 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Visual Forced Alignment: Learning to Align Transcription with Talking Face Video
Feb 27, 2023
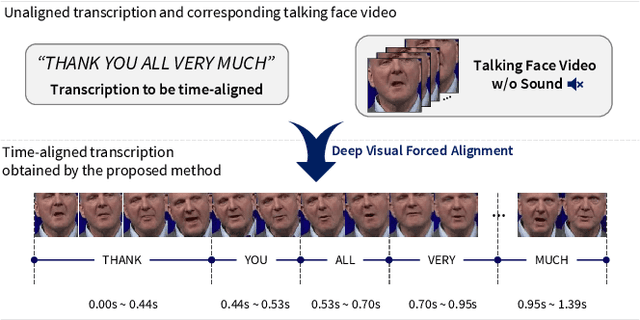
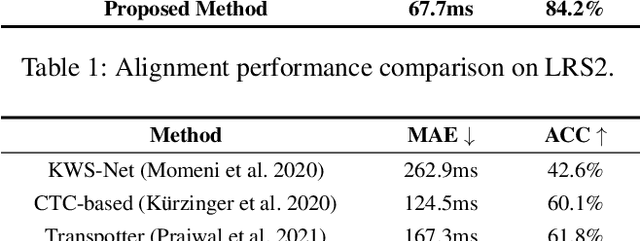
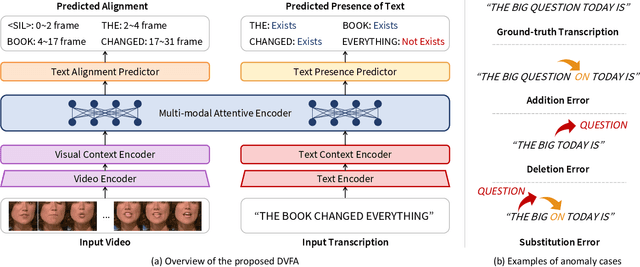
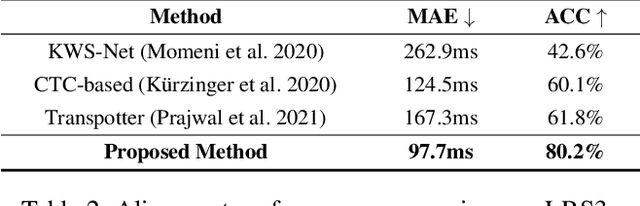
Forced alignment refers to a technology that time-aligns a given transcription with a corresponding speech. However, as the forced alignment technologies have developed using speech audio, they might fail in alignment when the input speech audio is noise-corrupted or is not accessible. We focus on that there is another component that the speech can be inferred from, the speech video (i.e., talking face video). Since the drawbacks of audio-based forced alignment can be complemented using the visual information when the audio signal is under poor condition, we try to develop a novel video-based forced alignment method. However, different from audio forced alignment, it is challenging to develop a reliable visual forced alignment technology for the following two reasons: 1) Visual Speech Recognition (VSR) has a much lower performance compared to audio-based Automatic Speech Recognition (ASR), and 2) the translation from text to video is not reliable, so the method typically used for building audio forced alignment cannot be utilized in developing visual forced alignment. In order to alleviate these challenges, in this paper, we propose a new method that is appropriate for visual forced alignment, namely Deep Visual Forced Alignment (DVFA). The proposed DVFA can align the input transcription (i.e., sentence) with the talking face video without accessing the speech audio. Moreover, by augmenting the alignment task with anomaly case detection, DVFA can detect mismatches between the input transcription and the input video while performing the alignment. Therefore, we can robustly align the text with the talking face video even if there exist error words in the text. Through extensive experiments, we show the effectiveness of the proposed DVFA not only in the alignment task but also in interpreting the outputs of VSR models.
