 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HREyes: Design, Development, and Evaluation of a Novel Method for AUVs to Communicate Information and Gaze Direction
Nov 05, 2022
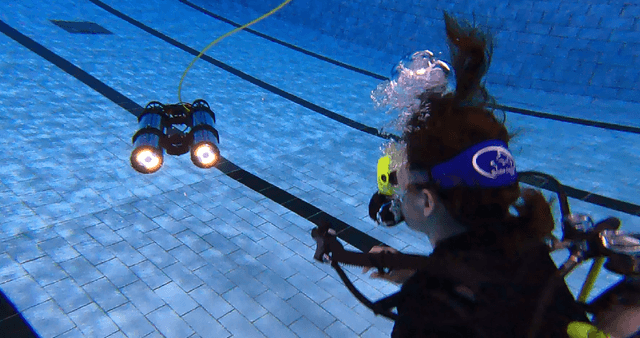

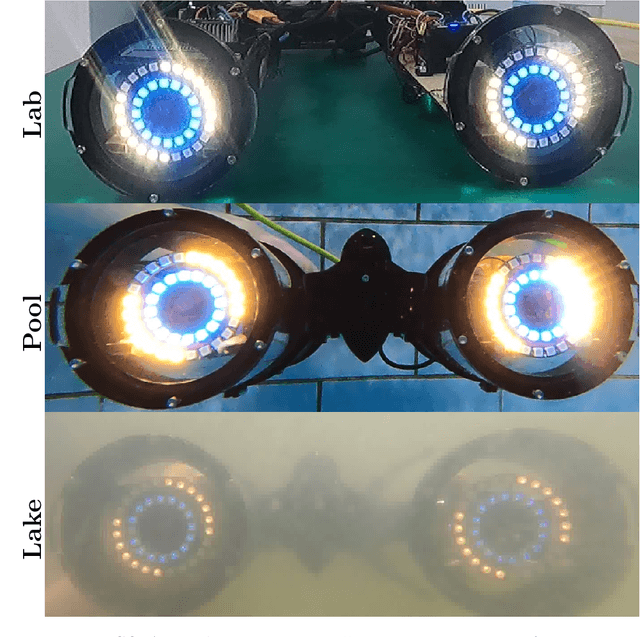

We present the design, development, and evaluation of HREyes: biomimetic communication devices which use light to communicate information and, for the first time, gaze direction from AUVs to humans. First, we introduce two types of information displays using the HREye devices: active lucemes and ocular lucemes. Active lucemes communicate information explicitly through animations, while ocular lucemes communicate gaze direction implicitly by mimicking human eyes. We present a human study in which our system is compared to the use of an embedded digital display that explicitly communicates information to a diver by displaying text. Our results demonstrate accurate recognition of active lucemes for trained interactants, limited intuitive understanding of these lucemes for untrained interactants, and relatively accurate perception of gaze direction for all interactants. The results on active luceme recognition demonstrate more accurate recognition than previous light-based communication systems for AUVs (albeit with different phrase sets). Additionally, the ocular lucemes we introduce in this work represent the first method for communicating gaze direction from an AUV, a critical aspect of nonverbal communication used in collaborative work. With readily available hardware as well as open-source and easily re-configurable programming, HREyes can be easily integrated into any AUV with the physical space for the devices and used to communicate effectively with divers in any underwater environment with appropriate visibility.
