 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepRGVP: A Novel Microstructure-Informed Supervised Contrastive Learning Framework for Automated Identification Of The Retinogeniculate Pathway Using dMRI Tractography
Nov 15, 2022
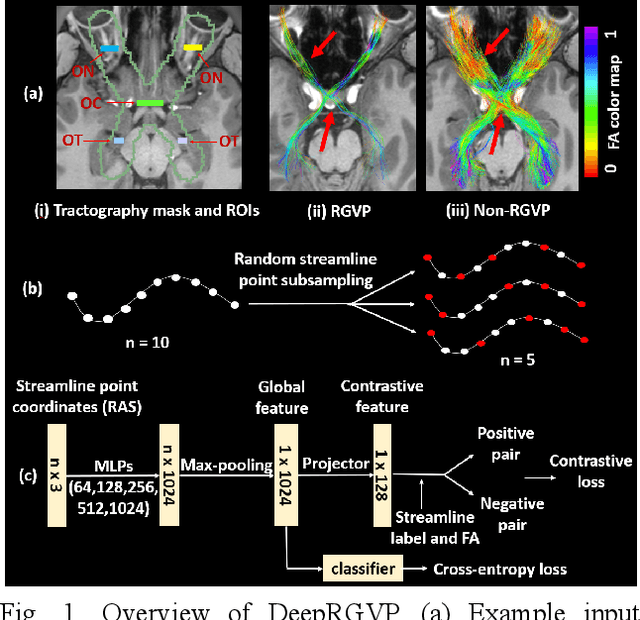

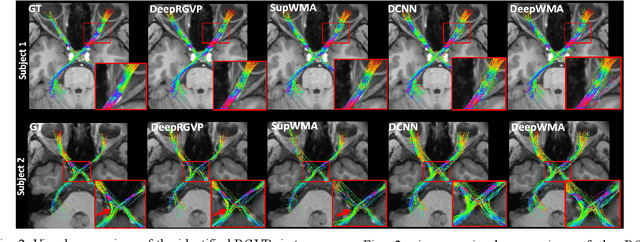
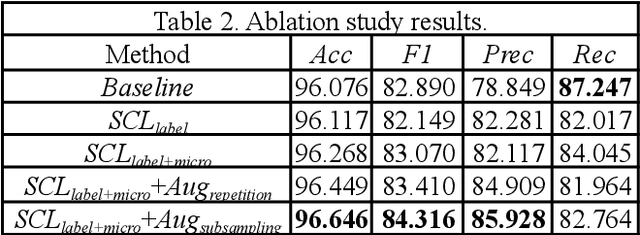
The retinogeniculate pathway (RGVP) is responsible for carrying visual information from the retina to the lateral geniculate nucleus. Identification and visualization of the RGVP are important in studying the anatomy of the visual system and can inform treatment of related brain diseases. Diffusion MRI (dMRI) tractography is an advanced imaging method that uniquely enables in vivo mapping of the 3D trajectory of the RGVP. Currently, identification of the RGVP from tractography data relies on expert (manual) selection of tractography streamlines, which is time-consuming, has high clinical and expert labor costs, and affected by inter-observer variability. In this paper, we present what we believe is the first deep learning framework, namely DeepRGVP, to enable fast and accurate identification of the RGVP from dMRI tractography data. We design a novel microstructure-informed supervised contrastive learning method that leverages both streamline label and tissue microstructure information to determine positive and negative pairs. We propose a simple and successful streamline-level data augmentation method to address highly imbalanced training data, where the number of RGVP streamlines is much lower than that of non-RGVP streamlines. We perform comparisons with several state-of-the-art deep learning methods that were designed for tractography parcellation, and we show superior RGVP identification results using DeepRGVP.
