 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EfficientMorph: Parameter-Efficient Transformer-Based Architecture for 3D Image Registration
Mar 16, 2024
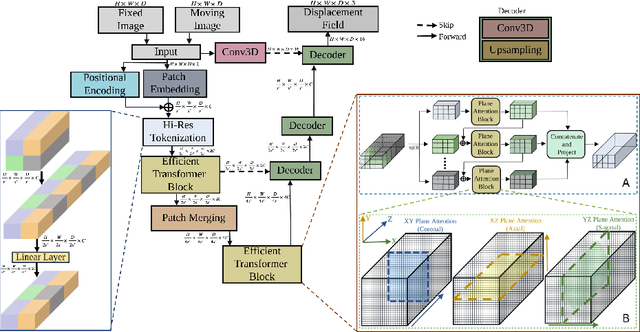
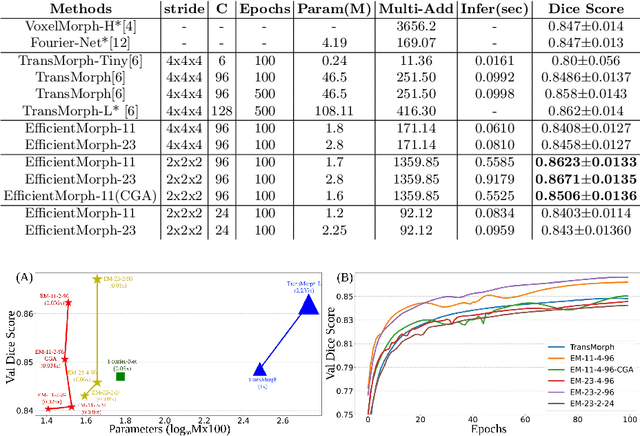
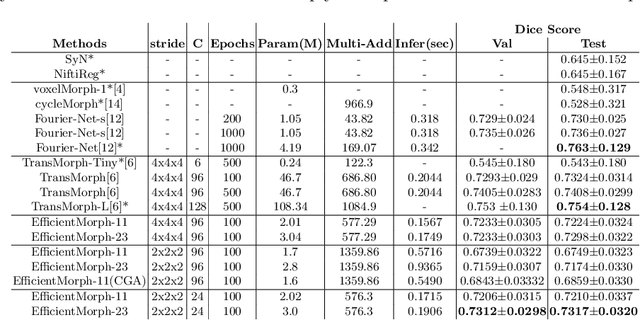
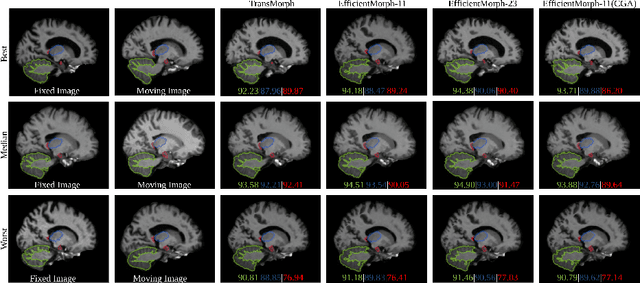
Transformers have emerged as the state-of-the-art architecture in medical image registration, outperforming convolutional neural networks (CNNs) by addressing their limited receptive fields and overcoming gradient instability in deeper models. Despite their success, transformer-based models require substantial resources for training, including data, memory, and computational power, which may restrict their applicability for end users with limited resources. In particular, existing transformer-based 3D image registration architectures face three critical gaps that challenge their efficiency and effectiveness. Firstly, while mitigating the quadratic complexity of full attention by focusing on local regions, window-based attention mechanisms often fail to adequately integrate local and global information. Secondly, feature similarities across attention heads that were recently found in multi-head attention architectures indicate a significant computational redundancy, suggesting that the capacity of the network could be better utilized to enhance performance. Lastly, the granularity of tokenization, a key factor in registration accuracy, presents a trade-off; smaller tokens improve detail capture at the cost of higher computational complexity, increased memory demands, and a risk of overfitting. Here, we propose EfficientMorph, a transformer-based architecture for unsupervised 3D image registration. It optimizes the balance between local and global attention through a plane-based attention mechanism, reduces computational redundancy via cascaded group attention, and captures fine details without compromising computational efficiency, thanks to a Hi-Res tokenization strategy complemented by merging operations. Notably, EfficientMorph sets a new benchmark for performance on the OASIS dataset with 16-27x fewer parameters.