A Random Projection k Nearest Neighbours Ensemble for Classification via Extended Neighbourhood Rule
Mar 21, 2023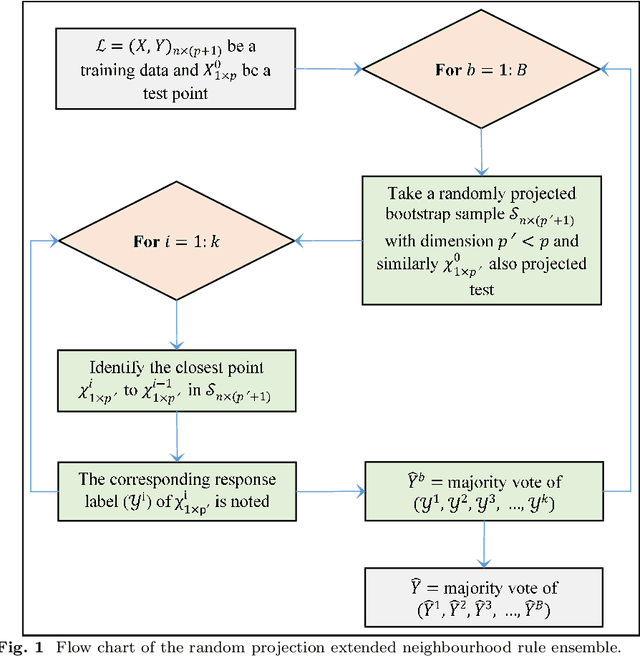
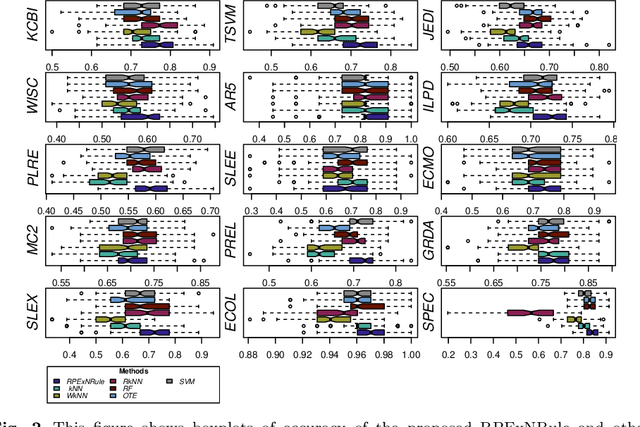
Ensembles based on k nearest neighbours (kNN) combine a large number of base learners, each constructed on a sample taken from a given training data. Typical kNN based ensembles determine the k closest observations in the training data bounded to a test sample point by a spherical region to predict its class. In this paper, a novel random projection extended neighbourhood rule (RPExNRule) ensemble is proposed where bootstrap samples from the given training data are randomly projected into lower dimensions for additional randomness in the base models and to preserve features information. It uses the extended neighbourhood rule (ExNRule) to fit kNN as base learners on randomly projected bootstrap samples.
Zero-shot Medical Image Translation via Frequency-Guided Diffusion Models
Apr 05, 2023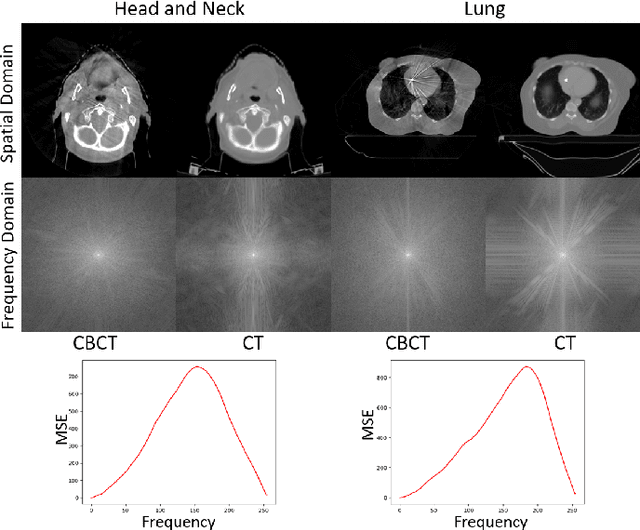

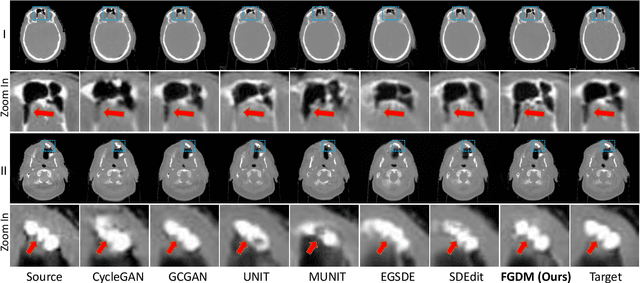
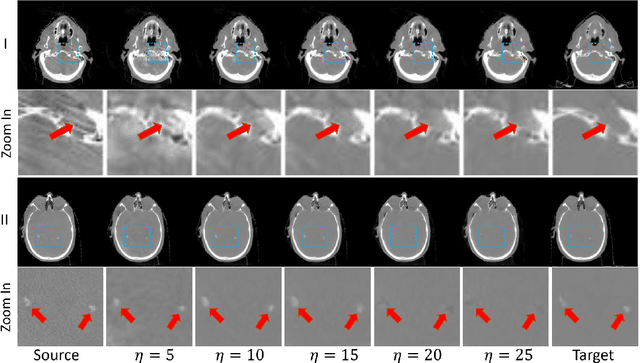
Recently, the diffusion model has emerged as a superior generative model that can produce high-quality images with excellent realism. There is a growing interest in applying diffusion models to image translation tasks. However, for medical image translation, the existing diffusion models are deficient in accurately retaining structural information since the structure details of source domain images are lost during the forward diffusion process and cannot be fully recovered through learned reverse