Representing Knowledge by Spans: A Knowledge-Enhanced Model for Information Extraction
Aug 20, 2022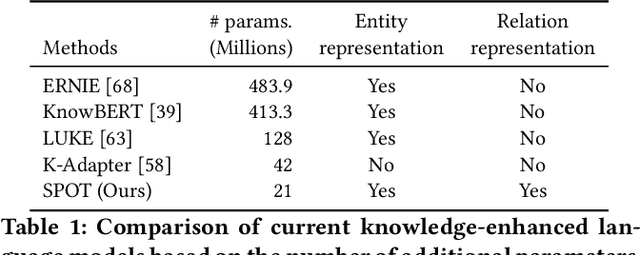
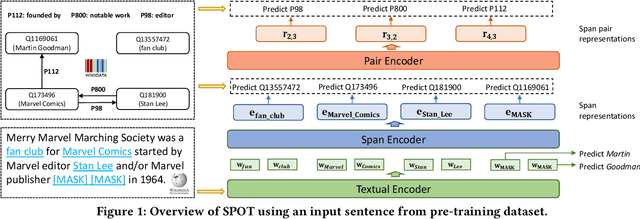
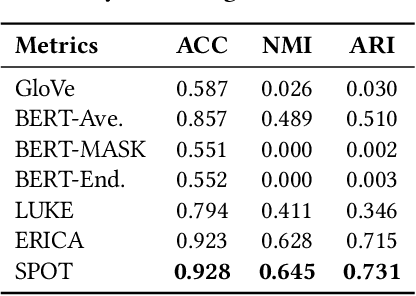
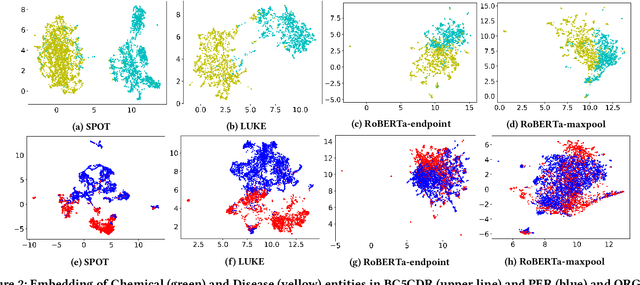
Knowledge-enhanced pre-trained models for language representation have been shown to be more effective in knowledge base construction tasks (i.e.,~relation extraction) than language models such as BERT. These knowledge-enhanced language models incorporate knowledge into pre-training to generate representations of entities or relationships. However, existing methods typically represent each entity with a separate embedding. As a result, these methods struggle to represent out-of-vocabulary entities and a large amount of parameters, on top of their underlying token models (i.e.,~the transformer), must be used and the number of entities that can be handled is limited in practice due to memory constraints. Moreover, existing models still struggle to represent entities and relationships simultaneously. To address these problems, we propose a new pre-trained model that learns representations of both entities and relationships from token spans and span pairs in the text respectively. By encoding spans efficiently with span modules, our model can represent both entities and their relationships but requires fewer parameters than existing models. We pre-trained our model with the knowledge graph extracted from Wikipedia and test it on a broad range of supervised and unsupervised information extraction tasks. Results show that our model learns better representations for both entities and relationships than baselines, while in supervised settings, fine-tuning our model outperforms RoBERTa consistently and achieves competitive results on information extraction tasks.
Query Performance Prediction for Neural IR: Are We There Yet?
