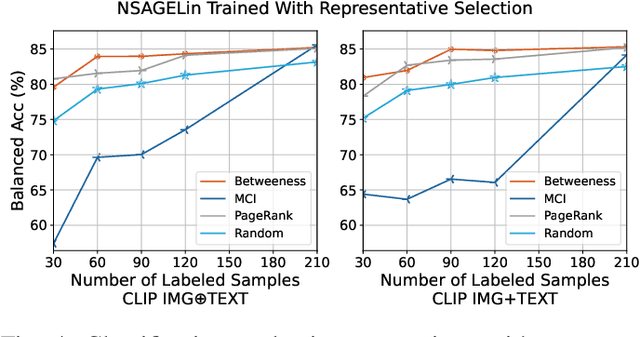
Social media has become an important data source for event analysis. When collecting this type of data, most contain no useful information to a target event. Thus, it is essential to filter out those noisy data at the earliest opportunity for a human expert to perform further inspection. Most existing solutions for event filtering rely on fully supervised methods for training. However, in many real-world scenarios, having access to large number of labeled samples is not possible. To deal with a few labeled sample training problem for event filtering, we propose a graph-based few-shot learning pipeline. We also release the Brazilian Protest Dataset to test our method. To the best of our knowledge, this dataset is the first of its kind in event filtering that focuses on protests in multi-modal social media data, with most of the text in Portuguese. Our experimental results show that our proposed pipeline has comparable performance with only a few labeled samples (60) compared with a fully labeled dataset (3100). To facilitate the research community, we make our dataset and code available at https://github.com/jdnascim/7Set-AL.
The Missing Indicator Method: From Low to High Dimensions
Nov 16, 2022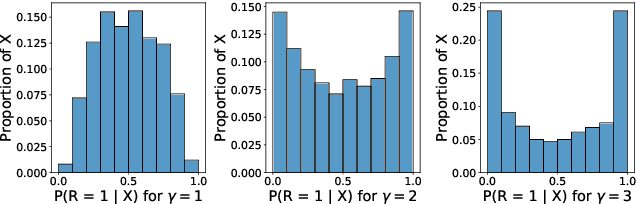
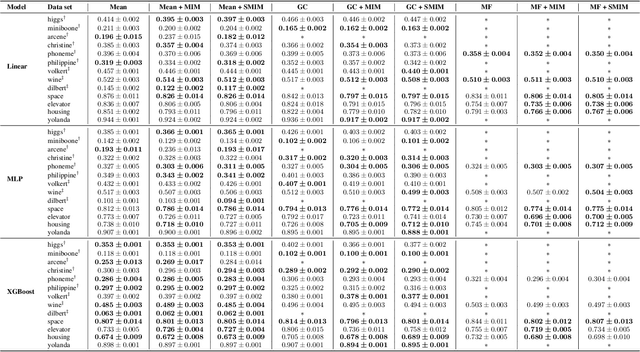
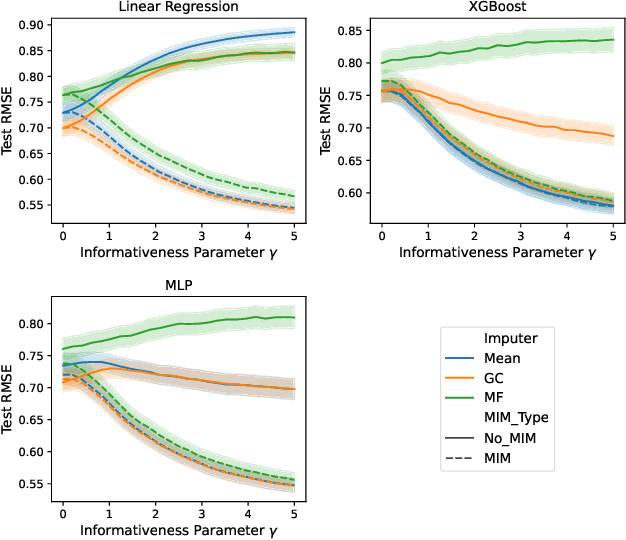
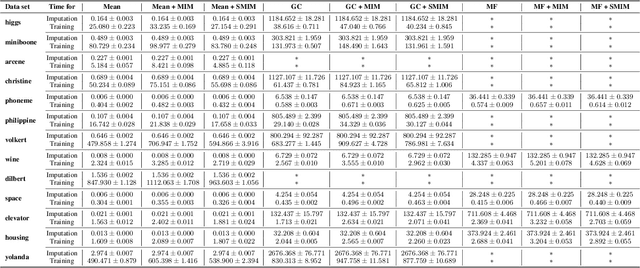
Missing data is common in applied data science, particularly for tabular data sets found in healthcare, social sciences, and natural sciences. Most supervised learning methods work only on complete data, thus requiring preprocessing, such as missing value imputation, to work on incomplete data sets. However, imputation discards potentially useful information encoded by the pattern of missing values. For data sets with informative missing patterns, the Missing Indicator Method (MIM), which adds indicator variables to indicate the missing pattern, can be used in conjunction with imputation to improve model performance. We show experimentally that MIM improves performance for informative missing