 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalizable Neural Voxels for Fast Human Radiance Fields
Mar 27, 2023
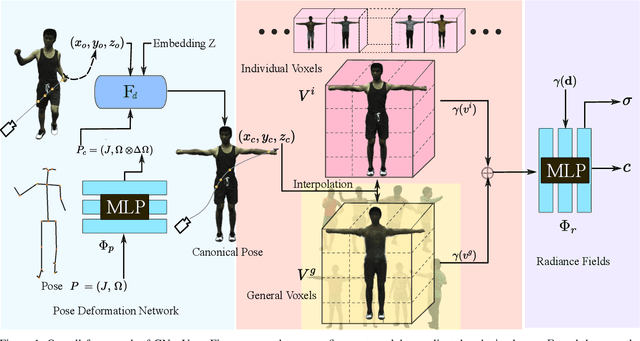
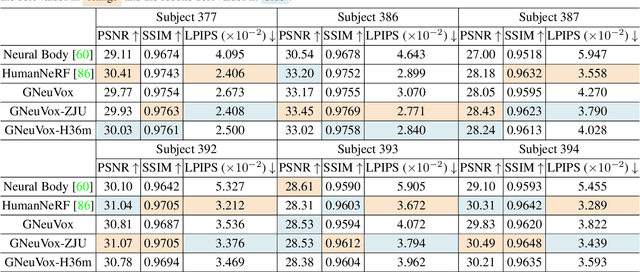
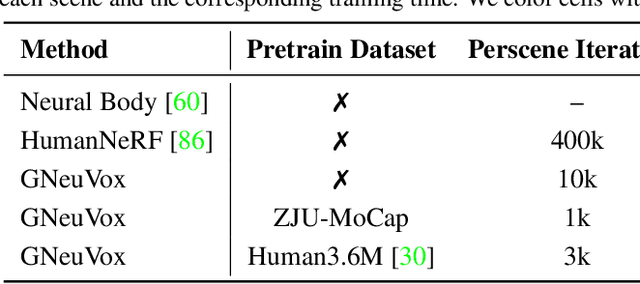

Rendering moving human bodies at free viewpoints only from a monocular video is quite a challenging problem. The information is too sparse to model complicated human body structures and motions from both view and pose dimensions. Neural radiance fields (NeRF) have shown great power in novel view synthesis and have been applied to human body rendering. However, most current NeRF-based methods bear huge costs for both training and rendering, which impedes the wide applications in real-life scenarios. In this paper, we propose a rendering framework that can learn moving human body structures extremely quickly from a monocular video. The framework is built by integrating both neural fields and neural voxels. Especially, a set of generalizable neural voxels are constructed. With pretrained on various human bodies, these general voxels represent a basic skeleton and can provide strong geometric priors. For the fine-tuning process, individual voxels are constructed for learning differential textures, complementary to general voxels. Thus learning a novel body can be further accelerated, taking only a few minutes. Our method shows significantly higher training efficiency compared with previous methods, while maintaining similar rendering quality. The project page is at https://taoranyi.com/gneuvox .
UniDistill: A Universal Cross-Modality Knowledge Distillation Framework for 3D Object Detection in Bird's-Eye View
