 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SRFormer: Permuted Self-Attention for Single Image Super-Resolution
Mar 17, 2023
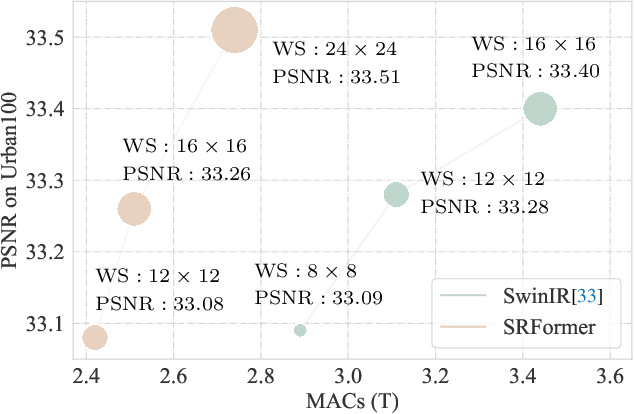
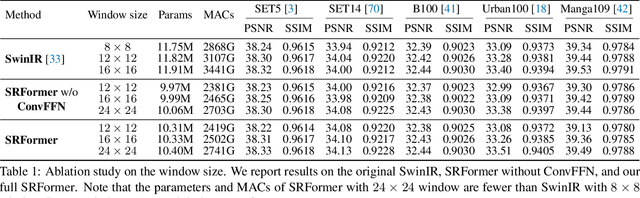

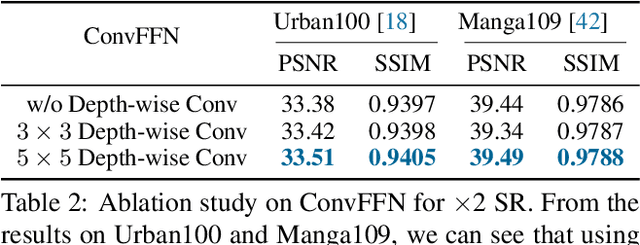
Previous works have shown that increasing the window size for Transformer-based image super-resolution models (e.g., SwinIR) can significantly improve the model performance but the computation overhead is also considerable. In this paper, we present SRFormer, a simple but novel method that can enjoy the benefit of large window self-attention but introduces even less computational burden. The core of our SRFormer is the permuted self-attention (PSA), which strikes an appropriate balance between the channel and spatial information for self-attention. Our PSA is simple and can be easily applied to existing super-resolution networks based on window self-attention. Without any bells and whistles, we show that our SRFormer achieves a 33.86dB PSNR score on the Urban100 dataset, which is 0.46dB higher than that of SwinIR but uses fewer parameters and computations. We hope our simple and effective approach can serve as a useful tool for future research in super-resolution model design.
Contrastive Self-supervised Learning in Recommender Systems: A Survey
