 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Confidence and Dispersity Speak: Characterising Prediction Matrix for Unsupervised Accuracy Estimation
Feb 02, 2023
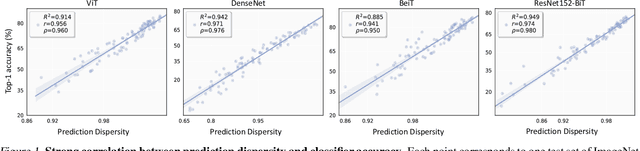
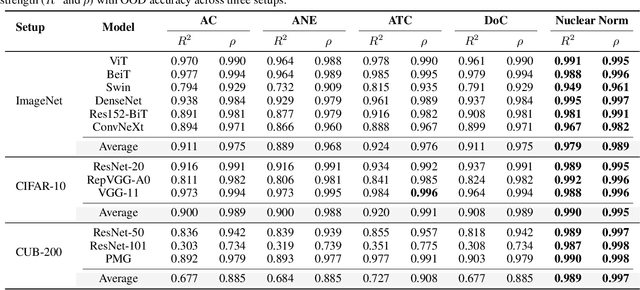
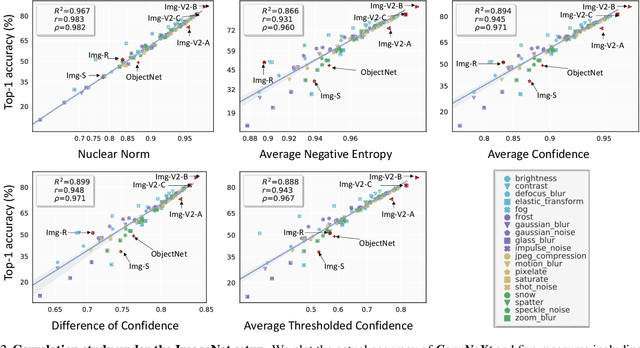
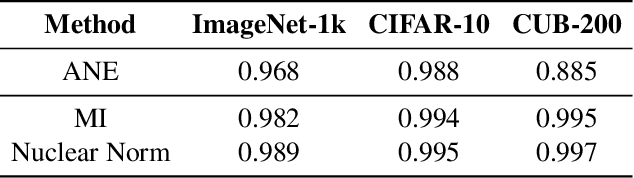
This work aims to assess how well a model performs under distribution shifts without using labels. While recent methods study prediction confidence, this work reports prediction dispersity is another informative cue. Confidence reflects whether the individual prediction is certain; dispersity indicates how the overall predictions are distributed across all categories. Our key insight is that a well-performing model should give predictions with high confidence and high dispersity. That is, we need to consider both properties so as to make more accurate estimates. To this end, we use the nuclear norm that has been shown to be effective in characterizing both properties. Extensive experiments validate the effectiveness of nuclear norm for various models (e.g., ViT and ConvNeXt), different datasets (e.g., ImageNet and CUB-200), and diverse types of distribution shifts (e.g., style shift and reproduction shift). We show that the nuclear norm is more accurate and robust in accuracy estimation than existing methods. Furthermore, we validate the feasibility of other measurements (e.g., mutual information maximization) for characterizing dispersity and confidence. Lastly, we investigate the limitation of the nuclear norm, study its improved variant under severe class imbalance, and discuss potential directions.