TBI Image/Text (TBI-IT): Comprehensive Text and Image Datasets for Traumatic Brain Injury Research
Mar 14, 2024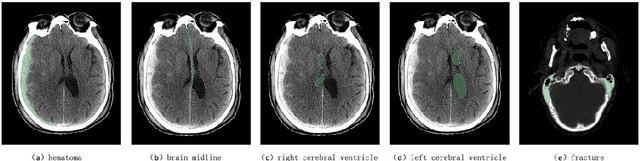

In this paper, we introduce a new dataset in the medical field of Traumatic Brain Injury (TBI), called TBI-IT, which includes both electronic medical records (EMRs) and head CT images. This dataset is designed to enhance the accuracy of artificial intelligence in the diagnosis and treatment of TBI. This dataset, built upon the foundation of standard text and image data, incorporates specific annotations within the EMRs, extracting key content from the text information, and categorizes the annotation content of imaging data into five types: brain midline, hematoma, left cerebral ventricle, right cerebral ventricle and fracture. TBI-IT aims to be a foundational dataset for feature learning in image segmentation tasks and named entity recognition.
Online and Offline Evaluation in Search Clarification
Mar 14, 2024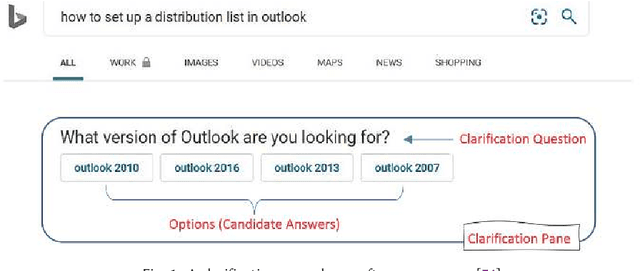
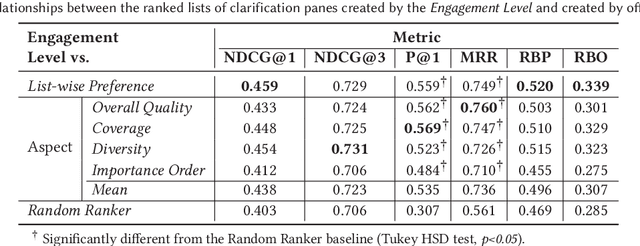
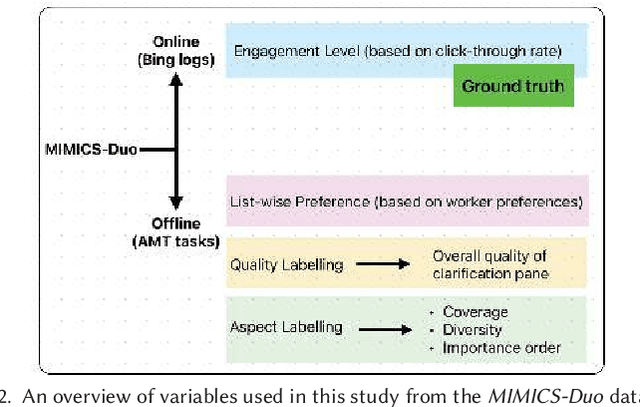
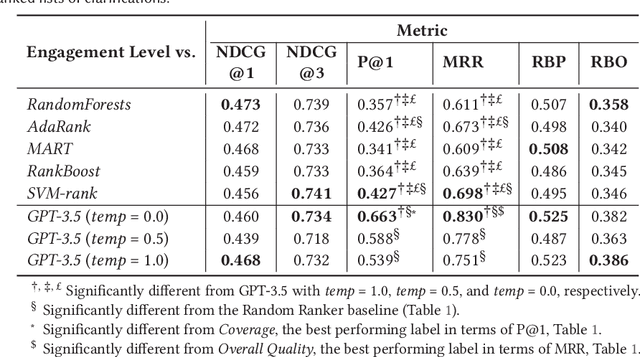
The effectiveness of clarification question models in engaging users within search systems is currently constrained, casting doubt on their overall usefulness. To improve the performance of these models, it is crucial to employ assessment approaches that encompass both real-time feedback from users (online evaluation) and the characteristics of clarification questions evaluated through human assessment (offline evaluation). However, the relationship between online and offline evaluations has been debated in information retrieval. This study aims to investigate how this discordance holds in search clarification. We use user engagement as ground truth and employ several offline labels to investigate to what extent the offline ranked lists of clarification resemble the ideal ranked lists based on online user engagement.