Mar 27, 2023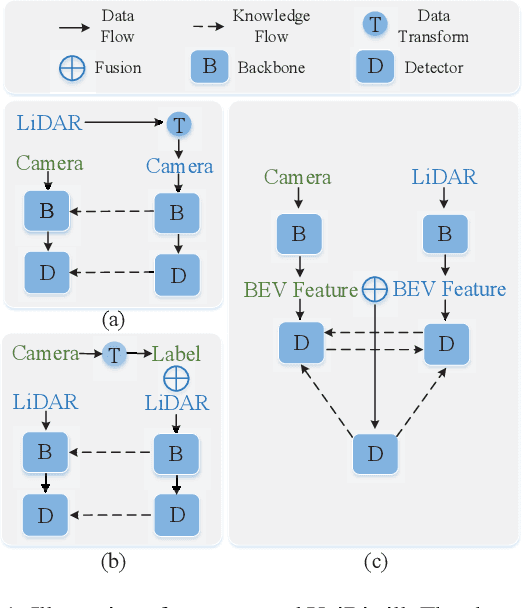
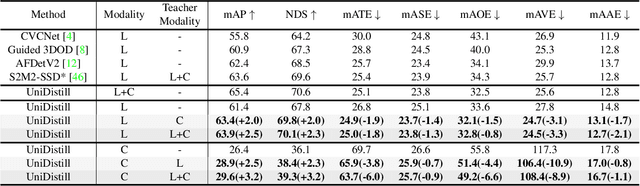
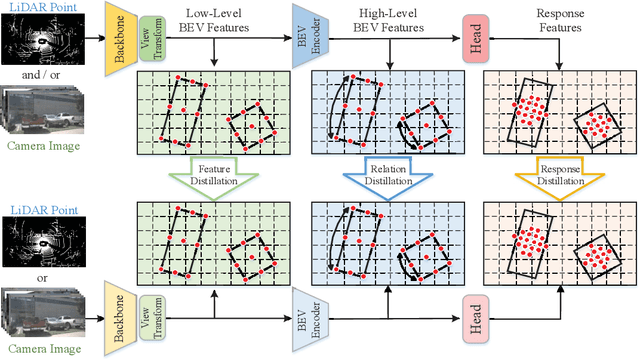
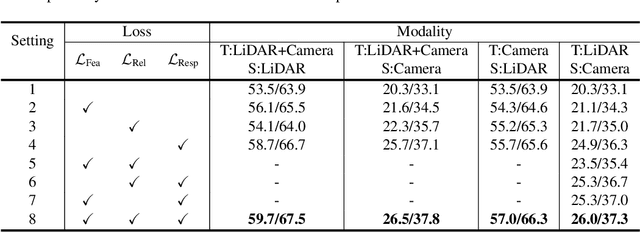
In the field of 3D object detection for autonomous driving, the sensor portfolio including multi-modality and single-modality is diverse and complex. Since the multi-modal methods have system complexity while the accuracy of single-modal ones is relatively low, how to make a tradeoff between them is difficult. In this work, we propose a universal cross-modality knowledge distillation framework (UniDistill) to improve the performance of single-modality detectors. Specifically, during training, UniDistill projects the features of both the teacher and the student detector into Bird's-Eye-View (BEV), which is a friendly representation for different modalities. Then, three distillation losses are calculated to sparsely align the foreground features, helping the student learn from the teacher without introducing additional cost during inference. Taking advantage of the similar detection paradigm of different detectors in BEV, UniDistill easily supports LiDAR-to-camera, camera-to-LiDAR, fusion-to-LiDAR and fusion-to-camera distillation paths. Furthermore, the three distillation losses can filter the effect of misaligned background information and balance between objects of different sizes, improving the distillation effectiveness. Extensive experiments on nuScenes demonstrate that UniDistill effectively improves the mAP and NDS of student detectors by 2.0%~3.2%.
Unified Text Structuralization with Instruction-tuned Language Models