values, and we prove that MIM does not hurt linear models asymptotically for uninformative missing values. Nonetheless, MIM can increase variance if many of the added indicators are uninformative, causing harm particularly for high-dimensional data sets. To address this issue, we introduce Selective MIM (SMIM), a method that adds missing indicators only for features that have informative missing patterns. We show empirically that SMIM performs at least as well as MIM across a range of experimental settings, and improves MIM for high-dimensional data.
Deep Joint Source-Channel Coding for Semantic Communications
Nov 16, 2022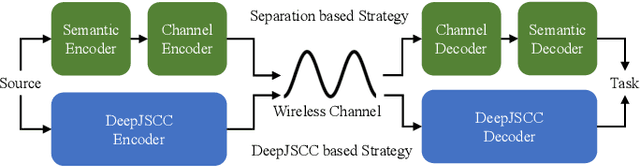
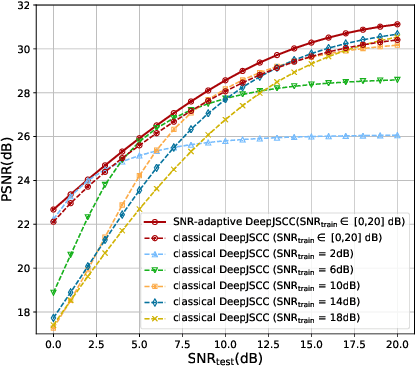
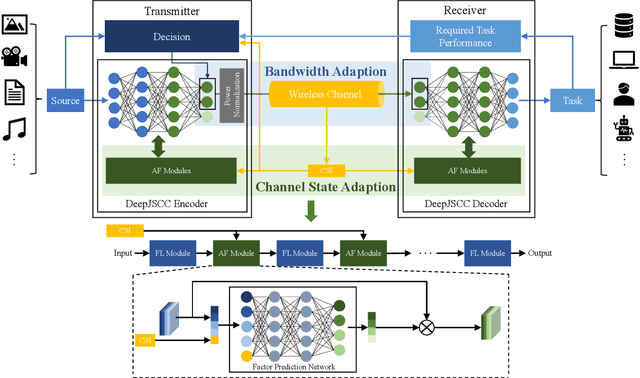
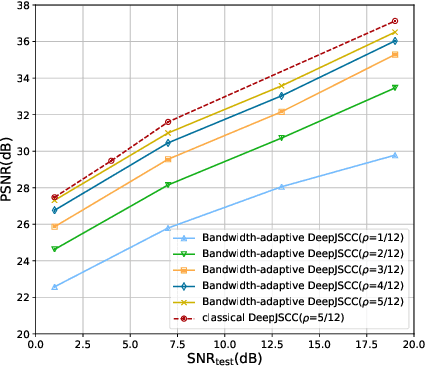
Semantic communications is considered as a promising technology for reducing the bandwidth requirements of next-generation communication systems, particularly targeting human-machine interactions. In contrast to the source-agnostic approach of conventional wireless communication systems, semantic communication seeks to ensure that only the relevant information for the underlying task is communicated to the receiver. A prominent approach to semantic communications is to model it as a joint source-channel coding (JSCC) problem. Although JSCC has been a long-standing open problem in communication and coding theory, remarkable performance gains have been shown recently over existing separate source and channel coding systems, particularly in low-latency and low-power scenarios, typically encountered in edge intelligence applications. Recent progress is thanks to the adoption of deep learning techniques for JSCC code design, which are shown to outperform the concatenation of state-of-the-art compression and channel coding schemes, each of which is a result of decades-long research efforts. In this article, we present an adaptive deep learning based JSCC (DeepJSCC) architecture for semantic communications, introduce its design principles, highlight its benefits, and outline future research challenges that lie ahead.