PAI3D: Painting Adaptive Instance-Prior for 3D Object Detection
Nov 15, 2022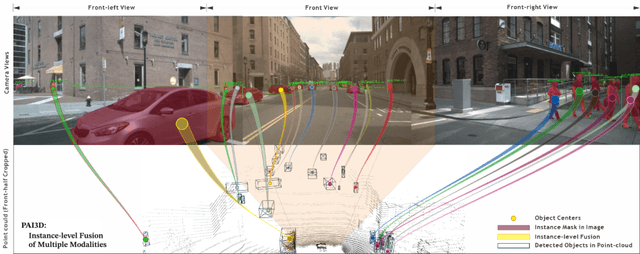
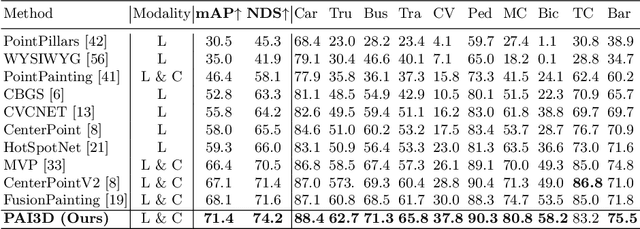
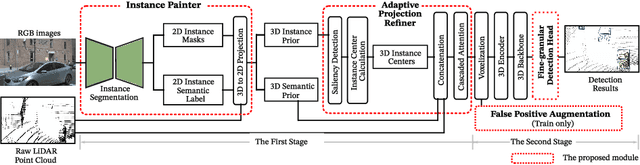
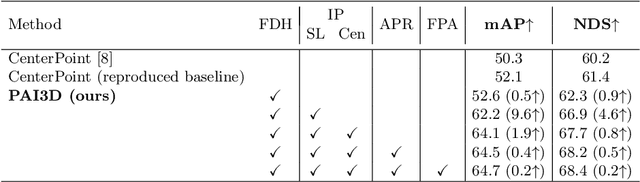
3D object detection is a critical task in autonomous driving. Recently multi-modal fusion-based 3D object detection methods, which combine the complementary advantages of LiDAR and camera, have shown great performance improvements over mono-modal methods. However, so far, no methods have attempted to utilize the instance-level contextual image semantics to guide the 3D object detection. In this paper, we propose a simple and effective Painting Adaptive Instance-prior for 3D object detection (PAI3D) to fuse instance-level image semantics flexibly with point cloud features. PAI3D is a multi-modal sequential instance-level fusion framework. It first extracts instance-level semantic information from images, the extracted information, including objects categorical label, point-to-object membership and object position, are then used to augment each LiDAR point in the subsequent 3D detection network to guide and improve detection performance. PAI3D outperforms the state-of-the-art with a large margin on the nuScenes dataset, achieving 71.4 in mAP and 74.2 in NDS on the test split. Our comprehensive experiments show that instance-level image semantics contribute the most to the performance gain, and PAI3D works well with any good-quality instance segmentation models and any modern point cloud 3D encoders, making it a strong candidate for deployment on autonomous vehicles.
Predicting Eye Gaze Location on Websites
Nov 15, 2022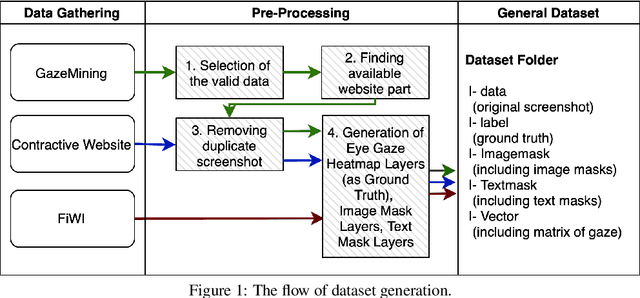
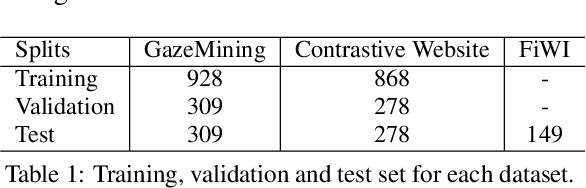
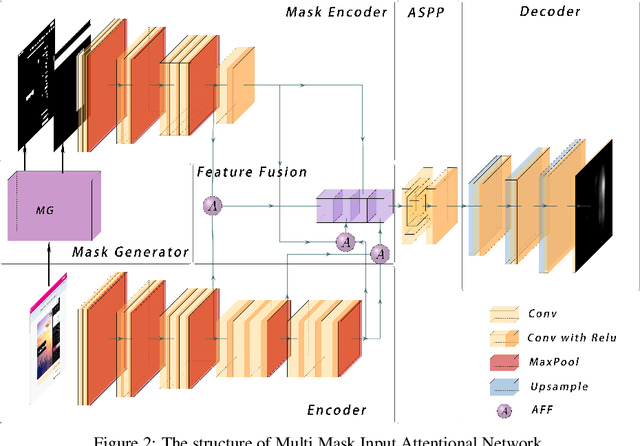
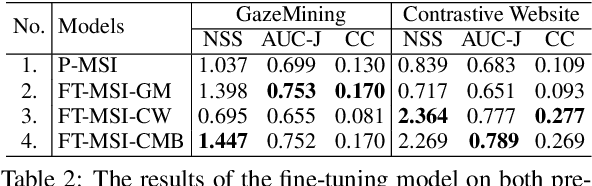
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.
