 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Joint Source-Channel Coding for Semantic Communications
Dec 05, 2022
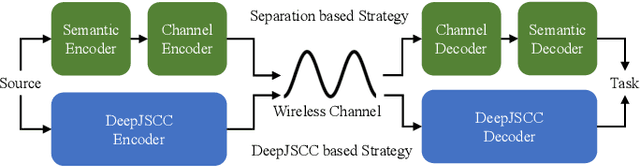
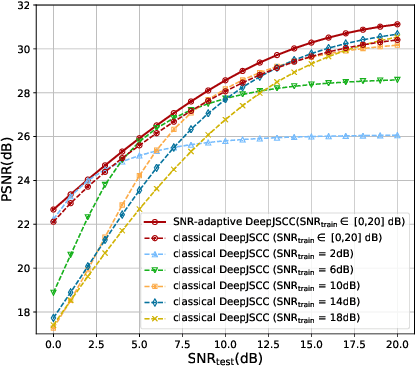
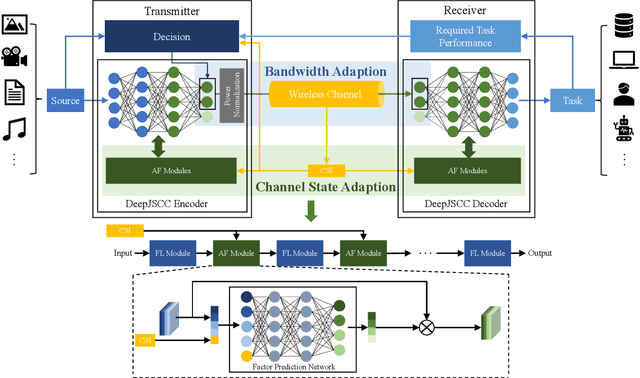
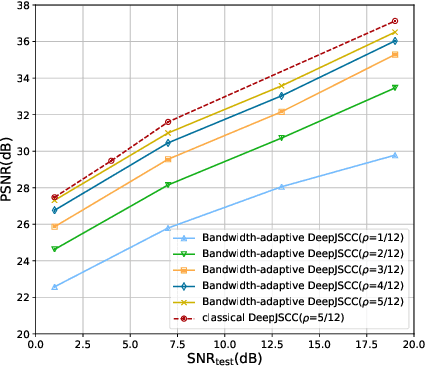
Semantic communications is considered as a promising technology for reducing the bandwidth requirements of next-generation communication systems, particularly targeting human-machine interactions. In contrast to the source-agnostic approach of conventional wireless communication systems, semantic communication seeks to ensure that only the relevant information for the underlying task is communicated to the receiver. A prominent approach to semantic communications is to model it as a joint source-channel coding (JSCC) problem. Although JSCC has been a long-standing open problem in communication and coding theory, remarkable performance gains have been shown recently over existing separate source and channel coding systems, particularly in low-latency and low-power scenarios, typically encountered in edge intelligence applications. Recent progress is thanks to the adoption of deep learning techniques for JSCC code design, which are shown to outperform the concatenation of state-of-the-art compression and channel coding schemes, each of which is a result of decades-long research efforts. In this article, we present an adaptive deep learning based JSCC (DeepJSCC) architecture for semantic communications, introduce its design principles, highlight its benefits, and outline future research challenges that lie ahead.
