 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CompactIE: Compact Facts in Open Information Extraction
May 05, 2022

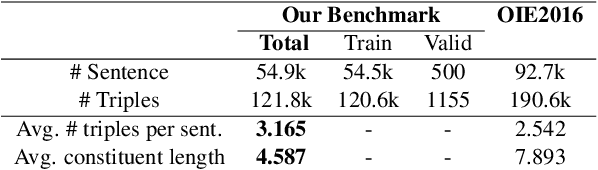
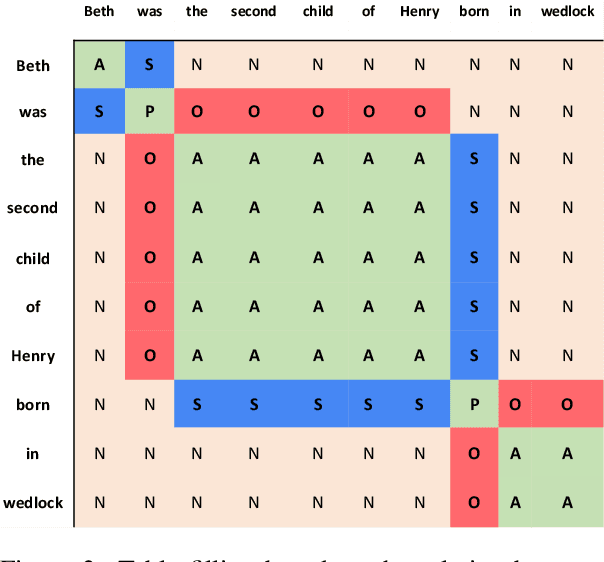

A major drawback of modern neural OpenIE systems and benchmarks is that they prioritize high coverage of information in extractions over compactness of their constituents. This severely limits the usefulness of OpenIE extractions in many downstream tasks. The utility of extractions can be improved if extractions are compact and share constituents. To this end, we study the problem of identifying compact extractions with neural-based methods. We propose CompactIE, an OpenIE system that uses a novel pipelined approach to produce compact extractions with overlapping constituents. It first detects constituents of the extractions and then links them to build extractions. We train our system on compact extractions obtained by processing existing benchmarks. Our experiments on CaRB and Wire57 datasets indicate that CompactIE finds 1.5x-2x more compact extractions than previous systems, with high precision, establishing a new state-of-the-art performance in OpenIE.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022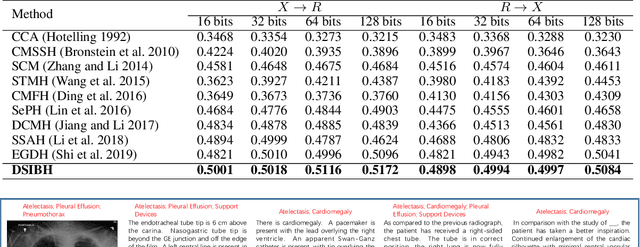
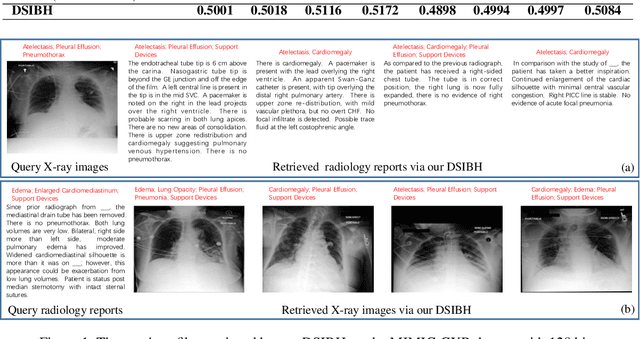
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure
Multilingual Entity and Relation Extraction from Unified to Language-specific Training
Jan 11, 2023

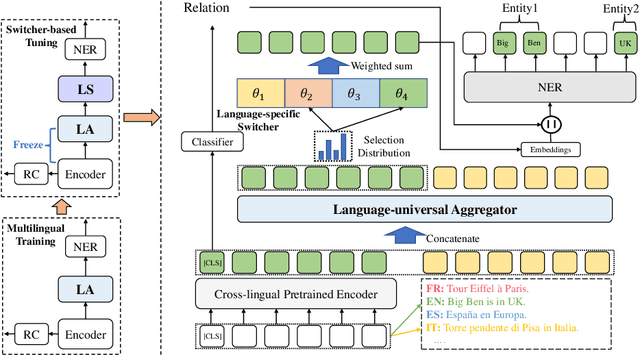
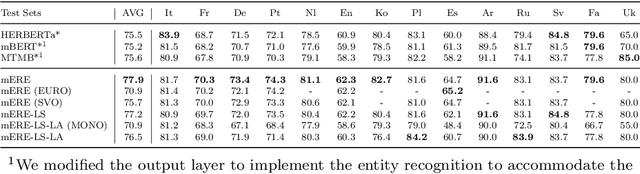
Entity and relation extraction is a key task in information extraction, where the output can be used for downstream NLP tasks. Existing approaches for entity and relation extraction tasks mainly focus on the English corpora and ignore other languages. Thus, it is critical to improving