Hierarchical Dynamic Image Harmonization
Nov 16, 2022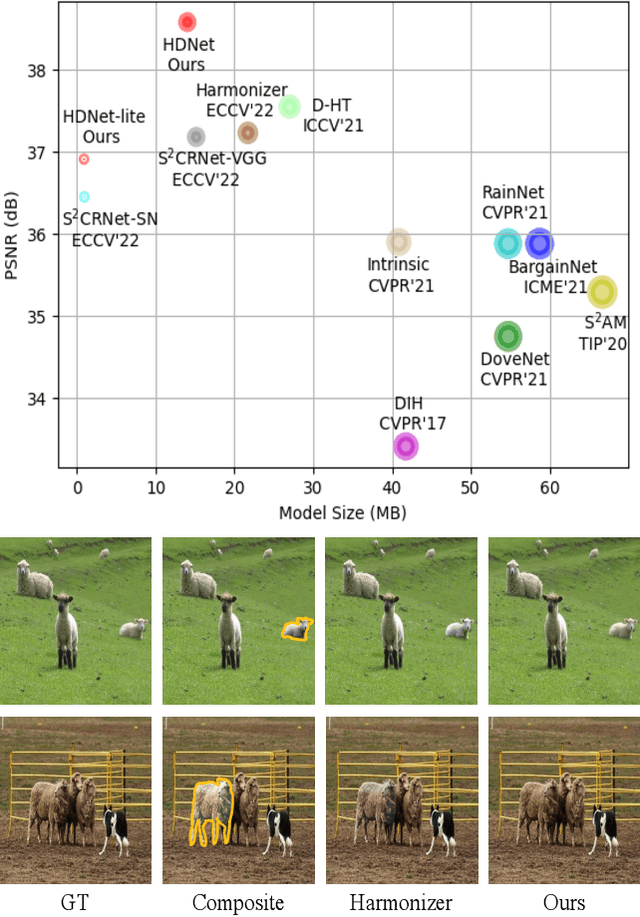
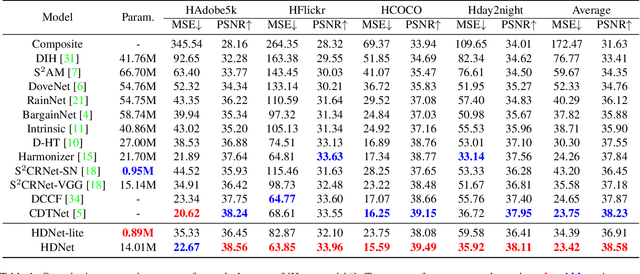
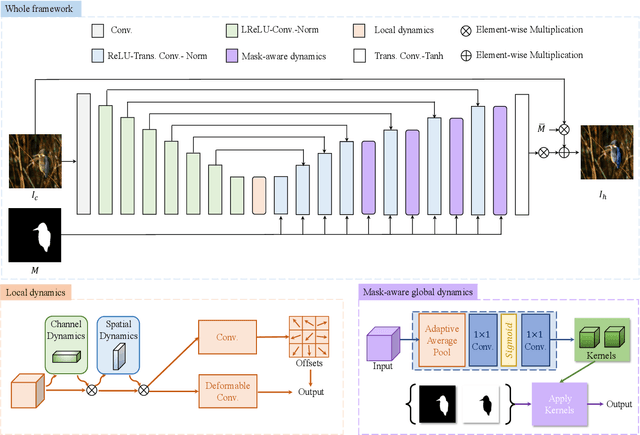
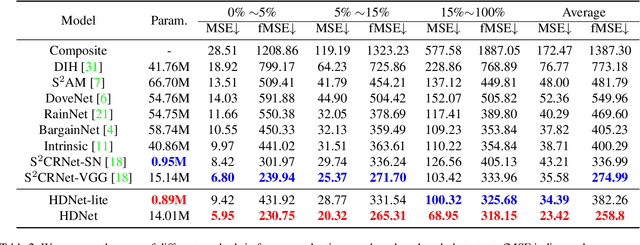
Image harmonization is a critical task in computer vision, which aims to adjust the fore-ground to make it compatible with the back-ground. Recent works mainly focus on using global transformation (i.e., normalization and color curve rendering) to achieve visual consistency. However, these model ignore local consistency and their model size limit their harmonization ability on edge devices. Inspired by the dynamic deep networks that adapt the model structures or parameters conditioned on the inputs, we propose a hierarchical dynamic network (HDNet) for efficient image harmonization to adapt the model parameters and features from local to global view for better feature transformation. Specifically, local dynamics (LD) and mask-aware global dynamics (MGD) are applied. LD enables features of different channels and positions to change adaptively and improve the representation ability of geometric transformation through structural information learning. MGD learns the representations of fore- and back-ground regions and correlations to global harmonization. Experiments show that the proposed HDNet reduces more than 80\% parameters compared with previous methods but still achieves the state-of-the-art performance on the popular iHarmony4 dataset. Our code is avaliable in https://github.com/chenhaoxing/HDNet.