PromptCAL: Contrastive Affinity Learning via Auxiliary Prompts for Generalized Novel Category Discovery
Dec 11, 2022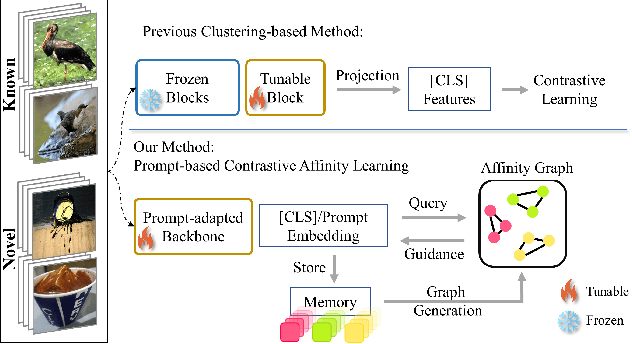
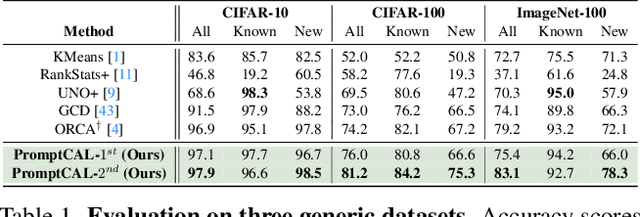
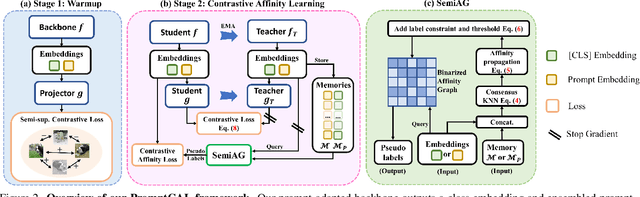
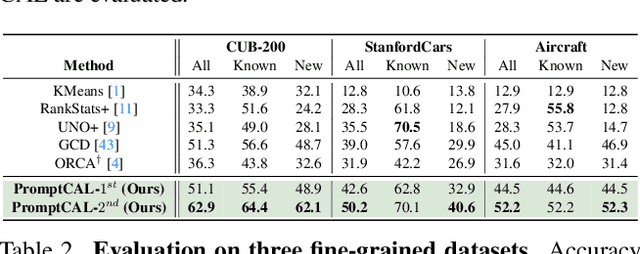
Although existing semi-supervised learning models achieve remarkable success in learning with unannotated in-distribution data, they mostly fail to learn on unlabeled data sampled from novel semantic classes due to their closed-set assumption. In this work, we target a pragmatic but under-explored Generalized Novel Category Discovery (GNCD) setting. The GNCD setting aims to categorize unlabeled training data coming from known and novel classes by leveraging the information of partially labeled known classes. We propose a two-stage Contrastive Affinity Learning method with auxiliary visual Prompts, dubbed PromptCAL, to address this challenging problem. Our approach discovers reliable pairwise sample affinities to learn better semantic clustering of both known and novel classes for the class token and visual prompts. First, we propose a discriminative prompt regularization loss to reinforce semantic discriminativeness of prompt-adapted pre-trained vision transformer for refined affinity relationships. Besides, we propose a contrastive affinity learning stage to calibrate semantic representations based on our iterative semi-supervised affinity graph generation method for semantically-enhanced prompt supervision. Extensive experimental evaluation demonstrates that our PromptCAL method is more effective in discovering novel classes even with limited annotations and surpasses the current state-of-the-art on generic and fine-grained benchmarks (with nearly $11\%$ gain on CUB-200, and $9\%$ on ImageNet-100) on overall accuracy.
