 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA nonparametric two-sample test using a parametric integral probability metric
Jun 15, 2026Detecting distributional differences between two independent samples is a fundamental problem in statistics and machine learning. Nonparametric two-sample testing provides a principled framework for determining whether two samples are drawn from the same underlying distribution, without assuming any specific parametric form for the distribution. In this study, we propose a new two-sample test statistic based on a newly introduced integral probability metric (IPM), using a specially designed parametric discriminator class with a single node of a neural network. We show that the resulting test statistic, called PReLU-IPM, is nonparametric and establish theoretical guarantees for the associated two-sample testing procedure, PReLU-TST, including its consistency and asymptotical equivalence to nonparametric IPM-based tests under regularity conditions. By analyzing multiple simulated and real benchmark datasets, we demonstrate that PReLU-TST achieves higher power across a range of alternatives or performs comparably to its competitors, for finite samples.
A Composite Activation Function for Learning Stable Binary Representations
May 12, 2026Activation functions play a central role in neural networks by shaping internal representations. Recently, learning binary activation representations has attracted significant attention due to their advantages in computational and memory efficiency, as well as interpretability. However, training neural networks with Heaviside activations remains challenging, as their non-differentiability obstructs standard gradient-based optimization. In this paper, we propose Heavy Tailed Activation Function (HTAF), a smooth approximation to the Heaviside function that enables stable training with gradient-based optimization. We construct HTAF as a sigmoid hyperbolic tangent composite function and theoretically show that it maintains a large gradient mass around zero inputs while exhibiting slower gradient decay in the tail regions. We show that Spiking Neural Networks, Binary Neural Networks and Deep Heaviside neural Networks can be trained stably using HTAF with gradient-based optimization. Finally, we introduce Implicit Concept Bottleneck Models (ICBMs), an interpretable image model that leverages HTAF to induce discrete feature representations. Extensive experiments across various architectures and image datasets demonstrate that ICBM enables stable discretization while achieving prediction performance comparable to or better than standard models.
Fair Model-based Clustering
Feb 25, 2026The goal of fair clustering is to find clusters such that the proportion of sensitive attributes (e.g., gender, race, etc.) in each cluster is similar to that of the entire dataset. Various fair clustering algorithms have been proposed that modify standard K-means clustering to satisfy a given fairness constraint. A critical limitation of several existing fair clustering algorithms is that the number of parameters to be learned is proportional to the sample size because the cluster assignment of each datum should be optimized simultaneously with the cluster center, and thus scaling up