Feb 20, 2023
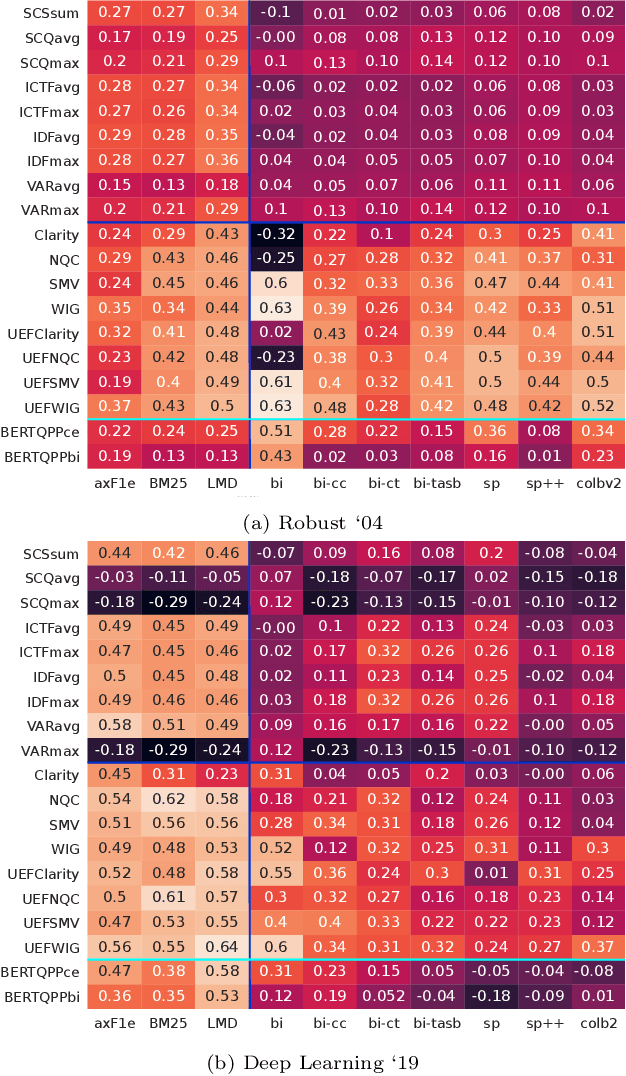

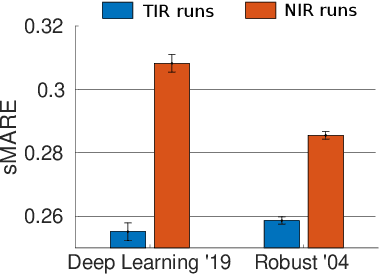
Evaluation in Information Retrieval relies on post-hoc empirical procedures, which are time-consuming and expensive operations. To alleviate this, Query Performance Prediction (QPP) models have been developed to estimate the performance of a system without the need for human-made relevance judgements. Such models, usually relying on lexical features from queries and corpora, have been applied to traditional sparse IR methods - with various degrees of success. With the advent of neural IR and large Pre-trained Language Models, the retrieval paradigm has significantly shifted towards more semantic signals. In this work, we study and analyze to what extent current QPP models can predict the performance of such systems. Our experiments consider seven traditional bag-of-words and seven BERT-based IR approaches, as well as nineteen state-of-the-art QPPs evaluated on two collections, Deep Learning '19 and Robust '04. Our findings show that QPPs perform statistically significantly worse on neural IR systems. In settings where semantic signals are prominent (e.g., passage retrieval), their performance on neural models drops by as much as 10% compared to bag-of-words approaches. On top of that, in lexical-oriented scenarios, QPPs fail to predict performance for neural IR systems on those queries where they differ from traditional approaches the most.