A PINN Approach to Symbolic Differential Operator Discovery with Sparse Data
Dec 09, 2022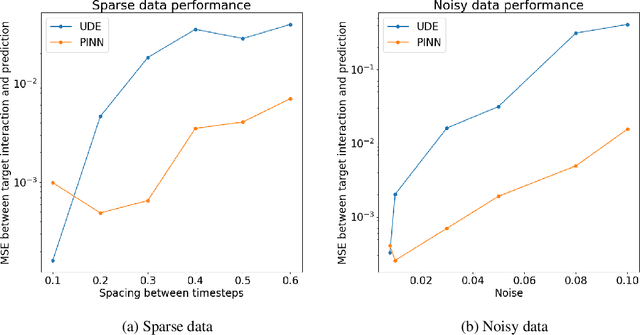
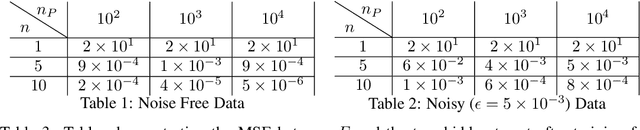
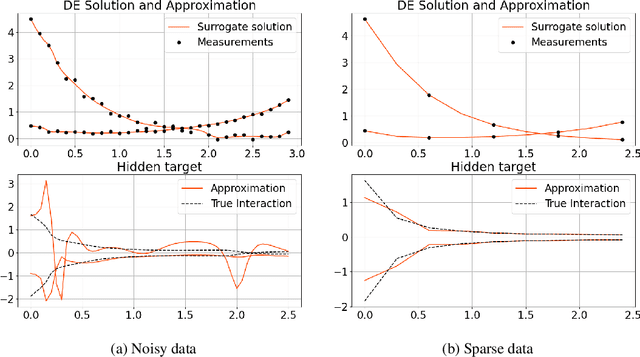
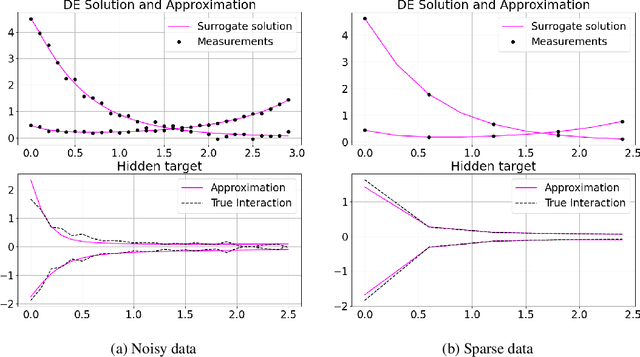
Given ample experimental data from a system governed by differential equations, it is possible to use deep learning techniques to construct the underlying differential operators. In this work we perform symbolic discovery of differential operators in a situation where there is sparse experimental data. This small data regime in machine learning can be made tractable by providing our algorithms with prior information about the underlying dynamics. Physics Informed Neural Networks (PINNs) have been very successful in this regime (reconstructing entire ODE solutions using only a single point or entire PDE solutions with very few measurements of the initial condition). We modify the PINN approach by adding a neural network that learns a representation of unknown hidden terms in the differential equation. The algorithm yields both a surrogate solution to the differential equation and a black-box representation of the hidden terms. These hidden term neural networks can then be converted into symbolic equations using symbolic regression techniques like AI Feynman. In order to achieve convergence of these neural networks, we provide our algorithms with (noisy) measurements of both the initial condition as well as (synthetic) experimental data obtained at later times. We demonstrate strong performance of this approach even when provided with very few measurements of noisy data in both the ODE and PDE regime.