Generalizable Person Re-Identification via Viewpoint Alignment and Fusion
Dec 05, 2022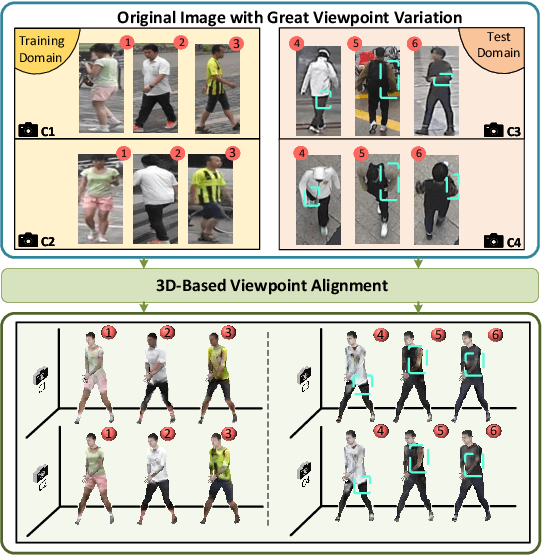
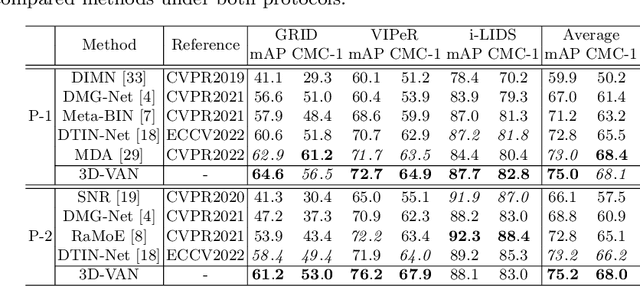
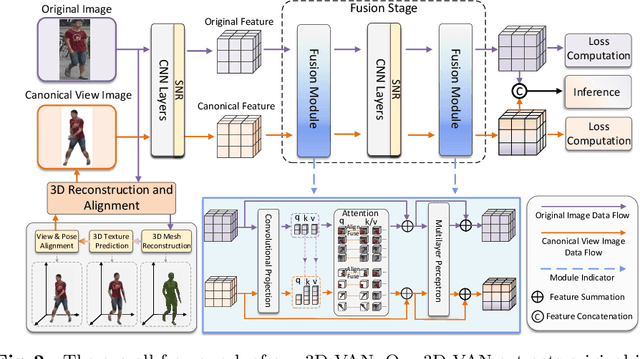
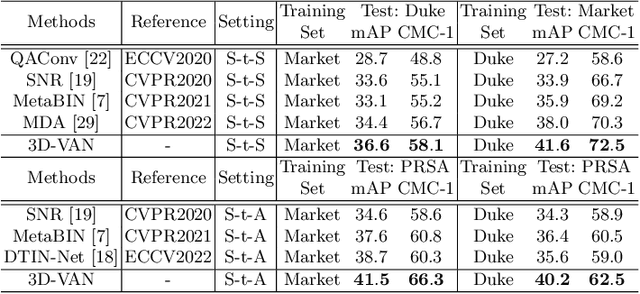
In the current person Re-identification (ReID) methods, most domain generalization works focus on dealing with style differences between domains while largely ignoring unpredictable camera view change, which we identify as another major factor leading to a poor generalization of ReID methods. To tackle the viewpoint change, this work proposes to use a 3D dense pose estimation model and a texture mapping module to map the pedestrian images to canonical view images. Due to the imperfection of the texture mapping module, the canonical view images may lose the discriminative detail clues from the original images, and thus directly using them for ReID will inevitably result in poor performance. To handle this issue, we propose to fuse the original image and canonical view image via a transformer-based module. The key insight of this design is that the cross-attention mechanism in the transformer could be an ideal solution to align the discriminative texture clues from the original image with the canonical view image, which could compensate for the low-quality texture information of the canonical view image. Through extensive experiments, we show that our method can lead to superior performance over the existing approaches in various evaluation settings.
Inspired by Norbert Wiener: FeedBack Loop Network Learning Incremental Knowledge for Driver Attention Prediction and Beyond
Dec 05, 2022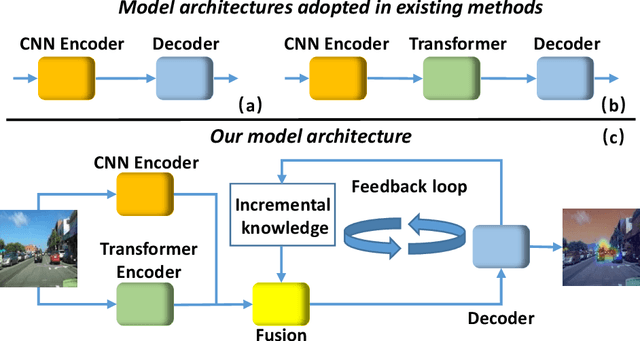
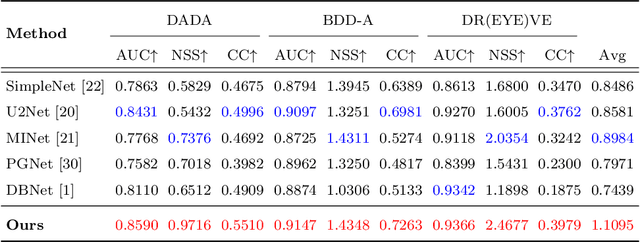
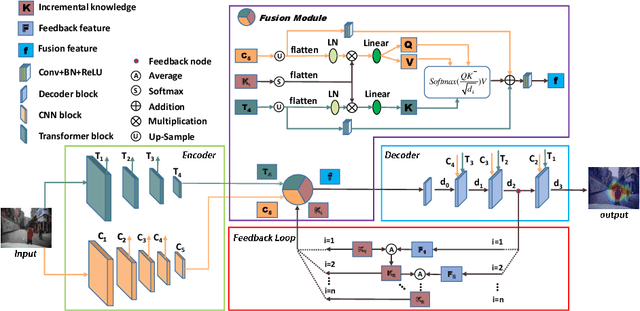
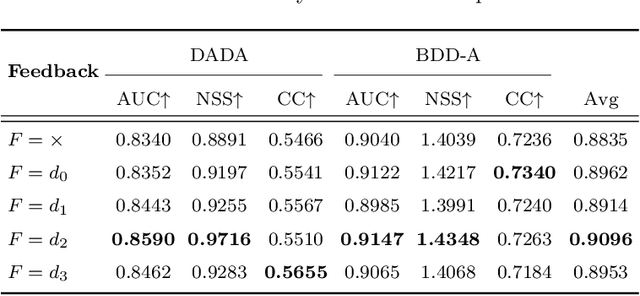
The problem of predicting driver attention from the driving perspective is gaining the increasing research focuses due to its remarkable significance for autonomous driving and assisted driving systems. Driving experience is extremely important for driver attention prediction, a skilled driver is able to effortlessly predict oncoming danger (before it becomes salient) based on driving experience and quickly pay attention on the corresponding zones. However, the nonobjective driving experience is difficult to model, so a mechanism simulating driver experience accumulation procedure is absent in existing methods, and the existing methods usually follow the technique line of