Mar 27, 2023
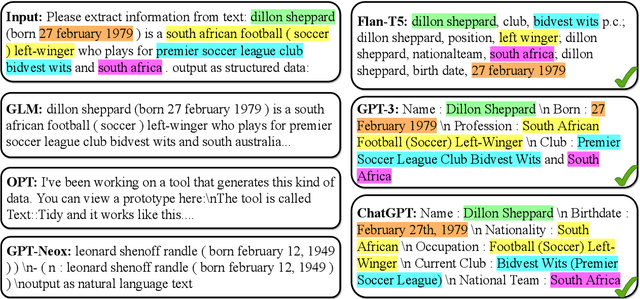
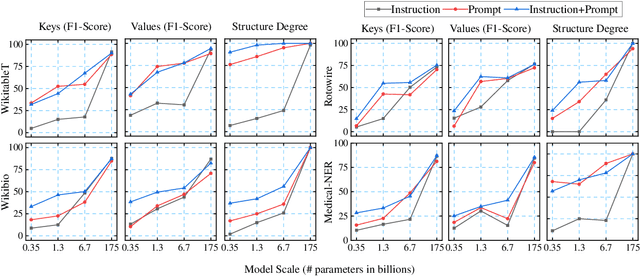
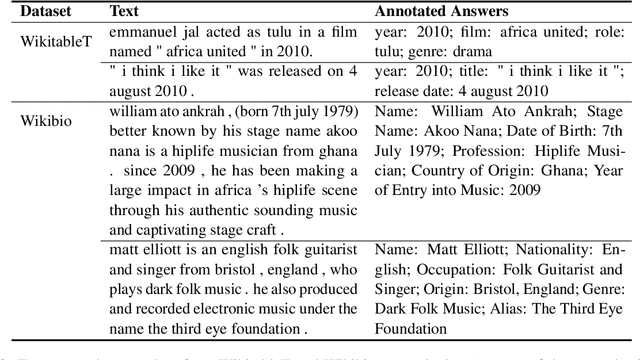
Text structuralization is one of the important fields of natural language processing (NLP) consists of information extraction (IE) and structure formalization. However, current studies of text structuralization suffer from a shortage of manually annotated high-quality datasets from different domains and languages, which require specialized professional knowledge. In addition, most IE methods are designed for a specific type of structured data, e.g., entities, relations, and events, making them hard to generalize to others. In this work, we propose a simple and efficient approach to instruct large language model (LLM) to extract a variety of structures from texts. More concretely, we add a prefix and a suffix instruction to indicate the desired IE task and structure type, respectively, before feeding the text into a LLM. Experiments on two LLMs show that this approach can enable language models to perform comparable with other state-of-the-art methods on datasets of a variety of languages and knowledge, and can generalize to other IE sub-tasks via changing the content of instruction. Another benefit of our approach is that it can help researchers to build datasets in low-source and domain-specific scenarios, e.g., fields in finance and law, with low cost.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023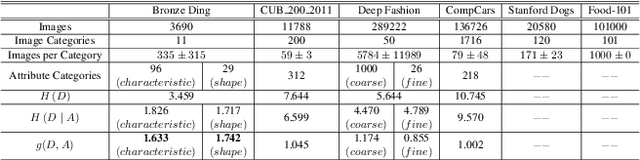

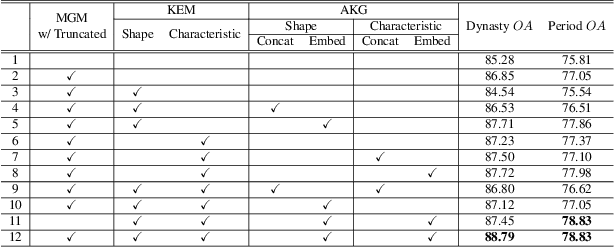
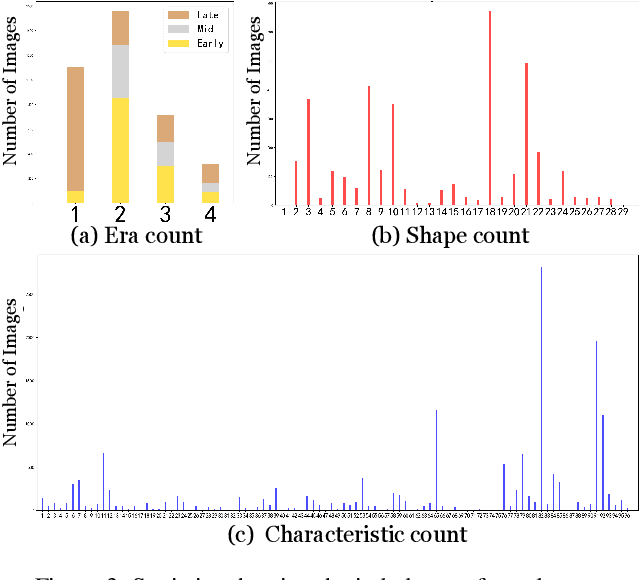
The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.