diffusion, while the integrity of anatomical structures is extremely important in medical images. Training and conditioning diffusion models using paired source and target images with matching anatomy can help. However, such paired data are very difficult and costly to obtain, and may also reduce the robustness of the developed model to out-of-distribution testing data. We propose a frequency-guided diffusion model (FGDM) that employs frequency-domain filters to guide the diffusion model for structure-preserving image translation. Based on its design, FGDM allows zero-shot learning, as it can be trained solely on the data from the target domain, and used directly for source-to-target domain translation without any exposure to the source-domain data during training. We trained FGDM solely on the head-and-neck CT data, and evaluated it on both head-and-neck and lung cone-beam CT (CBCT)-to-CT translation tasks. FGDM outperformed the state-of-the-art methods (GAN-based, VAE-based, and diffusion-based) in all metrics, showing its significant advantages in zero-shot medical image translation.
Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
Apr 05, 2023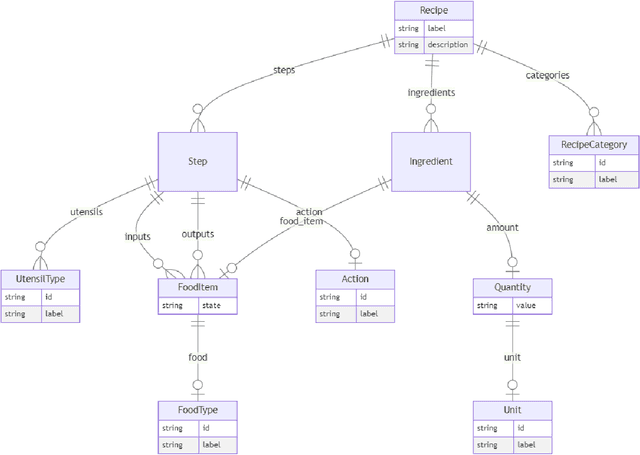
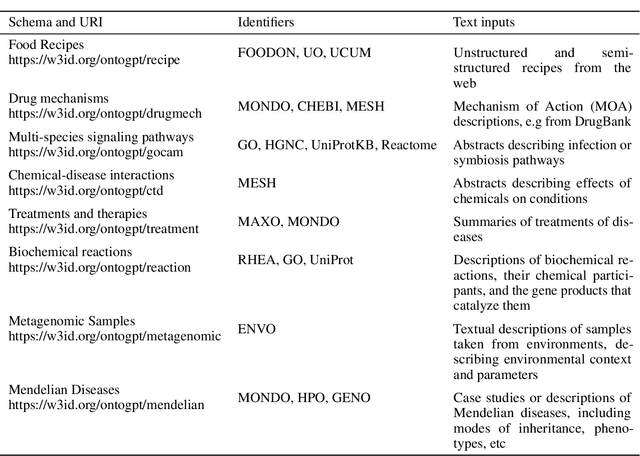
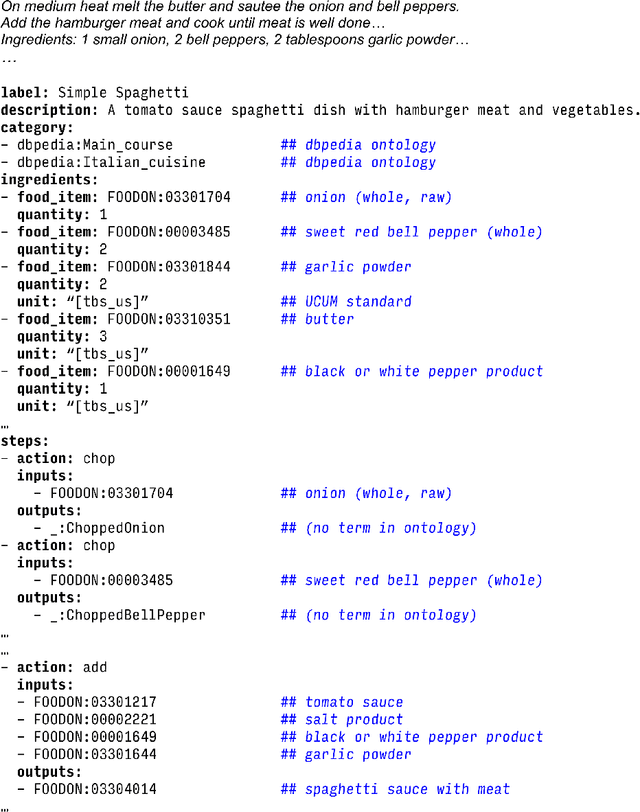

Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
Detecting and Grounding Multi-Modal Media Manipulation
Apr 05, 2023
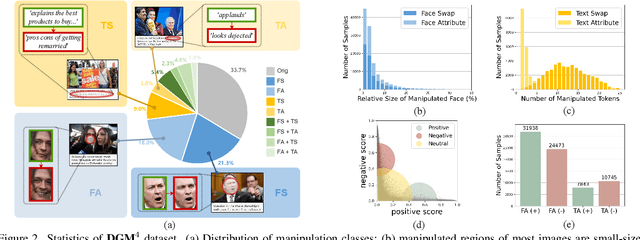
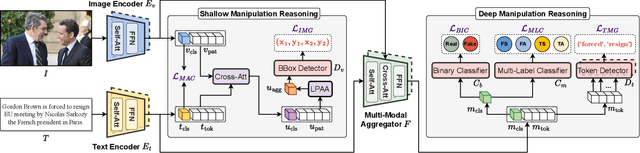

