 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inverse Quantum Fourier Transform Inspired Algorithm for Unsupervised Image Segmentation
Jan 11, 2023
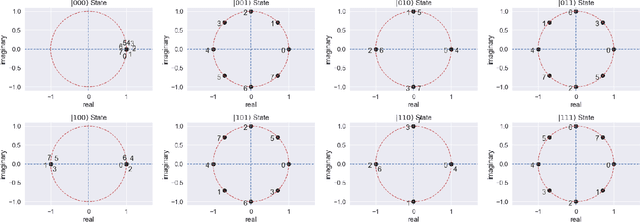

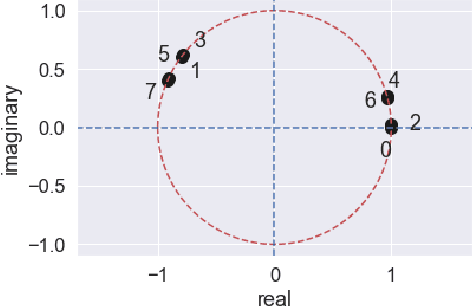
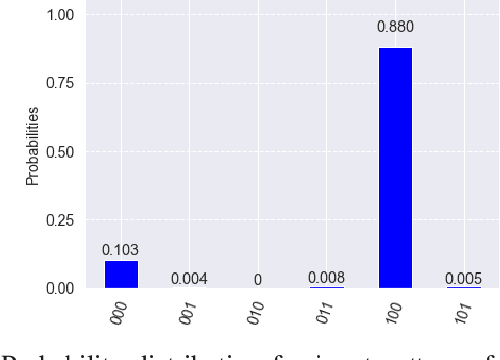
Image segmentation is a very popular and important task in computer vision. In this paper, inverse quantum Fourier transform (IQFT) for image segmentation has been explored and a novel IQFT-inspired algorithm is proposed and implemented by leveraging the underlying mathematical structure of the IQFT. Specifically, the proposed method takes advantage of the phase information of the pixels in the image by encoding the pixels' intensity into qubit relative phases and applying IQFT to classify the pixels into different segments automatically and efficiently. To the best of our knowledge, this is the first attempt of using IQFT for unsupervised image segmentation. The proposed method has low computational cost comparing to the deep learning-based methods and more importantly it does not require training, thus make it suitable for real-time applications. The performance of the proposed method is compared with K-means and Otsu-thresholding. The proposed method outperforms both of them on the PASCAL VOC 2012 segmentation benchmark and the xVIEW2 challenge dataset by as much as 50% in terms of mean Intersection-Over-Union (mIOU).
ODIM: an efficient method to detect outliers via inlier-memorization effect of deep generative models
Jan 11, 2023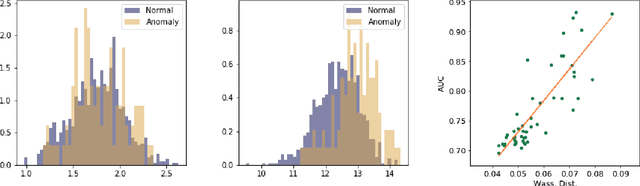
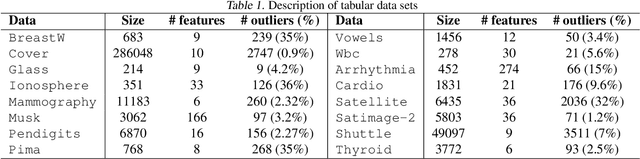
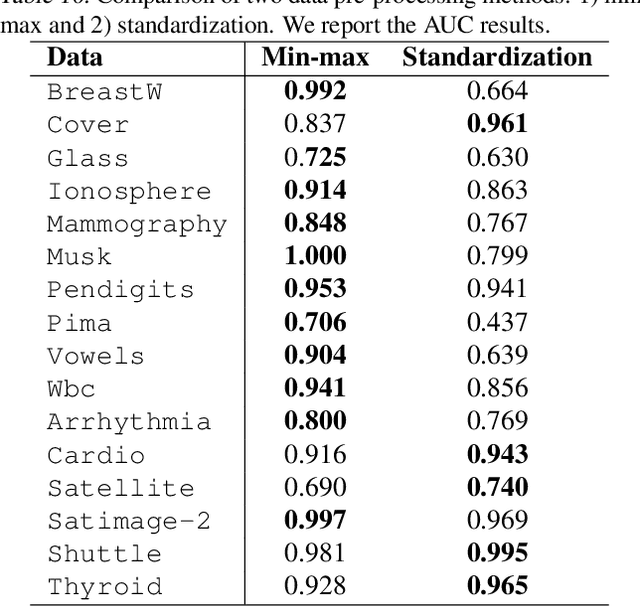
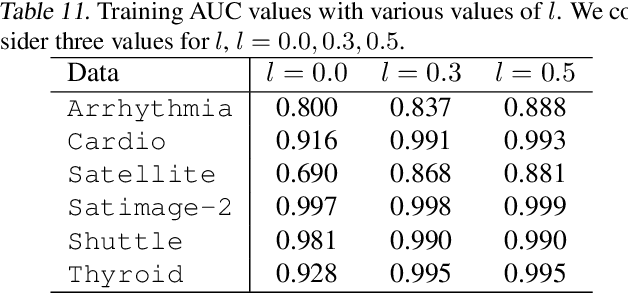