Energy Efficient Training of SNN using Local Zeroth Order Method
Feb 02, 2023
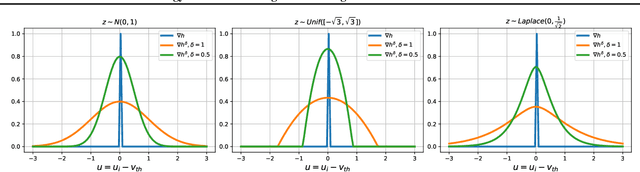
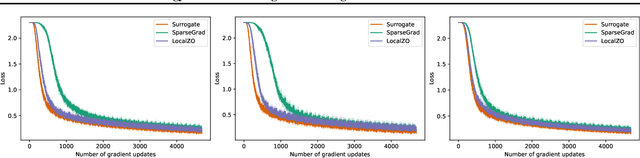
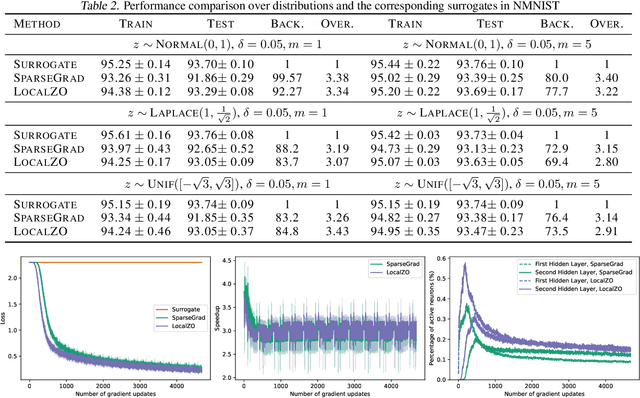
Spiking neural networks are becoming increasingly popular for their low energy requirement in real-world tasks with accuracy comparable to the traditional ANNs. SNN training algorithms face the loss of gradient information and non-differentiability due to the Heaviside function in minimizing the model loss over model parameters. To circumvent the problem surrogate method uses a differentiable approximation of the Heaviside in the backward pass, while the forward pass uses the Heaviside as the spiking function. We propose to use the zeroth order technique at the neuron level to resolve this dichotomy and use it within the automatic differentiation tool. As a result, we establish a theoretical connection between the proposed local zeroth-order technique and the existing surrogate methods and vice-versa. The proposed method naturally lends itself to energy-efficient training of SNNs on GPUs. Experimental results with neuromorphic datasets show that such implementation requires less than 1 percent neurons to be active in the backward pass, resulting in a 100x speed-up in the backward computation time. Our method offers better generalization compared to the state-of-the-art energy-efficient technique while maintaining similar efficiency.
SeeGera: Self-supervised Semi-implicit Graph Variational Auto-encoders with Masking
Feb 07, 2023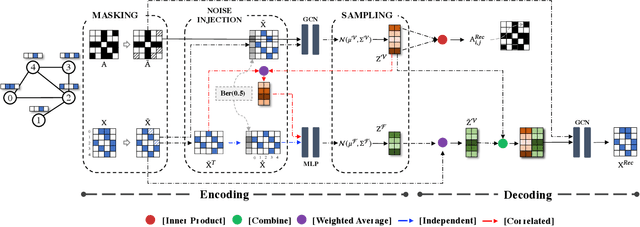
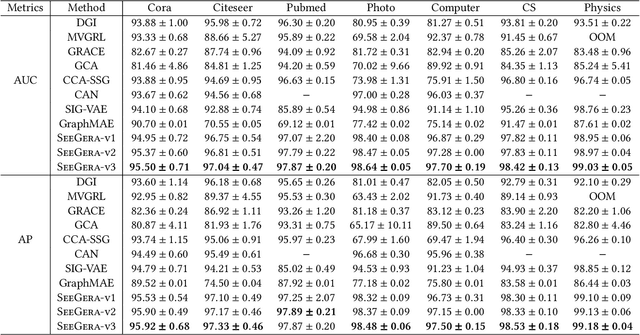

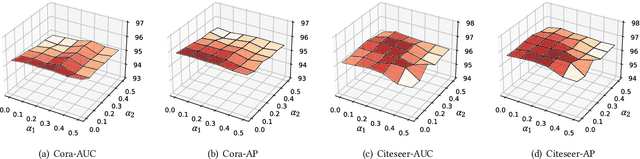
Generative graph self-supervised learning (SSL) aims to learn node representations by reconstructing the input graph data. However, most existing methods focus on unsupervised learning tasks only and very few work has shown its superiority over the state-of-the-art graph contrastive learning (GCL) models, especially on the classification task. While a very recent model has been proposed to bridge the gap, its performance on unsupervised learning tasks is still unknown. In this paper, to comprehensively enhance the performance of generative graph SSL against other GCL models on both unsupervised and supervised learning tasks, we propose the SeeGera model, which is based on the family of self-supervised variational graph auto-encoder (VGAE). Specifically, SeeGera adopts the semi-implicit variational inference framework, a hierarchical variational framework, and mainly focuses on feature reconstruction and structure/feature masking. On the one hand, SeeGera co-embeds both nodes and features in the encoder and reconstructs both links and features in the decoder. Since feature embeddings contain rich semantic information on features, they can be combined with node embeddings to provide fine-grained knowledge for feature reconstruction. On the other hand, SeeGera adds an additional layer for structure/feature masking to the hierarchical variational framework, which boosts the model generalizability. We conduct extensive experiments comparing SeeGera with 9 other state-of-the-art competitors. Our results show that SeeGera can compare favorably against other state-of-the-art GCL methods in a variety of unsupervised and supervised learning tasks.