Recovering 3D Hand Mesh Sequence from a Single Blurry Image: A New Dataset and Temporal Unfolding
Mar 27, 2023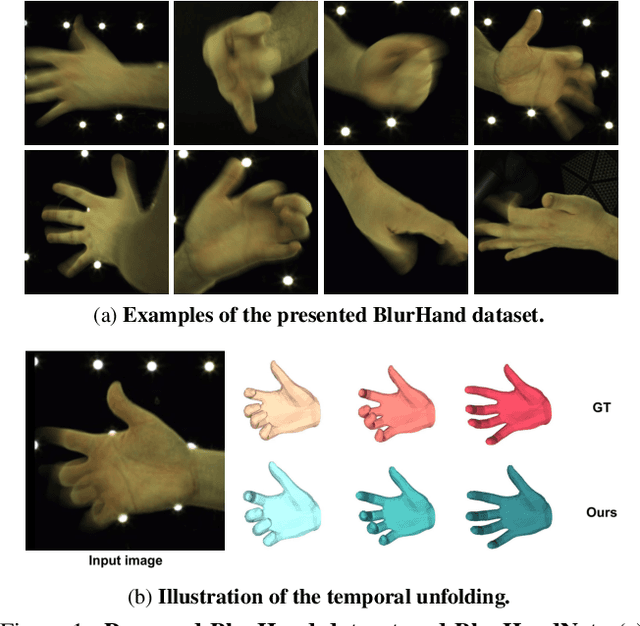
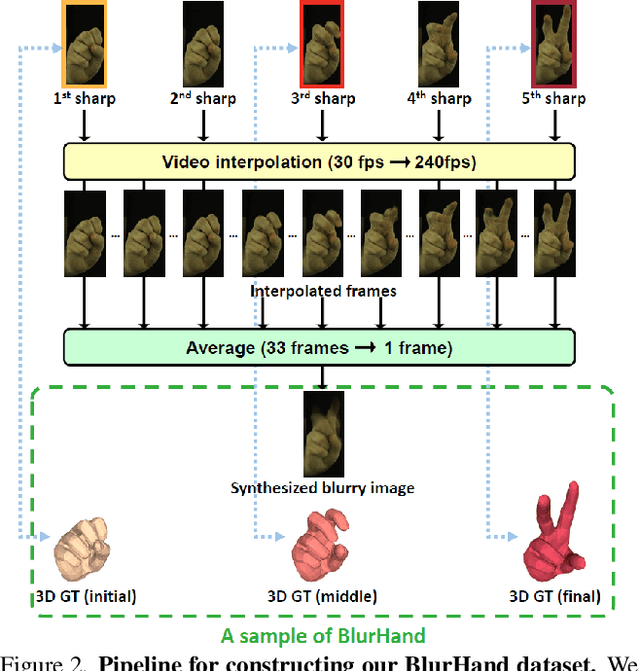
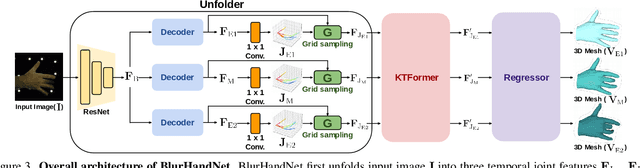

Hands, one of the most dynamic parts of our body, suffer from blur due to their active movements. However, previous 3D hand mesh recovery methods have mainly focused on sharp hand images rather than considering blur due to the absence of datasets providing blurry hand images. We first present a novel dataset BlurHand, which contains blurry hand images with 3D groundtruths. The BlurHand is constructed by synthesizing motion blur from sequential sharp hand images, imitating realistic and natural motion blurs. In addition to the new dataset, we propose BlurHandNet, a baseline network for accurate 3D hand mesh recovery from a blurry hand image. Our BlurHandNet unfolds a blurry input image to a 3D hand mesh sequence to utilize temporal information in the blurry input image, while previous works output a static single hand mesh. We demonstrate the usefulness of BlurHand for the 3D hand mesh recovery from blurry images in our experiments. The proposed BlurHandNet produces much more robust results on blurry images while generalizing well to in-the-wild images. The training codes and BlurHand dataset are available at https://github.com/JaehaKim97/BlurHand_RELEASE.
