 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairFinGAN: Fairness-aware Synthetic Financial Data Generation
Mar 05, 2026Financial datasets often suffer from bias that can lead to unfair decision-making in automated systems. In this work, we propose FairFinGAN, a WGAN-based framework designed to generate synthetic financial data while mitigating bias with respect to the protected attribute. Our approach incorporates fairness constraints directly into the training process through a classifier, ensuring that the synthetic data is both fair and preserves utility for downstream predictive tasks. We evaluate our proposed model on five real-world financial datasets and compare it with existing GAN-based data generation methods. Experimental results show that our approach achieves superior fairness metrics without significant loss in data utility, demonstrating its potential as a tool for bias-aware data generation in financial applications.
Automating Computational Reproducibility in Social Science: Comparing Prompt-Based and Agent-Based Approaches
Feb 09, 2026Reproducing computational research is often assumed to be as simple as rerunning the original code with provided data. In practice, missing packages, fragile file paths, version conflicts, or incomplete logic frequently cause analyses to fail, even when materials are shared. This study investigates whether large language models and AI agents can automate the diagnosis and repair of such failures, making computational results easier to reproduce and verify. We evaluate this using a controlled reproducibility testbed built from five fully reproducible R-based social science studies. Realistic failures were injected, ranging from simple issues to complex missing logic, and two automated repair workflows were tested in clean Docker environments. The first workflow is prompt-based, repeatedly querying language models with structured prompts of varying context, while the second uses agent-based systems that inspect files, modify code, and rerun analyses autonomously. Across prompt-based runs, reproduction success ranged from 31-79 percent, with performance strongly influenced by prompt context and error complexity. Complex cases benefited most from additional context. Agent-based workflows performed substantially better, with success rates of 69-96 percent across all complexity levels. These results suggest that automated workflows, especially agent-based systems, can significantly reduce manual effort and improve reproduction success across diverse error types. Unlike prior benchmarks, our testbed isolates post-publication repair under controlled failure modes, allowing direct comparison of prompt-based and agent-based approaches.
Training Gradient Boosted Decision Trees on Tabular Data Containing Label Noise for Classification Tasks
Sep 13, 2024



Label noise refers to the phenomenon where instances in a data set are assigned to the wrong label. Label noise is harmful to classifier performance, increases model complexity and impairs feature selection. Addressing label noise is crucial, yet current research primarily focuses on image and text data using deep neural networks. This leaves a gap in the study of tabular data and gradient-boosted decision trees (GBDTs), the leading algorithm for tabular data. Different methods have already been developed which either try to filter label noise, model label noise while simultaneously training a classifier or use learning algorithms which remain effective even if label noise is present. This study aims to further investigate the effects of label noise on gradient-boosted decision trees and methods to mitigate those effects. Through comprehensive experiments and analysis, the implemented methods demonstrate state-of-the-art noise detection performance on the Adult dataset and achieve the highest classification precision and recall on the Adult and Breast Cancer datasets, respectively. In summary, this paper enhances the understanding of the impact of label noise on GBDTs and lays the groundwork for future research in noise detection and correction methods.
AI Chatbots as Multi-Role Pedagogical Agents: Transforming Engagement in CS Education
Aug 08, 2023



This study investigates the use of Artificial Intelligence (AI)-powered, multi-role chatbots as a means to enhance learning experiences and foster engagement in computer science education. Leveraging a design-based research approach, we develop, implement, and evaluate a novel learning environment enriched with four distinct chatbot roles: Instructor Bot, Peer Bot, Career Advising Bot, and Emotional Supporter Bot. These roles, designed around the tenets of Self-Determination Theory, cater to the three innate psychological needs of learners - competence, autonomy, and relatedness. Additionally, the system embraces an inquiry-based learning paradigm, encouraging students to ask questions, seek solutions, and explore their curiosities. We test this system in a higher education context over a period of one month with 200 participating students, comparing outcomes with conditions involving a human tutor and a single chatbot. Our research utilizes a mixed-methods approach, encompassing quantitative measures such as chat log sequence analysis, and qualitative methods including surveys and focus group interviews. By integrating cutting-edge Natural Language Processing techniques such as topic modelling and sentiment analysis, we offer an in-depth understanding of the system's impact on learner engagement, motivation, and inquiry-based learning. This study, through its rigorous design and innovative approach, provides significant insights into the potential of AI-empowered, multi-role chatbots in reshaping the landscape of computer science education and fostering an engaging, supportive, and motivating learning environment.
An Analysis of Classification Approaches for Hit Song Prediction using Engineered Metadata Features with Lyrics and Audio Features
Jan 31, 2023