Misinformation has become a pressing issue. Fake media, in both visual and textual forms, is widespread on the web. While various deepfake detection and text fake news detection methods have been proposed, they are only designed for single-modality forgery based on binary classification, let alone analyzing and reasoning subtle forgery traces across different modalities. In this paper, we highlight a new research problem for multi-modal fake media, namely Detecting and Grounding Multi-Modal Media Manipulation (DGM^4). DGM^4 aims to not only detect the authenticity of multi-modal media, but also ground the manipulated content (i.e., image bounding boxes and text tokens), which requires deeper reasoning of multi-modal media manipulation. To support a large-scale investigation, we construct the first DGM^4 dataset, where image-text pairs are manipulated by various approaches, with rich annotation of diverse manipulations. Moreover, we propose a novel HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER) to fully capture the fine-grained interaction between different modalities. HAMMER performs 1) manipulation-aware contrastive learning between two uni-modal encoders as shallow manipulation reasoning, and 2) modality-aware cross-attention by multi-modal aggregator as deep manipulation reasoning. Dedicated manipulation detection and grounding heads are integrated from shallow to deep levels based on the interacted multi-modal information. Finally, we build an extensive benchmark and set up rigorous evaluation metrics for this new research problem. Comprehensive experiments demonstrate the superiority of our model; several valuable observations are also revealed to facilitate future research in multi-modal media manipulation.
