 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Characterizing the Optimal 0-1 Loss for Multi-class Classification with a Test-time Attacker
Feb 21, 2023
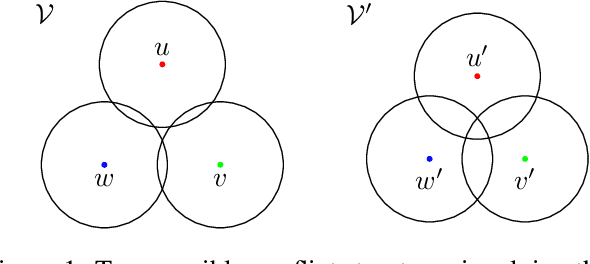
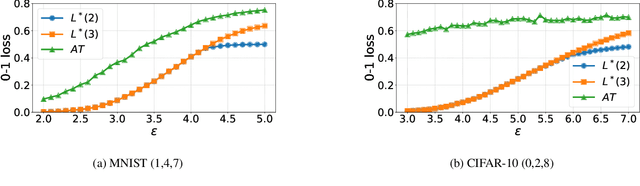
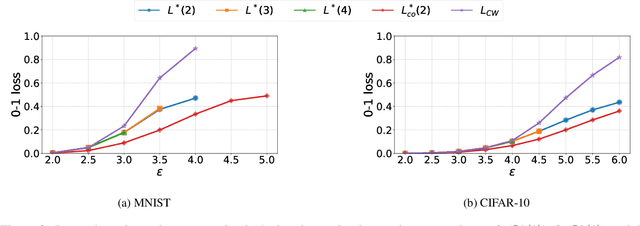
Finding classifiers robust to adversarial examples is critical for their safe deployment. Determining the robustness of the best possible classifier under a given threat model for a given data distribution and comparing it to that achieved by state-of-the-art training methods is thus an important diagnostic tool. In this paper, we find achievable information-theoretic lower bounds on loss in the presence of a test-time attacker for multi-class classifiers on any discrete dataset. We provide a general framework for finding the optimal 0-1 loss that revolves around the construction of a conflict hypergraph from the data and adversarial constraints. We further define other variants of the attacker-classifier game that determine the range of the optimal loss more efficiently than the full-fledged hypergraph construction. Our evaluation shows, for the first time, an analysis of the gap to optimal robustness for classifiers in the multi-class setting on benchmark datasets.