A Counterfactual Collaborative Session-based Recommender System
Feb 07, 2023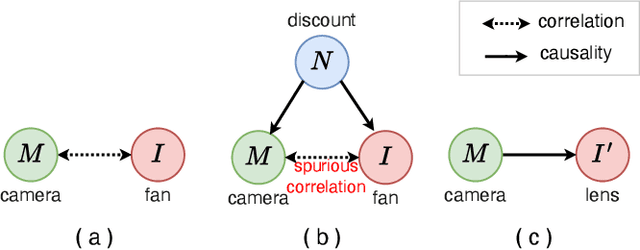
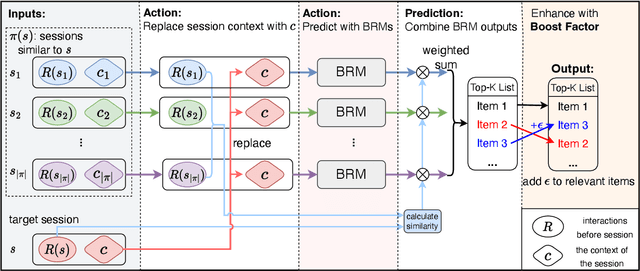
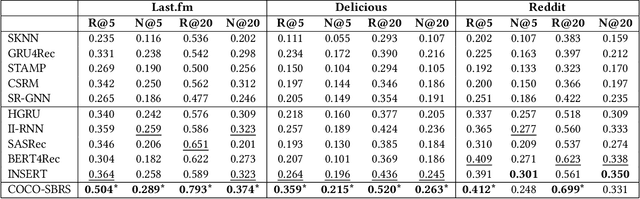
Most session-based recommender systems (SBRSs) focus on extracting information from the observed items in the current session of a user to predict a next item, ignoring the causes outside the session (called outer-session causes, OSCs) that influence the user's selection of items. However, these causes widely exist in the real world, and few studies have investigated their role in SBRSs. In this work, we analyze the causalities and correlations of the OSCs in SBRSs from the perspective of causal inference. We find that the OSCs are essentially the confounders in SBRSs, which leads to spurious correlations in the data used to train SBRS models. To address this problem, we propose a novel SBRS framework named COCO-SBRS (COunterfactual COllaborative Session-Based Recommender Systems) to learn the causality between OSCs and user-item interactions in SBRSs. COCO-SBRS first adopts a self-supervised approach to pre-train a recommendation model by designing pseudo-labels of causes for each user's selection of the item in data to guide the training process. Next, COCO-SBRS adopts counterfactual inference to recommend items based on the outputs of the pre-trained recommendation model considering the causalities to alleviate the data sparsity problem. As a result, COCO-SBRS can learn the causalities in data, preventing the model from learning spurious correlations. The experimental results of our extensive experiments conducted on three real-world datasets demonstrate the superiority of our proposed framework over ten representative SBRSs.