the algorithms is difficult. In this paper, we propose a new fair clustering algorithm based on a finite mixture model, called Fair Model-based Clustering (FMC). A main advantage of FMC is that the number of learnable parameters is independent of the sample size and thus can be scaled up easily. In particular, mini-batch learning is possible to obtain clusters that are approximately fair. Moreover, FMC can be applied to non-metric data (e.g., categorical data) as long as the likelihood is well-defined. Theoretical and empirical justifications for the superiority of the proposed algorithm are provided.
Knowledge Distillation of Uncertainty using Deep Latent Factor Model
Oct 22, 2025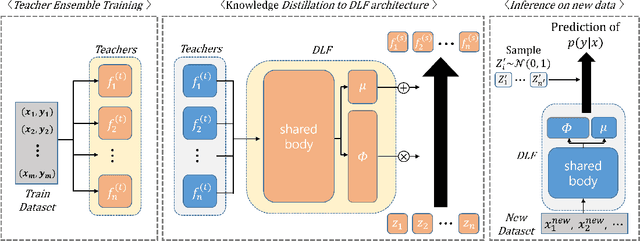
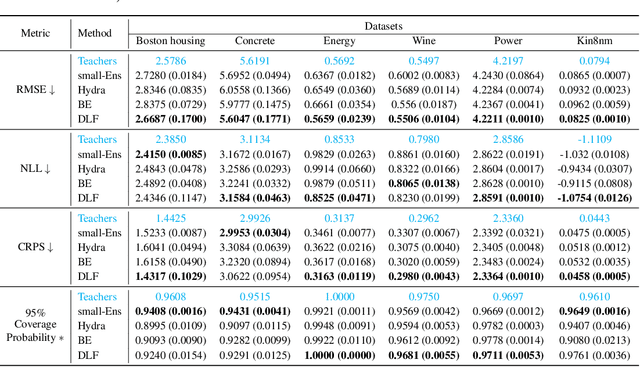
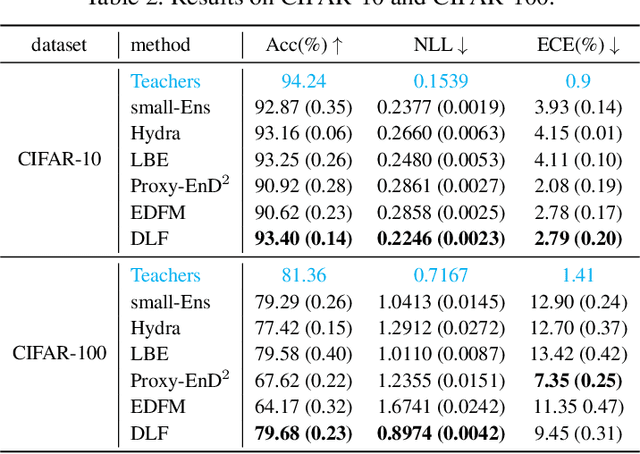
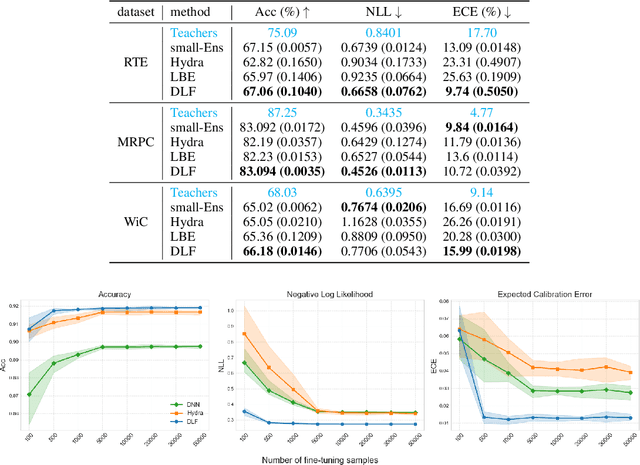
Deep ensembles deliver state-of-the-art, reliable uncertainty quantification, but their heavy computational and memory requirements hinder their practical deployments to real applications such as on-device AI. Knowledge distillation compresses an ensemble into small student models, but existing techniques struggle to preserve uncertainty partly because reducing the size of DNNs typically results in variation reduction. To resolve this limitation, we introduce a new method of distribution distillation (i.e. compressing a teacher ensemble into a student distribution instead of a student ensemble) called Gaussian distillation, which estimates the distribution of a teacher ensemble through a special Gaussian process called the deep latent factor model (DLF) by treating each member of the teacher ensemble as a realization of a certain stochastic process. The mean and covariance functions in the DLF model are estimated stably by using the expectation-maximization (EM) algorithm. By using multiple benchmark datasets, we demonstrate that the proposed Gaussian distillation outperforms existing baselines. In addition, we illustrate that Gaussian distillation works well for fine-tuning of language models and distribution shift problems.
Bayesian Neural Networks for Functional ANOVA model
Oct 01, 2025With the increasing demand for interpretability in machine learning, functional ANOVA decomposition has gained renewed attention as a principled tool for breaking down high-dimensional function into low-dimensional components that reveal the contributions of different variable groups. Recently, Tensor Product Neural Network (TPNN) has been developed and applied as basis functions in the functional ANOVA model, referred to as ANOVA-TPNN. A disadvantage of ANOVA-TPNN, however, is that the components to be estimated must be specified in advance, which makes it difficult to incorporate higher-order TPNNs into the functional ANOVA model due to computational and memory constraints. In this work, we propose Bayesian-TPNN, a Bayesian inference procedure for the functional ANOVA model with TPNN basis functions, enabling the detection of higher-order components with reduced computational cost compared to ANOVA-TPNN. We develop an efficient MCMC algorithm and demonstrate that Bayesian-TPNN performs well by analyzing multiple benchmark datasets. Theoretically, we prove that the posterior of Bayesian-TPNN is consistent.