Identifying whether a given sample is an outlier or not is an important issue in various real-world domains. This study aims to solve the unsupervised outlier detection problem where training data contain outliers, but any label information about inliers and outliers is not given. We propose a powerful and efficient learning framework to identify outliers in a training data set using deep neural networks. We start with a new observation called the inlier-memorization (IM) effect. When we train a deep generative model with data contaminated with outliers, the model first memorizes inliers before outliers. Exploiting this finding, we develop a new method called the outlier detection via the IM effect (ODIM). The ODIM only requires a few updates; thus, it is computationally efficient, tens of times faster than other deep-learning-based algorithms. Also, the ODIM filters out outliers successfully, regardless of the types of data, such as tabular, image, and sequential. We empirically demonstrate the superiority and efficiency of the ODIM by analyzing 20 data sets.
Guaranteed Encapsulation of Targets with Unknown Motion by a Minimalist Robotic Swarm
Jan 13, 2023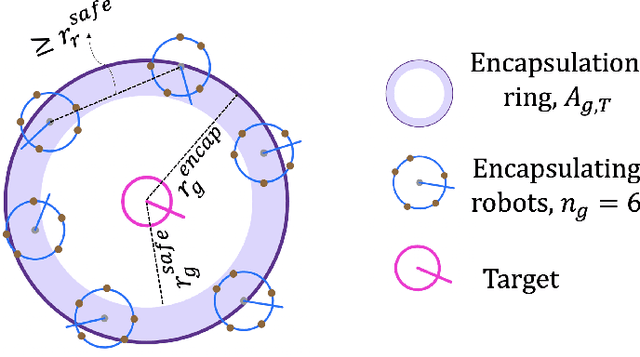
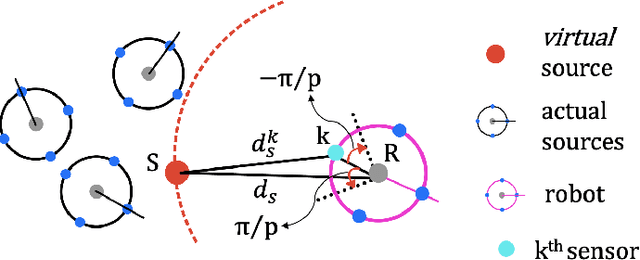
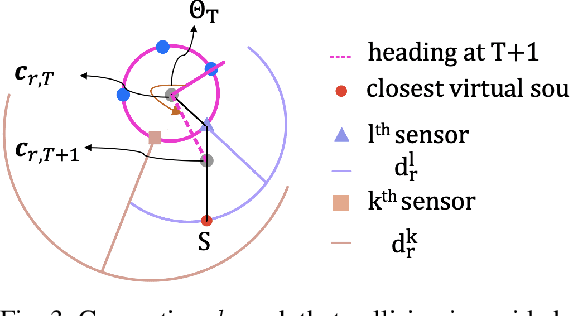
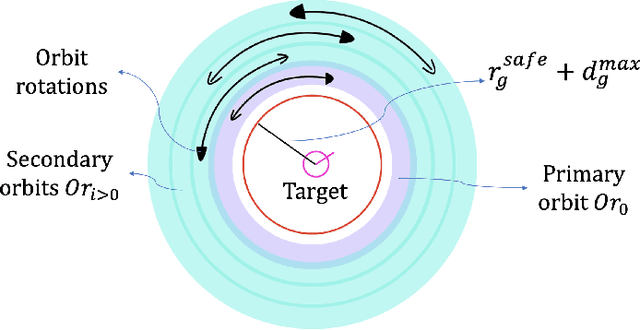
We present a decentralized control algorithm for a robotic swarm given the task of encapsulating static and moving targets in a bounded unknown environment. We consider minimalist robots without memory, explicit communication, or localization information. The state-of-the-art approaches generally assume that the robots in the swarm are able to detect the relative position of neighboring robots and targets in order to provide convergence guarantees. In this work, we propose a novel control law for the guaranteed encapsulation of static and moving targets while avoiding all collisions, when the robots do not know the exact relative location of any robot or target in the environment. We make use of the Lyapunov stability theory to prove the convergence of our control algorithm and provide bounds on the ratio between