Mar 17, 2023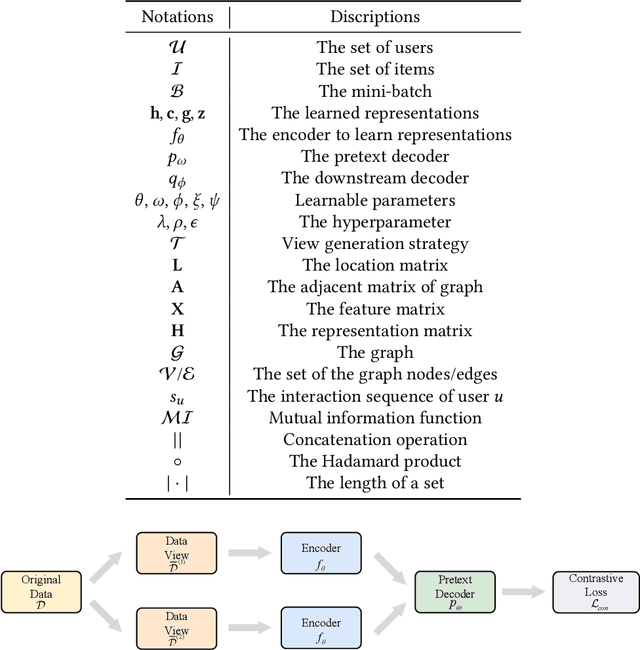
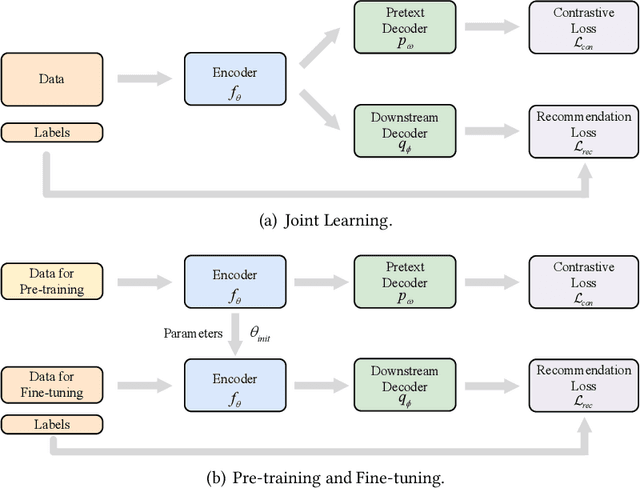
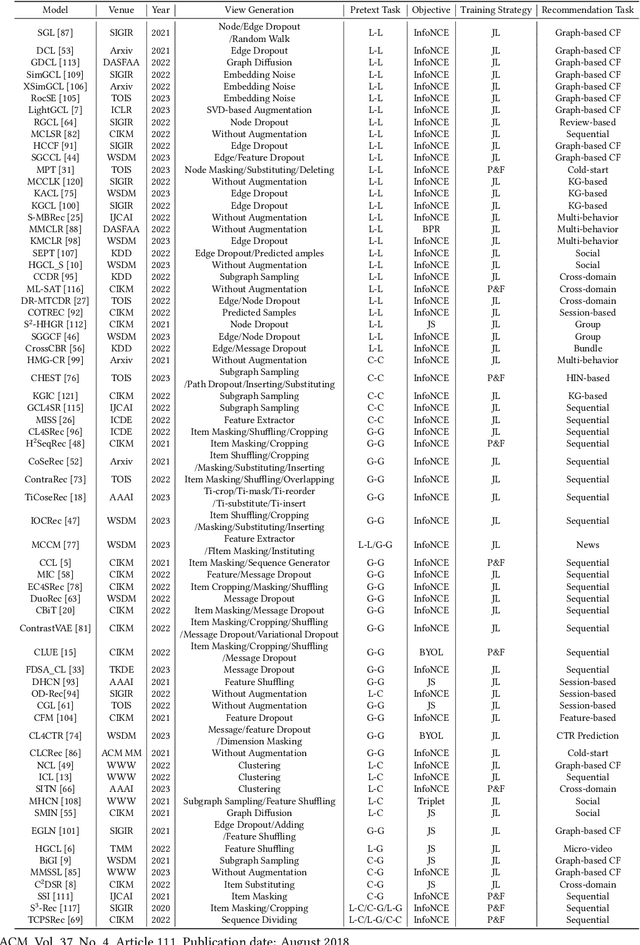
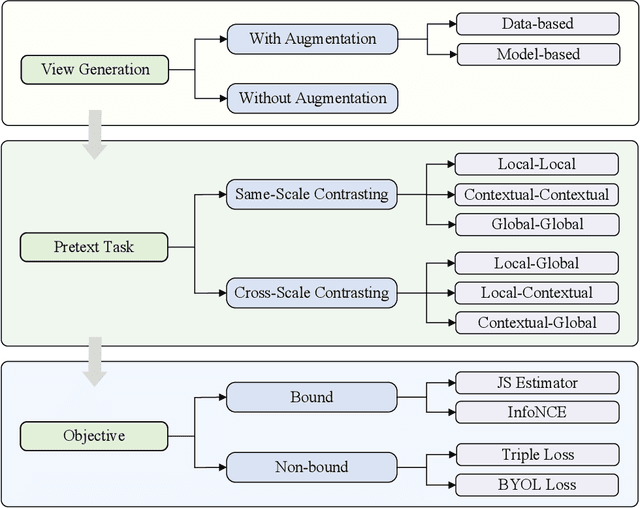
Deep learning-based recommender systems have achieved remarkable success in recent years. However, these methods usually heavily rely on labeled data (i.e., user-item interactions), suffering from problems such as data sparsity and cold-start. Self-supervised learning, an emerging paradigm that extracts information from unlabeled data, provides insights into addressing these problems. Specifically, contrastive self-supervised learning, due to its flexibility and promising performance, has attracted considerable interest and recently become a dominant branch in self-supervised learning-based recommendation methods. In this survey, we provide an up-to-date and comprehensive review of current contrastive self-supervised learning-based recommendation methods. Firstly, we propose a unified framework for these methods. We then introduce a taxonomy based on the key components of the framework, including view generation strategy, contrastive task, and contrastive objective. For each component, we provide detailed descriptions and discussions to guide the choice of the appropriate method. Finally, we outline open issues and promising directions for future research.