performance in a multilingual setting. Meanwhile, multilingual training is usually used to boost cross-lingual performance by transferring knowledge from languages (e.g., high-resource) to other (e.g., low-resource) languages. However, language interference usually exists in multilingual tasks as the model parameters are shared among all languages. In this paper, we propose a two-stage multilingual training method and a joint model called Multilingual Entity and Relation Extraction framework (mERE) to mitigate language interference across languages. Specifically, we randomly concatenate sentences in different languages to train a Language-universal Aggregator (LA), which narrows the distance of embedding representations by obtaining the unified language representation. Then, we separate parameters to mitigate interference via tuning a Language-specific Switcher (LS), which includes several independent sub-modules to refine the language-specific feature representation. After that, to enhance the relational triple extraction, the sentence representations concatenated with the relation feature are used to recognize the entities. Extensive experimental results show that our method outperforms both the monolingual and multilingual baseline methods. Besides, we also perform detailed analysis to show that mERE is lightweight but effective on relational triple extraction and mERE{} is easy to transfer to other backbone models of multi-field tasks, which further demonstrates the effectiveness of our method.
Head-Free Lightweight Semantic Segmentation with Linear Transformer
Jan 11, 2023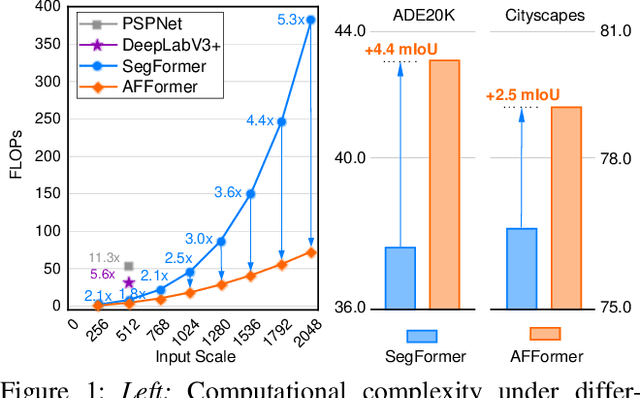
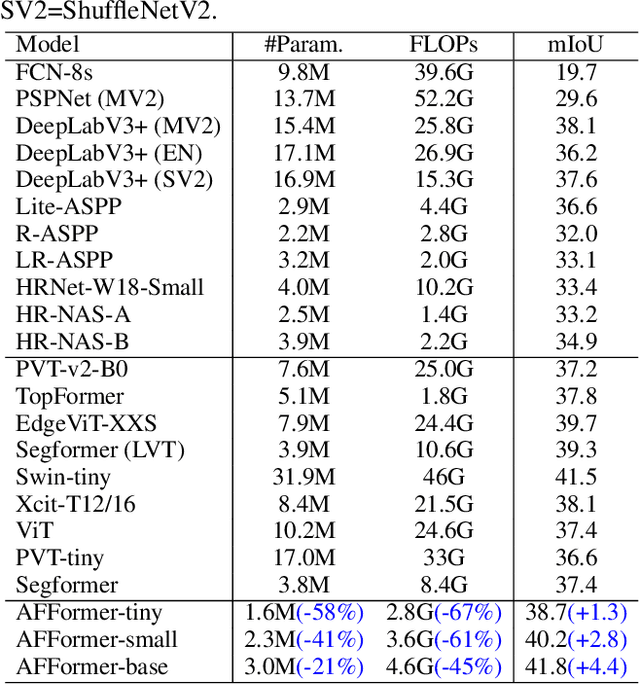
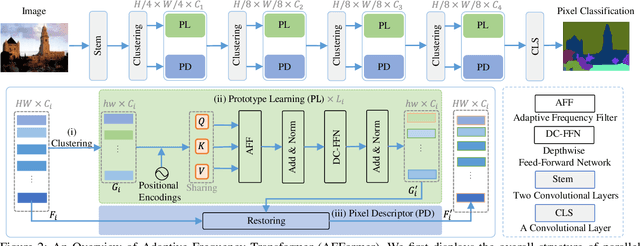

