 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Federated Learning for CIoT Devices in Smart Home Applications
Dec 29, 2022
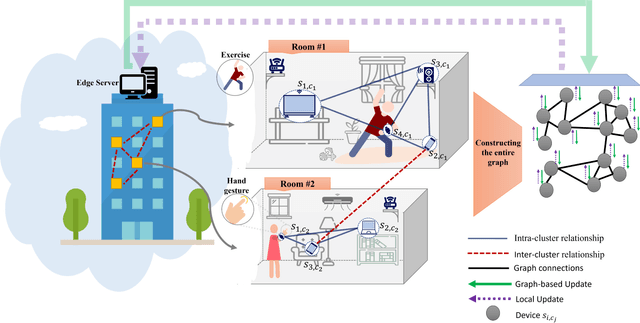
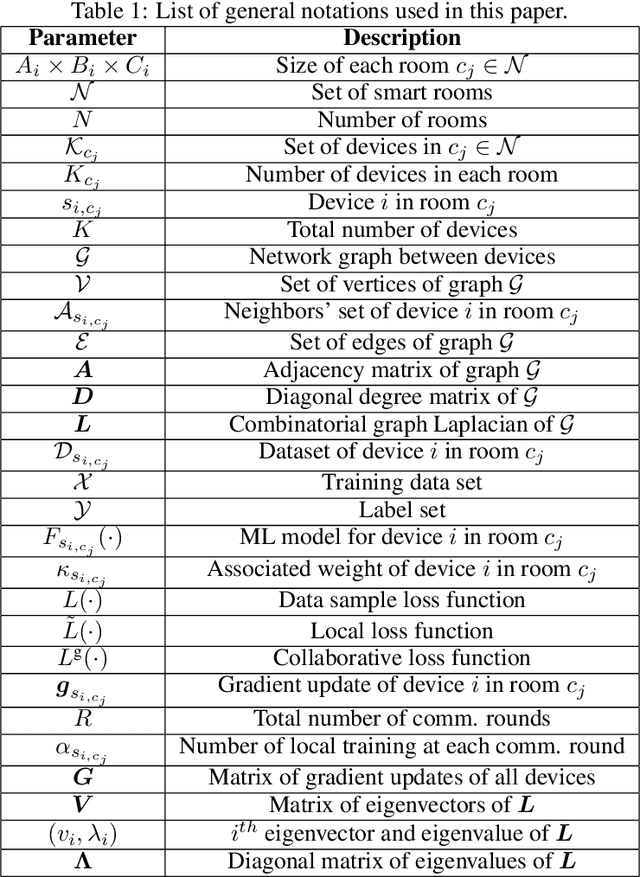
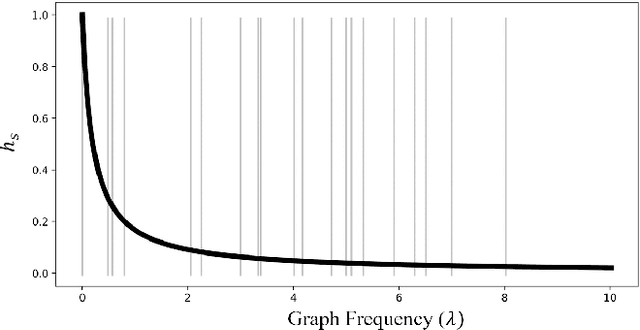
This paper deals with the problem of statistical and system heterogeneity in a cross-silo Federated Learning (FL) framework where there exist a limited number of Consumer Internet of Things (CIoT) devices in a smart building. We propose a novel Graph Signal Processing (GSP)-inspired aggregation rule based on graph filtering dubbed ``G-Fedfilt''. The proposed aggregator enables a structured flow of information based on the graph's topology. This behavior allows capturing the interconnection of CIoT devices and training domain-specific models. The embedded graph filter is equipped with a tunable parameter which enables a continuous trade-off between domain-agnostic and domain-specific FL. In the case of domain-agnostic, it forces G-Fedfilt to act similar to the conventional Federated Averaging (FedAvg) aggregation rule. The proposed G-Fedfilt also enables an intrinsic smooth clustering based on the graph connectivity without explicitly specified which further boosts the personalization of the models in the framework. In addition, the proposed scheme enjoys a communication-efficient time-scheduling to alleviate the system heterogeneity. This is accomplished by adaptively adjusting the amount of training data samples and sparsity of the models' gradients to reduce communication desynchronization and latency. Simulation results show that the proposed G-Fedfilt achieves up to $3.99\% $ better classification accuracy than the conventional FedAvg when concerning model personalization on the statistically heterogeneous local datasets, while it is capable of yielding up to $2.41\%$ higher accuracy than FedAvg in the case of testing the generalization of the models.