A Framework for UAV-based Distributed Sensing Under Half-Duplex Operation
Feb 21, 2023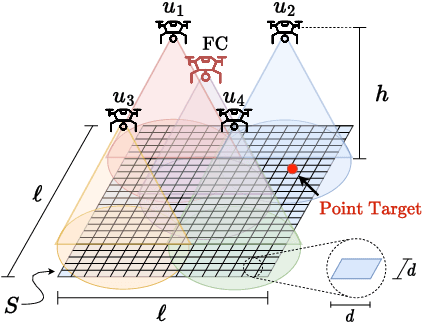
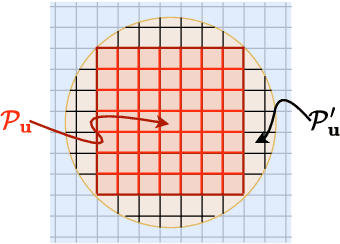
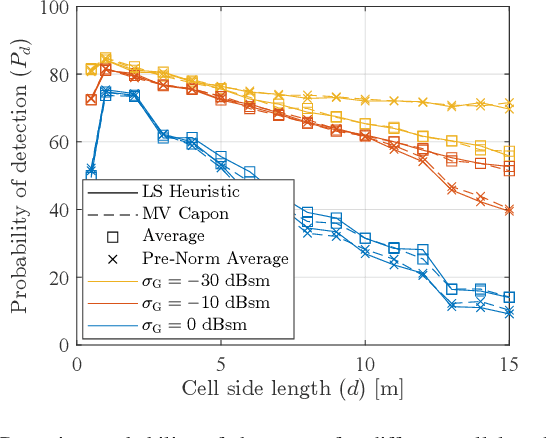
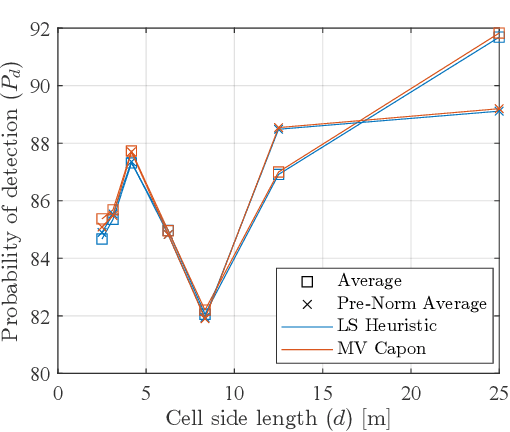
This paper proposes an unmanned aerial vehicle (UAV)-based distributed sensing framework that uses frequency-division multiplexing (OFDM) waveforms to detect the position of a ground target under half-duplex operation. The area of interest, where the target is located, is sectioned into a grid of cells, where the radar cross-section (RCS) of every cell is jointly estimated by the UAVs, and a central node acts as a fusion center by receiving all the estimations and performing information-level fusion. For local estimation at each UAV, the periodogram approach is utilised, and a digital receive beamformer is assumed. The fused RCS estimates of the grid are used to estimate the cell containing the target. Monte Carlo simulations are performed to obtain the detection probability of the proposed framework, and our results show that the proposed framework attains improved accuracy for the detection of a target than other OFDM bi-static radar approaches proposed in the literature.
DasFormer: Deep Alternating Spectrogram Transformer for Multi/Single-Channel Speech Separation