Style Transfer for 2D Talking Head Animation
Mar 17, 2023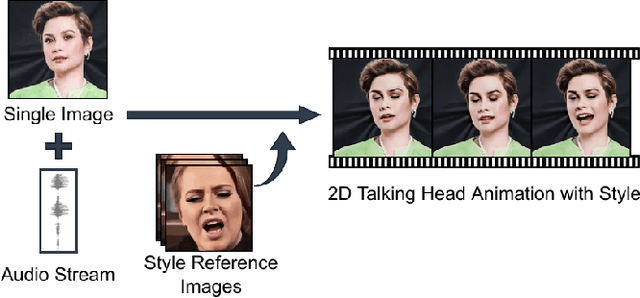
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
CHAMPAGNE: Learning Real-world Conversation from Large-Scale Web Videos
Mar 17, 2023
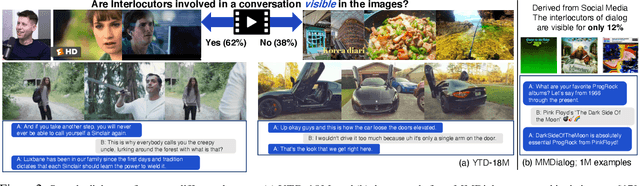
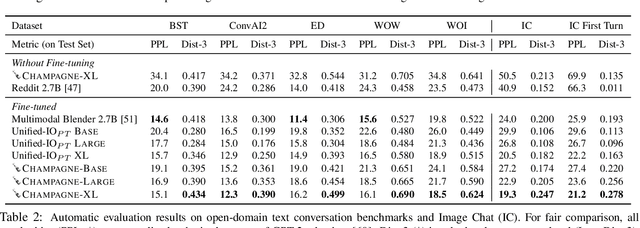
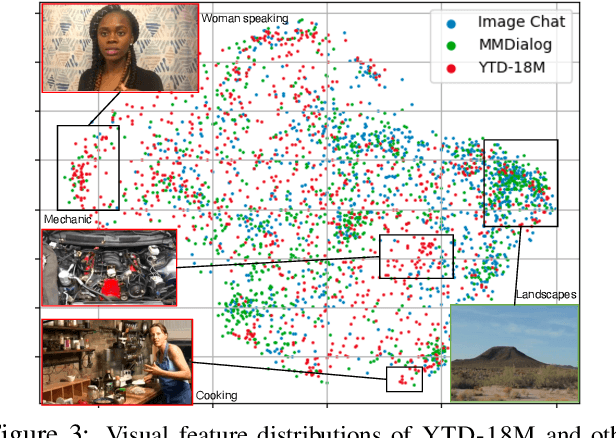
Visual information is central to conversation: body gestures and facial expressions, for example, contribute to meaning that transcends words alone. To date, however, most neural conversational models are limited to just text. We introduce CHAMPAGNE, a generative model of conversations that can account for visual contexts. To train CHAMPAGNE, we collect and release YTD-18M, a large-scale corpus of 18M video-based dialogues. YTD-18M is constructed from web videos: crucial to our data collection pipeline is a pretrained language model that converts error-prone automatic transcripts to a cleaner dialogue format while maintaining meaning. Human evaluation reveals that YTD-18M is more sensible and specific than prior resources (MMDialog, 1M dialogues), while maintaining visual-groundedness. Experiments demonstrate that 1) CHAMPAGNE learns to conduct conversation from YTD-18M; and 2) when fine-tuned, it achieves state-of-the-art results on four vision-language tasks focused on real-world conversations. We release data, models, and code at https://seungjuhan.me/champagne.