Object-Aware Distillation Pyramid for Open-Vocabulary Object Detection
Mar 10, 2023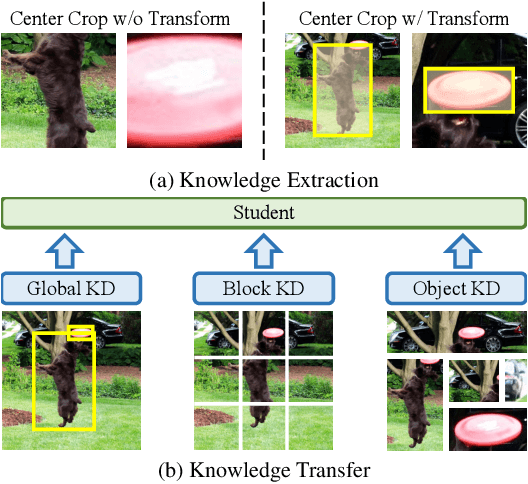
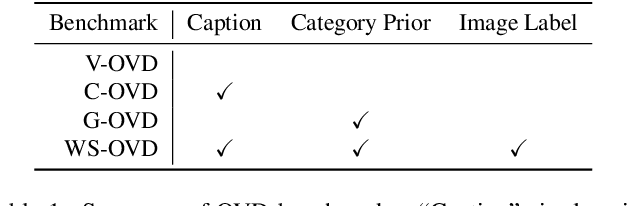
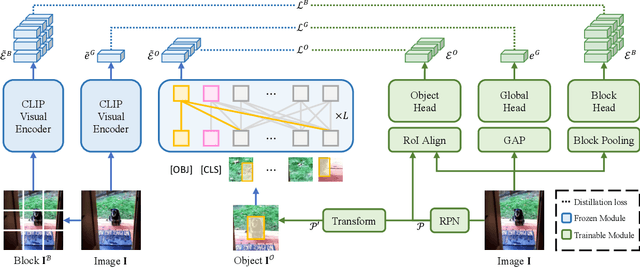
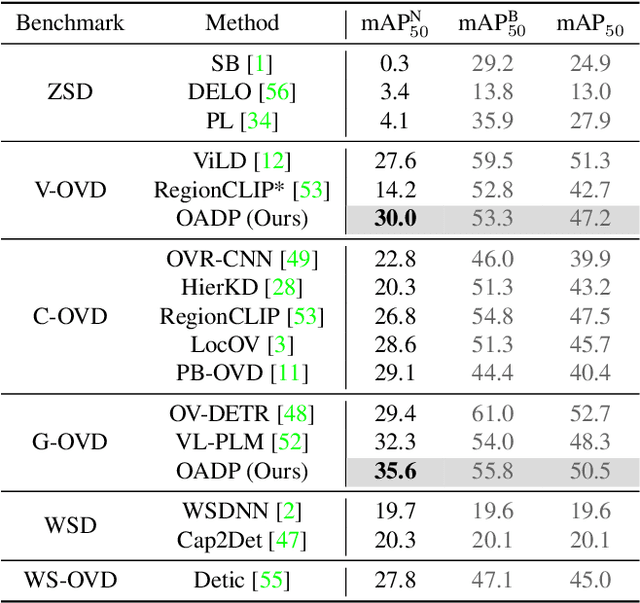
Open-vocabulary object detection aims to provide object detectors trained on a fixed set of object categories with the generalizability to detect objects described by arbitrary text queries. Previous methods adopt knowledge distillation to extract knowledge from Pretrained Vision-and-Language Models (PVLMs) and transfer it to detectors. However, due to the non-adaptive proposal cropping and single-level feature mimicking processes, they suffer from information destruction during knowledge extraction and inefficient knowledge transfer. To remedy these limitations, we propose an Object-Aware Distillation Pyramid (OADP) framework, including an Object-Aware Knowledge Extraction (OAKE) module and a Distillation Pyramid (DP) mechanism. When extracting object knowledge from PVLMs, the former adaptively transforms object proposals and adopts object-aware mask attention to obtain precise and complete knowledge of objects. The latter introduces global and block distillation for more comprehensive knowledge transfer to compensate for the missing relation information in object distillation. Extensive experiments show that our method achieves significant improvement compared to current methods. Especially on the MS-COCO dataset, our OADP framework reaches $35.6$ mAP$^{\text{N}}_{50}$, surpassing the current state-of-the-art method by $3.3$ mAP$^{\text{N}}_{50}$. Code is released at https://github.com/LutingWang/OADP.
