 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Informed Speech Enhancement Using Attention-Based Beamforming
Mar 05, 2026Recent studies have demonstrated that incorporating auxiliary information, such as speaker voiceprint or visual cues, can substantially improve Speech Enhancement (SE) performance. However, single-channel methods often yield suboptimal results in low signal-to-noise ratio (SNR) conditions, when there is high reverberation, or in complex scenarios involving dynamic speakers, overlapping speech, or non-stationary noise. To address these issues, we propose a novel Visual-Informed Neural Beamforming Network (VI-NBFNet), which integrates microphone array signal processing and deep neural networks (DNNs) using multimodal input features. The proposed network leverages a pretrained visual speech recognition model to extract lip movements as input features, which serve for voice activity detection (VAD) and target speaker identification. The system is intended to handle both static and moving speakers by introducing a supervised end-to-end beamforming framework equipped with an attention mechanism. The experimental results demonstrated that the proposed audiovisual system has achieved better SE performance and robustness for both stationary and dynamic speaker scenarios, compared to several baseline methods.
* 15 pages, 14 figures
Egonoise Resilient Source Localization and Speech Enhancement for Drones Using a Hybrid Model and Learning-Based Approach
Aug 08, 2025Drones are becoming increasingly important in search and rescue missions, and even military operations. While the majority of drones are equipped with camera vision capabilities, the realm of drone audition remains underexplored due to the inherent challenge of mitigating the egonoise generated by the rotors. In this paper, we present a novel technique to address this extremely low signal-to-noise ratio (SNR) problem encountered by the microphone-embedded drones. The technique is implemented using a hybrid approach that combines Array Signal Processing (ASP) and Deep Neural Networks (DNN) to enhance the speech signals captured by a six-microphone uniform circular array mounted on a quadcopter. The system performs localization of the target speaker through beamsteering in conjunction with speech enhancement through a Generalized Sidelobe Canceller-DeepFilterNet 2 (GSC-DF2) system. To validate the system, the DREGON dataset and measured data are employed. Objective evaluations of the proposed hybrid approach demonstrated its superior performance over four baseline methods in the SNR condition as low as -30 dB.
A tunable binaural audio telepresence system capable of balancing immersive and enhanced modes
May 14, 2024Binaural Audio Telepresence (BAT) aims to encode the acoustic scene at the far end into binaural signals for the user at the near end. BAT encompasses an immense range of applications that can vary between two extreme modes of Immersive BAT (I-BAT) and Enhanced BAT (E-BAT). With I-BAT, our goal is to preserve the full ambience as if we were at the far end, while with E-BAT, our goal is to enhance the far-end conversation with significantly improved speech quality and intelligibility. To this end, this paper presents a tunable BAT system to vary between these two AT modes with a desired application-specific balance. Microphone signals are converted into binaural signals with prescribed ambience factor. A novel Spatial COherence REpresentation (SCORE) is proposed as an input feature for model training so that the network remains robust to different array setups. Experimental results demonstrated the superior performance of the proposed BAT, even when the array configurations were not included in the training phase.
Spatial-Temporal Activity-Informed Diarization and Separation
Jan 30, 2024A robust multichannel speaker diarization and separation system is proposed by exploiting the spatio-temporal activity of the speakers. The system is realized in a hybrid architecture that combines the array signal processing units and the deep learning units. For speaker diarization, a spatial coherence matrix across time frames is computed based on the whitened relative transfer functions (wRTFs) of the microphone array. This serves as a robust feature for subsequent machine learning without the need for prior knowledge of the array configuration. A computationally efficient Spatial Activity-driven Speaker Diarization network (SASDnet) is constructed to estimate the speaker activity directly from the spatial coherence matrix. For speaker separation, we propose the Global and Local Activity-driven Speaker Extraction network (GLASEnet) to separate speaker signals via speaker-specific global and local spatial activity functions. The local spatial activity functions depend on the coherence between the wRTFs of each time-frequency bin and the target speaker-dominant bins. The global spatial activity functions are computed from the global spatial coherence functions based on frequency-averaged local spatial activity functions. Experimental results have demonstrated superior speaker, diarization, counting, and separation performance achieved by the proposed system with low computational complexity compared to the pre-selected baselines.
Learning-based Array Configuration-Independent Binaural Audio Telepresence with Scalable Signal Enhancement and Ambience Preservation
Nov 21, 2023Audio Telepresence (AT) aims to create an immersive experience of the audio scene at the far end for the user(s) at the near end. The application of AT could encompass scenarios with varying degrees of emphasis on signal enhancement and ambience preservation. It is desirable for an AT system to be scalable between these two extremes. To this end, we propose an array-based Binaural AT (BAT) system using the DeepFilterNet as the backbone to convert the array microphone signals into the Head-Related Transfer Function (HRTF)-filtered signals, with a tunable weighting between signal enhancement and ambience preservation. An array configuration-independent Spatial COherence REpresentation (SCORE) feature is proposed for the model training so that the network remains robust to different array geometries and sensor counts. magnitude-weighted Interaural Phase Difference error (mw-IPDe), magnitude-weighted Interaural Level Difference error (mw-ILDe), and modified Scale-Invariant Signal-to-Distortion Ratio (mSI-SDR) are defined as performance metrics for objective evaluation. Subjective listening tests were also performed to validate the proposed BAT system. The results have shown that the proposed BAT system can achieve superior telepresence performance with the desired balance between signal enhancement and ambience preservation, even when the array configurations are unseen in the training phase.