Scribble-Supervised RGB-T Salient Object Detection
Mar 17, 2023
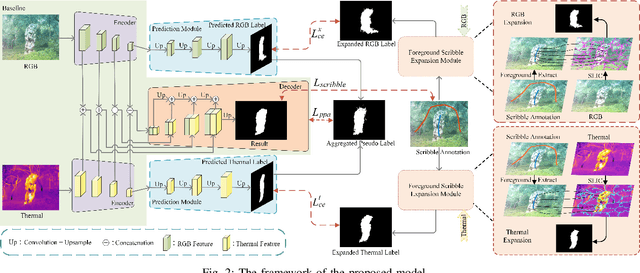


Salient object detection segments attractive objects in scenes. RGB and thermal modalities provide complementary information and scribble annotations alleviate large amounts of human labor. Based on the above facts, we propose a scribble-supervised RGB-T salient object detection model. By a four-step solution (expansion, prediction, aggregation, and supervision), label-sparse challenge of scribble-supervised method is solved. To expand scribble annotations, we collect the superpixels that foreground scribbles pass through in RGB and thermal images, respectively. The expanded multi-modal labels provide the coarse object boundary. To further polish the expanded labels, we propose a prediction module to alleviate the sharpness of boundary. To play the complementary roles of two modalities, we combine the two into aggregated pseudo labels. Supervised by scribble annotations and pseudo labels, our model achieves the state-of-the-art performance on the relabeled RGBT-S dataset. Furthermore, the model is applied to RGB-D and video scribble-supervised applications, achieving consistently excellent performance.
Policy Gradient Converges to the Globally Optimal Policy for Nearly Linear-Quadratic Regulators
Mar 15, 2023Nonlinear control systems with partial information to the decision maker are prevalent in a variety of applications. As a step toward studying such nonlinear systems, this work explores reinforcement learning methods for finding the optimal policy in the nearly linear-quadratic regulator systems. In particular, we consider a dynamic system that combines linear and nonlinear components, and is governed by a policy with the same structure. Assuming that the nonlinear component comprises kernels with small Lipschitz coefficients, we characterize the optimization landscape of the cost function. Although the cost function is nonconvex in general, we establish the local strong convexity and smoothness in the vicinity of the global optimizer. Additionally, we propose an initialization mechanism to leverage these properties. Building on the developments, we design a policy gradient algorithm that is guaranteed to converge to the globally optimal policy with a linear rate.