Hierarchical Auto-Organizing System for Open-Ended Multi-Agent Navigation
Mar 13, 2024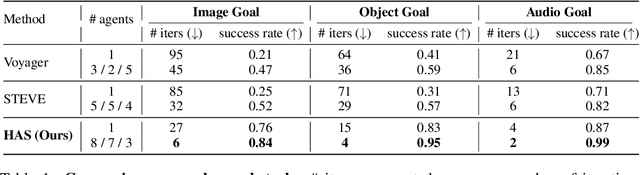
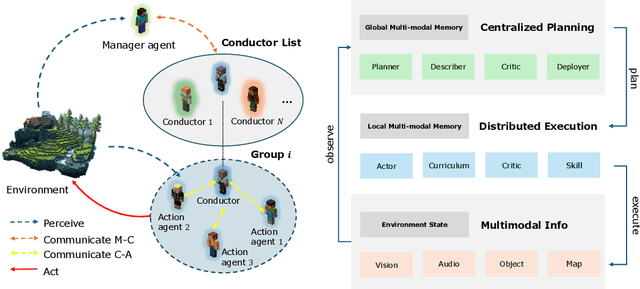
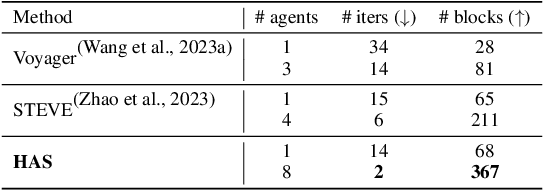
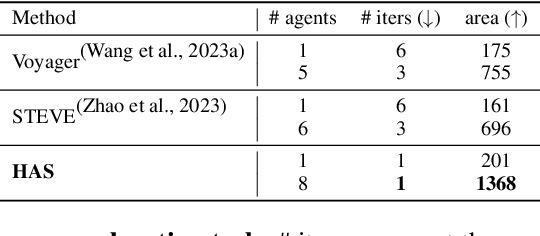
Navigating complex environments in Minecraft poses significant challenges for multi-agent systems due to the game's dynamic and unpredictable open-world setting. Agents need to interact with the environment and coordinate their actions with other agents to achieve common objectives. However, traditional approaches often struggle to efficiently manage inter-agent communication and task distribution, which are crucial for effective multi-agent navigation. Furthermore, processing and integrating multi-modal information (such as visual, textual, and auditory data) is essential for agents to fully comprehend their goals and navigate the environment successfully. To address this issue, we design the HAS framework to auto-organize groups of LLM-based agents to complete Navigation tasks. In our approach, we devise a hierarchical auto-organizing navigation system, which is characterized by 1) a hierarchical system for multi-agent organization, ensuring centralized planning and decentralized execution; 2) an auto-organizing and intra-communication mechanism, enabling dynamic group adjustment under subtasks; 3) a multi-modal information platform, facilitating multi-modal perception to perform the three navigation tasks with one system. To assess organizational behavior, we design a series of navigation tasks in the Minecraft environment, which includes searching and exploring. We aim to develop embodied organizations that push the boundaries of embodied AI, moving it towards a more human-like organizational structure.