Deep Beamforming for Speech Enhancement and Speaker Localization with an Array Response-Aware Loss Function
Oct 22, 2023



Recent research advances in deep neural network (DNN)-based beamformers have shown great promise for speech enhancement under adverse acoustic conditions. Different network architectures and input features have been explored in estimating beamforming weights. In this paper, we propose a deep beamformer based on an efficient convolutional recurrent network (CRN) trained with a novel ARray RespOnse-aWare (ARROW) loss function. The ARROW loss exploits the array responses of the target and interferer by using the ground truth relative transfer functions (RTFs). The DNN-based beamforming system, trained with ARROW loss through supervised learning, is able to perform speech enhancement and speaker localization jointly. Experimental results have shown that the proposed deep beamformer, trained with the linearly weighted scale-invariant source-to-noise ratio (SI-SNR) and ARROW loss functions, achieves superior performance in speech enhancement and speaker localization compared to two baselines.
Array Configuration-Agnostic Personal Voice Activity Detection Based on Spatial Coherence
Apr 18, 2023Personal voice activity detection has received increased attention due to the growing popularity of personal mobile devices and smart speakers. PVAD is often an integral element to speech enhancement and recognition for these applications in which lightweight signal processing is only enabled for the target user. However, in real-world scenarios, the detection performance may degrade because of competing speakers, background noise, and reverberation. To address this problem, we proposed to use equivalent rectangular bandwidth ERB-scaled spatial coherence as the input feature to train an array configuration-agnostic PVAD network. Whereas the network model requires only 112k parameters, it exhibits excellent detection performance and robustness in adverse acoustic conditions. Notably, the proposed ARCA-PVAD system is scalable to array configurations. Experimental results have demonstrated the superior performance achieved by the proposed ARCA-PVAD system over a baseline in terms of the area under receiver operating characteristic curve and equal error rate.
Array Configuration-Agnostic Personalized Speech Enhancement using Long-Short-Term Spatial Coherence
Nov 16, 2022Personalized speech enhancement has been a field of active research for suppression of speechlike interferers such as competing speakers or TV dialogues. Compared with single channel approaches, multichannel PSE systems can be more effective in adverse acoustic conditions by leveraging the spatial information in microphone signals. However, the implementation of multichannel PSEs to accommodate a wide range of array topology in household applications can be challenging. To develop an array configuration agnostic PSE system, we define a spatial feature termed the long short term spatial coherence as the input feature to a convolutional recurrent network to monitor the voice activity of the target speaker. As another refinement, an equivalent rectangular bandwidth scaled LSTSC feature can be used to reduce the computational cost. Experiments were conducted to compare the proposed PSE systems, including the complete and the simplified versions with two baselines using unseen room responses and array configurations in the presence of TV noise and competing speakers. The results demonstrated that the proposed multichannel PSE network trained with the LSTSC feature achieved superior enhancement performance without precise knowledge of the array configurations and room responses.