the target and robot speeds. Furthermore, our proposed approach is able to provide stochastic guarantees under the bounds that we determine on task parameters for scenarios where a target moves faster than a robot. Finally, we present an analysis of how the emergent behavior changes with different parameters of the task and noisy sensor readings.
Efficient Activation Function Optimization through Surrogate Modeling
Jan 13, 2023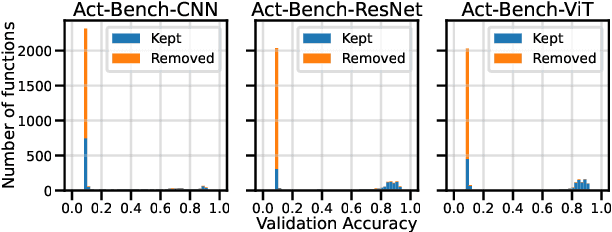
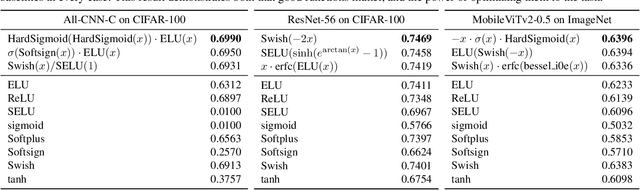
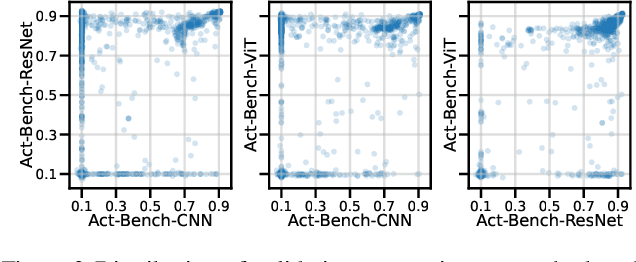

Carefully designed activation functions can improve the performance of neural networks in many machine learning tasks. However, it is difficult for humans to construct optimal activation functions, and current activation function search algorithms are prohibitively expensive. This paper aims to improve the state of the art through three steps: First, the benchmark datasets Act-Bench-CNN, Act-Bench-ResNet, and Act-Bench-ViT were created by training convolutional, residual, and vision transformer architectures from scratch with 2,913 systematically generated activation functions. Second, a characterization of the benchmark space was developed, leading to a new surrogate-based method for optimization. More specifically, the spectrum of the Fisher information matrix associated with the model's predictive distribution at initialization and the activation function's output distribution were found to be highly predictive of performance. Third, the surrogate was used to discover improved activation functions in CIFAR-100 and ImageNet tasks. Each of these steps is a contribution in its own right; together they serve as a practical and theoretical foundation for further research on activation function optimization. Code is available at https://github.com/cognizant-ai-labs/aquasurf, and the benchmark datasets are at https://github.com/cognizant-ai-labs/act-bench.