MagicNet: Semi-Supervised Multi-Organ Segmentation via Magic-Cube Partition and Recovery
Dec 29, 2022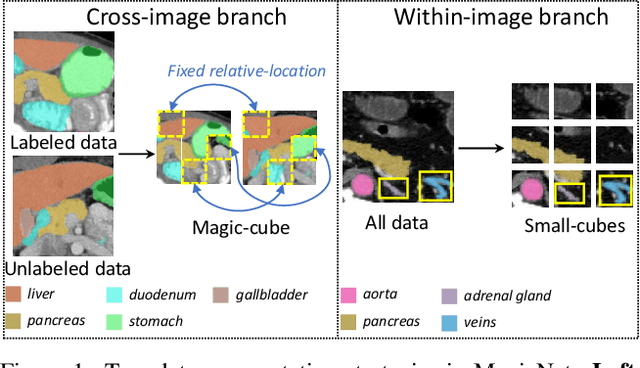
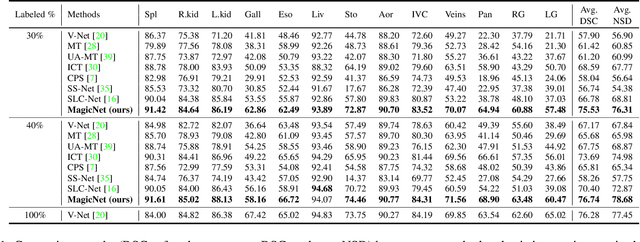
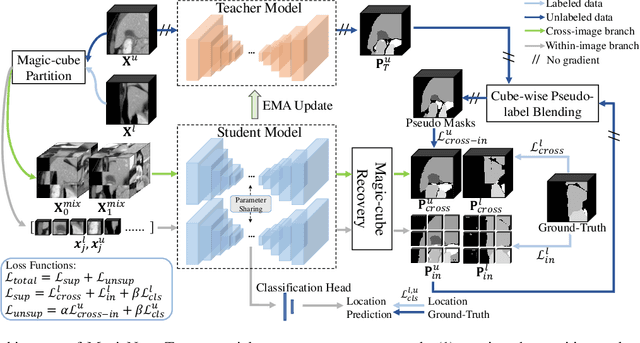
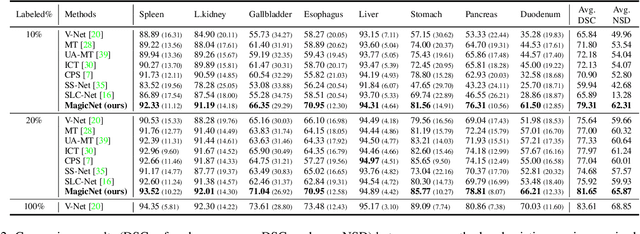
We propose a novel teacher-student model for semi-supervised multi-organ segmentation. In teacher-student model, data augmentation is usually adopted on unlabeled data to regularize the consistent training between teacher and student. We start from a key perspective that fixed relative locations and variable sizes of different organs can provide distribution information where a multi-organ CT scan is drawn. Thus, we treat the prior anatomy as a strong tool to guide the data augmentation and reduce the mismatch between labeled and unlabeled images for semi-supervised learning. More specifically, we propose a data augmentation strategy based on partition-and-recovery N$^3$ cubes cross- and within- labeled and unlabeled images. Our strategy encourages unlabeled images to learn organ semantics in relative locations from the labeled images (cross-branch) and enhances the learning ability for small organs (within-branch). For within-branch, we further propose to refine the quality of pseudo labels by blending the learned representations from small cubes to incorporate local attributes. Our method is termed as MagicNet, since it treats the CT volume as a magic-cube and $N^3$-cube partition-and-recovery process matches with the rule of playing a magic-cube. Extensive experiments on two public CT multi-organ datasets demonstrate the effectiveness of MagicNet, and noticeably outperforms state-of-the-art semi-supervised medical image segmentation approaches, with +7% DSC improvement on MACT dataset with 10% labeled images.