Kernel function impact on convolutional neural networks
Feb 20, 2023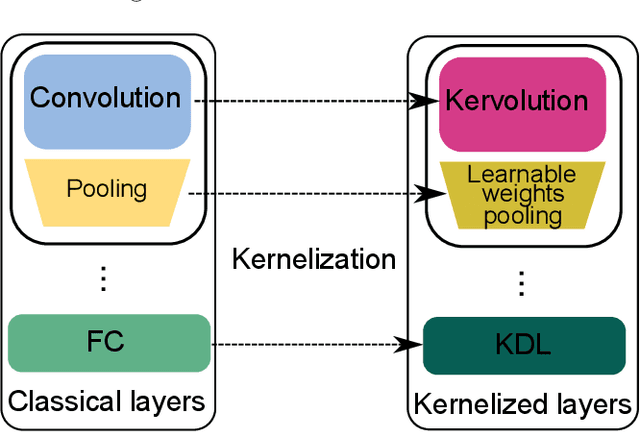
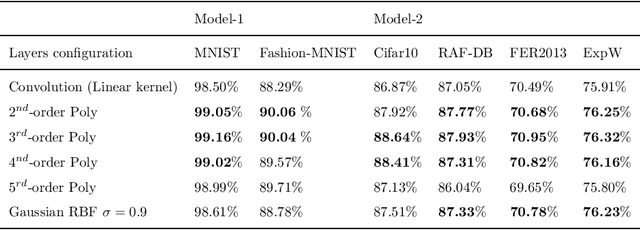
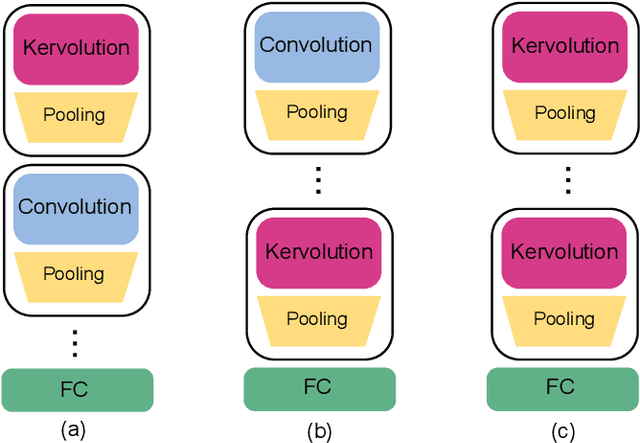
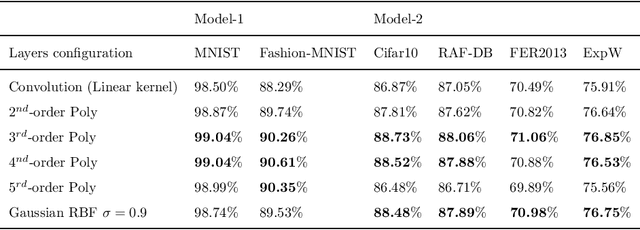
This paper investigates the usage of kernel functions at the different layers in a convolutional neural network. We carry out extensive studies of their impact on convolutional, pooling and fully-connected layers. We notice that the linear kernel may not be sufficiently effective to fit the input data distributions, whereas high order kernels prone to over-fitting. This leads to conclude that a trade-off between complexity and performance should be reached. We show how one can effectively leverage kernel functions, by introducing a more distortion aware pooling layers which reduces over-fitting while keeping track of the majority of the information fed into subsequent layers. We further propose Kernelized Dense Layers (KDL), which replace fully-connected layers, and capture higher order feature interactions. The experiments on conventional classification datasets i.e. MNIST, FASHION-MNIST and CIFAR-10, show that the proposed techniques improve the performance of the network compared to classical convolution, pooling and fully connected layers. Moreover, experiments on fine-grained classification i.e. facial expression databases, namely RAF-DB, FER2013 and ExpW demonstrate that the discriminative power of the network is boosted, since the proposed techniques improve the awareness to slight visual details and allows the network reaching state-of-the-art results.