4K-NeRF: High Fidelity Neural Radiance Fields at Ultra High Resolutions
Dec 09, 2022

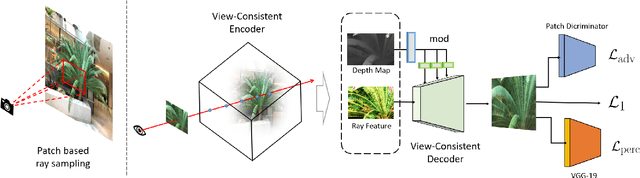
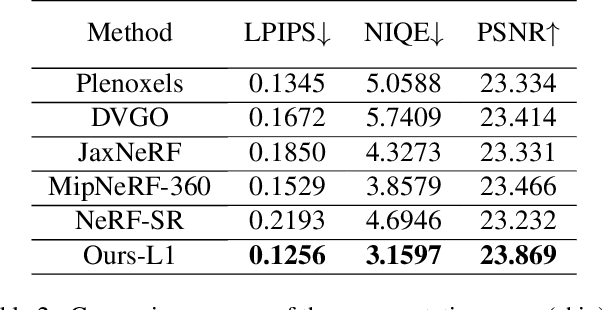
In this paper, we present a novel and effective framework, named 4K-NeRF, to pursue high fidelity view synthesis on the challenging scenarios of ultra high resolutions, building on the methodology of neural radiance fields (NeRF). The rendering procedure of NeRF-based methods typically relies on a pixel wise manner in which rays (or pixels) are treated independently on both training and inference phases, limiting its representational ability on describing subtle details especially when lifting to a extremely high resolution. We address the issue by better exploring ray correlation for enhancing high-frequency details benefiting from the use of geometry-aware local context. Particularly, we use the view-consistent encoder to model geometric information effectively in a lower resolution space and recover fine details through the view-consistent decoder, conditioned on ray features and depths estimated by the encoder. Joint training with patch-based sampling further facilitates our method incorporating the supervision from perception oriented regularization beyond pixel wise loss. Quantitative and qualitative comparisons with modern NeRF methods demonstrate that our method can significantly boost rendering quality for retaining high-frequency details, achieving the state-of-the-art visual quality on 4K ultra-high-resolution scenario. Code Available at \url{https://github.com/frozoul/4K-NeRF}
TRBLLmaker -- Transformer Reads Between Lyrics Lines maker
Dec 09, 2022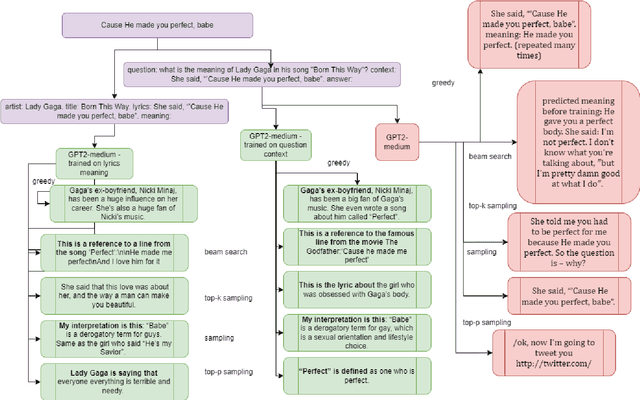
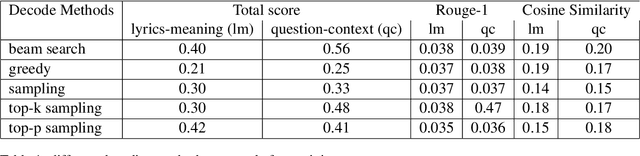
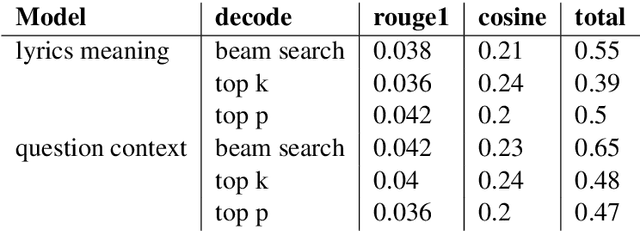
Even for us, it can be challenging to comprehend the meaning of songs. As part of this project, we explore the process of generating the meaning of songs. Despite the widespread use of text-to-text models, few attempts have been made to achieve a similar objective. Songs are primarily studied in the context of sentiment analysis. This involves identifying opinions and emotions in texts, evaluating them as positive or negative, and utilizing these evaluations to make music recommendations. In this paper, we present a generative model that offers implicit meanings for several lines of a song. Our model uses a decoder Transformer architecture GPT-2, where the input is the lyrics of a song. Furthermore, we compared the performance of this architecture with that of the encoder-decoder Transformer architecture of the T5 model. We also examined the effect of different prompt types with the option of appending additional information, such as the name of the artist and the title of the song. Moreover, we tested different decoding methods with different training parameters and evaluated our results using ROUGE. In order to build our dataset, we utilized the 'Genious' API, which allowed us to acquire the lyrics of songs and their explanations, as well as their rich metadata.
SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
Dec 09, 2022
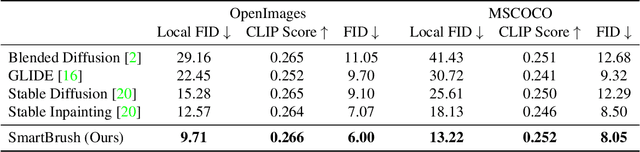
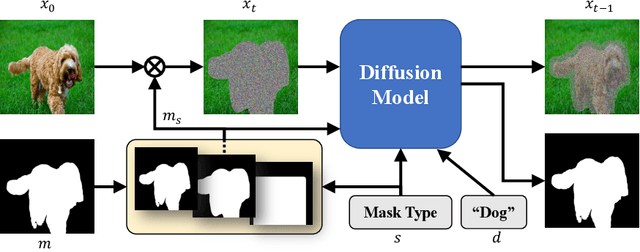
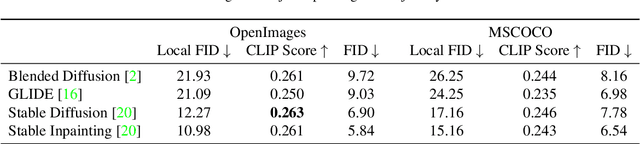
Generic image inpainting aims to complete a corrupted image by borrowing surrounding information, which barely generates novel content. By contrast, multi-modal inpainting provides more flexible and useful controls on the inpainted content, \eg, a text prompt can be used to describe an object with richer attributes, and a mask can be used to constrain the shape of the inpainted object rather than being only considered as a missing area. We propose a new diffusion-based model named SmartBrush for completing a missing region with an object using both text and shape-guidance. While previous work such as DALLE-2 and Stable Diffusion can do text-guided inapinting they do not support shape guidance and tend to modify background texture surrounding the generated object. Our model incorporates both text and shape guidance with precision control. To preserve the background better, we propose a novel training and sampling strategy by augmenting the diffusion U-net with object-mask prediction. Lastly, we introduce a multi-task training strategy by jointly training inpainting with text-to-image generation to leverage more training data. We conduct extensive experiments showing that our model outperforms all baselines in terms of visual quality, mask controllability, and background preservation.