LSEH: Semantically Enhanced Hard Negatives for Cross-modal Information Retrieval
Oct 10, 2022
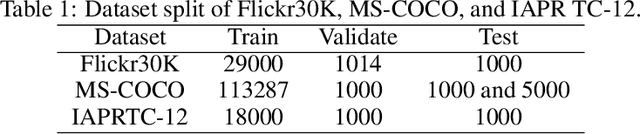
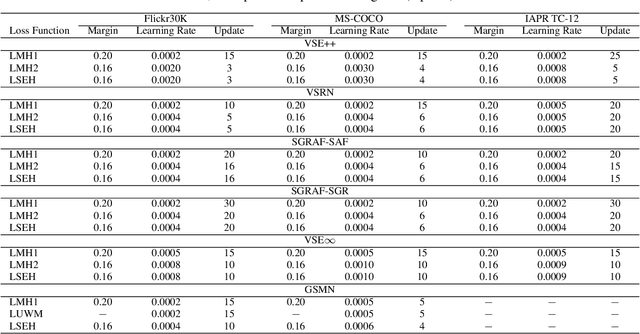
Visual Semantic Embedding (VSE) aims to extract the semantics of images and their descriptions, and embed them into the same latent space for cross-modal information retrieval. Most existing VSE networks are trained by adopting a hard negatives loss function which learns an objective margin between the similarity of relevant and irrelevant image-description embedding pairs. However, the objective margin in the hard negatives loss function is set as a fixed hyperparameter that ignores the semantic differences of the irrelevant image-description pairs. To address the challenge of measuring the optimal similarities between image-description pairs before obtaining the trained VSE networks, this paper presents a novel approach that comprises two main parts: (1) finds the underlying semantics of image descriptions; and (2) proposes a novel semantically enhanced hard negatives loss function, where the learning objective is dynamically determined based on the optimal similarity scores between irrelevant image-description pairs. Extensive experiments were carried out by integrating the proposed methods into five state-of-the-art VSE networks that were applied to three benchmark datasets for cross-modal information retrieval tasks. The results revealed that the proposed methods achieved the best performance and can also be adopted by existing and future VSE networks.
Generalization algorithm of multimodal pre-training model based on graph-text self-supervised training
Feb 16, 2023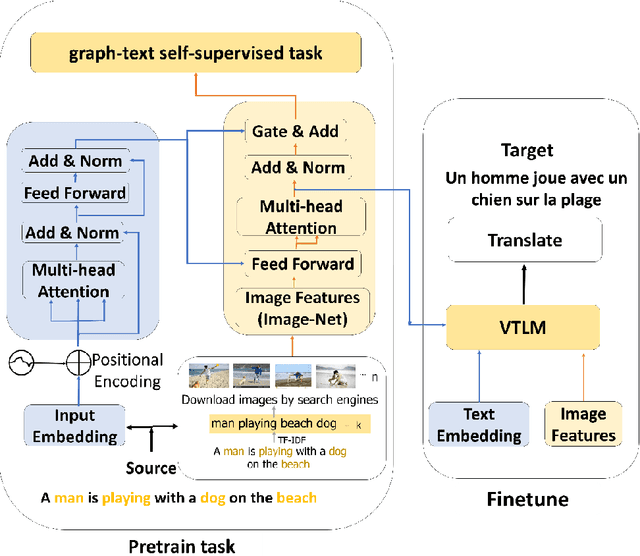


Recently, a large number of studies have shown that the introduction of visual information can effectively improve the effect of neural machine translation (NMT). Its effectiveness largely depends on the availability of a large number of bilingual parallel sentence pairs and manual image annotation. The lack of images and the effectiveness of images have been difficult to solve. In this paper, a multimodal pre-training generalization algorithm for self-supervised training is proposed, which overcomes the lack of visual information and inaccuracy, and thus extends the applicability of images on NMT. Specifically, we will search for many pictures from the existing sentences through the search engine, and then through the relationship between visual information and text, do the self-supervised training task of graphics and text to obtain more effective visual information for text. We show that when the filtered information is used as multimodal machine translation for fine-tuning, the effect of translation in the global voice dataset is 0.5 BLEU higher than the baseline.