Quantifying the Roles of Visual, Linguistic, and Visual-Linguistic Complexity in Verb Acquisition
Apr 05, 2023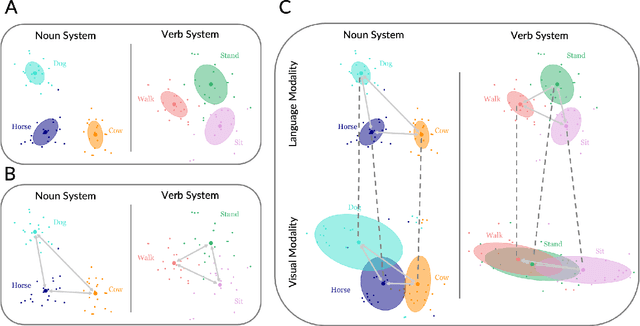
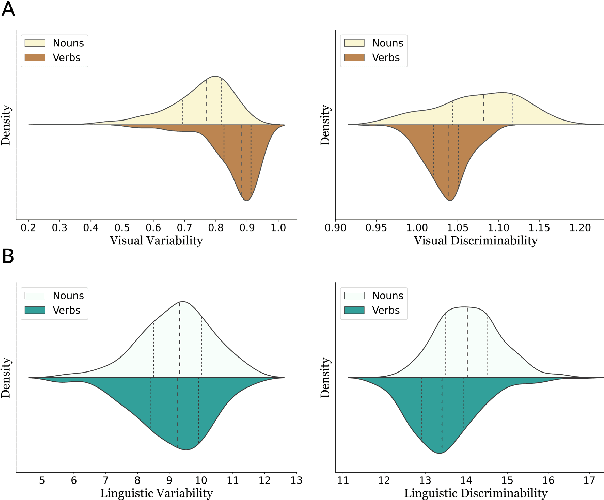
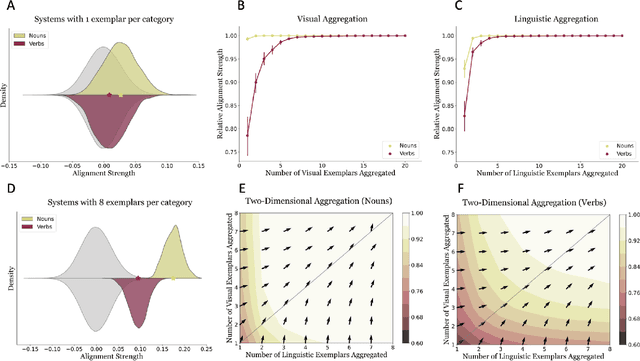
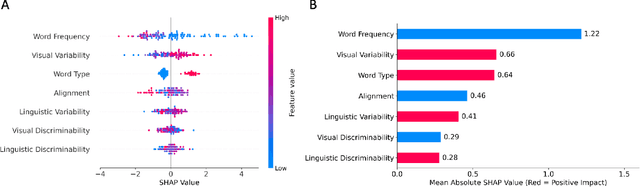
Children typically learn the meanings of nouns earlier than the meanings of verbs. However, it is unclear whether this asymmetry is a result of complexity in the visual structure of categories in the world to which language refers, the structure of language itself, or the interplay between the two sources of information. We quantitatively test these three hypotheses regarding early verb learning by employing visual and linguistic representations of words sourced from large-scale pre-trained artificial neural networks. Examining the structure of both visual and linguistic embedding spaces, we find, first, that the representation of verbs is generally more variable and less discriminable within domain than the representation of nouns. Second, we find that if only one learning instance per category is available, visual and linguistic representations are less well aligned in the verb system than in the noun system. However, in parallel with the course of human language development, if multiple learning instances per category are available, visual and linguistic representations become almost as well aligned in the verb system as in the noun system. Third, we compare the relative contributions of factors that may predict learning difficulty for individual words. A regression analysis reveals that visual variability is the strongest factor that internally drives verb learning, followed by visual-linguistic alignment and linguistic variability. Based on these results, we conclude that verb acquisition is influenced by all three sources of complexity, but that the variability of visual structure poses the most significant challenge for verb learning.