Multi-channel target speech enhancement based on ERB-scaled spatial coherence features
Jul 17, 2022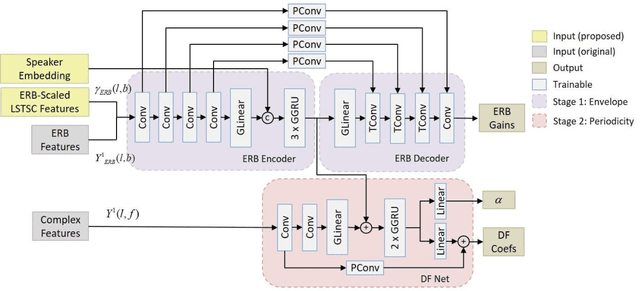
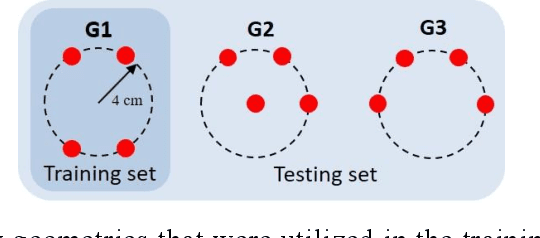
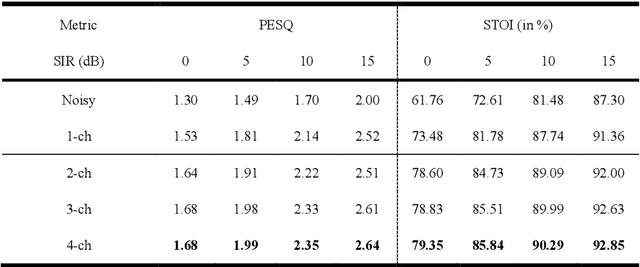
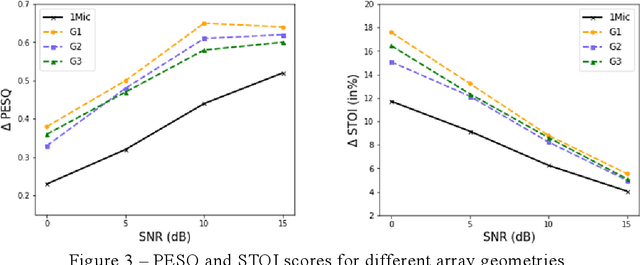
Recently, speech enhancement technologies that are based on deep learning have received considerable research attention. If the spatial information in microphone signals is exploited, microphone arrays can be advantageous under some adverse acoustic conditions compared with single-microphone systems. However, multichannel speech enhancement is often performed in the short-time Fourier transform (STFT) domain, which renders the enhancement approach computationally expensive. To remedy this problem, we propose a novel equivalent rectangular bandwidth (ERB)-scaled spatial coherence feature that is dependent on the target speaker activity between two ERB bands. Experiments conducted using a four-microphone array in a reverberant environment, which involved speech interference, demonstrated the efficacy of the proposed system. This study also demonstrated that a network that was trained with the ERB-scaled spatial feature was robust against variations in the geometry and number of the microphones in the array.
Multi-channel end-to-end neural network for speech enhancement, source localization, and voice activity detection
Jun 20, 2022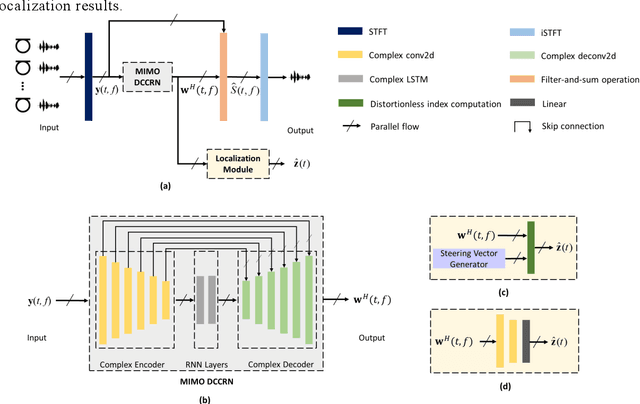
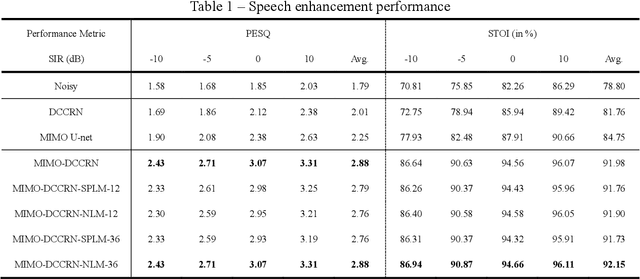
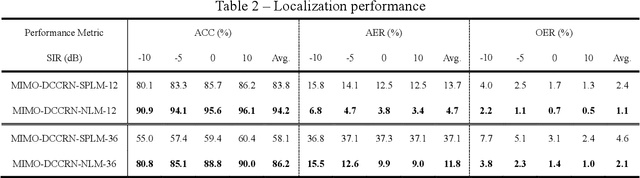
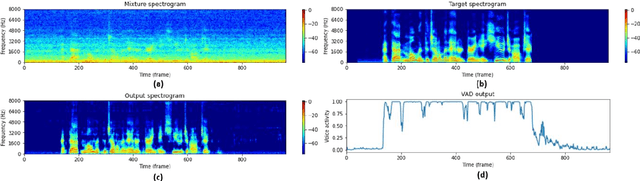
Speech enhancement and source localization has been active research for several decades with a wide range of real-world applications. Recently, the Deep Complex Convolution Recurrent network (DCCRN) has yielded impressive enhancement performance for single-channel systems. In this study, a neural beamformer consisting of a beamformer and a novel multi-channel DCCRN is proposed for speech enhancement and source localization. Complex-valued filters estimated by the multi-channel DCCRN serve as the weights of beamformer. In addition, a one-stage learning-based procedure is employed for speech enhancement and source localization. The proposed network composed of the multi-channel DCCRN and the auxiliary network models the sound field, while minimizing the distortionless response loss function. Simulation results show that the proposed neural beamformer is effective in enhancing speech signals, with speech quality well preserved. The proposed neural beamformer also provides source localization and voice activity detection (VAD) functions.