Bi-objective Optimization of Information Rate and Harvested Power in RIS-aided SWIPT Systems
Apr 24, 2022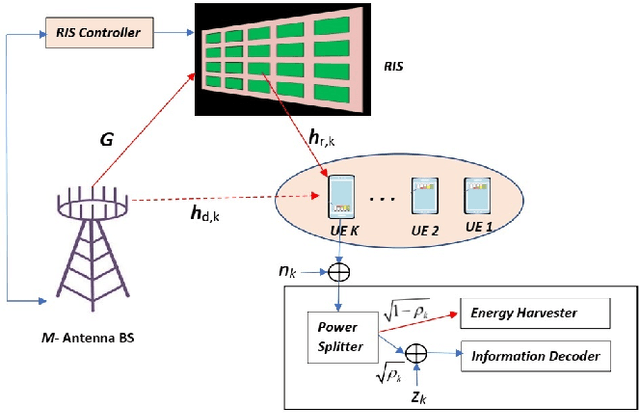
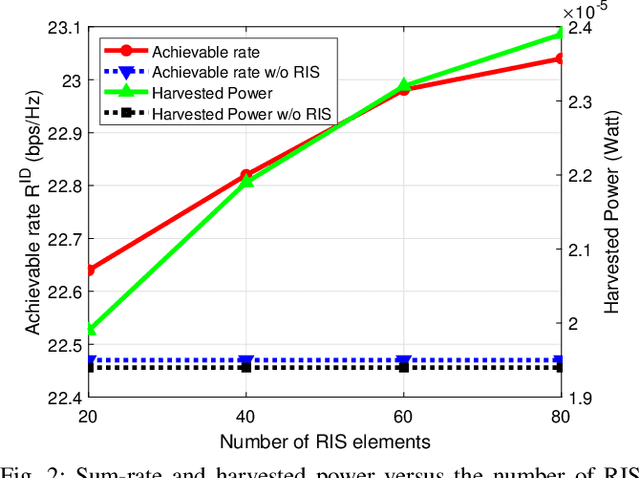
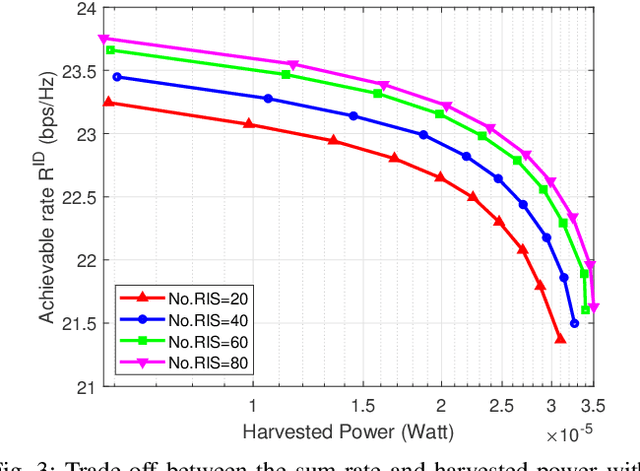
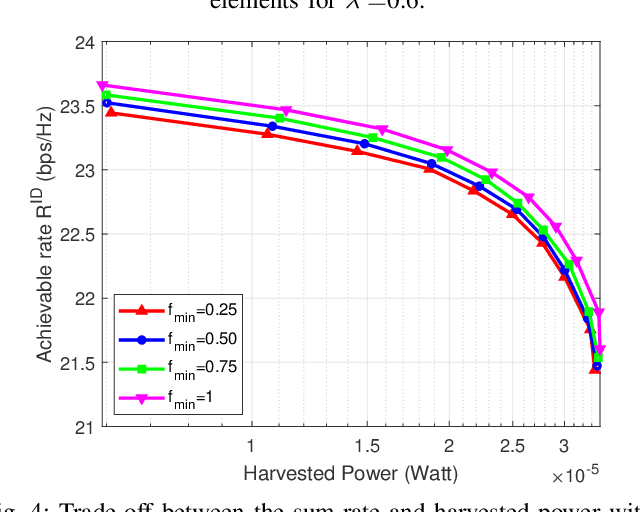
The problem of simultaneously optimizing the information rate and the harvested power in a reconfigurable intelligent surface (RIS)-aided multiple-input single-output downlink wireless network with simultaneous wireless information and power transfer (SWIPT) is addressed. The beamforming vectors, RIS reflection coefficients, and power split ratios are jointly optimized subject to maximum power constraints, minimum harvested power constraints, and realistic constraints on the RIS reflection coefficients. A practical algorithm is developed through an interplay of alternating optimization, sequential optimization, and pricing-based methods. Numerical results show that the deployment of RISs can significantly improve the information rate and the amount of harvested power.