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Feb 27, 2023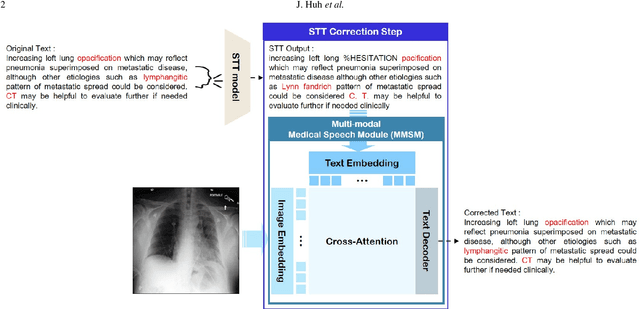

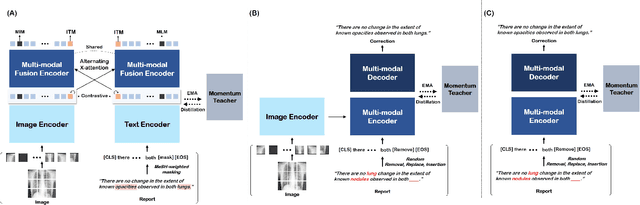
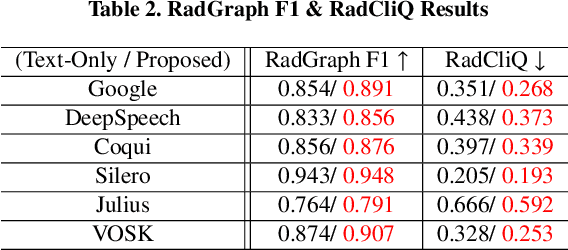
Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by transcribing spoken words into text. In the medical field, STT has the potential to significantly reduce the workload of clinicians who rely on typists to transcribe their voice recordings. However, developing an STT model for the medical domain is challenging due to the lack of sufficient speech and text datasets. To address this issue, we propose a medical-domain text correction method that modifies the output text of a general STT system using the Vision Language Pre-training (VLP) method. VLP combines textual and visual information to correct text based on image knowledge. Our extensive experiments demonstrate that the proposed method offers quantitatively and clinically significant improvements in STT performance in the medical field. We further show that multi-modal understanding of image and text information outperforms single-modal understanding using only text information.
Image-Based Virtual Try-on System With Clothing-Size Adjustment
Feb 27, 2023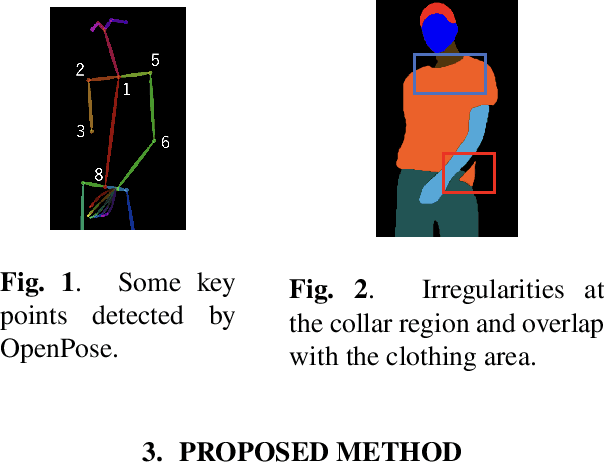
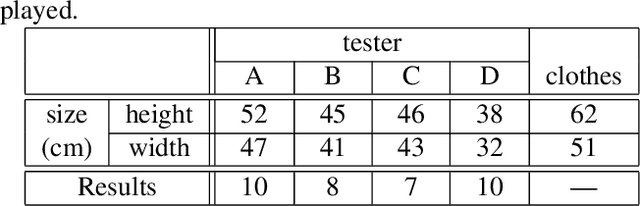
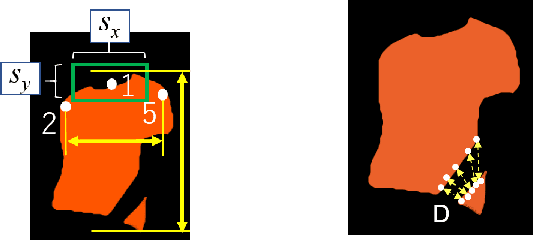
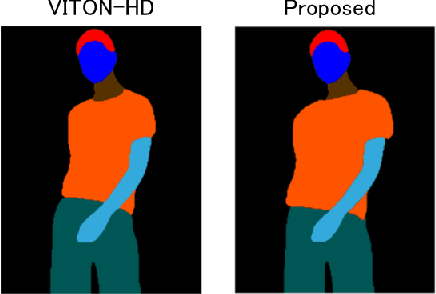
The conventional image-based virtual try-on method cannot generate fitting images that correspond to the clothing size because the system cannot accurately reflect the body information of a person. In this study, an image-based virtual try-on system that could adjust the clothing size was proposed. The size information of the person and clothing were used as the input for the proposed method to visualize the fitting of various clothing sizes in a virtual space. First, the distance between the shoulder width and height of the clothing in the person image is calculated based on the coordinate information of the key points detected by OpenPose. Then, the system changes the size of only the clothing area of the segmentation map, whose layout is estimated using the size of the person measured in the person image based on the ratio of the person and clothing sizes. If the size of the clothing area increases during the drawing, the details in the collar and overlapping areas are corrected to improve visual appearance.