A LiDAR-Inertial-Visual SLAM System with Loop Detection
Jan 13, 2023
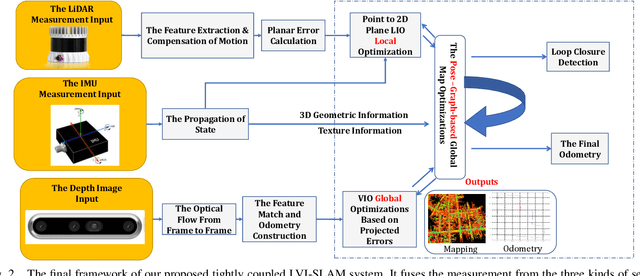
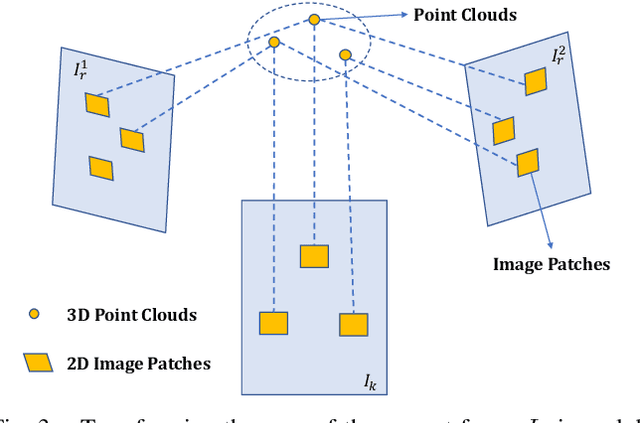
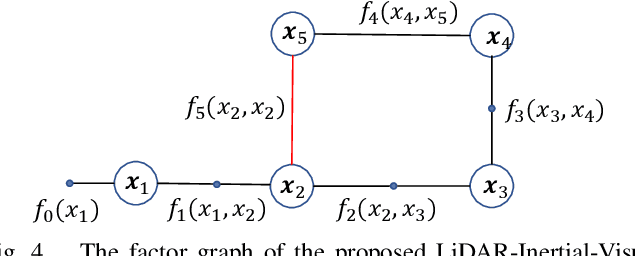
We have proposed, to the best of our knowledge, the first-of-its-kind LiDAR-Inertial-Visual-Fused simultaneous localization and mapping (SLAM) system with a strong place recognition capacity. Our proposed SLAM system is consist of visual-inertial odometry (VIO) and LiDAR inertial odometry (LIO) subsystems. We propose the LIO subsystem utilizing the measurement from the LiDAR and the inertial sensors to build the local odometry map, and propose the VIO subsystem which takes in the visual information to construct the 2D-3D associated map. Then, we propose an iterative Kalman Filter-based optimization function to optimize the local project-based 2D-to-3D photo-metric error between the projected image pixels and the local 3D points to make the robust 2D-3D alignment. Finally, we have also proposed the back-end pose graph global optimization and the elaborately designed loop closure detection network to improve the accuracy of the whole SLAM system. Extensive experiments deployed on the UGV in complicated real-world circumstances demonstrate that our proposed LiDAR-Visual-Inertial localization system outperforms the current state-of-the-art in terms of accuracy, efficiency, and robustness.