More Generalized and Personalized Unsupervised Representation Learning In A Distributed System
Nov 11, 2022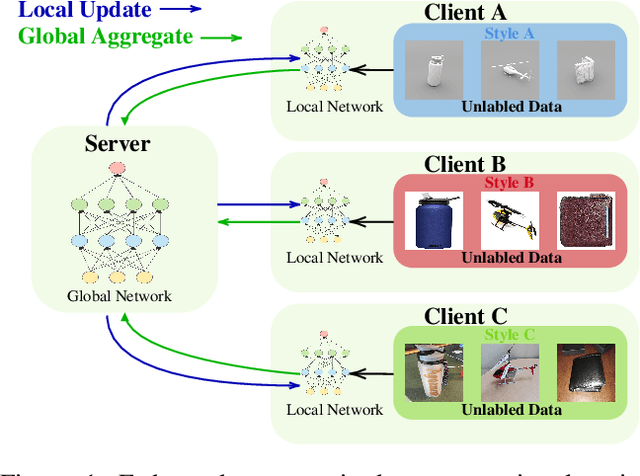
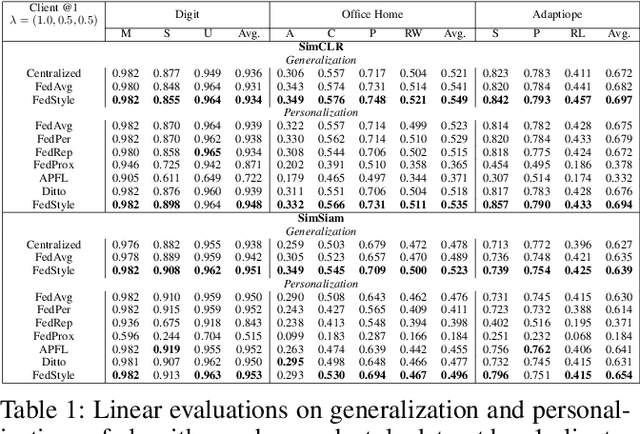
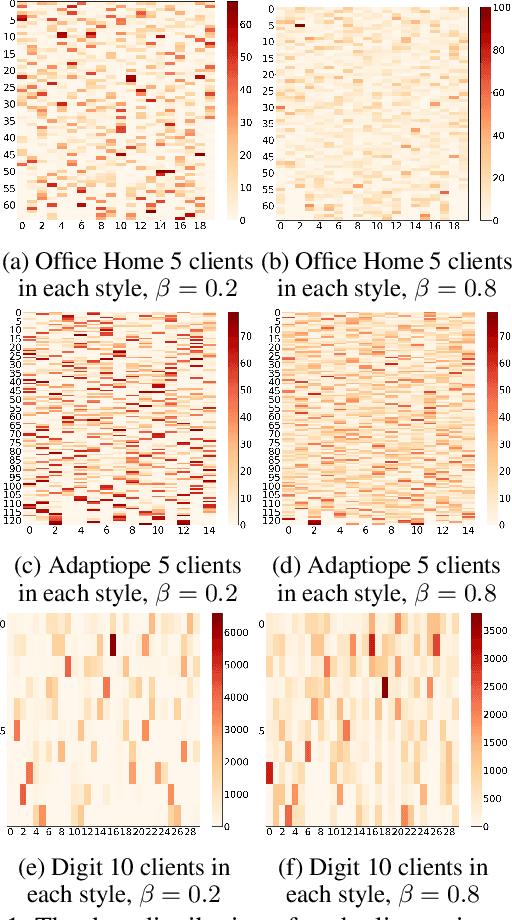
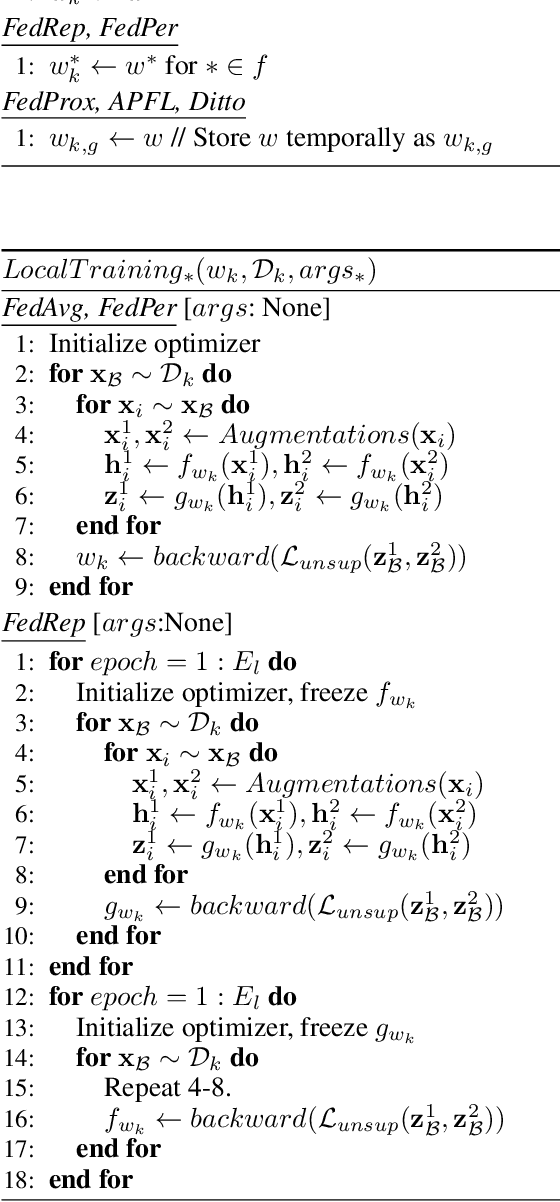
Discriminative unsupervised learning methods such as contrastive learning have demonstrated the ability to learn generalized visual representations on centralized data. It is nonetheless challenging to adapt such methods to a distributed system with unlabeled, private, and heterogeneous client data due to user styles and preferences. Federated learning enables multiple clients to collectively learn a global model without provoking any privacy breach between local clients. On the other hand, another direction of federated learning studies personalized methods to address the local heterogeneity. However, work on solving both generalization and personalization without labels in a decentralized setting remains unfamiliar. In this work, we propose a novel method, FedStyle, to learn a more generalized global model by infusing local style information with local content information for contrastive learning, and to learn more personalized local models by inducing local style information for downstream tasks. The style information is extracted by contrasting original local data with strongly augmented local data (Sobel filtered images). Through extensive experiments with linear evaluations in both IID and non-IID settings, we demonstrate that FedStyle outperforms both the generalization baseline methods and personalization baseline methods in a stylized decentralized setting. Through comprehensive ablations, we demonstrate our design of style infusion and stylized personalization improve performance significantly.