Monocular Microscope to CT Registration using Pose Estimation of the Incus for Augmented Reality Cochlear Implant Surgery
Mar 12, 2024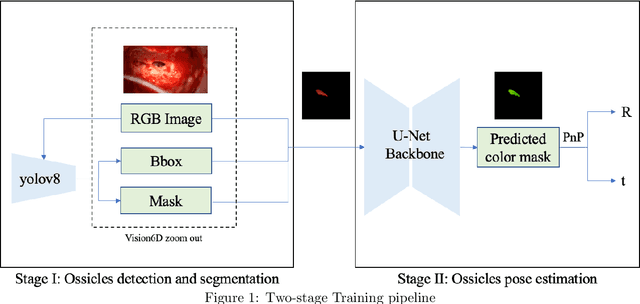

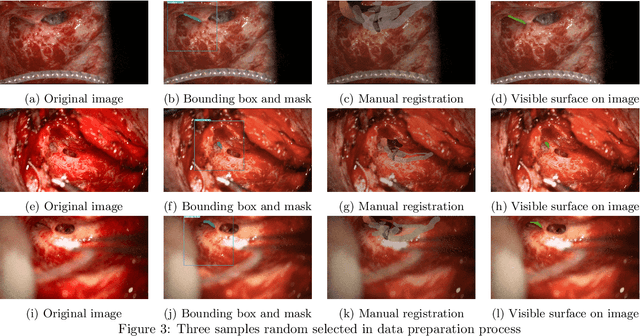

For those experiencing severe-to-profound sensorineural hearing loss, the cochlear implant (CI) is the preferred treatment. Augmented reality (AR) aided surgery can potentially improve CI procedures and hearing outcomes. Typically, AR solutions for image-guided surgery rely on optical tracking systems to register pre-operative planning information to the display so that hidden anatomy or other important information can be overlayed and co-registered with the view of the surgical scene. In this paper, our goal is to develop a method that permits direct 2D-to-3D registration of the microscope video to the pre-operative Computed Tomography (CT) scan without the need for external tracking equipment. Our proposed solution involves using surface mapping of a portion of the incus in surgical recordings and determining the pose of this structure relative to the surgical microscope by performing pose estimation via the perspective-n-point (PnP) algorithm. This registration can then be applied to pre-operative segmentations of other anatomy-of-interest, as well as the planned electrode insertion trajectory to co-register this information for the AR display. Our results demonstrate the accuracy with an average rotation error of less than 25 degrees and a translation error of less than 2 mm, 3 mm, and 0.55% for the x, y, and z axes, respectively. Our proposed method has the potential to be applicable and generalized to other surgical procedures while only needing a monocular microscope during intra-operation.