Bayesian Additive Regression Trees for functional ANOVA model
Sep 04, 2025Bayesian Additive Regression Trees (BART) is a powerful statistical model that leverages the strengths of Bayesian inference and regression trees. It has received significant attention for capturing complex non-linear relationships and interactions among predictors. However, the accuracy of BART often comes at the cost of interpretability. To address this limitation, we propose ANOVA Bayesian Additive Regression Trees (ANOVA-BART), a novel extension of BART based on the functional ANOVA decomposition, which is used to decompose the variability of a function into different interactions, each representing the contribution of a different set of covariates or factors. Our proposed ANOVA-BART enhances interpretability, preserves and extends the theoretical guarantees of BART, and achieves superior predictive performance. Specifically, we establish that the posterior concentration rate of ANOVA-BART is nearly minimax optimal, and further provides the same convergence rates for each interaction that are not available for BART. Moreover, comprehensive experiments confirm that ANOVA-BART surpasses BART in both accuracy and uncertainty quantification, while also demonstrating its effectiveness in component selection. These results suggest that ANOVA-BART offers a compelling alternative to BART by balancing predictive accuracy, interpretability, and theoretical consistency.
Fair Bayesian Model-Based Clustering
Jun 15, 2025Fair clustering has become a socially significant task with the advancement of machine learning technologies and the growing demand for trustworthy AI. Group fairness ensures that the proportions of each sensitive group are similar in all clusters. Most existing group-fair clustering methods are based on the $K$-means clustering and thus require the distance between instances and the number of clusters to be given in advance. To resolve this limitation, we propose a fair Bayesian model-based clustering called Fair Bayesian Clustering (FBC). We develop a specially designed prior which puts its mass only on fair clusters, and implement an efficient MCMC algorithm. Advantages of FBC are that it can infer the number of clusters and can be applied to any data type as long as the likelihood is defined (e.g., categorical data). Experiments on real-world datasets show that FBC (i) reasonably infers the number of clusters, (ii) achieves a competitive utility-fairness trade-off compared to existing fair clustering methods, and (iii) performs well on categorical data.
Fair Clustering via Alignment
May 14, 2025Algorithmic fairness in clustering aims to balance the proportions of instances assigned to each cluster with respect to a given sensitive attribute. While recently developed fair clustering algorithms optimize clustering objectives under specific fairness constraints, their inherent complexity or approximation often results in suboptimal clustering utility or numerical instability in practice. To resolve these limitations, we propose a new fair clustering algorithm based on a novel decomposition of the fair K-means clustering objective function. The proposed algorithm, called Fair Clustering via Alignment (FCA), operates by alternately (i) finding a joint probability distribution to align the data from different protected groups, and (ii) optimizing cluster centers in the aligned space. A key advantage of FCA is that it theoretically guarantees approximately optimal clustering utility for any given fairness level without complex constraints, thereby enabling high-utility fair clustering in practice. Experiments show that FCA outperforms existing methods by (i) attaining a superior trade-off between fairness level and clustering utility, and (ii) achieving near-perfect fairness without numerical instability.
TAROT: Towards Essentially Domain-Invariant Robustness with Theoretical Justification
May 10, 2025Robust domain adaptation against adversarial attacks is a critical research area that aims to develop models capable of maintaining consistent performance across diverse and challenging domains. In this paper, we derive a new generalization bound for robust risk on the target domain using a novel divergence measure specifically designed for robust domain adaptation. Building upon this, we propose a new algorithm named TAROT, which is designed to enhance both domain adaptability and robustness. Through extensive experiments, TAROT not only surpasses state-of-the-art methods in accuracy and robustness but also significantly enhances domain generalization and scalability by effectively learning domain-invariant features. In particular, TAROT achieves superior performance on the challenging DomainNet dataset, demonstrating its ability to learn domain-invariant representations that generalize well across different domains, including unseen ones. These results highlight the broader applicability of our approach in real-world domain adaptation scenarios.
Fair Representation Learning for Continuous Sensitive Attributes using Expectation of Integral Probability Metrics
May 09, 2025AI fairness, also known as algorithmic fairness, aims to ensure that algorithms operate without bias or discrimination towards any individual or group. Among various AI algorithms, the Fair Representation Learning (FRL) approach has gained significant interest in recent years. However, existing FRL algorithms have a limitation: they are primarily designed for categorical sensitive attributes and thus cannot be applied to continuous sensitive attributes, such as age or income. In this paper, we propose an FRL algorithm for continuous sensitive attributes. First, we introduce a measure called the Expectation of Integral Probability Metrics (EIPM) to assess the fairness level of representation space for continuous sensitive attributes. We demonstrate that if the distribution of the representation has a low EIPM value, then any prediction head constructed on the top of the representation become fair, regardless of the selection of the prediction head. Furthermore, EIPM possesses a distinguished advantage in that it can be accurately estimated using our proposed estimator with finite samples. Based on these properties, we propose a new FRL algorithm called Fair Representation using EIPM with MMD (FREM). Experimental evidences show that FREM outperforms other baseline methods.