saliency prediction methods to predict driver attention. In this paper, we propose a FeedBack Loop Network (FBLNet), which attempts to model the driving experience accumulation procedure. By over-and-over iterations, FBLNet generates the incremental knowledge that carries rich historically-accumulative long-term temporal information. The incremental knowledge to our model is like the driving experience to humans. Under the guidance of the incremental knowledge, our model fuses the CNN feature and Transformer feature that are extracted from the input image to predict driver attention. Our model exhibits solid advantage over existing methods, achieving an average 10.3% performance improvement on three public datasets.
Crime Prediction using Machine Learning with a Novel Crime Dataset
Nov 03, 2022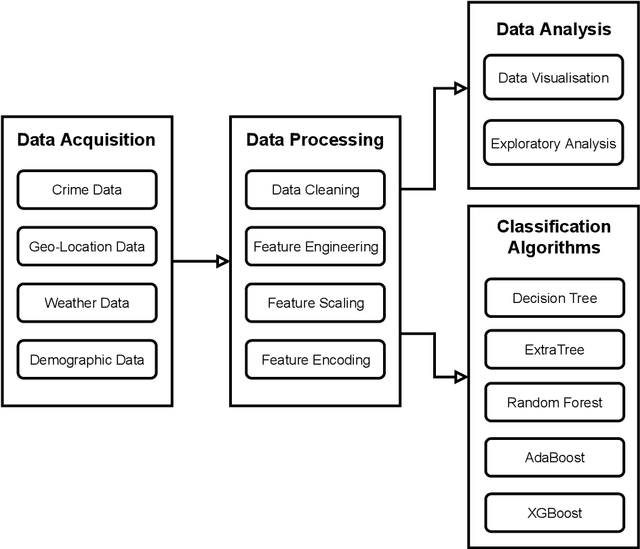

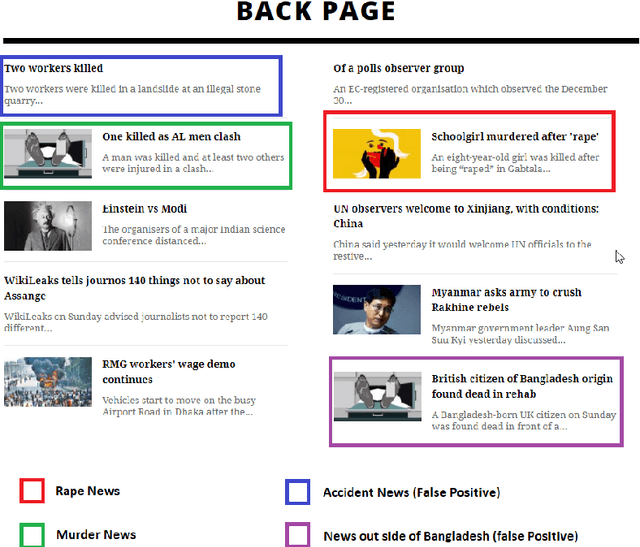
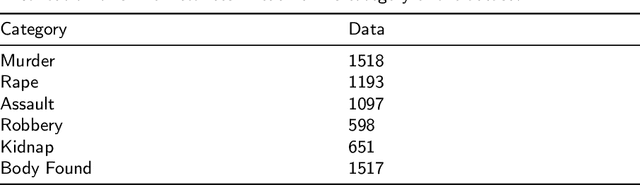
Crime is an unlawful act that carries legal repercussions. Bangladesh has a high crime rate due to poverty, population growth, and many other socio-economic issues. For law enforcement agencies, understanding crime patterns is essential for preventing future criminal activity. For this purpose, these agencies need structured crime database. This paper introduces a novel crime dataset that contains temporal, geographic, weather, and demographic data about 6574 crime incidents of Bangladesh. We manually gather crime news articles of a seven year time span from a daily newspaper archive. We extract basic features from these raw text. Using these basic features, we then consult standard service-providers of geo-location and weather data in order to garner these information related to the collected crime incidents. Furthermore, we collect demographic information from Bangladesh National Census data. All these information are combined that results in a standard machine learning dataset. Together, 36 features are engineered for the crime prediction task. Five supervised machine learning classification algorithms are then evaluated on this newly built dataset and satisfactory results are achieved. We also conduct exploratory analysis on various aspects the dataset. This dataset is expected to serve as the foundation for crime incidence prediction systems for Bangladesh and other countries. The findings of this study will help law enforcement agencies to forecast and contain crime as well as to ensure optimal resource allocation for crime patrol and prevention.