RGI : Regularized Graph Infomax for self-supervised learning on graphs
Mar 15, 2023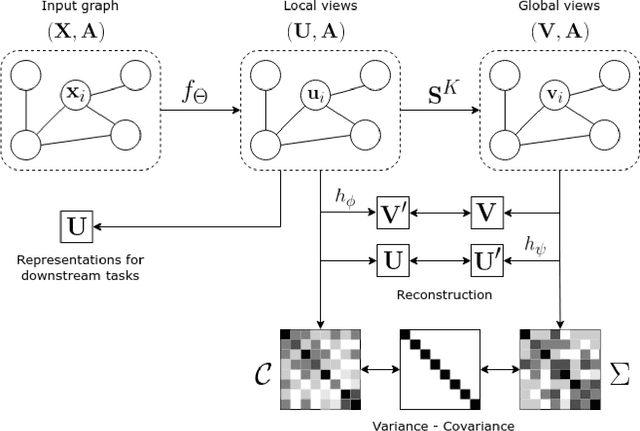

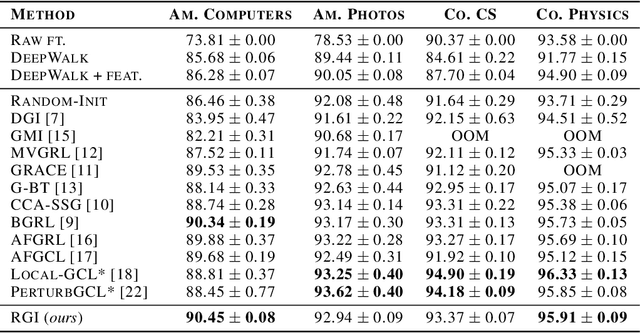
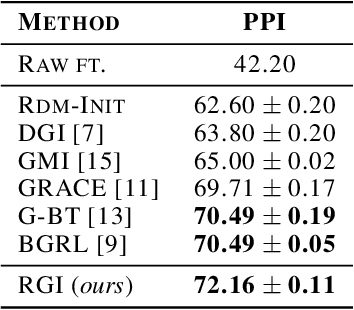
Self-supervised learning is gaining considerable attention as a solution to avoid the requirement of extensive annotations in representation learning on graphs. We introduce \textit{Regularized Graph Infomax (RGI)}, a simple yet effective framework for node level self-supervised learning on graphs that trains a graph neural network encoder by maximizing the mutual information between node level local and global views, in contrast to previous works that employ graph level global views. The method promotes the predictability between views while regularizing the covariance matrices of the representations. Therefore, RGI is non-contrastive, does not depend on complex asymmetric architectures nor training tricks, is augmentation-free and does not rely on a two branch architecture. We run RGI on both transductive and inductive settings with popular graph benchmarks and show that it can achieve state-of-the-art performance regardless of its simplicity.
WikiCoder: Learning to Write Knowledge-Powered Code
Mar 15, 2023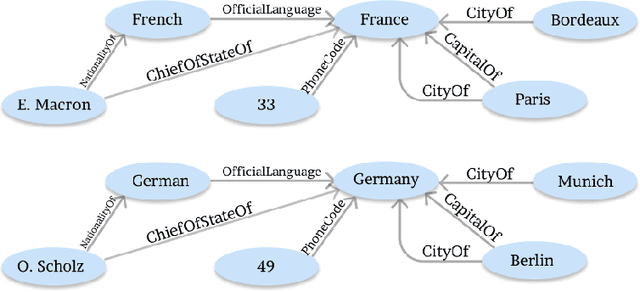
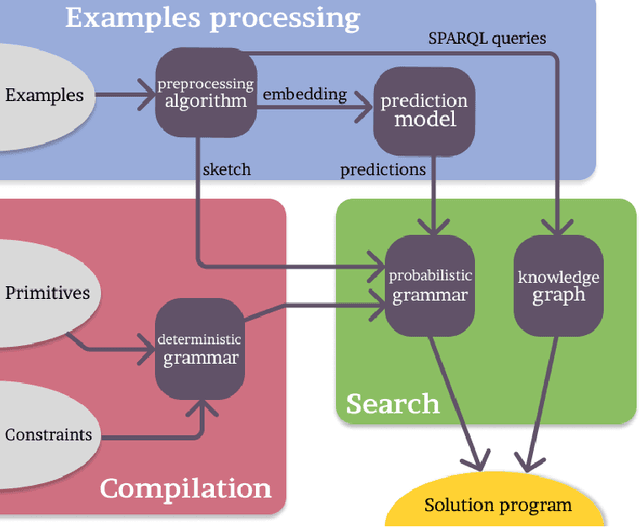
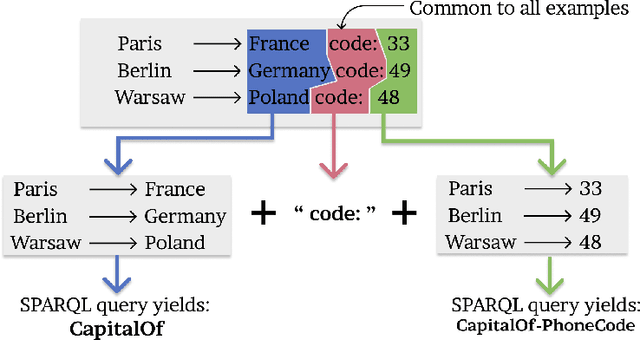
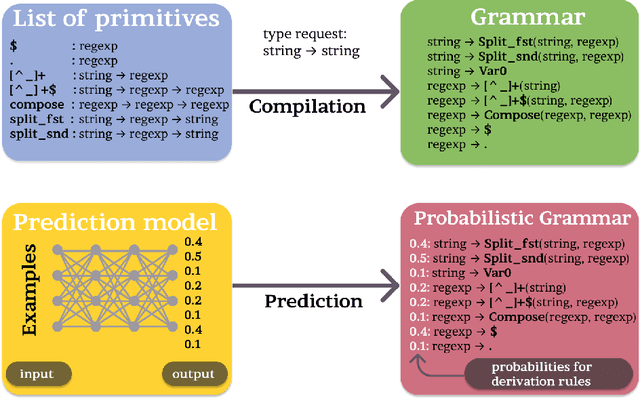
We tackle the problem of automatic generation of computer programs from a few pairs of input-output examples. The starting point of this work is the observation that in many applications a solution program must use external knowledge not present in the examples: we call such programs knowledge-powered since they can refer to information collected from a knowledge graph such as Wikipedia. This paper makes a first step towards knowledge-powered program synthesis. We present WikiCoder, a system building upon state of the art machine-learned