Undersampling and Cumulative Class Re-decision Methods to Improve Detection of Agitation in People with Dementia
Feb 07, 2023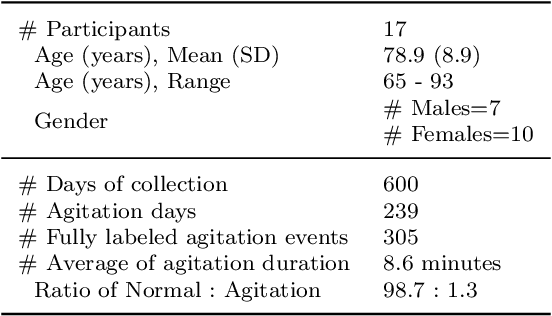
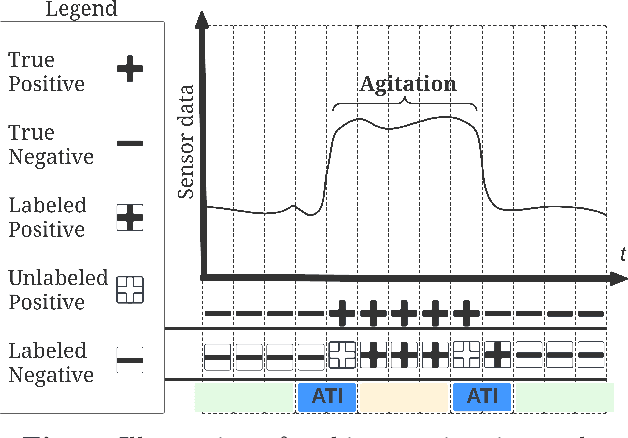
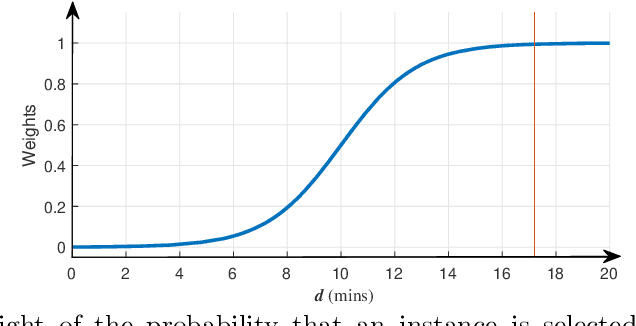
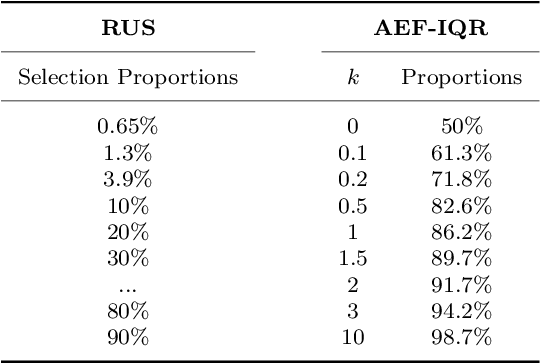
Agitation is one of the most prevalent symptoms in people with dementia (PwD) that can place themselves and the caregiver's safety at risk. Developing objective agitation detection approaches is important to support health and safety of PwD living in a residential setting. In a previous study, we collected multimodal wearable sensor data from 17 participants for 600 days and developed machine learning models for predicting agitation in one-minute windows. However, there are significant limitations in the dataset, such as imbalance problem and potential imprecise labels as the occurrence of agitation is much rarer in comparison to the normal behaviours. In this paper, we first implement different undersampling methods to eliminate the imbalance problem, and come to the conclusion that only 20% of normal behaviour data are adequate to train a competitive agitation detection model. Then, we design a weighted undersampling method to evaluate the manual labeling mechanism given the ambiguous time interval (ATI) assumption. After that, the postprocessing method of cumulative class re-decision (CCR) is proposed based on the historical sequential information and continuity characteristic of agitation, improving the decision-making performance for the potential application of agitation detection system. The results show that a combination of undersampling and CCR improves best F1-score by 26.6% and other metrics to varying degrees with less training time and data used, and inspires a way to find the potential range of optimal threshold reference for clinical purpose.
In-Context Retrieval-Augmented Language Models
Jan 31, 2023
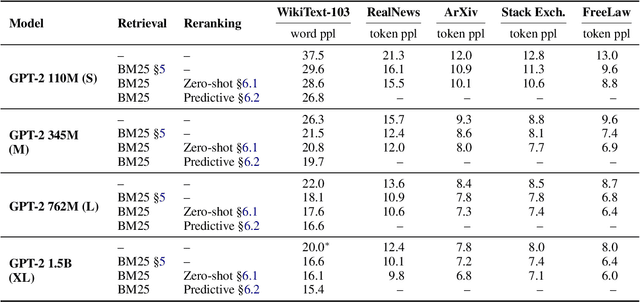
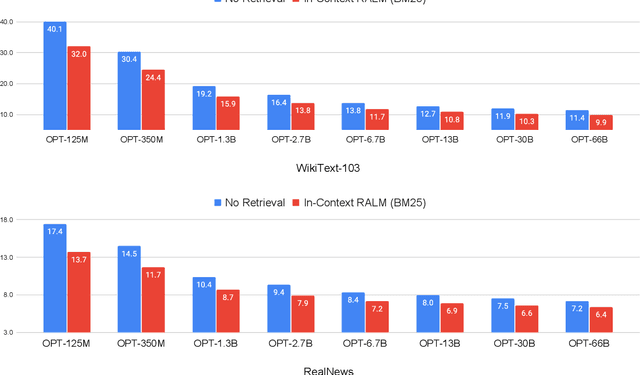
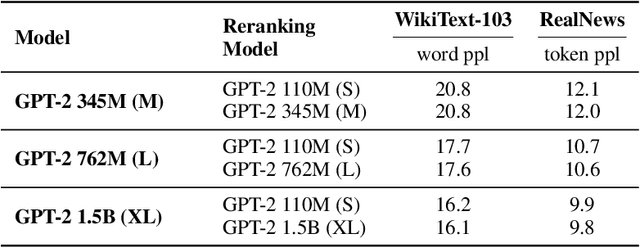