Large Language Models Struggle to Learn Long-Tail Knowledge
Nov 15, 2022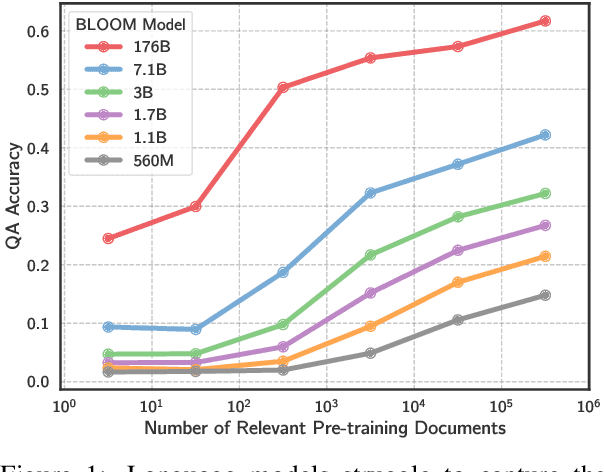
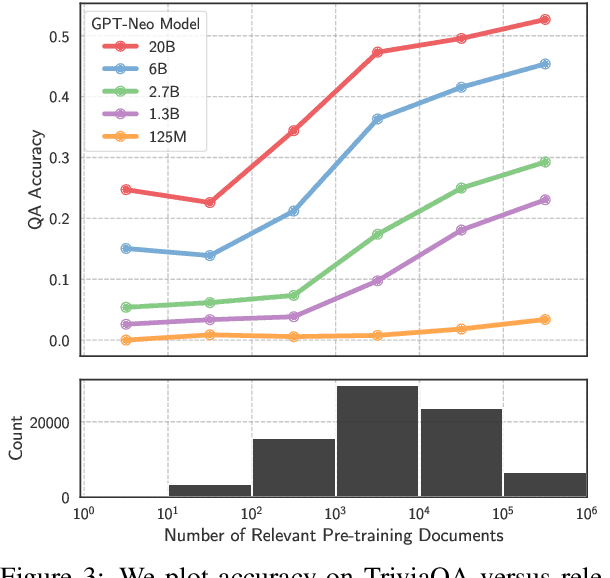
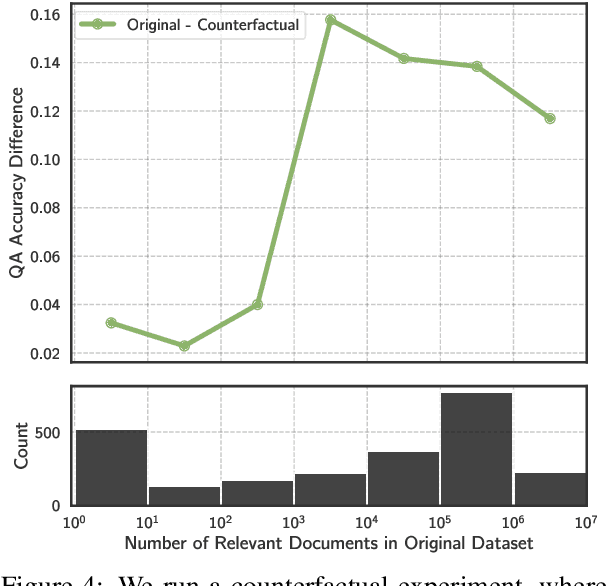
The internet contains a wealth of knowledge -- from the birthdays of historical figures to tutorials on how to code -- all of which may be learned by language models. However, there is a huge variability in the number of times a given piece of information appears on the web. In this paper, we study the relationship between the knowledge memorized by large language models and the information in their pre-training datasets. In particular, we show that a language model's ability to answer a fact-based question relates to how many documents associated with that question were seen during pre-training. We identify these relevant documents by entity linking pre-training datasets and counting documents that contain the same entities as a given question-answer pair. Our results demonstrate strong correlational and causal relationships between accuracy and relevant document count for numerous question answering datasets (e.g., TriviaQA), pre-training corpora (e.g., ROOTS), and model sizes (e.g., 176B parameters). Moreover, we find that while larger models are better at learning long-tail knowledge, we estimate that today's models must be scaled by many orders of magnitude to reach competitive QA performance on questions with little support in the pre-training data. Finally, we show that retrieval-augmentation can reduce the dependence on relevant document count, presenting a promising approach for capturing the long-tail.