Existing semantic segmentation works have been mainly focused on designing effective decoders; however, the computational load introduced by the overall structure has long been ignored, which hinders their applications on resource-constrained hardwares. In this paper, we propose a head-free lightweight architecture specifically for semantic segmentation, named Adaptive Frequency Transformer. It adopts a parallel architecture to leverage prototype representations as specific learnable local descriptions which replaces the decoder and preserves the rich image semantics on high-resolution features. Although removing the decoder compresses most of the computation, the accuracy of the parallel structure is still limited by low computational resources. Therefore, we employ heterogeneous operators (CNN and Vision Transformer) for pixel embedding and prototype representations to further save computational costs. Moreover, it is very difficult to linearize the complexity of the vision Transformer from the perspective of spatial domain. Due to the fact that semantic segmentation is very sensitive to frequency information, we construct a lightweight prototype learning block with adaptive frequency filter of complexity $O(n)$ to replace standard self attention with $O(n^{2})$. Extensive experiments on widely adopted datasets demonstrate that our model achieves superior accuracy while retaining only 3M parameters. On the ADE20K dataset, our model achieves 41.8 mIoU and 4.6 GFLOPs, which is 4.4 mIoU higher than Segformer, with 45% less GFLOPs. On the Cityscapes dataset, our model achieves 78.7 mIoU and 34.4 GFLOPs, which is 2.5 mIoU higher than Segformer with 72.5% less GFLOPs. Code is available at https://github.com/dongbo811/AFFormer.
Factors other than climate change are currently more important in predicting how well fruit farms are doing financially
Jan 11, 2023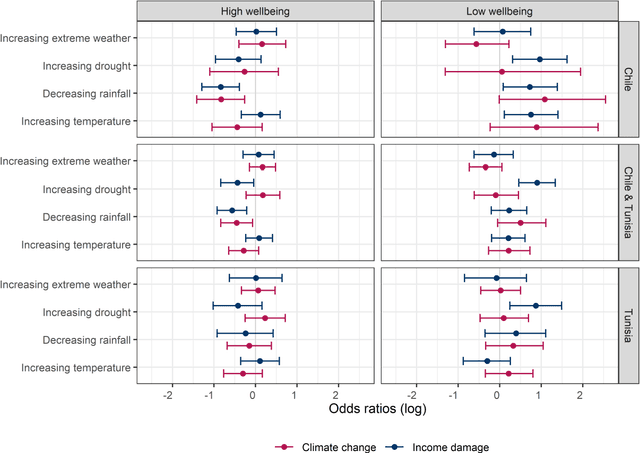
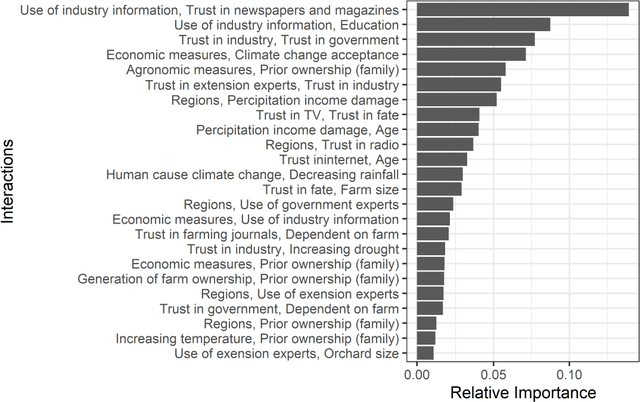