Retrieval-Augmented Language Modeling (RALM) methods, that condition a language model (LM) on relevant documents from a grounding corpus during generation, have been shown to significantly improve language modeling while also providing a natural source attribution mechanism. Existing RALM approaches focus on modifying the LM architecture in order to facilitate the incorporation of external information, significantly complicating deployment. This paper proposes an under-explored alternative, which we dub In-Context RALM: leaving the LM architecture unchanged and prepending grounding documents to the input. We show that in-context RALM which uses off-the-shelf general purpose retrievers provides surprisingly large LM gains across model sizes and diverse corpora. We also demonstrate that the document retrieval and ranking mechanism can be specialized to the RALM setting to further boost performance. We conclude that in-context RALM has considerable potential to increase the prevalence of LM grounding, particularly in settings where a pretrained LM must be used without modification or even via API access. To that end, we make our code publicly available.
An Analysis of Classification Approaches for Hit Song Prediction using Engineered Metadata Features with Lyrics and Audio Features
Jan 31, 2023

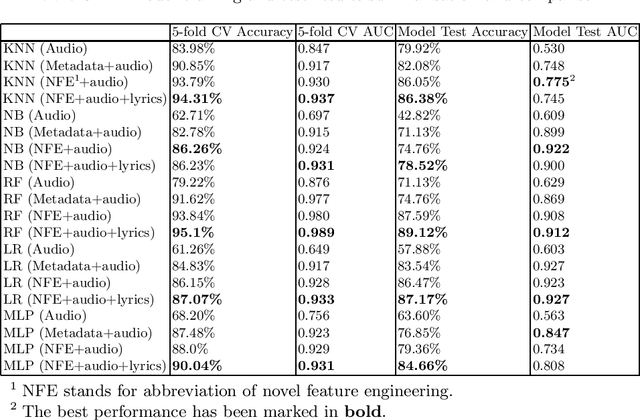
Hit song prediction, one of the emerging fields in music information retrieval (MIR), remains a considerable challenge. Being able to understand what makes a given song a hit is clearly beneficial to the whole music industry. Previous approaches to hit song prediction have focused on using audio features of a record. This study aims to improve the prediction result of the top 10 hits among Billboard Hot 100 songs using more alternative metadata, including song audio features provided by Spotify, song lyrics, and novel metadata-based features (title topic, popularity continuity and genre class). Five machine learning approaches are applied, including: k-nearest neighbours, Naive Bayes, Random Forest, Logistic Regression and Multilayer Perceptron. Our results show that Random Forest (RF) and Logistic Regression (LR) with all features (including novel features, song audio features and lyrics features) outperforms other models, achieving 89.1% and 87.2% accuracy, and 0.91 and 0.93 AUC, respectively. Our findings also demonstrate the utility of our novel music metadata features, which contributed most to the models' discriminative performance.