Feb 21, 2023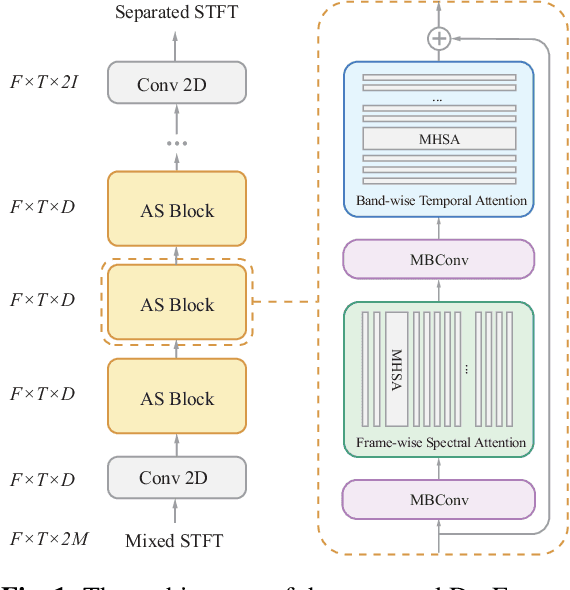
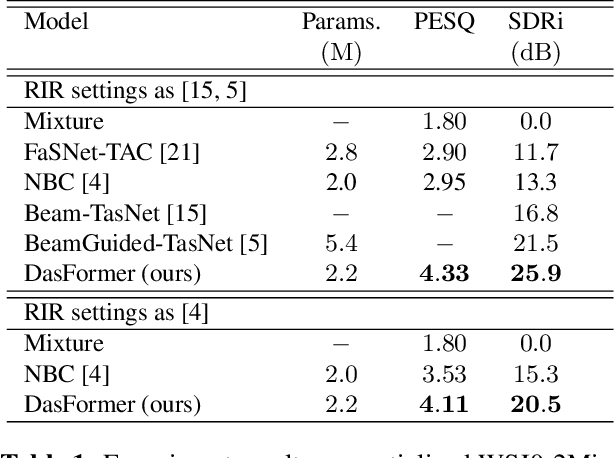
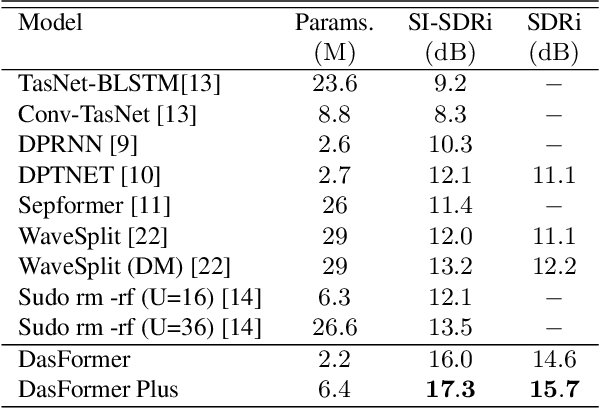
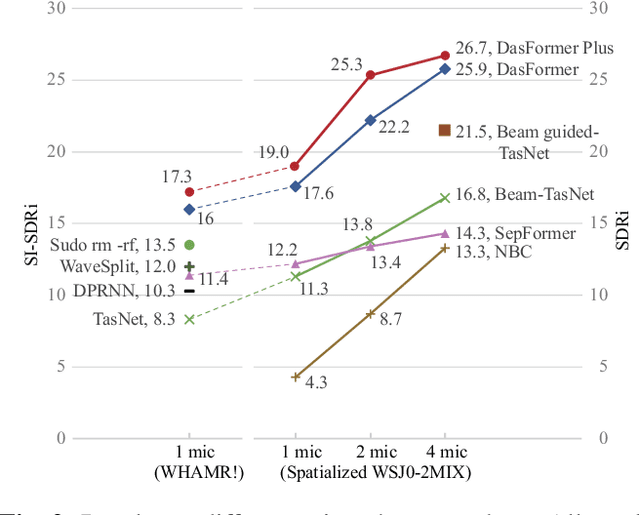
For the task of speech separation, previous study usually treats multi-channel and single-channel scenarios as two research tracks with specialized solutions developed respectively. Instead, we propose a simple and unified architecture - DasFormer (Deep alternating spectrogram transFormer) to handle both of them in the challenging reverberant environments. Unlike frame-wise sequence modeling, each TF-bin in the spectrogram is assigned with an embedding encoding spectral and spatial information. With such input, DasFormer is then formed by multiple repetition of simple blocks each of which integrates 1) two multi-head self-attention (MHSA) modules alternately processing within each frequency bin & temporal frame of the spectrogram 2) MBConv before each MHSA for modeling local features on the spectrogram. Experiments show that DasFormer has a powerful ability to model the time-frequency representation, whose performance far exceeds the current SOTA models in multi-channel speech separation, and also single-channel SOTA in the more challenging yet realistic reverberation scenario.