AdaMAE: Adaptive Masking for Efficient Spatiotemporal Learning with Masked Autoencoders
Nov 16, 2022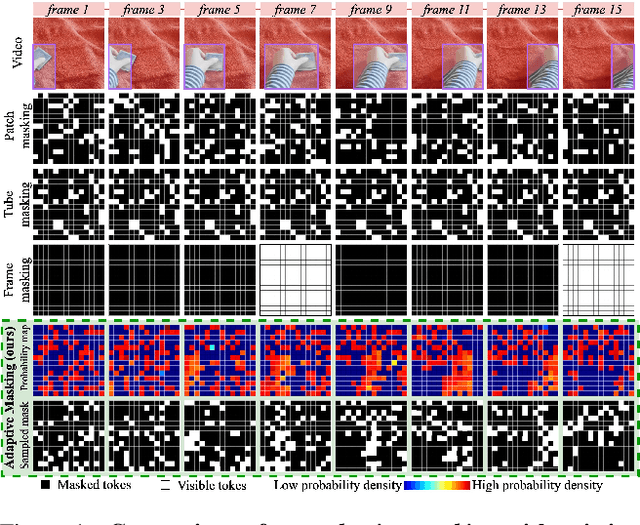

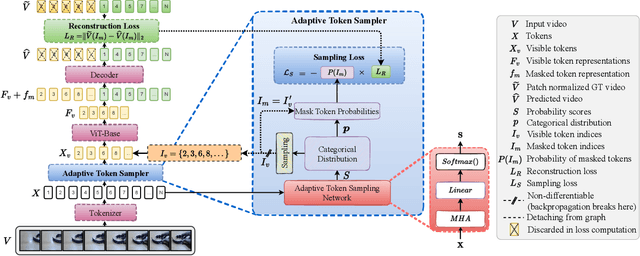
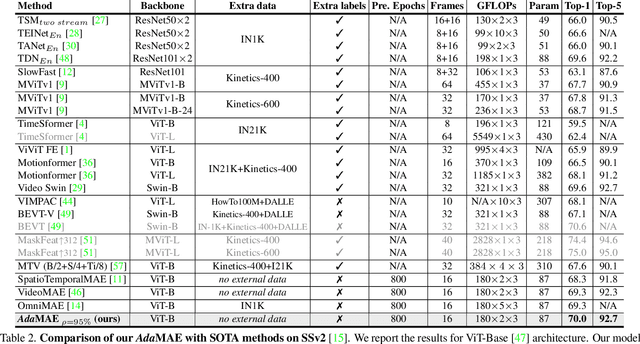
Masked Autoencoders (MAEs) learn generalizable representations for image, text, audio, video, etc., by reconstructing masked input data from tokens of the visible data. Current MAE approaches for videos rely on random patch, tube, or frame-based masking strategies to select these tokens. This paper proposes AdaMAE, an adaptive masking strategy for MAEs that is end-to-end trainable. Our adaptive masking strategy samples visible tokens based on the semantic context using an auxiliary sampling network. This network estimates a categorical distribution over spacetime-patch tokens. The tokens that increase the expected reconstruction error are rewarded and selected as visible tokens, motivated by the policy gradient algorithm in reinforcement learning. We show that AdaMAE samples more tokens from the high spatiotemporal information regions, thereby allowing us to mask 95% of tokens, resulting in lower memory requirements and faster pre-training. We conduct ablation studies on the Something-Something v2 (SSv2) dataset to demonstrate the efficacy of our adaptive sampling approach and report state-of-the-art results of 70.0% and 81.7% in top-1 accuracy on SSv2 and Kinetics-400 action classification datasets with a ViT-Base backbone and 800 pre-training epochs.