Hit song prediction, one of the emerging fields in music information retrieval (MIR), remains a considerable challenge. Being able to understand what makes a given song a hit is clearly beneficial to the whole music industry. Previous approaches to hit song prediction have focused on using audio features of a record. This study aims to improve the prediction result of the top 10 hits among Billboard Hot 100 songs using more alternative metadata, including song audio features provided by Spotify, song lyrics, and novel metadata-based features (title topic, popularity continuity and genre class). Five machine learning approaches are applied, including: k-nearest neighbours, Naive Bayes, Random Forest, Logistic Regression and Multilayer Perceptron. Our results show that Random Forest (RF) and Logistic Regression (LR) with all features (including novel features, song audio features and lyrics features) outperforms other models, achieving 89.1% and 87.2% accuracy, and 0.91 and 0.93 AUC, respectively. Our findings also demonstrate the utility of our novel music metadata features, which contributed most to the models' discriminative performance.
SS-BERT: Mitigating Identity Terms Bias in Toxic Comment Classification by Utilising the Notion of "Subjectivity" and "Identity Terms"
Sep 06, 2021
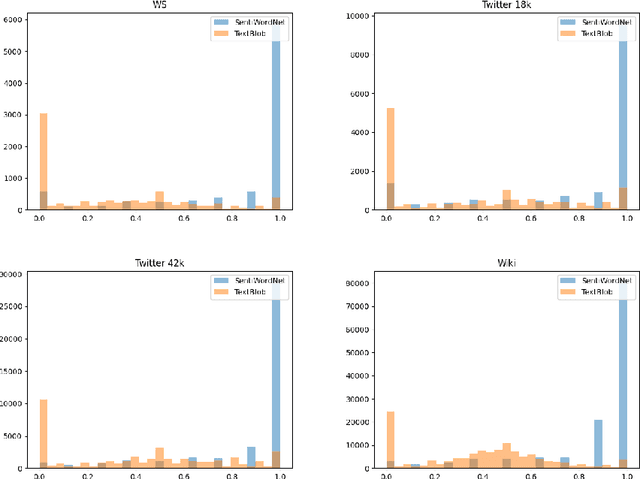

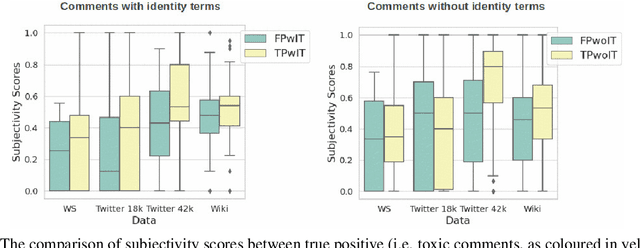
Toxic comment classification models are often found biased toward identity terms which are terms characterizing a specific group of people such as "Muslim" and "black". Such bias is commonly reflected in false-positive predictions, i.e. non-toxic comments with identity terms. In this work, we propose a novel approach to tackle such bias in toxic comment classification, leveraging the notion of subjectivity level of a comment and the presence of identity terms. We hypothesize that when a comment is made about a group of people that is characterized by an identity term, the likelihood of that comment being toxic is associated with the subjectivity level of the comment, i.e. the extent to which the comment conveys personal feelings and opinions. Building upon the BERT model, we propose a new structure that is able to leverage these features, and thoroughly evaluate our model on 4 datasets of varying sizes and representing different social media platforms. The results show that our model can consistently outperform BERT and a SOTA model devised to address identity term bias in a different way, with a maximum improvement in F1 of 2.43% and 1.91% respectively.