ConvFormer: Combining CNN and Transformer for Medical Image Segmentation
Nov 15, 2022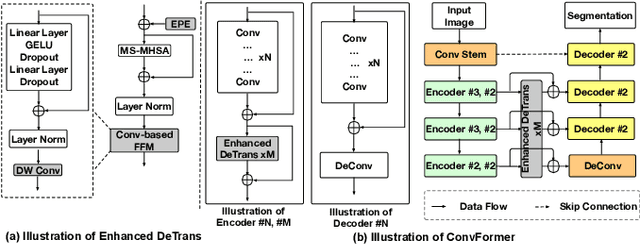
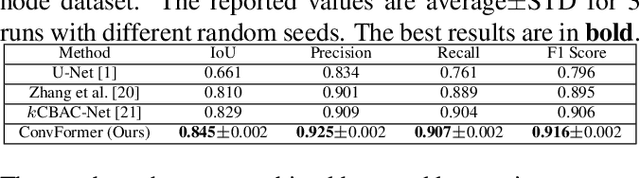
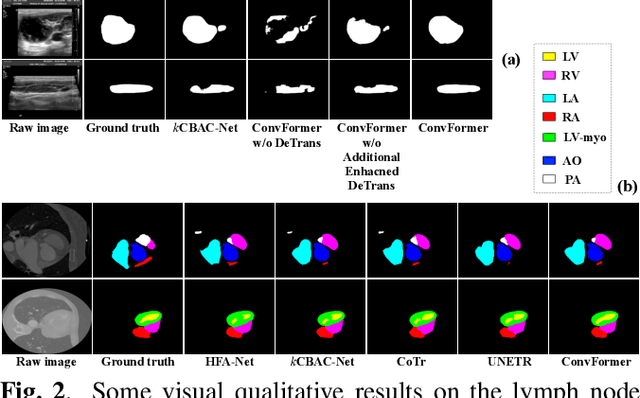
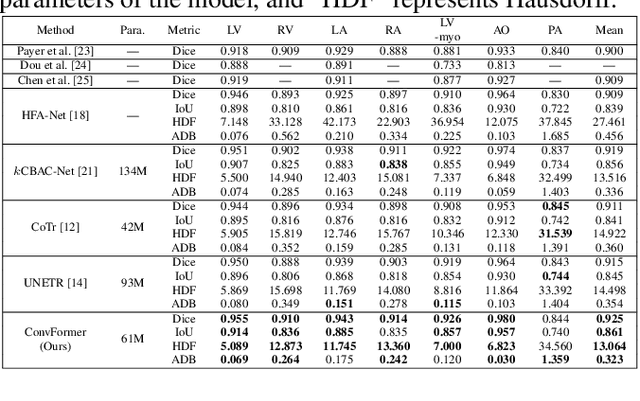
Convolutional neural network (CNN) based methods have achieved great successes in medical image segmentation, but their capability to learn global representations is still limited due to using small effective receptive fields of convolution operations. Transformer based methods are capable of modelling long-range dependencies of information for capturing global representations, yet their ability to model local context is lacking. Integrating CNN and Transformer to learn both local and global representations while exploring multi-scale features is instrumental in further improving medical image segmentation. In this paper, we propose a hierarchical CNN and Transformer hybrid architecture, called ConvFormer, for medical image segmentation. ConvFormer is based on several simple yet effective designs. (1) A feed forward module of Deformable Transformer (DeTrans) is re-designed to introduce local information, called Enhanced DeTrans. (2) A residual-shaped hybrid stem based on a combination of convolutions and Enhanced DeTrans is developed to capture both local and global representations to enhance representation ability. (3) Our encoder utilizes the residual-shaped hybrid stem in a hierarchical manner to generate feature maps in different scales, and an additional Enhanced DeTrans encoder with residual connections is built to exploit multi-scale features with feature maps of different scales as input. Experiments on several datasets show that our ConvFormer, trained from scratch, outperforms various CNN- or Transformer-based architectures, achieving state-of-the-art performance.