OrthoReg: Improving Graph-regularized MLPs via Orthogonality Regularization
Jan 31, 2023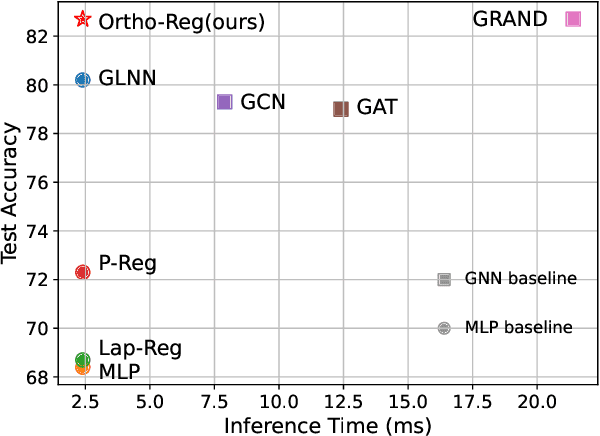
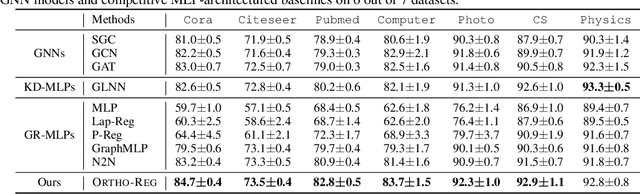
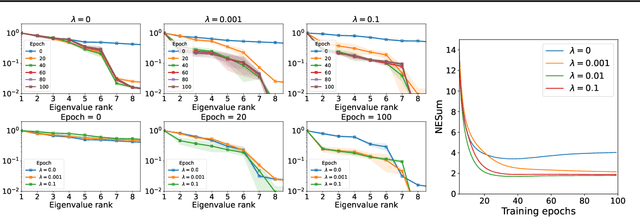
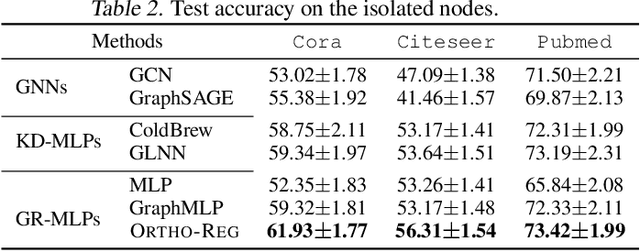
Graph Neural Networks (GNNs) are currently dominating in modeling graph-structure data, while their high reliance on graph structure for inference significantly impedes them from widespread applications. By contrast, Graph-regularized MLPs (GR-MLPs) implicitly inject the graph structure information into model weights, while their performance can hardly match that of GNNs in most tasks. This motivates us to study the causes of the limited performance of GR-MLPs. In this paper, we first demonstrate that node embeddings learned from conventional GR-MLPs suffer from dimensional collapse, a phenomenon in which the largest a few eigenvalues dominate the embedding space, through empirical observations and theoretical analysis. As a result, the expressive power of the learned node representations is constrained. We further propose OrthoReg, a novel GR-MLP model to mitigate the dimensional collapse issue. Through a soft regularization loss on the correlation matrix of node embeddings, OrthoReg explicitly encourages orthogonal node representations and thus can naturally avoid dimensionally collapsed representations. Experiments on traditional transductive semi-supervised classification tasks and inductive node classification for cold-start scenarios demonstrate its effectiveness and superiority.
Informing clinical assessment by contextualizing post-hoc explanations of risk prediction models in type-2 diabetes
Feb 11, 2023
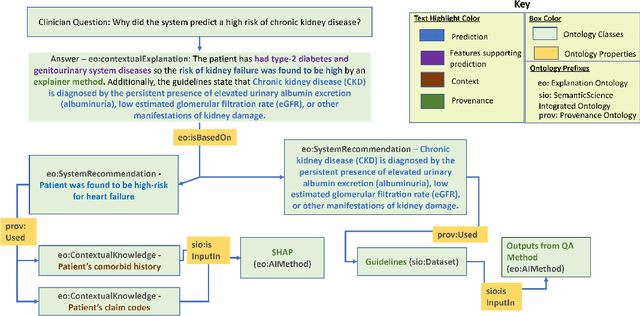
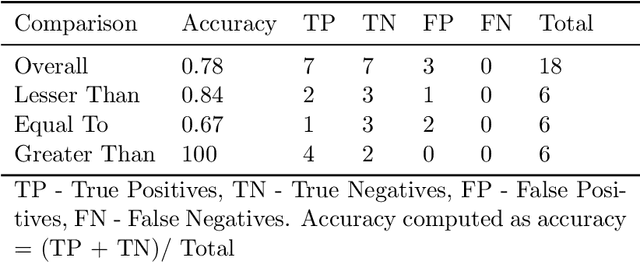
Medical experts may use Artificial Intelligence (AI) systems with greater trust if these are supported by contextual explanations that let the practitioner connect system inferences to their context of use. However, their importance in improving model usage and understanding has not been extensively studied. Hence, we consider a comorbidity risk prediction scenario and focus on contexts regarding the patients clinical state, AI predictions about their risk of complications, and algorithmic explanations supporting the predictions. We explore how relevant information for such dimensions can be extracted from Medical guidelines to answer typical questions from clinical practitioners. We identify this as a question answering (QA) task and employ several state-of-the-art LLMs to present contexts around risk prediction model inferences and evaluate their acceptability. Finally, we study the benefits of contextual explanations by building an end-to-end AI pipeline including data cohorting, AI risk modeling, post-hoc model explanations, and prototyped a visual dashboard to present the combined insights from different context dimensions and data sources, while predicting and identifying the drivers of risk of Chronic Kidney Disease - a common type-2 diabetes comorbidity. All of these steps were performed in engagement with medical experts, including a final evaluation of the dashboard results by an expert medical panel. We show that LLMs, in particular BERT and SciBERT, can be readily deployed to extract some relevant explanations to support clinical usage. To understand the value-add of the contextual explanations, the expert panel evaluated these regarding actionable insights in the relevant clinical setting. Overall, our paper is one of the first end-to-end analyses identifying the feasibility and benefits of contextual explanations in a real-world clinical use case.