Gabor-guided transformer for single image deraining
Mar 12, 2024
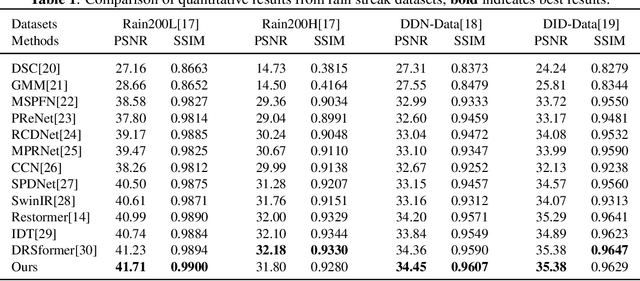
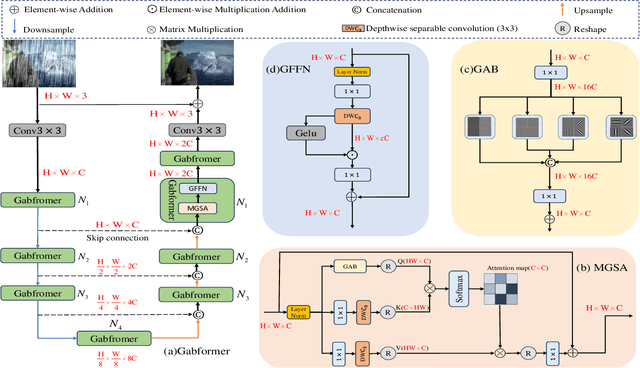

Image deraining have have gained a great deal of attention in order to address the challenges posed by the effects of harsh weather conditions on visual tasks. While convolutional neural networks (CNNs) are popular, their limitations in capturing global information may result in ineffective rain removal. Transformer-based methods with self-attention mechanisms have improved, but they tend to distort high-frequency details that are crucial for image fidelity. To solve this problem, we propose the Gabor-guided tranformer (Gabformer) for single image deraining. The focus on local texture features is enhanced by incorporating the information processed by the Gabor filter into the query vector, which also improves the robustness of the model to noise due to the properties of the filter. Extensive experiments on the benchmarks demonstrate that our method outperforms state-of-the-art approaches.
DyRoNet: A Low-Rank Adapter Enhanced Dynamic Routing Network for Streaming Perception
Mar 15, 2024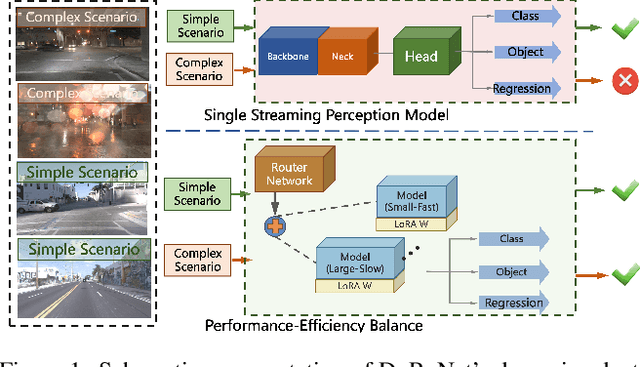
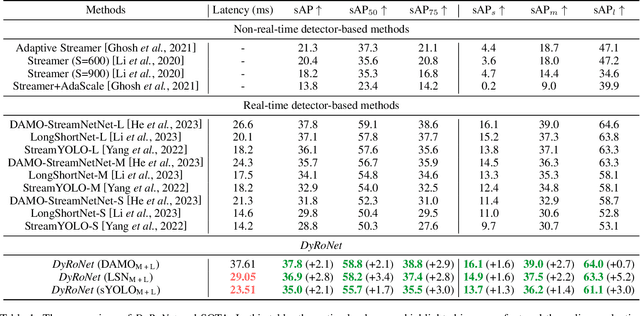
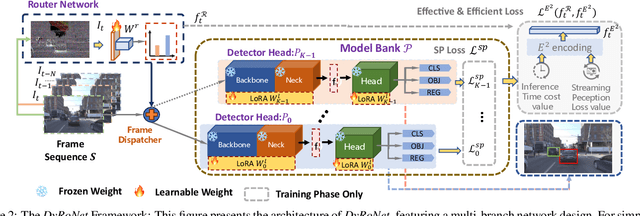
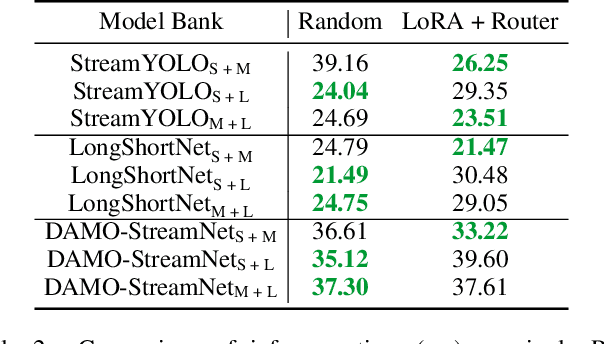
The quest for real-time, accurate environmental perception is pivotal in the evolution of autonomous driving technologies. In response to this challenge, we present DyRoNet, a Dynamic Router Network that innovates by incorporating low-rank dynamic routing to enhance streaming perception. DyRoNet distinguishes itself by seamlessly integrating a diverse array of specialized pre-trained branch networks, each meticulously fine-tuned for specific environmental contingencies, thus facilitating an optimal balance between response latency and detection precision. Central to DyRoNet's