Exploring Workplace Behaviors through Speaking Patterns using Large-scale Multimodal Wearable Recordings: A Study of Healthcare Providers
Dec 18, 2022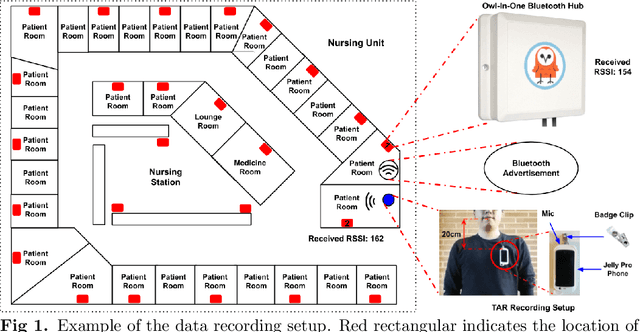
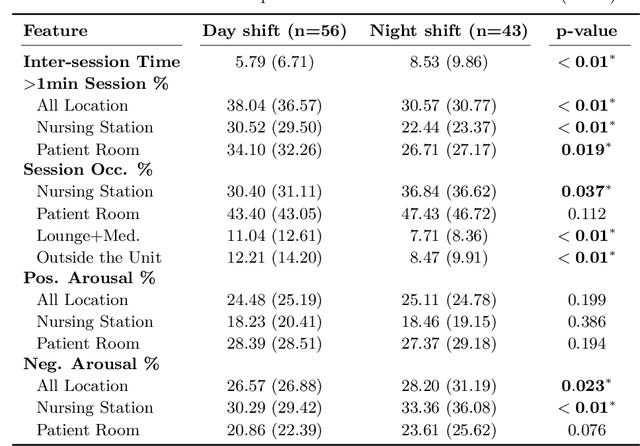

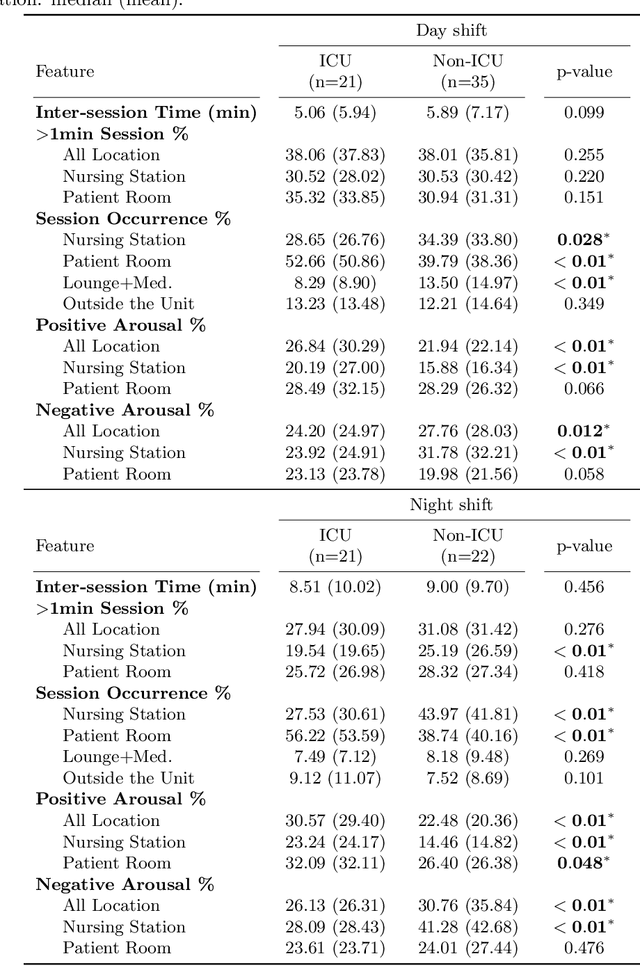
Interpersonal spoken communication is central to human interaction and the exchange of information. Such interactive processes involve not only speech and spoken language but also non-verbal cues such as hand gestures, facial expressions, and nonverbal vocalization, that are used to express feelings and provide feedback. These multimodal communication signals carry a variety of information about the people: traits like gender and age as well as about physical and psychological states and behavior. This work uses wearable multimodal sensors to investigate interpersonal communication behaviors focusing on speaking patterns among healthcare providers with a focus on nurses. We analyze longitudinal data collected from $99$ nurses in a large hospital setting over ten weeks. The results indicate that speaking pattern differences across shift schedules and working units. Moreover, results show that speaking patterns combined with physiological measures can be used to predict affect measures and life satisfaction scores. The implementation of this work can be accessed at https://github.com/usc-sail/tiles-audio-arousal.