A Light Touch Approach to Teaching Transformers Multi-view Geometry
Nov 28, 2022
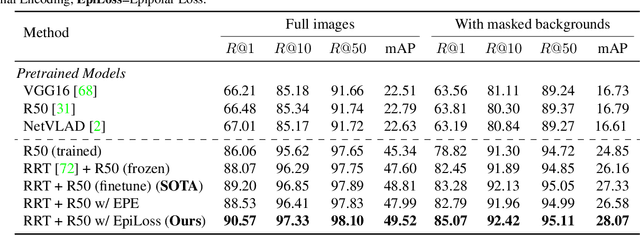
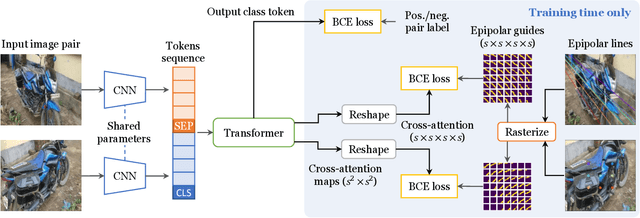
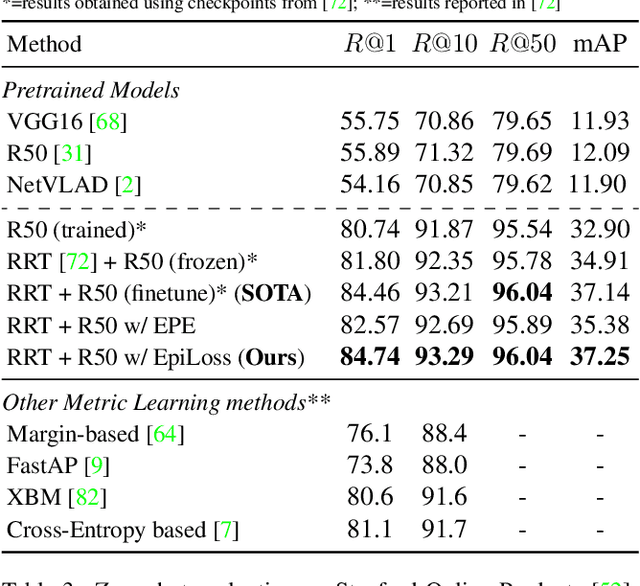
Transformers are powerful visual learners, in large part due to their conspicuous lack of manually-specified priors. This flexibility can be problematic in tasks that involve multiple-view geometry, due to the near-infinite possible variations in 3D shapes and viewpoints (requiring flexibility), and the precise nature of projective geometry (obeying rigid laws). To resolve this conundrum, we propose a "light touch" approach, guiding visual Transformers to learn multiple-view geometry but allowing them to break free when needed. We achieve this by using epipolar lines to guide the Transformer's cross-attention maps, penalizing attention values outside the epipolar lines and encouraging higher attention along these lines since they contain geometrically plausible matches. Unlike previous methods, our proposal does not require any camera pose information at test-time. We focus on pose-invariant object instance retrieval, where standard Transformer networks struggle, due to the large differences in viewpoint between query and retrieved images. Experimentally, our method outperforms state-of-the-art approaches at object retrieval, without needing pose information at test-time.