architecture is the Speed Router module, which employs an intelligent routing mechanism to dynamically allocate input data to the most suitable branch network, thereby ensuring enhanced performance adaptability in real-time scenarios. Through comprehensive evaluations, DyRoNet demonstrates superior adaptability and significantly improved performance over existing methods, efficiently catering to a wide variety of environmental conditions and setting new benchmarks in streaming perception accuracy and efficiency. Beyond establishing a paradigm in autonomous driving perception, DyRoNet also offers engineering insights and lays a foundational framework for future advancements in streaming perception. For further information and updates on the project, visit https://tastevision.github.io/DyRoNet/.
Shifting Focus: From Global Semantics to Local Prominent Features in Swin-Transformer for Knee Osteoarthritis Severity Assessment
Mar 15, 2024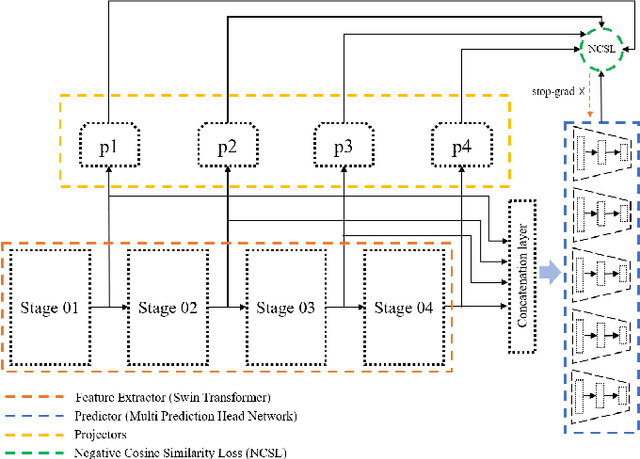
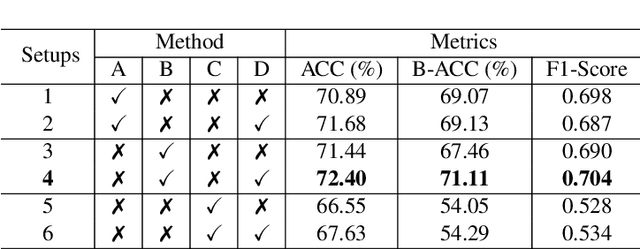
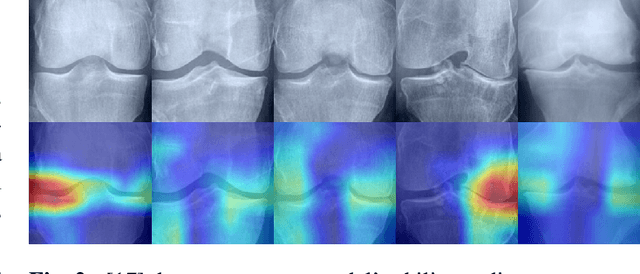
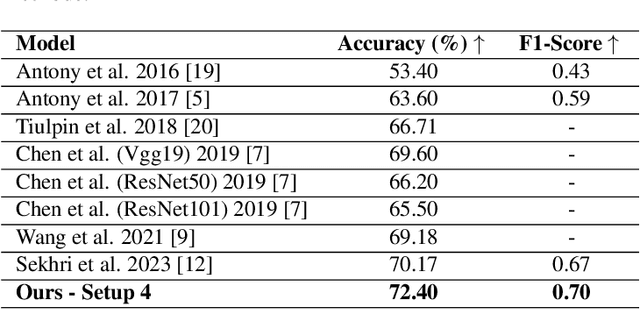
Conventional imaging diagnostics frequently encounter bottlenecks due to manual inspection, which can lead to delays and inconsistencies. Although deep learning offers a pathway to automation and enhanced accuracy, foundational models in computer vision often emphasize global context at the expense of local details, which are vital for medical imaging diagnostics. To address this, we harness the Swin Transformer's capacity to discern extended spatial dependencies within images through the hierarchical framework. Our novel contribution lies in refining local feature representations, orienting them specifically toward the final distribution of the classifier. This method ensures that local features are not only preserved but are also enriched with task-specific