Dealing with Collinearity in Large-Scale Linear System Identification Using Gaussian Regression
Feb 28, 2023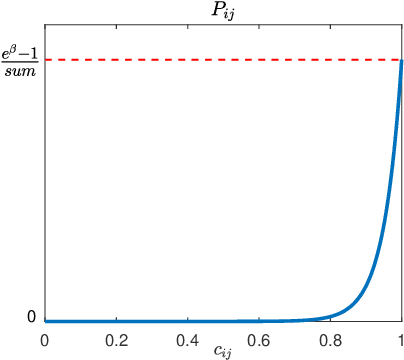
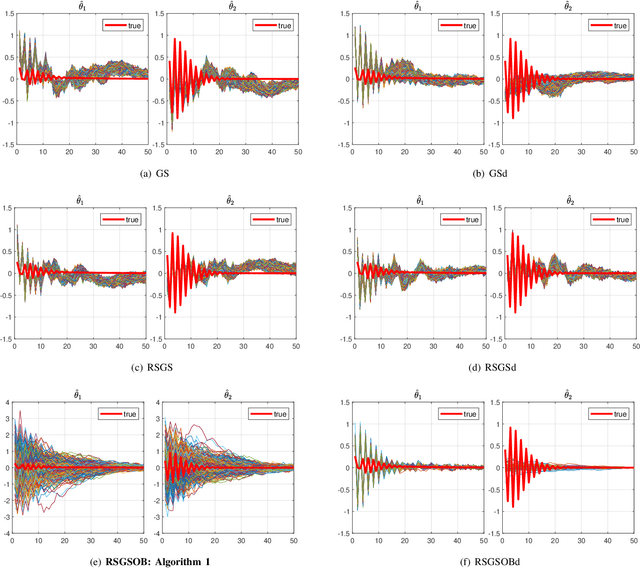
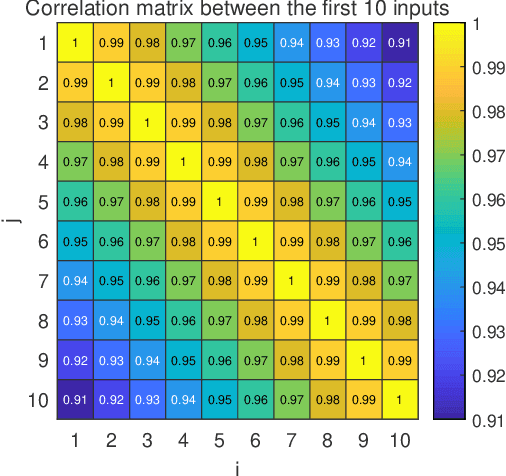
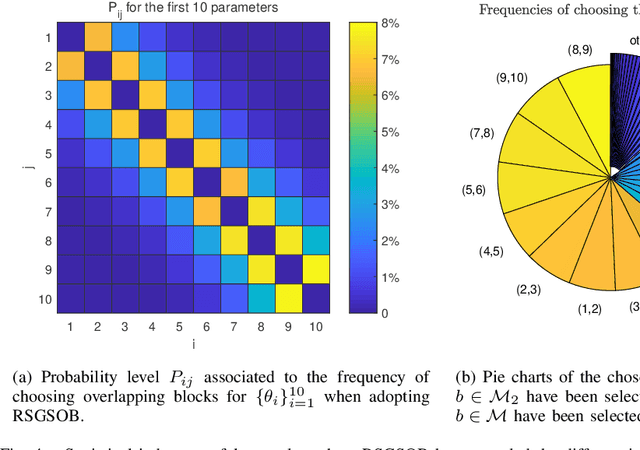
Many problems arising in control require the determination of a mathematical model of the application. This has often to be performed starting from input-output data, leading to a task known as system identification in the engineering literature. One emerging topic in this field is estimation of networks consisting of several interconnected dynamic systems. We consider the linear setting assuming that system outputs are the result of many correlated inputs, hence making system identification severely ill-conditioned. This is a scenario often encountered when modeling complex cybernetics systems composed by many sub-units with feedback and algebraic loops. We develop a strategy cast in a Bayesian regularization framework where any impulse response is seen as realization of a zero-mean Gaussian process. Any covariance is defined by the so called stable spline kernel which includes information on smooth exponential decay. We design a novel Markov chain Monte Carlo scheme able to reconstruct the impulse responses posterior by efficiently dealing with collinearity. Our scheme relies on a variation of the Gibbs sampling technique: beyond considering blocks forming a partition of the parameter space, some other (overlapping) blocks are also updated on the basis of the level of collinearity of the system inputs. Theoretical properties of the algorithm are studied obtaining its convergence rate. Numerical experiments are included using systems containing hundreds of impulse responses and highly correlated inputs.