Towards Understanding the Survival of Patients with High-Grade Gastroenteropancreatic Neuroendocrine Neoplasms: An Investigation of Ensemble Feature Selection in the Prediction of Overall Survival
Feb 20, 2023


Determining the most informative features for predicting the overall survival of patients diagnosed with high-grade gastroenteropancreatic neuroendocrine neoplasms is crucial to improve individual treatment plans for patients, as well as the biological understanding of the disease. Recently developed ensemble feature selectors like the Repeated Elastic Net Technique for Feature Selection (RENT) and the User-Guided Bayesian Framework for Feature Selection (UBayFS) allow the user to identify such features in datasets with low sample sizes. While RENT is purely data-driven, UBayFS is capable of integrating expert knowledge a priori in the feature selection process. In this work we compare both feature selectors on a dataset comprising of 63 patients and 134 features from multiple sources, including basic patient characteristics, baseline blood values, tumor histology, imaging, and treatment information. Our experiments involve data-driven and expert-driven setups, as well as combinations of both. We use findings from clinical literature as a source of expert knowledge. Our results demonstrate that both feature selectors allow accurate predictions, and that expert knowledge has a stabilizing effect on the feature set, while the impact on predictive performance is limited. The features WHO Performance Status, Albumin, Platelets, Ki-67, Tumor Morphology, Total MTV, Total TLG, and SUVmax are the most stable and predictive features in our study.
Unreliable Partial Label Learning with Recursive Separation
Feb 20, 2023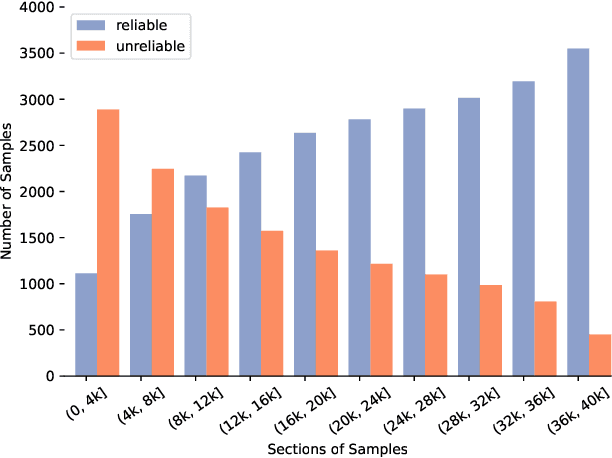
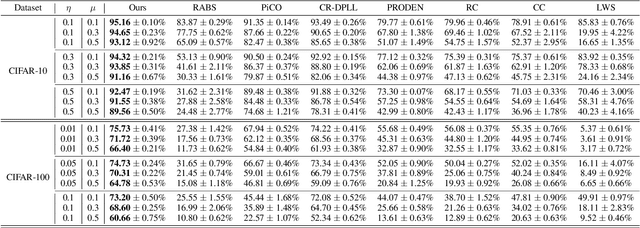


Partial label learning (PLL) is a typical weakly supervised learning problem in which each instance is associated with a candidate label set, and among which only one is true. However, the assumption that the ground-truth label is always among the candidate label set would be unrealistic, as the reliability of the candidate label sets in real-world applications cannot be guaranteed by annotators. Therefore, a generalized PLL named Unreliable Partial Label Learning (UPLL) is proposed, in which the true label may not be in the candidate label set. Due to the challenges posed by unreliable labeling, previous PLL methods will experience a marked decline in performance when applied to UPLL. To address the issue, we propose a two-stage framework named Unreliable Partial Label Learning with Recursive Separation (UPLLRS). In the first stage, the self-adaptive recursive separation strategy is proposed to separate the training set into a reliable subset and an unreliable subset. In the second stage, a disambiguation strategy is employed to progressively identify the ground-truth labels in the reliable subset. Simultaneously, semi-supervised learning methods are adopted to extract valuable information from the unreliable subset. Our method demonstrates state-of-the-art performance as evidenced by experimental results, particularly in situations of high unreliability.