An Improved Analysis of (Variance-Reduced) Policy Gradient and Natural Policy Gradient Methods
Nov 16, 2022
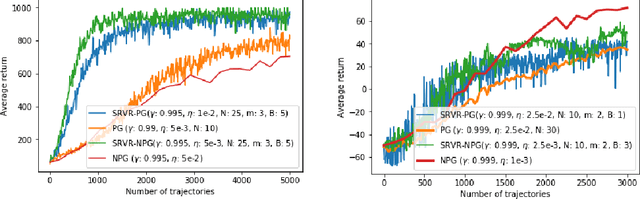
In this paper, we revisit and improve the convergence of policy gradient (PG), natural PG (NPG) methods, and their variance-reduced variants, under general smooth policy parametrizations. More specifically, with the Fisher information matrix of the policy being positive definite: i) we show that a state-of-the-art variance-reduced PG method, which has only been shown to converge to stationary points, converges to the globally optimal value up to some inherent function approximation error due to policy parametrization; ii) we show that NPG enjoys a lower sample complexity; iii) we propose SRVR-NPG, which incorporates variance-reduction into the NPG update. Our improvements follow from an observation that the convergence of (variance-reduced) PG and NPG methods can improve each other: the stationary convergence analysis of PG can be applied to NPG as well, and the global convergence analysis of NPG can help to establish the global convergence of (variance-reduced) PG methods. Our analysis carefully integrates the advantages of these two lines of works. Thanks to this improvement, we have also made variance-reduction for NPG possible, with both global convergence and an efficient finite-sample complexity.
* NeurIPS 2020 (improve the proof of Lemma B.1 and Proposition G.1.)