information, enhancing their relevance and detail at every hierarchical level. By implementing this strategy, our model demonstrates significant robustness and precision, as evidenced by extensive validation of two established benchmarks for Knee OsteoArthritis (KOA) grade classification. These results highlight our approach's effectiveness and its promising implications for the future of medical imaging diagnostics. Our implementation is available on https://github.com/mtliba/KOA_NLCS2024
Variance-Dependent Regret Bounds for Non-stationary Linear Bandits
Mar 15, 2024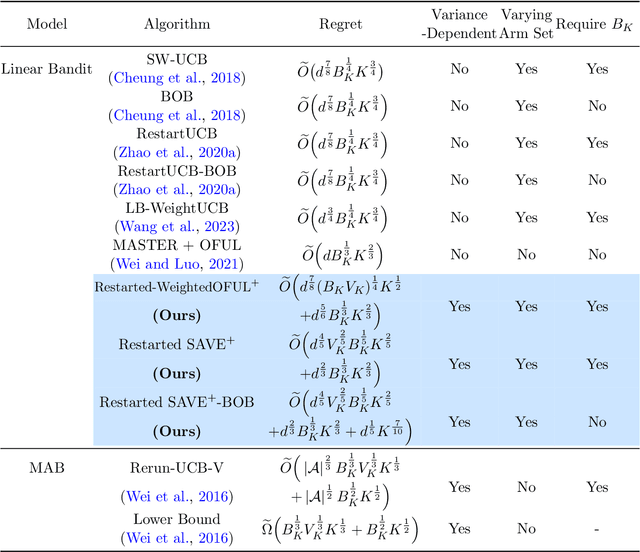
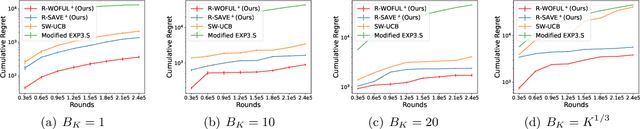
We investigate the non-stationary stochastic linear bandit problem where the reward distribution evolves each round. Existing algorithms characterize the non-stationarity by the total variation budget $B_K$, which is the summation of the change of the consecutive feature vectors of the linear bandits over $K$ rounds. However, such a quantity only measures the non-stationarity with respect to the expectation of the reward distribution, which makes existing algorithms sub-optimal under the general non-stationary distribution setting. In this work, we propose algorithms that utilize the variance of the reward distribution as well as the $B_K$, and show that they can achieve tighter regret upper bounds. Specifically, we introduce two novel algorithms: Restarted Weighted$\text{OFUL}^+$ and Restarted $\text{SAVE}^+$. These algorithms address cases where the variance information of the rewards is known and unknown, respectively. Notably, when the total variance $V_K$ is much smaller than $K$, our algorithms outperform previous state-of-the-art results on non-stationary stochastic linear bandits under different settings. Experimental evaluations further validate the superior performance of our proposed algorithms over existing works.