Explainable Data-Driven Optimization: From Context to Decision and Back Again
Jan 24, 2023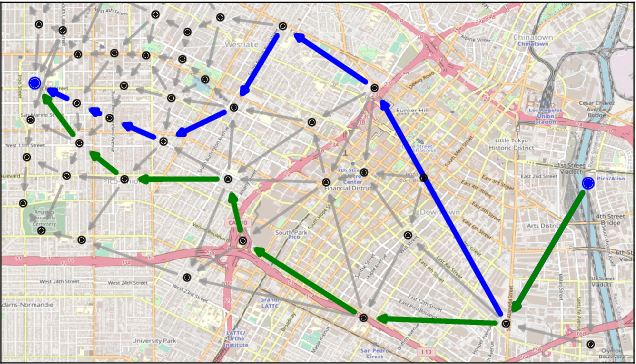
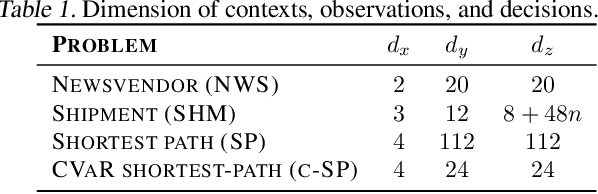
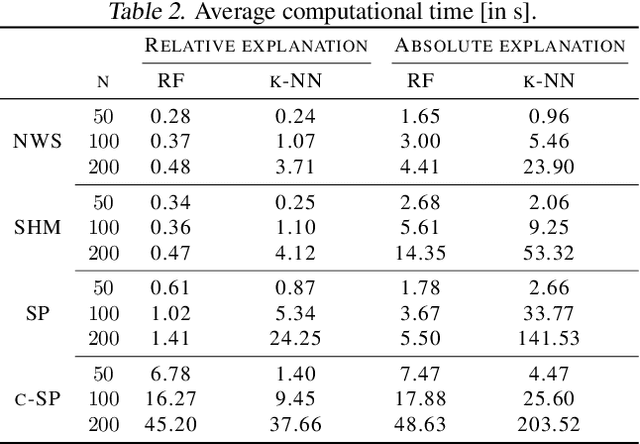
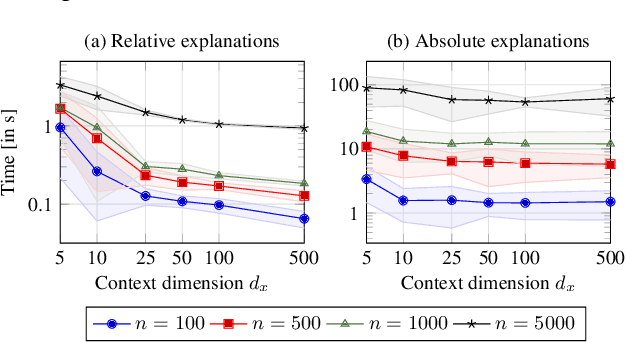
Data-driven optimization uses contextual information and machine learning algorithms to find solutions to decision problems with uncertain parameters. While a vast body of work is dedicated to interpreting machine learning models in the classification setting, explaining decision pipelines involving learning algorithms remains unaddressed. This lack of interpretability can block the adoption of data-driven solutions as practitioners may not understand or trust the recommended decisions. We bridge this gap by introducing a counterfactual explanation methodology tailored to explain solutions to data-driven problems. We introduce two classes of explanations and develop methods to find nearest explanations of random forest and nearest-neighbor predictors. We demonstrate our approach by explaining key problems in operations management such as inventory management and routing.