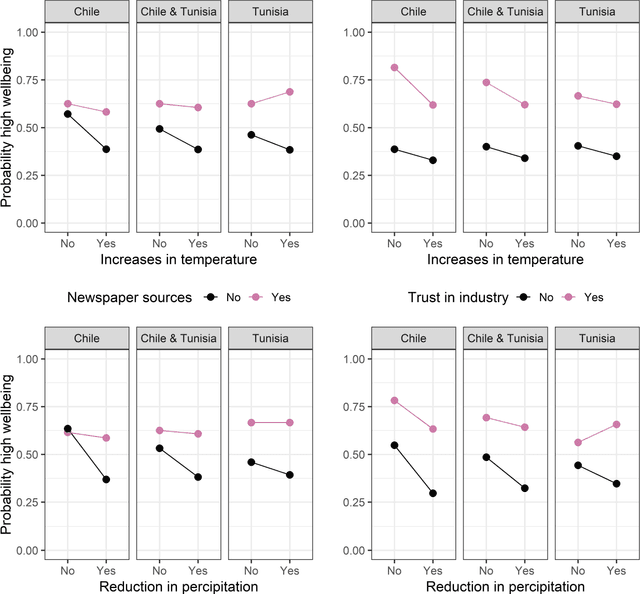
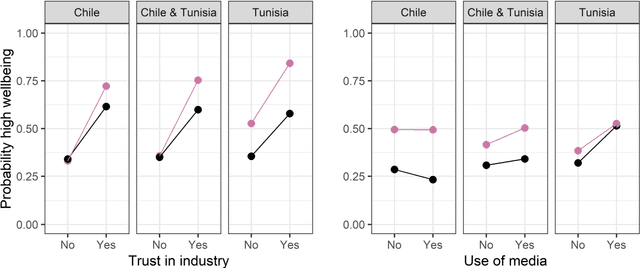
Machine learning and statistical modeling methods were used to analyze the impact of climate change on financial wellbeing of fruit farmers in Tunisia and Chile. The analysis was based on face to face interviews with 801 farmers. Three research questions were investigated. First, whether climate change impacts had an effect on how well the farm was doing financially. Second, if climate change was not influential, what factors were important for predicting financial wellbeing of the farm. And third, ascertain whether observed effects on the financial wellbeing of the farm were a result of interactions between predictor variables. This is the first report directly comparing climate change with other factors potentially impacting financial wellbeing of farms. Certain climate change factors, namely increases in temperature and reductions in precipitation, can regionally impact self-perceived financial wellbeing of fruit farmers. Specifically, increases in temperature and reduction in precipitation can have a measurable negative impact on the financial wellbeing of farms in Chile. This effect is less pronounced in Tunisia. Climate impact differences were observed within Chile but not in Tunisia. However, climate change is only of minor importance for predicting farm financial wellbeing, especially for farms already doing financially well. Factors that are more important, mainly in Tunisia, included trust in information sources and prior farm ownership. Other important factors include farm size, water management systems used and diversity of fruit crops grown. Moreover, some of the important factors identified differed between farms doing and not doing well financially. Interactions between factors may improve or worsen farm financial wellbeing.