Belief Aided Navigation using Bayesian Reinforcement Learning for Avoiding Humans in Blind Spots
Mar 15, 2024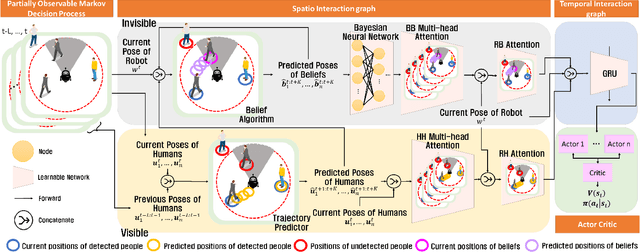
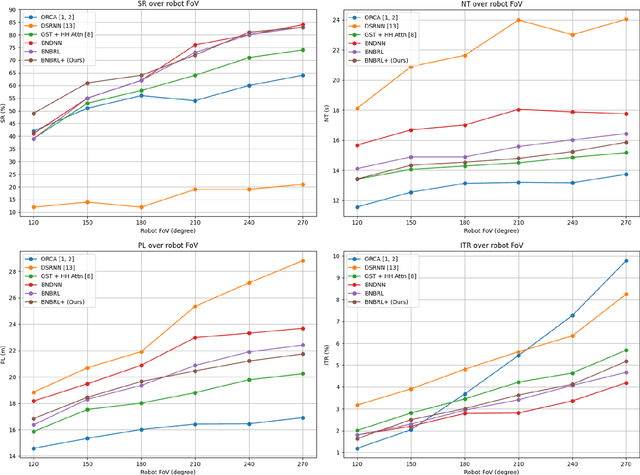
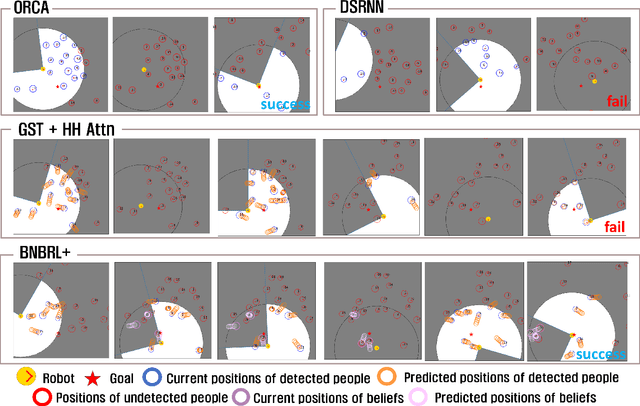
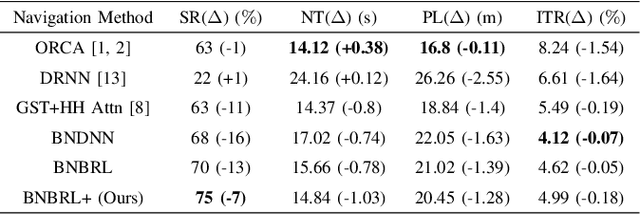
Recent research on mobile robot navigation has focused on socially aware navigation in crowded environments. However, existing methods do not adequately account for human robot interactions and demand accurate location information from omnidirectional sensors, rendering them unsuitable for practical applications. In response to this need, this study introduces a novel algorithm, BNBRL+, predicated on the partially observable Markov decision process framework to assess risks in unobservable areas and formulate movement strategies under uncertainty. BNBRL+ consolidates belief algorithms with Bayesian neural networks to probabilistically infer beliefs based on the positional data of humans. It further integrates the dynamics between the robot, humans, and inferred beliefs to determine the navigation paths and embeds social norms within the reward function, thereby facilitating socially aware navigation. Through experiments in various risk laden scenarios, this study validates the effectiveness of BNBRL+ in navigating crowded environments with blind spots. The model's ability to navigate effectively in spaces with limited visibility and avoid obstacles dynamically can significantly improve the safety and reliability of autonomous vehicles.