program synthesizers and integrating knowledge graphs. We evaluate it to show its wide applicability over different domains and discuss its limitations. WikiCoder solves tasks that no program synthesizers were able to solve before thanks to the use of knowledge graphs, while integrating with recent developments in the field to operate at scale.
FaceXHuBERT: Text-less Speech-driven E(X)pressive 3D Facial Animation Synthesis Using Self-Supervised Speech Representation Learning
Mar 09, 2023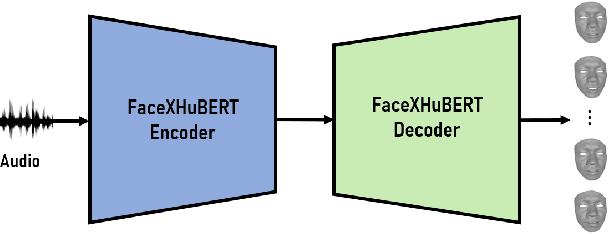
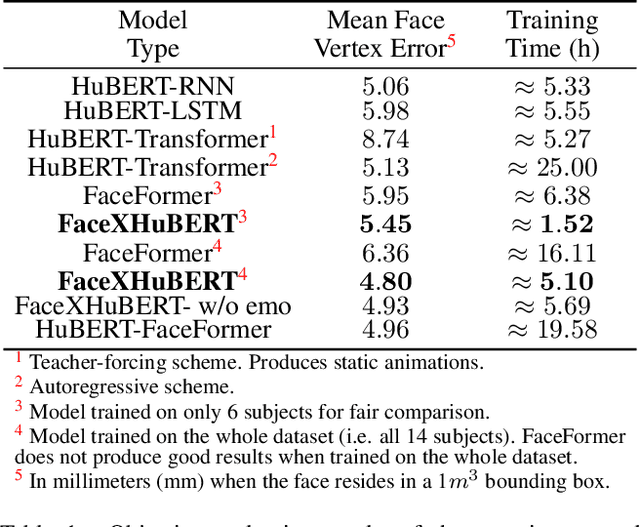
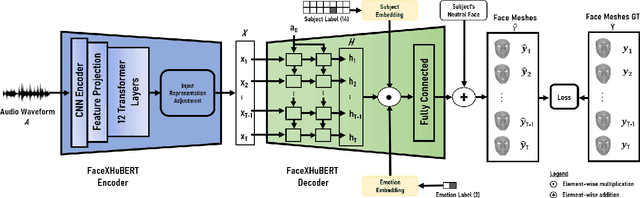

This paper presents FaceXHuBERT, a text-less speech-driven 3D facial animation generation method that allows to capture personalized and subtle cues in speech (e.g. identity, emotion and hesitation). It is also very robust to background noise and can handle audio recorded in a variety of situations (e.g. multiple people speaking). Recent approaches employ end-to-end deep learning taking into account both audio and text as input to generate facial animation for the whole face. However, scarcity of publicly available expressive audio-3D facial animation datasets poses a major bottleneck. The resulting animations still have issues regarding accurate lip-synching, expressivity, person-specific information and generalizability. We effectively employ self-supervised pretrained HuBERT model in the training process that allows us to incorporate both lexical and non-lexical information in the audio without using a large lexicon. Additionally, guiding the training with a binary emotion condition and speaker identity distinguishes the tiniest subtle facial motion. We carried out extensive objective and subjective evaluation in comparison to ground-truth and state-of-the-art work. A perceptual user study demonstrates that our approach produces superior results with respect to the realism of the animation 