 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-DS: A Domain Specific Language to Make Data Science Safe
Feb 28, 2023Due to the long runtime of Data Science (DS) pipelines, even small programming mistakes can be very costly, if they are not detected statically. However, even basic static type checking of DS pipelines is difficult because most are written in Python. Static typing is available in Python only via external linters. These require static type annotations for parameters or results of functions, which many DS libraries do not provide. In this paper, we show how the wealth of Python DS libraries can be used in a statically safe way via Safe-DS, a domain specific language (DSL) for DS. Safe-DS catches conventional type errors plus errors related to range restrictions, data manipulation, and call order of functions, going well beyond the abilities of current Python linters. Python libraries are integrated into Safe-DS via a stub language for specifying the interface of its declarations, and an API-Editor that is able to extract type information from the code and documentation of Python libraries, and automatically generate suitable stubs. Moreover, Safe-DS complements textual DS pipelines with a graphical representation that eases safe development by preventing syntax errors. The seamless synchronization of textual and graphic view lets developers always choose the one best suited for their skills and current task. We think that Safe-DS can make DS development easier, faster, and more reliable, significantly reducing development costs.
Improving the Learnability of Machine Learning APIs by Semi-Automated API Wrapping
Apr 06, 2022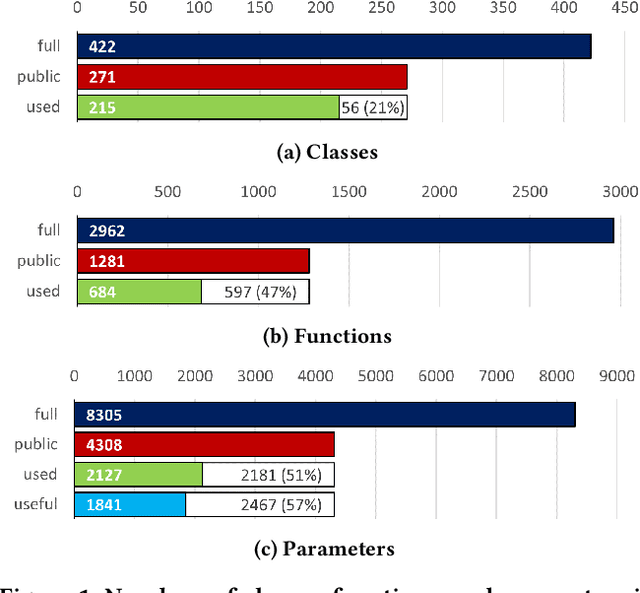

A major hurdle for students and professional software developers who want to enter the world of machine learning (ML), is mastering not just the scientific background but also the available ML APIs. Therefore, we address the challenge of creating APIs that are easy to learn and use, especially by novices. However, it is not clear how this can be achieved without compromising expressiveness. We investigate this problem for scikit-learn, a widely used ML API. In this paper, we analyze its use by the Kaggle community, identifying unused and apparently useless parts of the API that can be eliminated without affecting client programs. In addition, we discuss usability issues in the remaining parts, propose related design improvements and show how they can be implemented by semi-automated wrapping of the existing third-party API.
Achieving Guidance in Applied Machine Learning through Software Engineering Techniques
Mar 29, 2022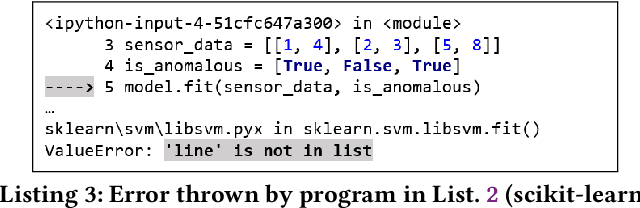

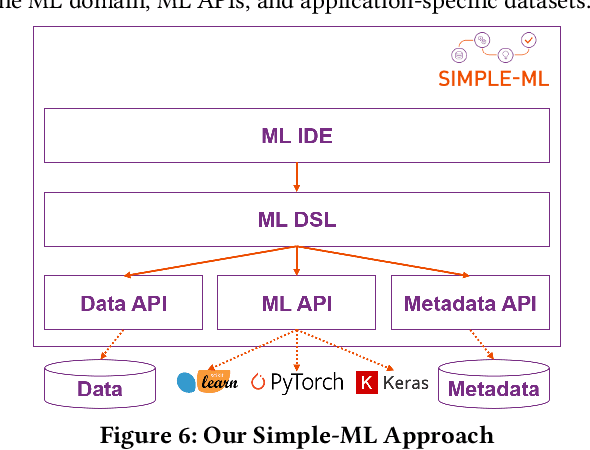
Development of machine learning (ML) applications is hard. Producing successful applications requires, among others, being deeply familiar with a variety of complex and quickly evolving application programming interfaces (APIs). It is therefore critical to understand what prevents developers from learning these APIs, using them properly at development time, and understanding what went wrong when it comes to debugging. We look at the (lack of) guidance that currently used development environments and ML APIs provide to developers of ML applications, contrast these with software engineering best practices, and identify gaps in the current state of the art. We show that current ML tools fall short of fulfilling some basic software engineering gold standards and point out ways in which software engineering concepts, tools and techniques need to be extended and adapted to match the special needs of ML application development. Our findings point out ample opportunities for research on ML-specific software engineering.