Array Configuration-Agnostic Personalized Speech Enhancement using Long-Short-Term Spatial Coherence
Nov 16, 2022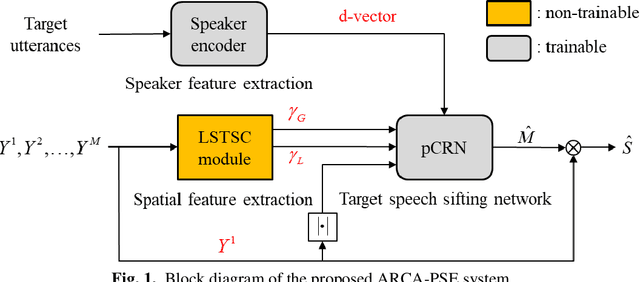
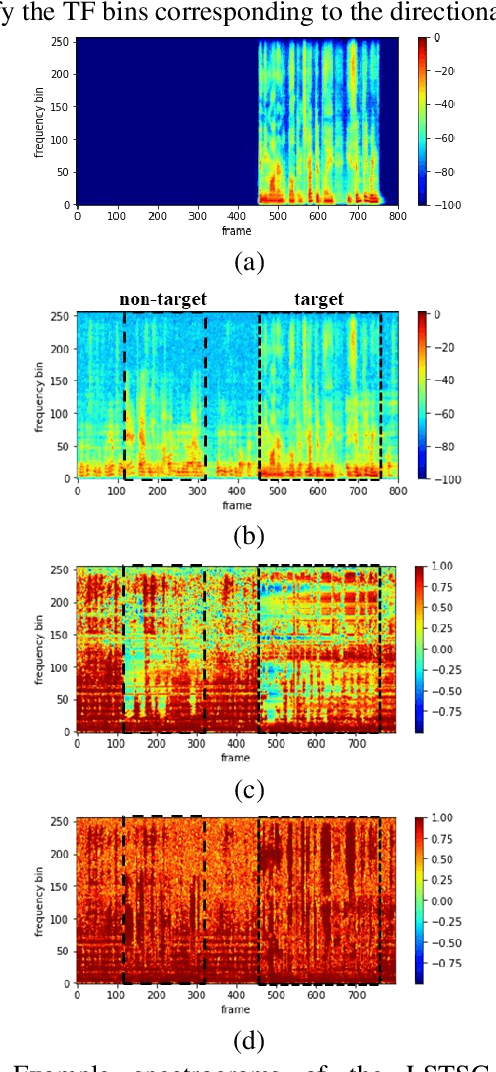
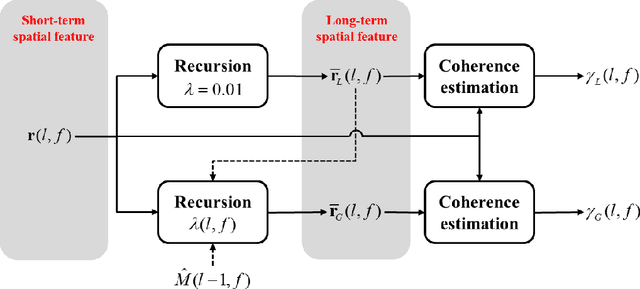
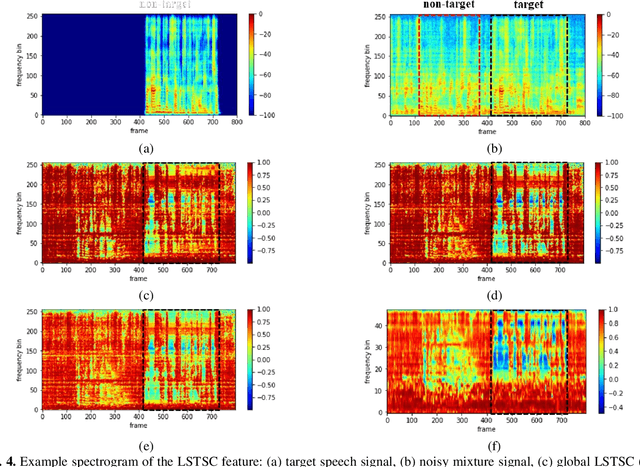
Personalized speech enhancement has been a field of active research for suppression of speechlike interferers such as competing speakers or TV dialogues. Compared with single channel approaches, multichannel PSE systems can be more effective in adverse acoustic conditions by leveraging the spatial information in microphone signals. However, the implementation of multichannel PSEs to accommodate a wide range of array topology in household applications can be challenging. To develop an array configuration agnostic PSE system, we define a spatial feature termed the long short term spatial coherence as the input feature to a convolutional recurrent network to monitor the voice activity of the target speaker. As another refinement, an equivalent rectangular bandwidth scaled LSTSC feature can be used to reduce the computational cost. Experiments were conducted to compare the proposed PSE systems, including the complete and the simplified versions with two baselines using unseen room responses and array configurations in the presence of TV noise and competing speakers. The results demonstrated that the proposed multichannel PSE network trained with the LSTSC feature achieved superior enhancement performance without precise knowledge of the array configurations and room responses.