Disparity estimation for fisheye images with an application to intermediate view synthesis
Dec 02, 2022
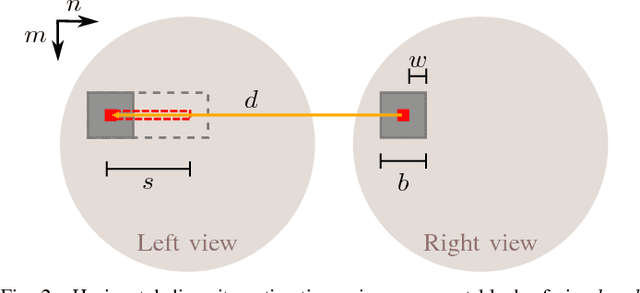
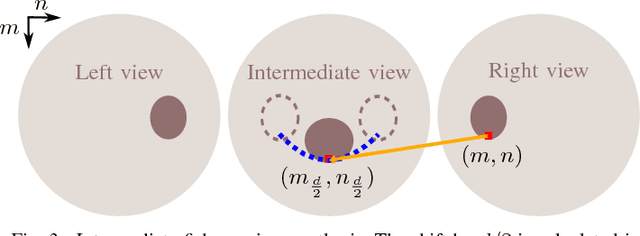

To obtain depth information from a stereo camera setup, a common way is to conduct disparity estimation between the two views; the disparity map thus generated may then also be used to synthesize arbitrary intermediate views. A straightforward approach to disparity estimation is block matching, which performs well with perspective data. When dealing with non-perspective imagery such as obtained from ultra wide-angle fisheye cameras, however, block matching meets its limits. In this paper, an adapted disparity estimation approach for fisheye images is introduced. The proposed method exploits knowledge about the fisheye projection function to transform the fisheye coordinate grid to a corresponding perspective mesh. Offsets between views can thus be determined more accurately, resulting in more reliable disparity maps. By re-projecting the perspective mesh to the fisheye domain, the original fisheye field of view is retained. The benefit of the proposed method is demonstrated in the context of intermediate view synthesis, for which both objectively evaluated as well as visually convincing results are provided.
A Multi-Stream Fusion Network for Image Splicing Localization
Dec 02, 2022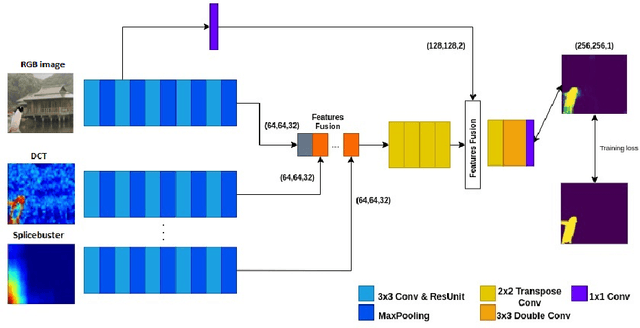
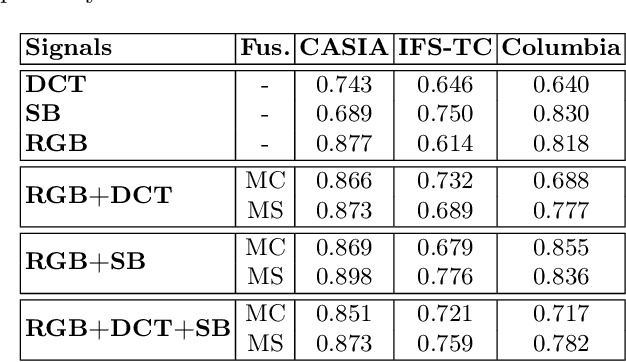
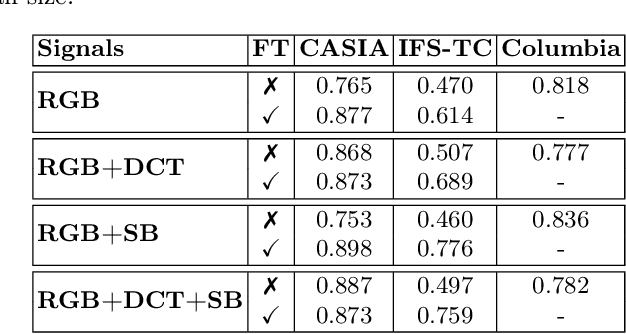

In this paper, we address the problem of image splicing localization with a multi-stream network architecture that processes the raw RGB image in parallel with other handcrafted forensic signals. Unlike previous methods that either use only the RGB images or stack several signals in a channel-wise manner, we propose an encoder-decoder architecture that consists of multiple encoder streams. Each stream is fed with either the tampered image or handcrafted signals and processes them separately to capture relevant information from each one independently. Finally, the extracted features from the multiple streams are fused in the bottleneck of the architecture and propagated to the decoder network that generates the output localization map. We experiment with two handcrafted algorithms, i.e., DCT and Splicebuster. Our proposed approach is benchmarked on three public forensics datasets, demonstrating competitive performance against several competing methods and achieving state-of-the-art results, e.g., 0.898 AUC on CASIA.