Text2Poster: Laying out Stylized Texts on Retrieved Images
Jan 06, 2023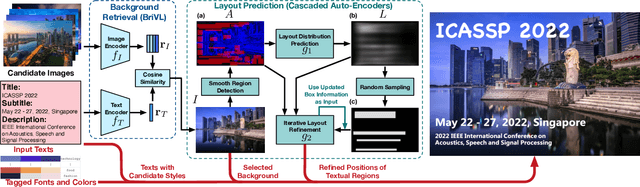
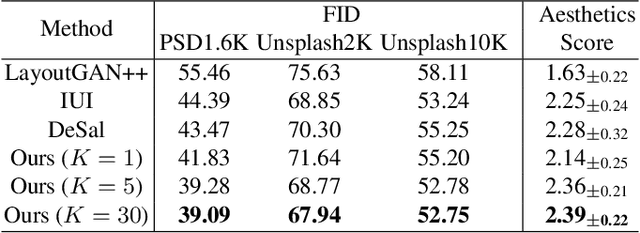


Poster generation is a significant task for a wide range of applications, which is often time-consuming and requires lots of manual editing and artistic experience. In this paper, we propose a novel data-driven framework, called \textit{Text2Poster}, to automatically generate visually-effective posters from textual information. Imitating the process of manual poster editing, our framework leverages a large-scale pretrained visual-textual model to retrieve background images from given texts, lays out the texts on the images iteratively by cascaded auto-encoders, and finally, stylizes the texts by a matching-based method. We learn the modules of the framework by weakly- and self-supervised learning strategies, mitigating the demand for labeled data. Both objective and subjective experiments demonstrate that our Text2Poster outperforms state-of-the-art methods, including academic research and commercial software, on the quality of generated posters.
Large Language Models are Zero-Shot Clinical Information Extractors
May 25, 2022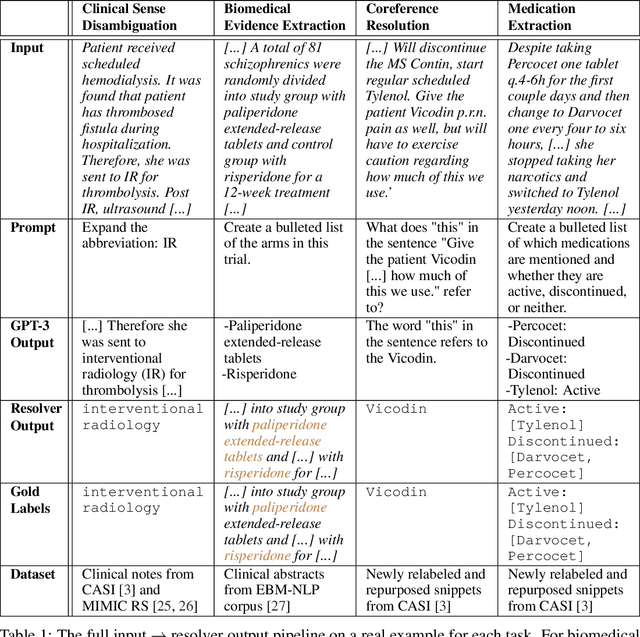


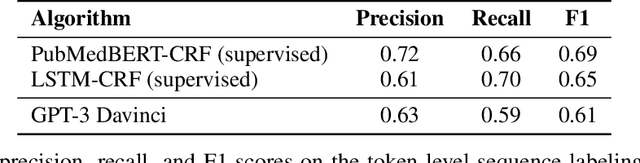
We show that large language models, such as GPT-3, perform well at zero-shot information extraction from clinical text despite not being trained specifically for the clinical domain. We present several examples showing how to use these models as tools for the diverse tasks of (i) concept disambiguation, (ii) evidence extraction, (iii) coreference resolution, and (iv) concept extraction, all on clinical text. The key to good performance is the use of simple task-specific programs that map from the language model outputs to the label space of the task. We refer to these programs as resolvers, a generalization of the verbalizer, which defines a mapping between output tokens and a discrete label space. We show in our examples that good resolvers share common components (e.g., "safety checks" that ensure the language model outputs faithfully match the input data), and that the common patterns across tasks make resolvers lightweight and easy to create. To better evaluate these systems, we also introduce two new datasets for benchmarking zero-shot clinical information extraction based on manual relabeling of the CASI dataset (Moon et al., 2014) with labels for new tasks. On the clinical extraction tasks we studied, the GPT-3 + resolver systems significantly outperform existing zero- and few-shot baselines.