Arguments to Key Points Mapping with Prompt-based Learning
Nov 28, 2022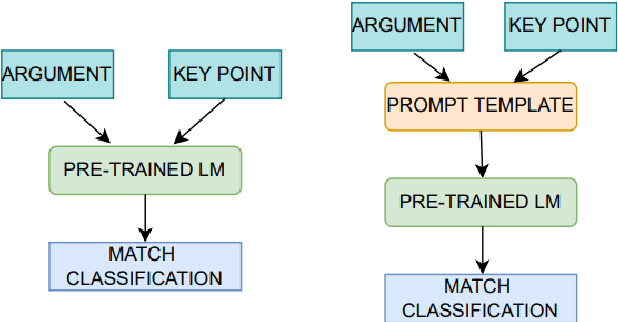

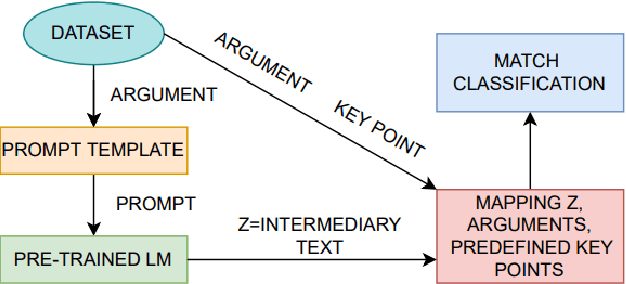
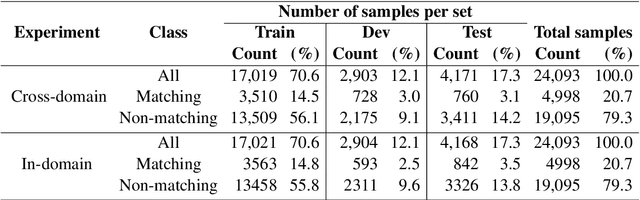
Handling and digesting a huge amount of information in an efficient manner has been a long-term demand in modern society. Some solutions to map key points (short textual summaries capturing essential information and filtering redundancies) to a large number of arguments/opinions have been provided recently (Bar-Haim et al., 2020). To complement the full picture of the argument-to-keypoint mapping task, we mainly propose two approaches in this paper. The first approach is to incorporate prompt engineering for fine-tuning the pre-trained language models (PLMs). The second approach utilizes prompt-based learning in PLMs to generate intermediary texts, which are then combined with the original argument-keypoint pairs and fed as inputs to a classifier, thereby mapping them. Furthermore, we extend the experiments to cross/in-domain to conduct an in-depth analysis. In our evaluation, we find that i) using prompt engineering in a more direct way (Approach 1) can yield promising results and improve the performance; ii) Approach 2 performs considerably worse than Approach 1 due to the negation issue of the PLM.
Beyond Contrastive Learning: A Variational Generative Model for Multilingual Retrieval
Dec 21, 2022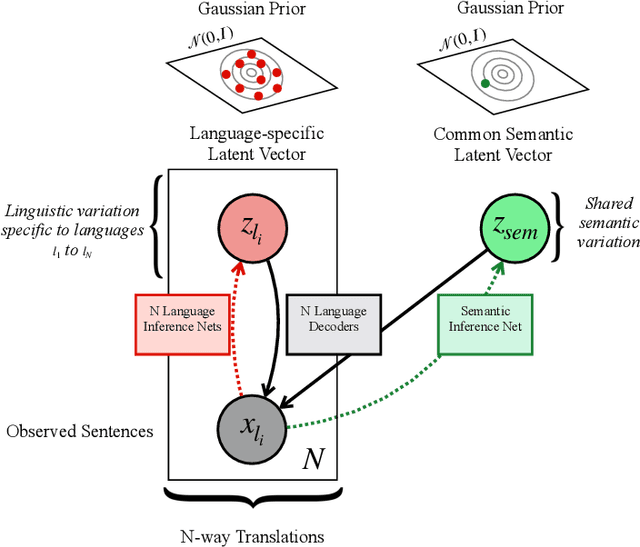

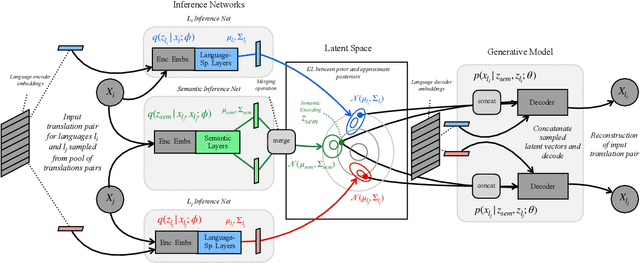
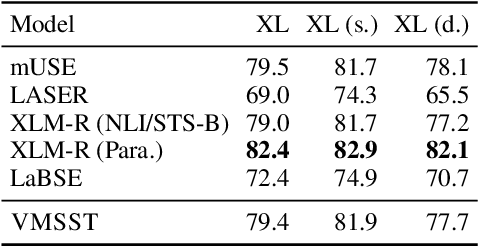
Contrastive learning has been successfully used for retrieval of semantically aligned sentences, but it often requires large batch sizes or careful engineering to work well. In this paper, we instead propose a generative model for learning multilingual text embeddings which can be used to retrieve or score sentence pairs. Our model operates on parallel data in $N$ languages and, through an approximation we introduce, efficiently encourages source separation in this multilingual setting, separating semantic information that is shared between translations from stylistic or language-specific variation. We show careful large-scale comparisons between contrastive and generation-based approaches for learning multilingual text embeddings, a comparison that has not been done to the best of our knowledge despite the popularity of these approaches. We evaluate this method on a suite of tasks including semantic similarity, bitext mining, and cross-lingual question retrieval -- the last of which we introduce in this paper. Overall, our Variational Multilingual Source-Separation Transformer (VMSST) model outperforms both a strong contrastive and generative baseline on these tasks.