Rho-Tau Bregman Information and the Geometry of Annealing Paths
Sep 15, 2022


Markov Chain Monte Carlo methods for sampling from complex distributions and estimating normalization constants often simulate samples from a sequence of intermediate distributions along an annealing path, which bridges between a tractable initial distribution and a target density of interest. Prior work has constructed annealing paths using quasi-arithmetic means, and interpreted the resulting intermediate densities as minimizing an expected divergence to the endpoints. We provide a comprehensive analysis of this 'centroid' property using Bregman divergences under a monotonic embedding of the density function, thereby associating common divergences such as Amari's and Renyi's ${\alpha}$-divergences, ${(\alpha,\beta)}$-divergences, and the Jensen-Shannon divergence with intermediate densities along an annealing path. Our analysis highlights the interplay between parametric families, quasi-arithmetic means, and divergence functions using the rho-tau Bregman divergence framework of Zhang 2004;2013.
Towards Sequence Utility Maximization under Utility Occupancy Measure
Dec 20, 2022

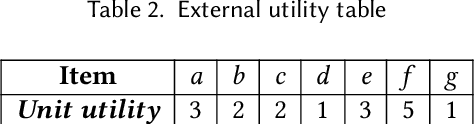

The discovery of utility-driven patterns is a useful and difficult research topic. It can extract significant and interesting information from specific and varied databases, increasing the value of the services provided. In practice, the measure of utility is often used to demonstrate the importance, profit, or risk of an object or a pattern. In the database, although utility is a flexible criterion for each pattern, it is a more absolute criterion due to the neglect of utility sharing. This leads to the derived patterns only exploring partial and local knowledge from a database. Utility occupancy is a recently proposed model that considers the problem of mining with high utility but low occupancy. However, existing studies are concentrated on itemsets that do not reveal the temporal relationship of object occurrences. Therefore, this paper towards sequence utility maximization. We first define utility occupancy on sequence data and raise the problem of High Utility-Occupancy Sequential Pattern Mining (HUOSPM). Three dimensions, including frequency, utility, and occupancy, are comprehensively evaluated in HUOSPM. An algorithm called Sequence Utility Maximization with Utility occupancy measure (SUMU) is proposed. Furthermore, two data structures for storing related information about a pattern, Utility-Occupancy-List-Chain (UOL-Chain) and Utility-Occupancy-Table (UO-Table) with six associated upper bounds, are designed to improve efficiency. Empirical experiments are carried out to evaluate the novel algorithm's efficiency and effectiveness. The influence of different upper bounds and pruning strategies is analyzed and discussed. The comprehensive results suggest that the work of our algorithm is intelligent and effective.
MDL-based Compressing Sequential Rules
Dec 20, 2022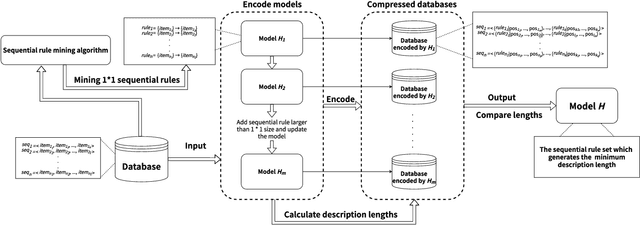
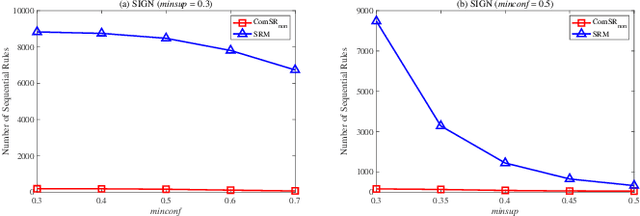
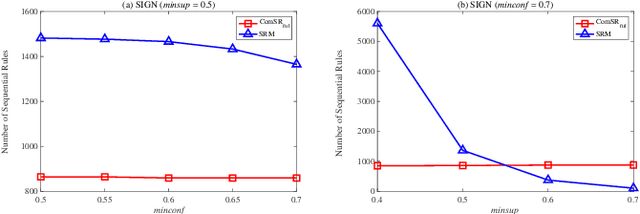
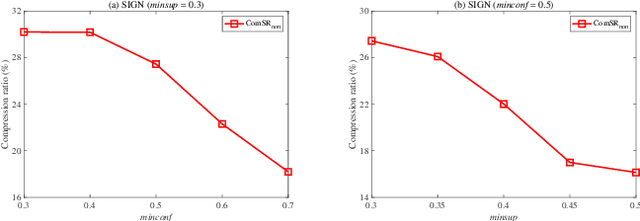
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
MINTIME: Multi-Identity Size-Invariant Video Deepfake Detection
Dec 07, 2022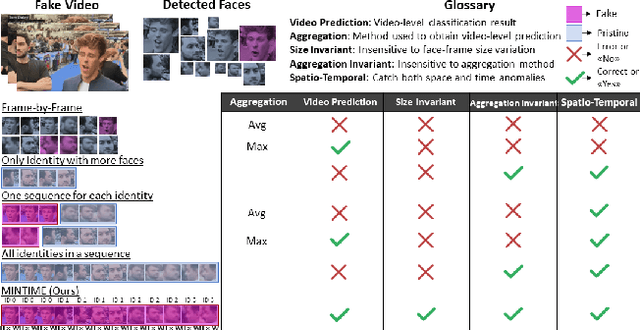
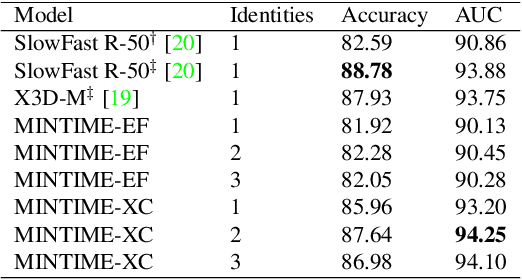
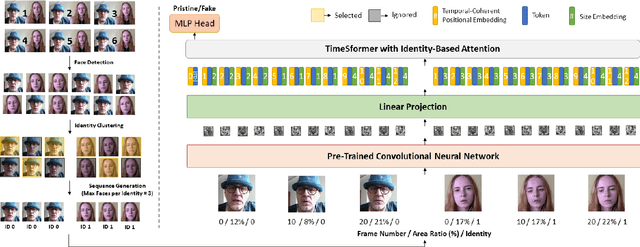

In this paper, we introduce MINTIME, a video deepfake detection approach that captures spatial and temporal anomalies and handles instances of multiple people in the same video and variations in face sizes. Previous approaches disregard such information either by using simple a-posteriori aggregation schemes, i.e., average or max operation, or using only one identity for the inference, i.e., the largest one. On the contrary, the proposed approach builds on a Spatio-Temporal TimeSformer combined with a Convolutional Neural Network backbone to capture spatio-temporal anomalies from the face sequences of multiple identities depicted in a video. This is achieved through an Identity-aware Attention mechanism that attends to each face sequence independently based on a masking operation and facilitates video-level aggregation. In addition, two novel embeddings are employed: (i) the Temporal Coherent Positional Embedding that encodes each face sequence's temporal information and (ii) the Size Embedding that encodes the size of the faces as a ratio to the video frame size. These extensions allow our system to adapt particularly well in the wild by learning how to aggregate information of multiple identities, which is usually disregarded by other methods in the literature. It achieves state-of-the-art results on the ForgeryNet dataset with an improvement of up to 14% AUC in videos containing multiple people and demonstrates ample generalization capabilities in cross-forgery and cross-dataset settings. The code is publicly available at https://github.com/davide-coccomini/MINTIME-Multi-Identity-size-iNvariant-TIMEsformer-for-Video-Deepfake-Detection.