Data-Driven Occupancy Grid Mapping using Synthetic and Real-World Data
Nov 15, 2022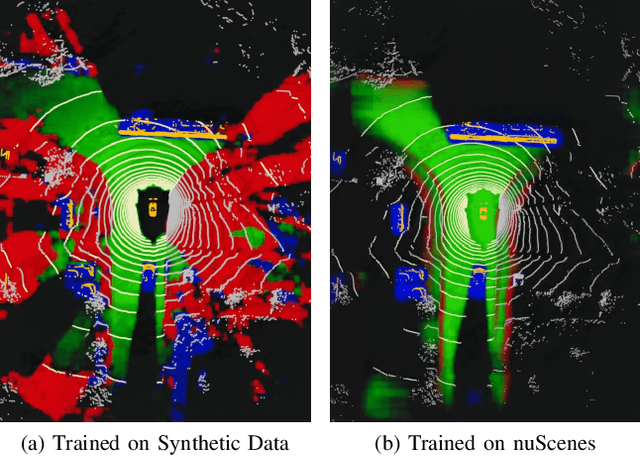
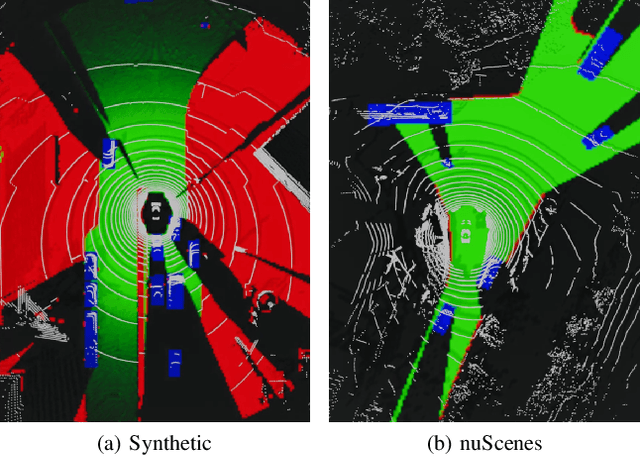


In perception tasks of automated vehicles (AVs) data-driven have often outperformed conventional approaches. This motivated us to develop a data-driven methodology to compute occupancy grid maps (OGMs) from lidar measurements. Our approach extends previous work such that the estimated environment representation now contains an additional layer for cells occupied by dynamic objects. Earlier solutions could only distinguish between free and occupied cells. The information whether an obstacle could move plays an important role for planning the behavior of an AV. We present two approaches to generating training data. One approach extends our previous work on using synthetic training data so that OGMs with the three aforementioned cell states are generated. The other approach uses manual annotations from the nuScenes dataset to create training data. We compare the performance of both models in a quantitative analysis on unseen data from the real-world dataset. Next, we analyze the ability of both approaches to cope with a domain shift, i.e. when presented with lidar measurements from a different sensor on a different vehicle. We propose using information gained from evaluation on real-world data to further close the reality gap and create better synthetic data that can be used to train occupancy grid mapping models for arbitrary sensor configurations. Code is available at https://github.com/ika-rwth-aachen/DEviLOG.
Chronic pain patient narratives allow for the estimation of current pain intensity
Nov 17, 2022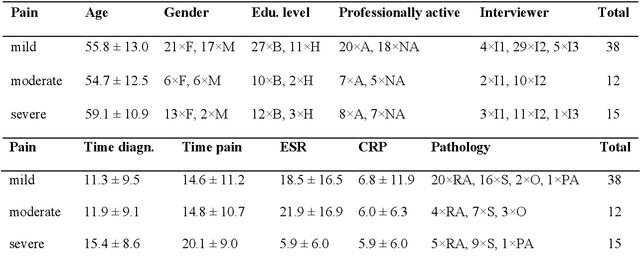
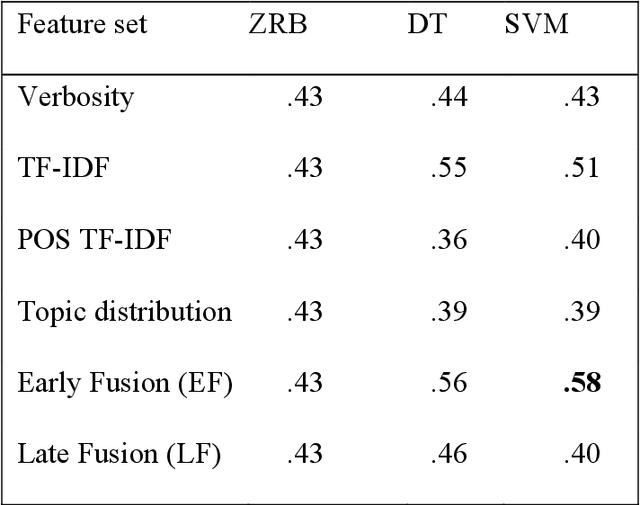

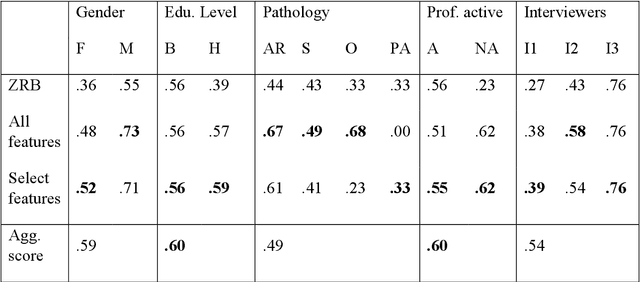
Chronic pain is a multi-dimensional experience, and pain intensity plays an important part, impacting the patients emotional balance, psychology, and behaviour. Standard self-reporting tools, such as the Visual Analogue Scale for pain, fail to capture this burden. Moreover, this type of tools is susceptible to a degree of subjectivity, dependent on the patients clear understanding of how to use it, social biases, and their ability to translate a complex experience to a scale. To overcome these and other self-reporting challenges, pain intensity estimation has been previously studied based on facial expressions, electroencephalograms, brain imaging, and autonomic features. However, to the best of our knowledge, it has never been attempted to base this estimation on the patient narratives of the personal