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023
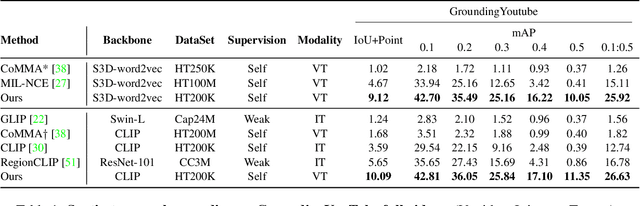
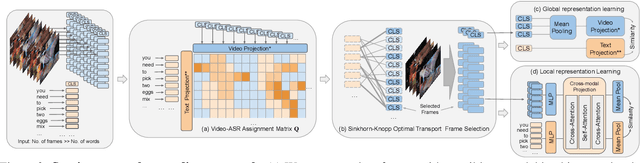
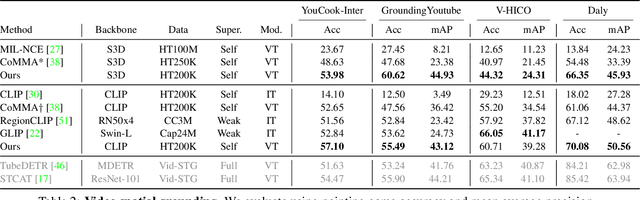
Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023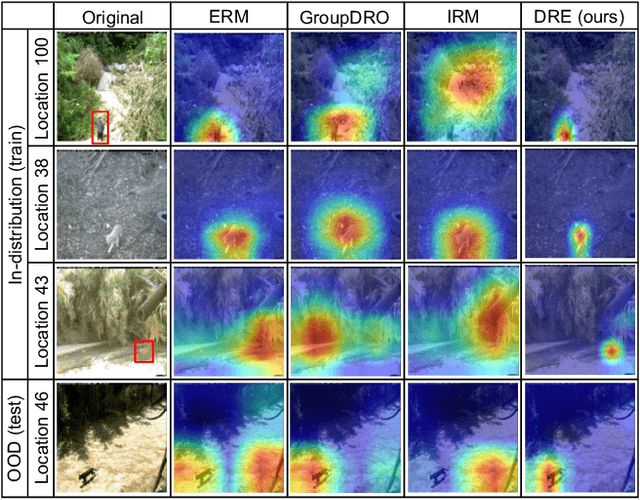
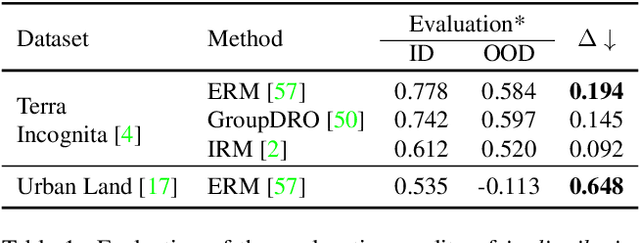
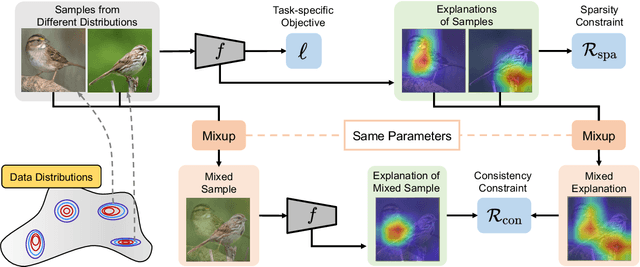

As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.