Causal Disentanglement with Network Information for Debiased Recommendations
Apr 14, 2022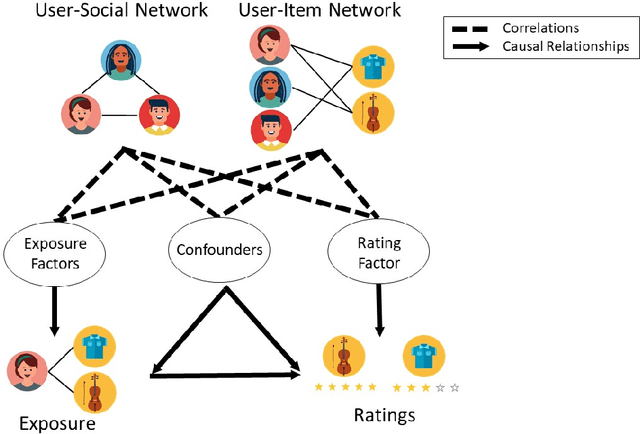
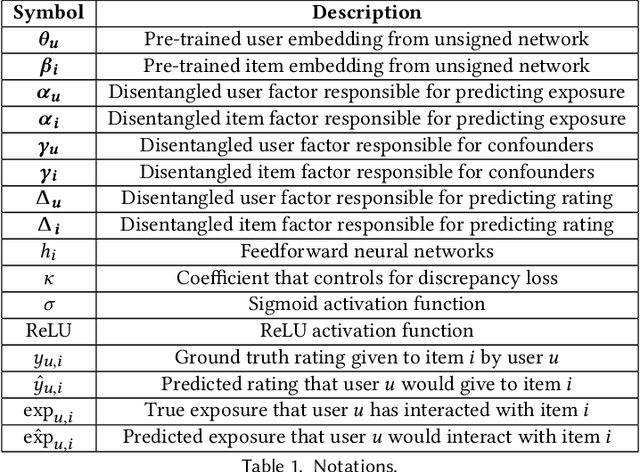
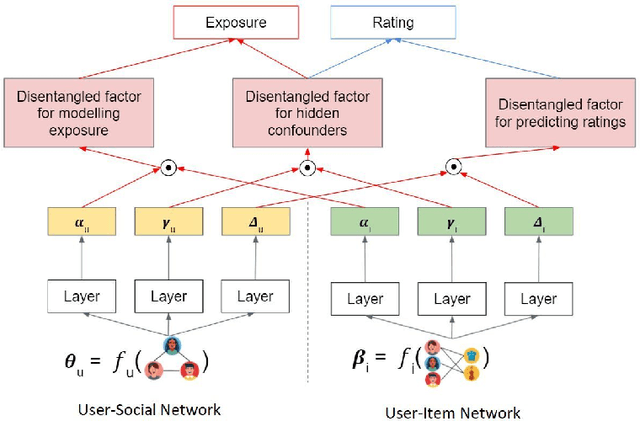

Recommender systems aim to recommend new items to users by learning user and item representations. In practice, these representations are highly entangled as they consist of information about multiple factors, including user's interests, item attributes along with confounding factors such as user conformity, and item popularity. Considering these entangled representations for inferring user preference may lead to biased recommendations (e.g., when the recommender model recommends popular items even if they do not align with the user's interests). Recent research proposes to debias by modeling a recommender system from a causal perspective. The exposure and the ratings are analogous to the treatment and the outcome in the causal inference framework, respectively. The critical challenge in this setting is accounting for the hidden confounders. These confounders are unobserved, making it hard to measure them. On the other hand, since these confounders affect both the exposure and the ratings, it is essential to account for them in generating debiased recommendations. To better approximate hidden confounders, we propose to leverage network information (i.e., user-social and user-item networks), which are shown to influence how users discover and interact with an item. Aside from the user conformity, aspects of confounding such as item popularity present in the network information is also captured in our method with the aid of \textit{causal disentanglement} which unravels the learned representations into independent factors that are responsible for (a) modeling the exposure of an item to the user, (b) predicting the ratings, and (c) controlling the hidden confounders. Experiments on real-world datasets validate the effectiveness of the proposed model for debiasing recommender systems.