Position-Aware Subgraph Neural Networks with Data-Efficient Learning
Nov 01, 2022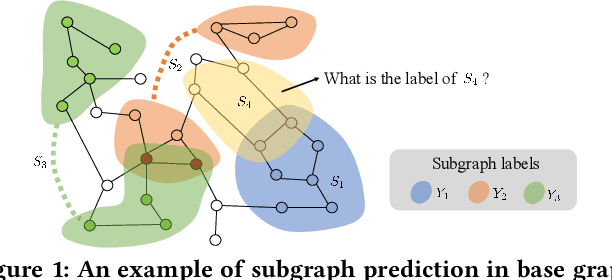
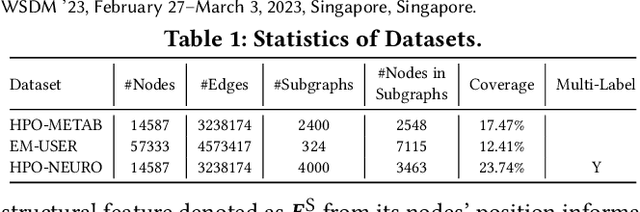
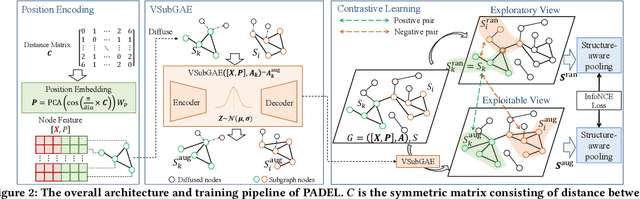
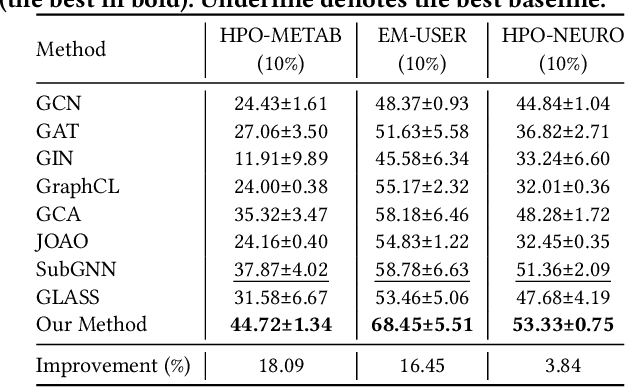
Data-efficient learning on graphs (GEL) is essential in real-world applications. Existing GEL methods focus on learning useful representations for nodes, edges, or entire graphs with ``small'' labeled data. But the problem of data-efficient learning for subgraph prediction has not been explored. The challenges of this problem lie in the following aspects: 1) It is crucial for subgraphs to learn positional features to acquire structural information in the base graph in which they exist. Although the existing subgraph neural network method is capable of learning disentangled position encodings, the overall computational complexity is very high. 2) Prevailing graph augmentation methods for GEL, including rule-based, sample-based, adaptive, and automated methods, are not suitable for augmenting subgraphs because a subgraph contains fewer nodes but richer information such as position, neighbor, and structure. Subgraph augmentation is more susceptible to undesirable perturbations. 3) Only a small number of nodes in the base graph are contained in subgraphs, which leads to a potential ``bias'' problem that the subgraph representation learning is dominated by these ``hot'' nodes. By contrast, the remaining nodes fail to be fully learned, which reduces the generalization ability of subgraph representation learning. In this paper, we aim to address the challenges above and propose a Position-Aware Data-Efficient Learning framework for subgraph neural networks called PADEL. Specifically, we propose a novel node position encoding method that is anchor-free, and design a new generative subgraph augmentation method based on a diffused variational subgraph autoencoder, and we propose exploratory and exploitable views for subgraph contrastive learning. Extensive experiment results on three real-world datasets show the superiority of our proposed method over state-of-the-art baselines.