Side Eye: Characterizing the Limits of POV Acoustic Eavesdropping from Smartphone Cameras with Rolling Shutters and Movable Lenses
Jan 24, 2023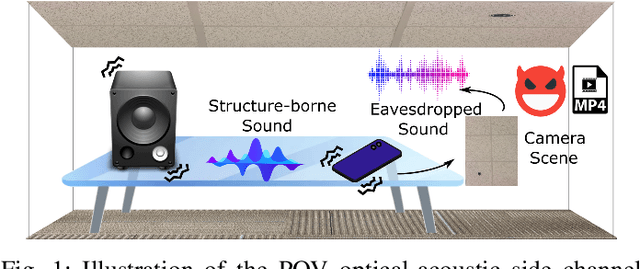

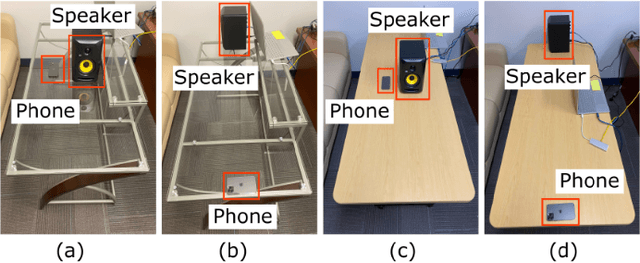
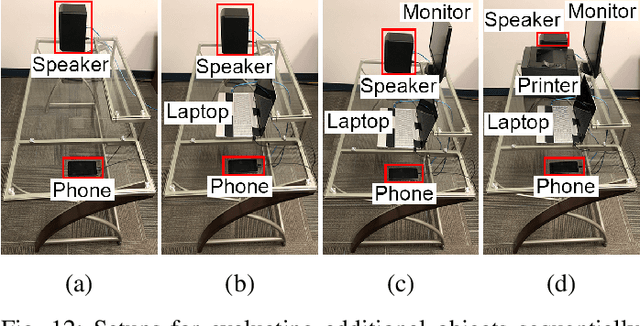
Our research discovers how the rolling shutter and movable lens structures widely found in smartphone cameras modulate structure-borne sounds onto camera images, creating a point-of-view (POV) optical-acoustic side channel for acoustic eavesdropping. The movement of smartphone camera hardware leaks acoustic information because images unwittingly modulate ambient sound as imperceptible distortions. Our experiments find that the side channel is further amplified by intrinsic behaviors of Complementary metal-oxide-semiconductor (CMOS) rolling shutters and movable lenses such as in Optical Image Stabilization (OIS) and Auto Focus (AF). Our paper characterizes the limits of acoustic information leakage caused by structure-borne sound that perturbs the POV of smartphone cameras. In contrast with traditional optical-acoustic eavesdropping on vibrating objects, this side channel requires no line of sight and no object within the camera's field of view (images of a ceiling suffice). Our experiments test the limits of this side channel with a novel signal processing pipeline that extracts and recognizes the leaked acoustic information. Our evaluation with 10 smartphones on a spoken digit dataset reports 80.66%, 91.28%, and 99.67% accuracies on recognizing 10 spoken digits, 20 speakers, and 2 genders respectively. We further systematically discuss the possible defense strategies and implementations. By modeling, measuring, and demonstrating the limits of acoustic eavesdropping from smartphone camera image streams, our contributions explain the physics-based causality and possible ways to reduce the threat on current and future devices.