SMSMix: Sense-Maintained Sentence Mixup for Word Sense Disambiguation
Dec 21, 2022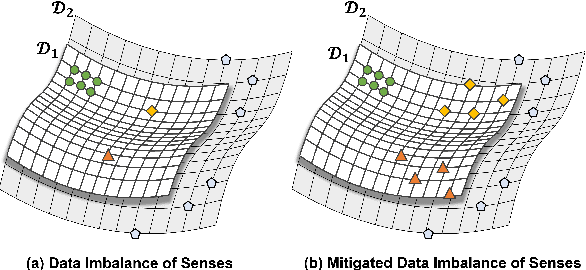
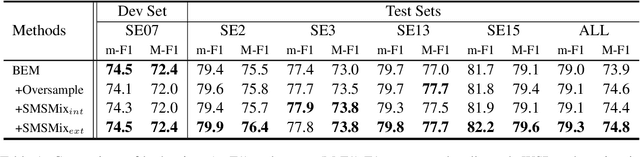

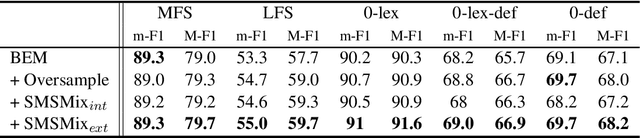
Word Sense Disambiguation (WSD) is an NLP task aimed at determining the correct sense of a word in a sentence from discrete sense choices. Although current systems have attained unprecedented performances for such tasks, the nonuniform distribution of word senses during training generally results in systems performing poorly on rare senses. To this end, we consider data augmentation to increase the frequency of these least frequent senses (LFS) to reduce the distributional bias of senses during training. We propose Sense-Maintained Sentence Mixup (SMSMix), a novel word-level mixup method that maintains the sense of a target word. SMSMix smoothly blends two sentences using mask prediction while preserving the relevant span determined by saliency scores to maintain a specific word's sense. To the best of our knowledge, this is the first attempt to apply mixup in NLP while preserving the meaning of a specific word. With extensive experiments, we validate that our augmentation method can effectively give more information about rare senses during training with maintained target sense label.
Structure-guided Image Outpainting
Dec 21, 2022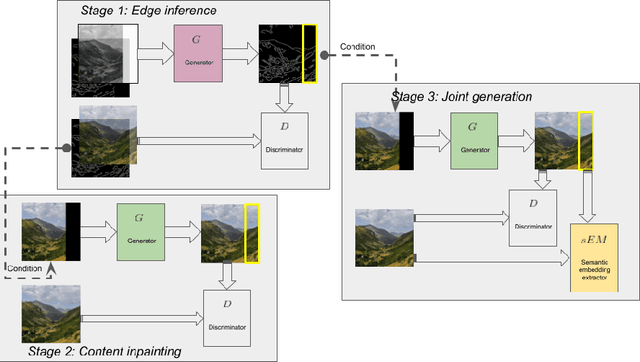
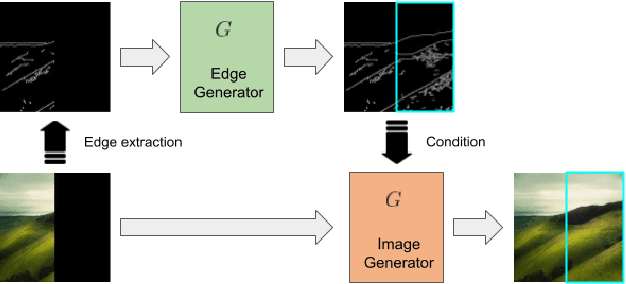


Deep learning techniques have made considerable progress in image inpainting, restoration, and reconstruction in the last few years. Image outpainting, also known as image extrapolation, lacks attention and practical approaches to be fulfilled, owing to difficulties caused by large-scale area loss and less legitimate neighboring information. These difficulties have made outpainted images handled by most of the existing models unrealistic to human eyes and spatially inconsistent. When upsampling through deconvolution to generate fake content, the naive generation methods may lead to results lacking high-frequency details and structural authenticity. Therefore, as our novelties to handle image outpainting problems, we introduce structural prior as a condition to optimize the generation quality and a new semantic embedding term to enhance perceptual sanity. we propose a deep learning method based on Generative Adversarial Network (GAN) and condition edges as structural prior in order to assist the generation. We use a multi-phase adversarial training scheme that comprises edge inference training, contents inpainting training, and joint training. The newly added semantic embedding loss is proved effective in practice.