DIONYSUS: A Pre-trained Model for Low-Resource Dialogue Summarization
Dec 20, 2022
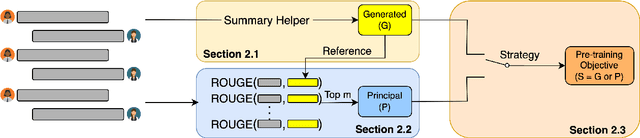

Dialogue summarization has recently garnered significant attention due to its wide range of applications. However, existing methods for summarizing dialogues are suboptimal because they do not take into account the inherent structure of dialogue and rely heavily on labeled data, which can lead to poor performance in new domains. In this work, we propose DIONYSUS (dynamic input optimization in pre-training for dialogue summarization), a pre-trained encoder-decoder model for summarizing dialogues in any new domain. To pre-train DIONYSUS, we create two pseudo summaries for each dialogue example: one is produced by a fine-tuned summarization model, and the other is a collection of dialogue turns that convey important information. We then choose one of these pseudo summaries based on the difference in information distribution across different types of dialogues. This selected pseudo summary serves as the objective for pre-training DIONYSUS using a self-supervised approach on a large dialogue corpus. Our experiments show that DIONYSUS outperforms existing methods on six datasets, as demonstrated by its ROUGE scores in zero-shot and few-shot settings.
REDAffectiveLM: Leveraging Affect Enriched Embedding and Transformer-based Neural Language Model for Readers' Emotion Detection
Jan 21, 2023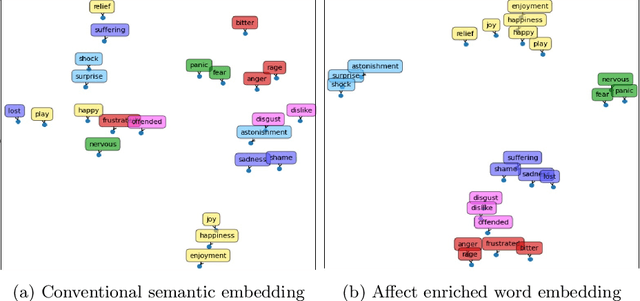
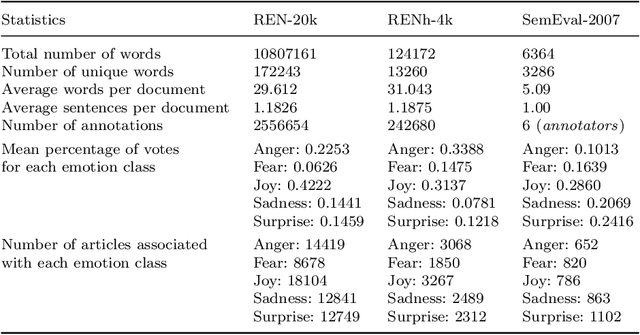
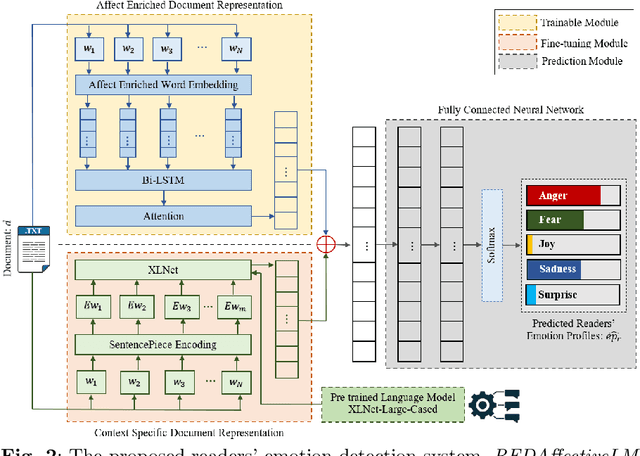
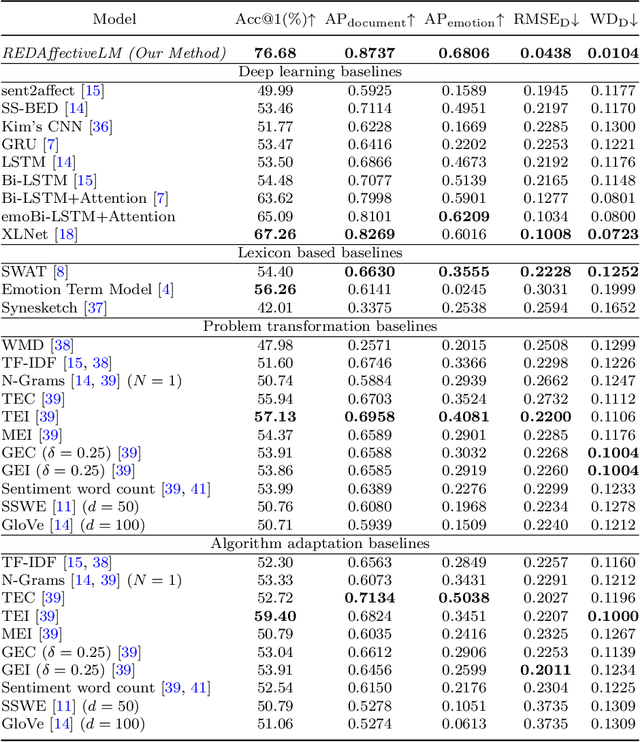