experience of chronic pain, which is what we propose in this work. Indeed, in the clinical assessment and management of chronic pain, verbal communication is essential to convey information to physicians that would otherwise not be easily accessible through standard reporting tools, since language, sociocultural, and psychosocial variables are intertwined. We show that language features from patient narratives indeed convey information relevant for pain intensity estimation, and that our computational models can take advantage of that. Specifically, our results show that patients with mild pain focus more on the use of verbs, whilst moderate and severe pain patients focus on adverbs, and nouns and adjectives, respectively, and that these differences allow for the distinction between these three pain classes.
Thermodynamics of bidirectional associative memories
Nov 17, 2022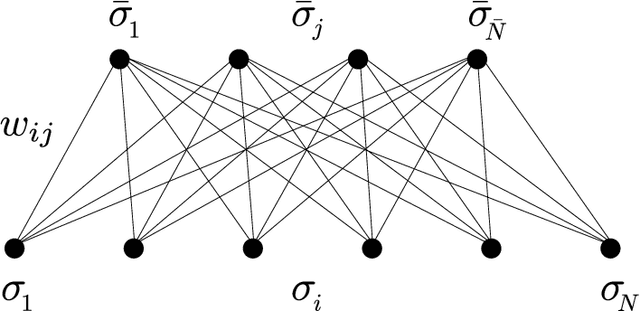
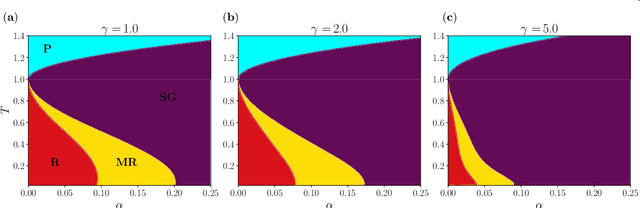
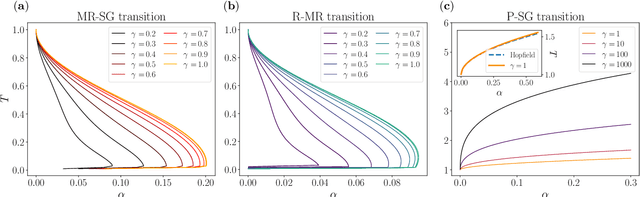
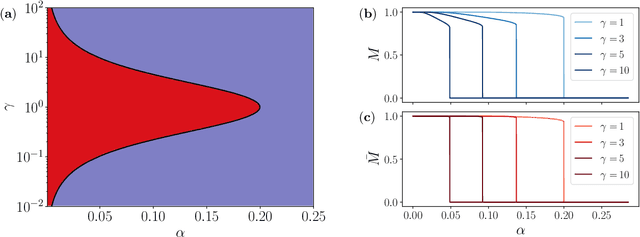
In this paper we investigate the equilibrium properties of bidirectional associative memories (BAMs). Introduced by Kosko in 1988 as a generalization of the Hopfield model to a bipartite structure, the simplest architecture is defined by two layers of neurons, with synaptic connections only between units of different layers: even without internal connections within each layer, information storage and retrieval are still possible through the reverberation of neural activities passing from one layer to another. We characterize the computational capabilities of a stochastic extension of this model in the thermodynamic limit, by applying rigorous techniques from statistical physics. A detailed picture of the phase diagram at the replica symmetric level is provided, both at finite temperature and in the noiseless regime. An analytical and numerical inspection of the transition curves (namely critical lines splitting the various modes of operation of the machine) is carried out as the control parameters - noise, load and asymmetry between the two layer sizes - are tuned. In particular, with a finite asymmetry between the two layers, it is shown how the BAM can store information more efficiently than the Hopfield model by requiring less parameters to encode a fixed number of patterns. Comparisons are made with numerical simulations of neural dynamics. Finally, a low-load analysis is carried out to explain the retrieval mechanism in the BAM by analogy with two interacting Hopfield models. A potential equivalence with two coupled Restricted Boltmzann Machines is also discussed.