78% of the time in comparison to the state-of-the-art. In addition, our method is 4 times faster eliminating the use of complex sequential models such as transformers. We strongly recommend watching the supplementary video before reading the paper. We also provide the implementation and evaluation codes with a GitHub repository link.
Phase transition for detecting a small community in a large network
Mar 09, 2023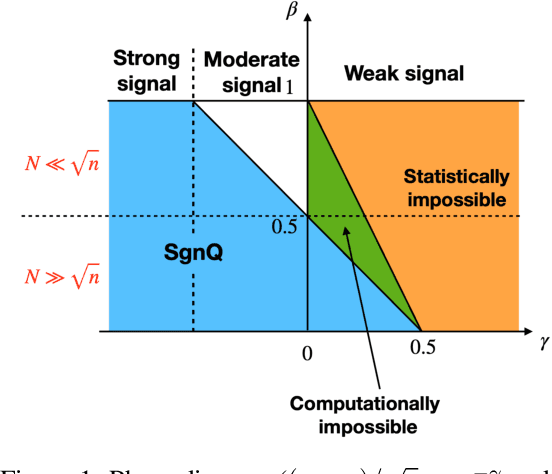
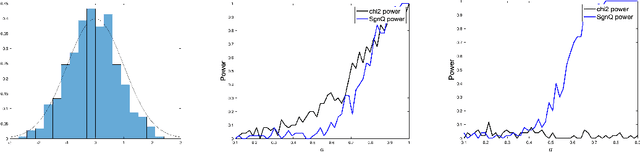
How to detect a small community in a large network is an interesting problem, including clique detection as a special case, where a naive degree-based $\chi^2$-test was shown to be powerful in the presence of an Erd\H{o}s-Renyi background. Using Sinkhorn's theorem, we show that the signal captured by the $\chi^2$-test may be a modeling artifact, and it may disappear once we replace the Erd\H{o}s-Renyi model by a broader network model. We show that the recent SgnQ test is more appropriate for such a setting. The test is optimal in detecting communities with sizes comparable to the whole network, but has never been studied for our setting, which is substantially different and more challenging. Using a degree-corrected block model (DCBM), we establish phase transitions of this testing problem concerning the size of the small community and the edge densities in small and large communities. When the size of the small community is larger than $\sqrt{n}$, the SgnQ test is optimal for it attains the computational lower bound (CLB), the information lower bound for methods allowing polynomial computation time. When the size of the small community is smaller than $\sqrt{n}$, we establish the parameter regime where the SgnQ test has full power and make some conjectures of the CLB. We also study the classical information lower bound (LB) and show that there is always a gap between the CLB and LB in our range of interest.