Technological advancements in web platforms allow people to express and share emotions towards textual write-ups written and shared by others. This brings about different interesting domains for analysis; emotion expressed by the writer and emotion elicited from the readers. In this paper, we propose a novel approach for Readers' Emotion Detection from short-text documents using a deep learning model called REDAffectiveLM. Within state-of-the-art NLP tasks, it is well understood that utilizing context-specific representations from transformer-based pre-trained language models helps achieve improved performance. Within this affective computing task, we explore how incorporating affective information can further enhance performance. Towards this, we leverage context-specific and affect enriched representations by using a transformer-based pre-trained language model in tandem with affect enriched Bi-LSTM+Attention. For empirical evaluation, we procure a new dataset REN-20k, besides using RENh-4k and SemEval-2007. We evaluate the performance of our REDAffectiveLM rigorously across these datasets, against a vast set of state-of-the-art baselines, where our model consistently outperforms baselines and obtains statistically significant results. Our results establish that utilizing affect enriched representation along with context-specific representation within a neural architecture can considerably enhance readers' emotion detection. Since the impact of affect enrichment specifically in readers' emotion detection isn't well explored, we conduct a detailed analysis over affect enriched Bi-LSTM+Attention using qualitative and quantitative model behavior evaluation techniques. We observe that compared to conventional semantic embedding, affect enriched embedding increases ability of the network to effectively identify and assign weightage to key terms responsible for readers' emotion detection.