Active Velocity Estimation using Light Curtains via Self-Supervised Multi-Armed Bandits
Feb 28, 2023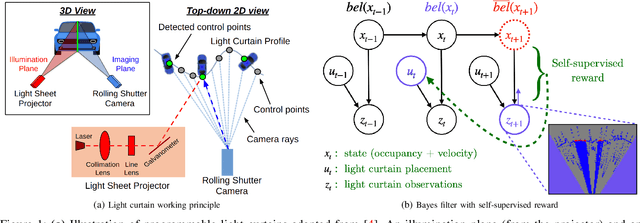
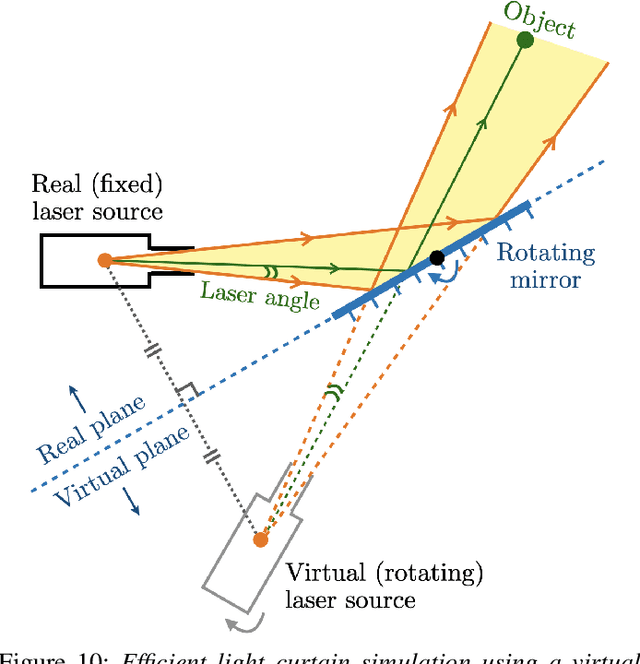

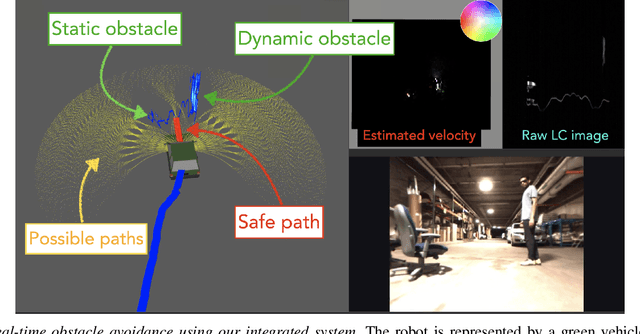
To navigate in an environment safely and autonomously, robots must accurately estimate where obstacles are and how they move. Instead of using expensive traditional 3D sensors, we explore the use of a much cheaper, faster, and higher resolution alternative: programmable light curtains. Light curtains are a controllable depth sensor that sense only along a surface that the user selects. We adapt a probabilistic method based on particle filters and occupancy grids to explicitly estimate the position and velocity of 3D points in the scene using partial measurements made by light curtains. The central challenge is to decide where to place the light curtain to accurately perform this task. We propose multiple curtain placement strategies guided by maximizing information gain and verifying predicted object locations. Then, we combine these strategies using an online learning framework. We propose a novel self-supervised reward function that evaluates the accuracy of current velocity estimates using future light curtain placements. We use a multi-armed bandit framework to intelligently switch between placement policies in real time, outperforming fixed policies. We develop a full-stack navigation system that uses position and velocity estimates from light curtains for downstream tasks such as localization, mapping, path-planning, and obstacle avoidance. This work paves the way for controllable light curtains to accurately, efficiently, and purposefully perceive and navigate complex and dynamic environments. Project website: https://siddancha.github.io/projects/active-velocity-estimation/
Neural Stochastic Agent-Based Limit Order Book Simulation: A Hybrid Methodology
Feb 28, 2023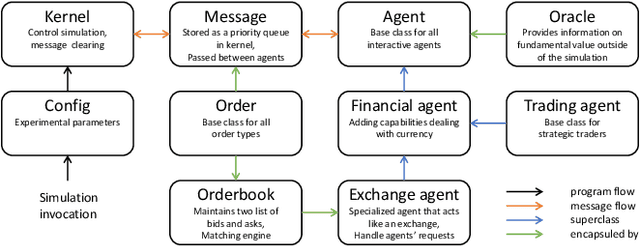

Modern financial exchanges use an electronic limit order book (LOB) to store bid and ask orders for a specific financial asset. As the most fine-grained information depicting the demand and supply of an asset, LOB data is essential in understanding market dynamics. Therefore, realistic LOB simulations offer a valuable methodology for explaining empirical properties of markets. Mainstream simulation models include agent-based models (ABMs) and stochastic models (SMs). However, ABMs tend not to be grounded on real historical data, while SMs tend