Tucker-O-Minus Decomposition for Multi-view Tensor Subspace Clustering
Oct 23, 2022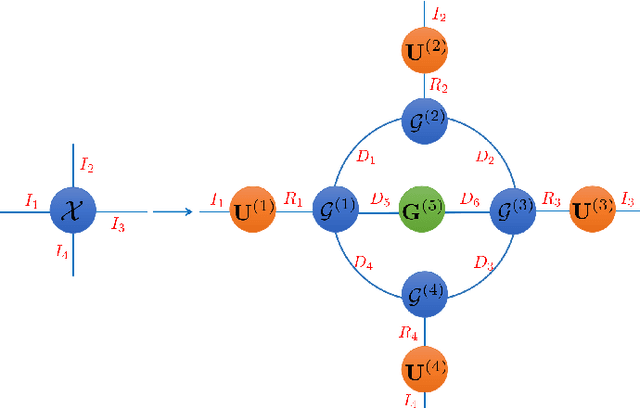

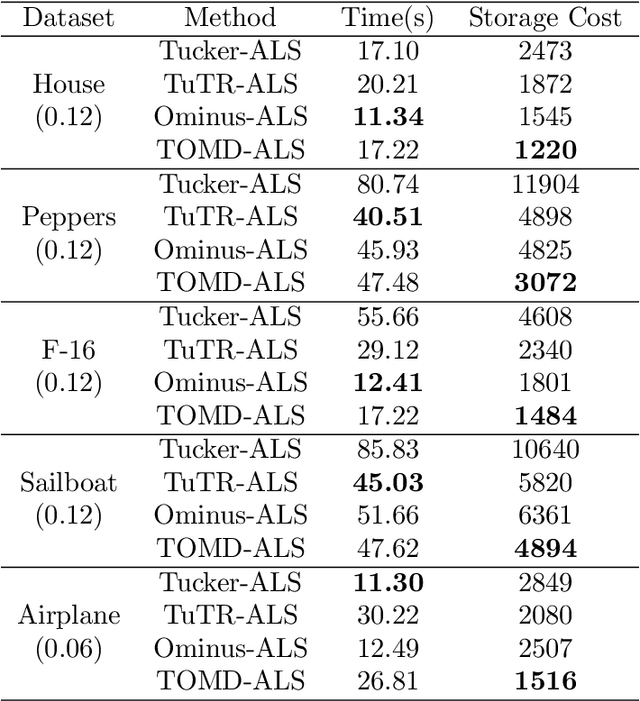
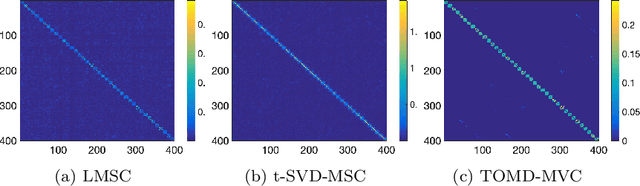
With powerful ability to exploit latent structure of self-representation information, different tensor decompositions have been employed into low rank multi-view clustering (LRMVC) models for achieving significant performance. However, current approaches suffer from a series of problems related to those tensor decomposition, such as the unbalanced matricization scheme, rotation sensitivity, deficient correlations capture and so forth. All these will lead to LRMVC having insufficient access to global information, which is contrary to the target of multi-view clustering. To alleviate these problems, we propose a new tensor decomposition called Tucker-O-Minus Decomposition (TOMD) for multi-view clustering. Specifically, based on the Tucker format, we additionally employ the O-minus structure, which consists of a circle with an efficient bridge linking two weekly correlated factors. In this way, the core tensor in Tucker format is replaced by the O-minus architecture with a more balanced structure, and the enhanced capacity of capturing the global low rank information will be achieved. The proposed TOMD also provides more compact and powerful representation abilities for the self-representation tensor, simultaneously. The alternating direction method of multipliers is used to solve the proposed model TOMD-MVC. Numerical experiments on six benchmark data sets demonstrate the superiority of our proposed method in terms of F-score, precision, recall, normalized mutual information, adjusted rand index, and accuracy.