EfficientFace: An Efficient Deep Network with Feature Enhancement for Accurate Face Detection
Feb 23, 2023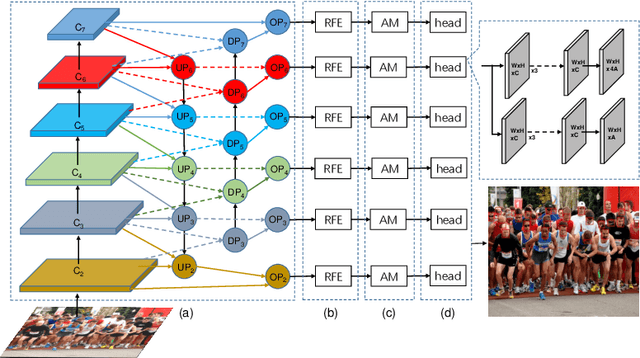

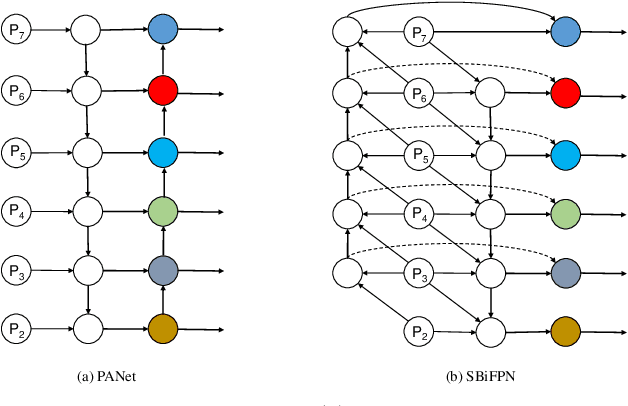
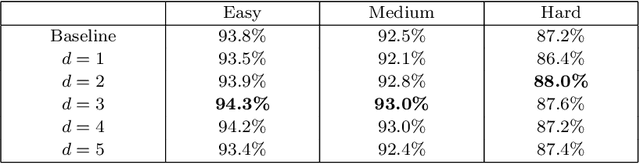
In recent years, deep convolutional neural networks (CNN) have significantly advanced face detection. In particular, lightweight CNNbased architectures have achieved great success due to their lowcomplexity structure facilitating real-time detection tasks. However, current lightweight CNN-based face detectors trading accuracy for efficiency have inadequate capability in handling insufficient feature representation, faces with unbalanced aspect ratios and occlusion. Consequently, they exhibit deteriorated performance far lagging behind the deep heavy detectors. To achieve efficient face detection without sacrificing accuracy, we design an efficient deep face detector termed EfficientFace in this study, which contains three modules for feature enhancement. To begin with, we design a novel cross-scale feature fusion strategy to facilitate bottom-up information propagation, such that fusing low-level and highlevel features is further strengthened. Besides, this is conducive to estimating the locations of faces and enhancing the descriptive power of face features. Secondly, we introduce a Receptive Field Enhancement module to consider faces with various aspect ratios. Thirdly, we add an Attention Mechanism module for improving the representational capability of occluded faces. We have evaluated EfficientFace on four public benchmarks and experimental results demonstrate the appealing performance of our method. In particular, our model respectively achieves 95.1% (Easy), 94.0% (Medium) and 90.1% (Hard) on validation set of WIDER Face dataset, which is competitive with heavyweight models with only 1/15 computational costs of the state-of-the-art MogFace detector.
Embeddings for Tabular Data: A Survey
Feb 23, 2023

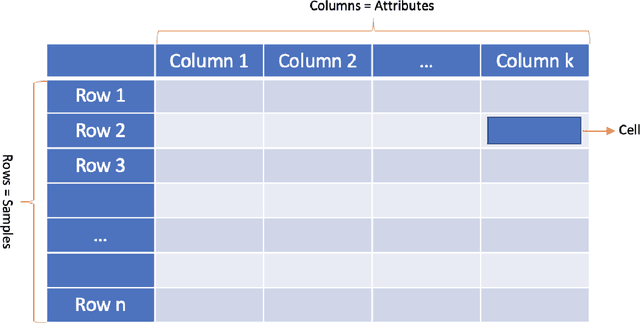

Tabular data comprising rows (samples) with the same set of columns (attributes, is one of the most widely used data-type among various industries, including financial services, health care, research, retail, and logistics, to name a few. Tables are becoming the natural way of storing data among various industries and academia. The data stored in these tables serve as an essential source of information for making various decisions. As computational power and internet connectivity increase, the data stored by these companies grow exponentially, and not only do the databases become vast and challenging to maintain and operate, but the quantity of database tasks also increases. Thus a new line of research work has been started, which applies various learning techniques to support various database tasks for such large and complex tables. In this work, we split the quest of learning on tabular data into two phases: The Classical Learning Phase and The Modern Machine Learning Phase. The classical learning phase consists of the models such as SVMs, linear and logistic regression, and tree-based methods. These models are best suited for small-size tables. However, the number of tasks these models can address is limited to classification and regression. In contrast, the Modern Machine Learning Phase contains models that use deep learning for learning latent space representation of table entities. The objective of this survey is to scrutinize the varied approaches used by practitioners to learn representation for the structured data, and to compare their efficacy.