not to enable dynamic agent-interaction. To overcome these limitations, we propose a novel hybrid LOB simulation paradigm characterised by: (1) representing the aggregation of market events' logic by a neural stochastic background trader that is pre-trained on historical LOB data through a neural point process model; and (2) embedding the background trader in a multi-agent simulation with other trading agents. We instantiate this hybrid NS-ABM model using the ABIDES platform. We first run the background trader in isolation and show that the simulated LOB can recreate a comprehensive list of stylised facts that demonstrate realistic market behaviour. We then introduce a population of `trend' and `value' trading agents, which interact with the background trader. We show that the stylised facts remain and we demonstrate order flow impact and financial herding behaviours that are in accordance with empirical observations of real markets.
Learned Risk Metric Maps for Kinodynamic Systems
Feb 28, 2023

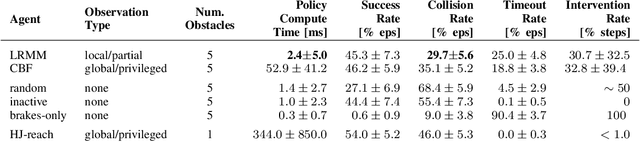
We present Learned Risk Metric Maps (LRMM) for real-time estimation of coherent risk metrics of high dimensional dynamical systems operating in unstructured, partially observed environments. LRMM models are simple to design and train -- requiring only procedural generation of obstacle sets, state and control sampling, and supervised training of a function approximator -- which makes them broadly applicable to arbitrary system dynamics and obstacle sets. In a parallel autonomy setting, we demonstrate the model's ability to rapidly infer collision probabilities of a fast-moving car-like robot driving recklessly in an obstructed environment; allowing the LRMM agent to intervene, take control of the vehicle, and avoid collisions. In this time-critical scenario, we show that LRMMs can evaluate risk metrics 20-100x times faster than alternative safety algorithms based on control barrier functions (CBFs) and Hamilton-Jacobi reachability (HJ-reach), leading to 5-15\% fewer obstacle collisions by the LRMM agent than CBFs and HJ-reach. This performance improvement comes in spite of the fact that the LRMM model only has access to local/partial observation of obstacles, whereas the CBF and HJ-reach agents are granted privileged/global information. We also show that our model can be equally well trained on a 12-dimensional quadrotor system operating in an obstructed indoor environment. The LRMM codebase is provided at https://github.com/mit-drl/pyrmm.
DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
Feb 28, 2023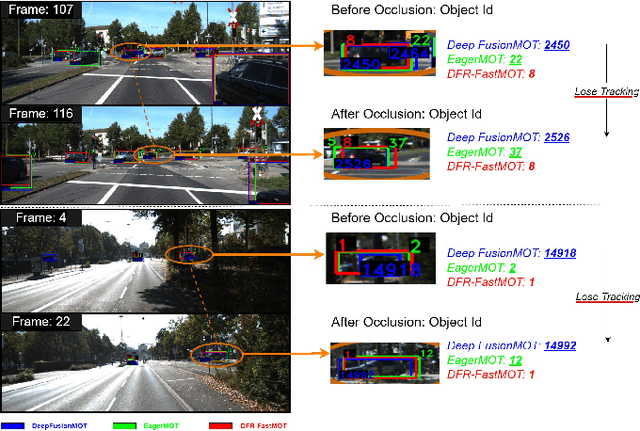
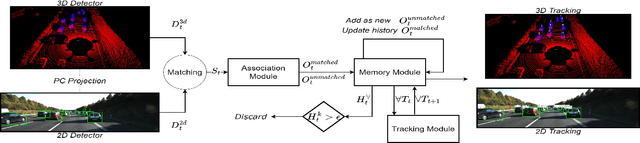

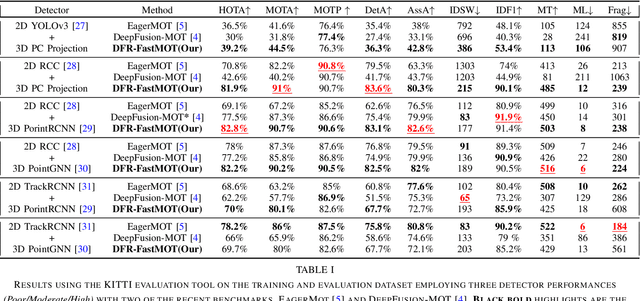
Persistent multi-object tracking (MOT) allows autonomous vehicles to navigate safely in highly dynamic environments. One of the well-known challenges in MOT is object occlusion when an object becomes unobservant for subsequent frames. The current MOT methods store objects information, like objects' trajectory, in internal memory to recover the objects after occlusions. However, they retain short-term memory to save computational time and avoid slowing down the MOT method. As a result, they lose track of objects in some occlusion scenarios, particularly long ones. In this paper, we propose DFR-FastMOT, a light MOT method that uses data from a camera and LiDAR sensors and relies on an algebraic formulation for object association and fusion. The formulation boosts the computational time and permits long-term memory that tackles more occlusion scenarios. Our method shows outstanding tracking performance over recent learning and non-learning benchmarks with about 3% and 4% margin in MOTA, respectively. Also, we conduct extensive experiments that simulate occlusion phenomena by employing detectors with various distortion levels. The proposed solution enables superior performance under various distortion levels in detection over current state-of-art methods. Our framework processes about 7,763 frames in 1.48 seconds, which is seven times faster than recent benchmarks. The framework will be available at https://github.com/MohamedNagyMostafa/DFR-FastMOT.
Safe-DS: A Domain Specific Language to Make Data Science Safe
Feb 28, 2023
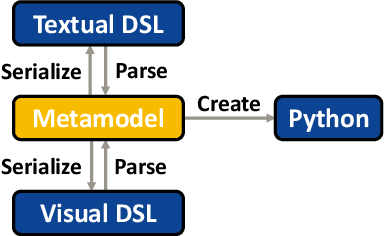
Due to the long runtime of Data Science (DS) pipelines, even small programming mistakes can be very costly, if they are not detected statically. However, even basic static type checking of DS pipelines is difficult because most are written in Python. Static typing is available in Python only via external linters. These require static type annotations for parameters or results of functions, which many DS libraries do not provide. In this paper, we show how the wealth of Python DS libraries can be used in a statically safe way via Safe-DS, a domain specific language (DSL) for DS. Safe-DS catches conventional type errors plus errors related to range restrictions, data manipulation, and call order of functions, going well beyond the abilities of current Python linters. Python libraries are integrated into Safe-DS via a stub language for specifying the interface of its declarations, and an API-Editor that is able to extract type information from the code and documentation of Python libraries, and automatically generate suitable stubs. Moreover, Safe-DS complements textual DS pipelines with a graphical representation that eases safe development by preventing syntax errors. The seamless synchronization of textual and graphic view lets developers always choose the one best suited for their skills and current task. We think that Safe-DS can make DS development easier, faster, and more reliable, significantly reducing development costs.