MoQuad: Motion-focused Quadruple Construction for Video Contrastive Learning
Dec 21, 2022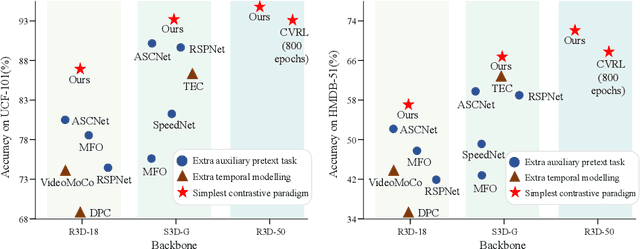
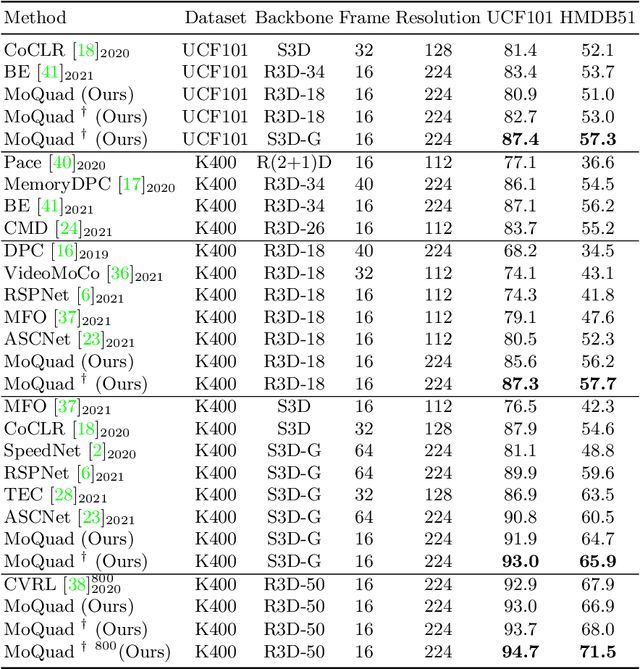
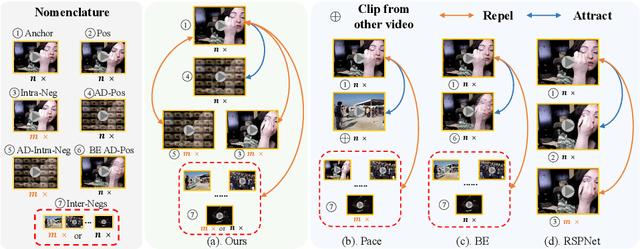
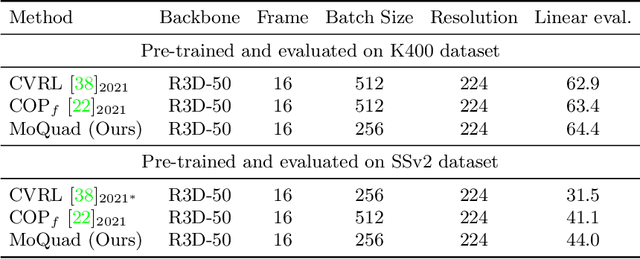
Learning effective motion features is an essential pursuit of video representation learning. This paper presents a simple yet effective sample construction strategy to boost the learning of motion features in video contrastive learning. The proposed method, dubbed Motion-focused Quadruple Construction (MoQuad), augments the instance discrimination by meticulously disturbing the appearance and motion of both the positive and negative samples to create a quadruple for each video instance, such that the model is encouraged to exploit motion information. Unlike recent approaches that create extra auxiliary tasks for learning motion features or apply explicit temporal modelling, our method keeps the simple and clean contrastive learning paradigm (i.e.,SimCLR) without multi-task learning or extra modelling. In addition, we design two extra training strategies by analyzing initial MoQuad experiments. By simply applying MoQuad to SimCLR, extensive experiments show that we achieve superior performance on downstream tasks compared to the state of the arts. Notably, on the UCF-101 action recognition task, we achieve 93.7% accuracy after pre-training the model on Kinetics-400 for only 200 epochs, surpassing various previous methods