Federated Learning for Water Consumption Forecasting in Smart Cities
Jan 30, 2023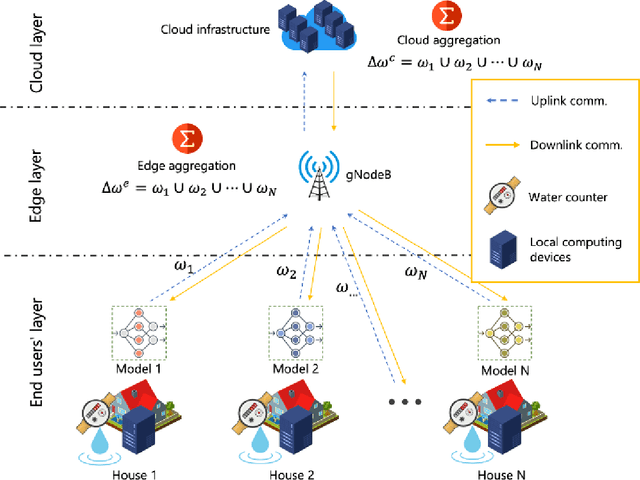
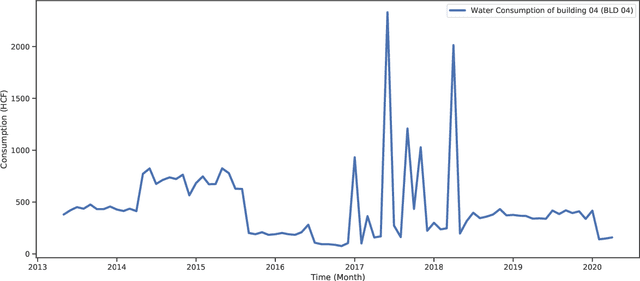
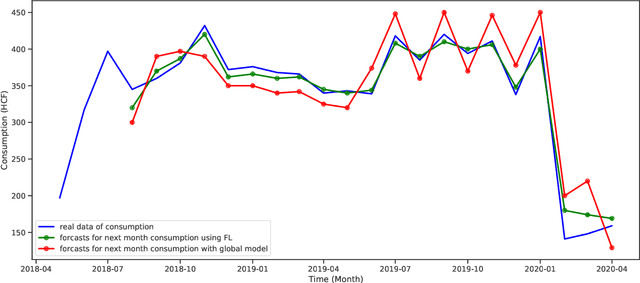
Water consumption remains a major concern among the world's future challenges. For applications like load monitoring and demand response, deep learning models are trained using enormous volumes of consumption data in smart cities. On the one hand, the information used is private. For instance, the precise information gathered by a smart meter that is a part of the system's IoT architecture at a consumer's residence may give details about the appliances and, consequently, the consumer's behavior at home. On the other hand, enormous data volumes with sufficient variation are needed for the deep learning models to be trained properly. This paper introduces a novel model for water consumption prediction in smart cities while preserving privacy regarding monthly consumption. The proposed approach leverages federated learning (FL) as a machine learning paradigm designed to train a machine learning model in a distributed manner while avoiding sharing the users data with a central training facility. In addition, this approach is promising to reduce the overhead utilization through decreasing the frequency of data transmission between the users and the central entity. Extensive simulation illustrate that the proposed approach shows an enhancement in predicting water consumption for different households.