Bayesian Kernelized Tensor Factorization as Surrogate for Bayesian Optimization
Feb 28, 2023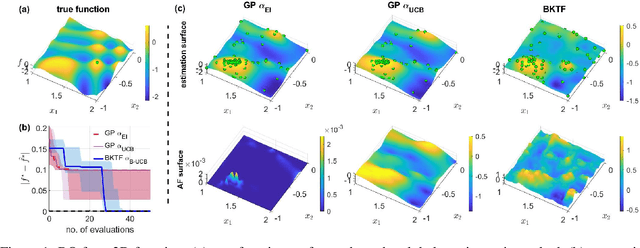
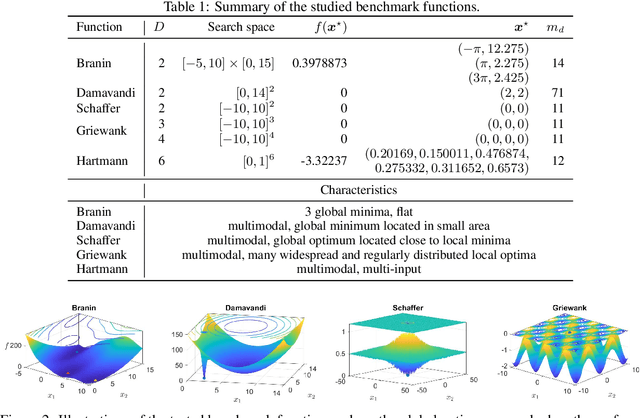
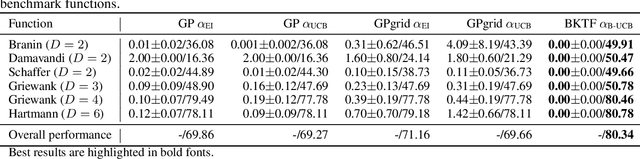
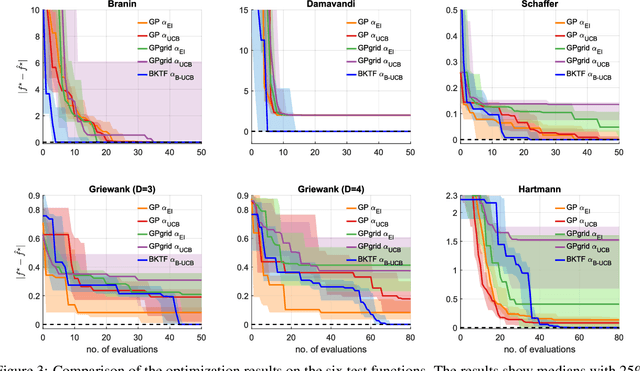
Bayesian optimization (BO) primarily uses Gaussian processes (GP) as the key surrogate model, mostly with a simple stationary and separable kernel function such as the widely used squared-exponential kernel with automatic relevance determination (SE-ARD). However, such simple kernel specifications are deficient in learning functions with complex features, such as being nonstationary, nonseparable, and multimodal. Approximating such functions using a local GP, even in a low-dimensional space, will require a large number of samples, not to mention in a high-dimensional setting. In this paper, we propose to use Bayesian Kernelized Tensor Factorization (BKTF) -- as a new surrogate model -- for BO in a D-dimensional Cartesian product space. Our key idea is to approximate the underlying D-dimensional solid with a fully Bayesian low-rank tensor CP decomposition, in which we place GP priors on the latent basis functions for each dimension to encode local consistency and smoothness. With this formulation, information from each sample can be shared not only with neighbors but also across dimensions. Although BKTF no longer has an analytical posterior, we can still efficiently approximate the posterior distribution through Markov chain Monte Carlo (MCMC) and obtain prediction and full uncertainty quantification (UQ). We conduct numerical experiments on both standard BO testing problems and machine learning hyperparameter tuning problems, and our results confirm the superiority of BKTF in terms of sample efficiency.