Evaluating GPT-3.5 and GPT-4 Models on Brazilian University Admission Exams
Mar 29, 2023


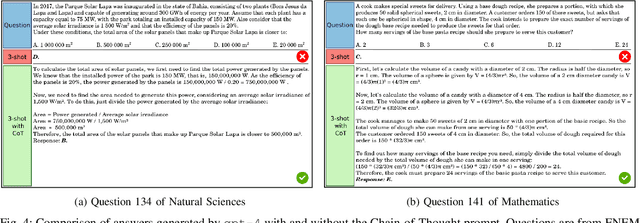
The present study aims to explore the capabilities of Language Models (LMs) in tackling high-stakes multiple-choice tests, represented here by the Exame Nacional do Ensino M\'edio (ENEM), a multidisciplinary entrance examination widely adopted by Brazilian universities. This exam poses challenging tasks for LMs, since its questions may span into multiple fields of knowledge, requiring understanding of information from diverse domains. For instance, a question may require comprehension of both statistics and biology to be solved. This work analyzed responses generated by GPT-3.5 and GPT-4 models for questions presented in the 2009-2017 exams, as well as for questions of the 2022 exam, which were made public after the training of the models was completed. Furthermore, different prompt strategies were tested, including the use of Chain-of-Thought (CoT) prompts to generate explanations for answers. On the 2022 edition, the best-performing model, GPT-4 with CoT, achieved an accuracy of 87%, largely surpassing GPT-3.5 by 11 points. The code and data used on experiments are available at https://github.com/piresramon/gpt-4-enem.
Point2Vec for Self-Supervised Representation Learning on Point Clouds
Mar 29, 2023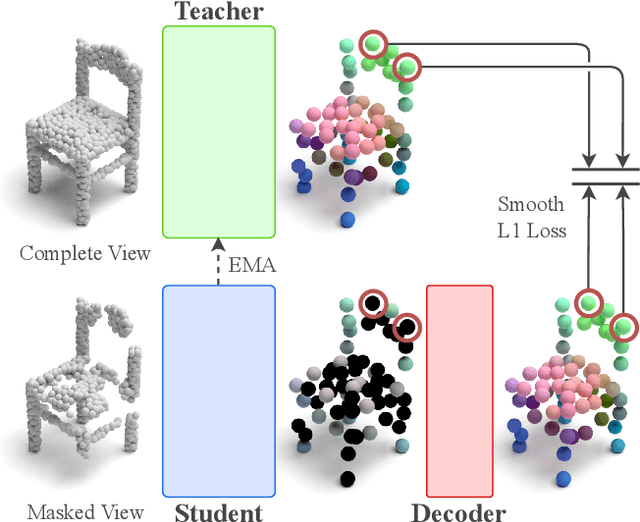
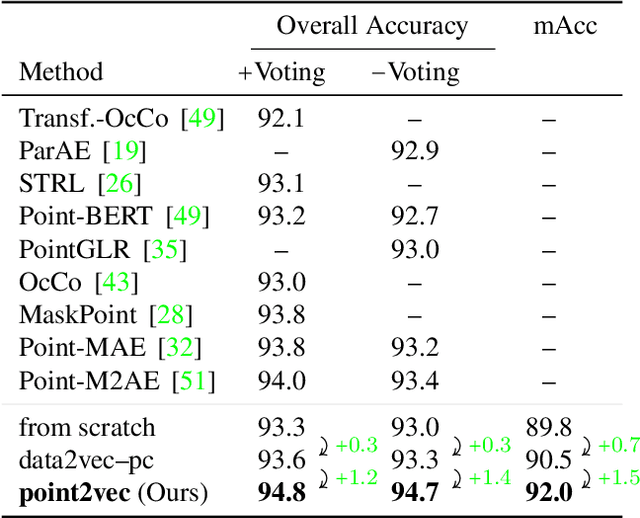
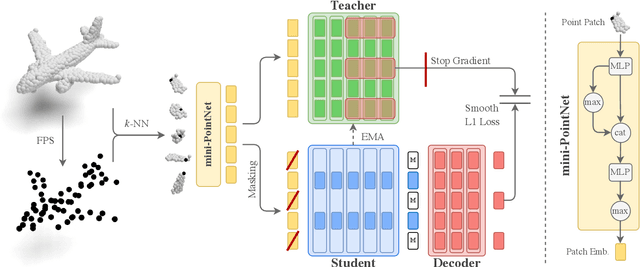
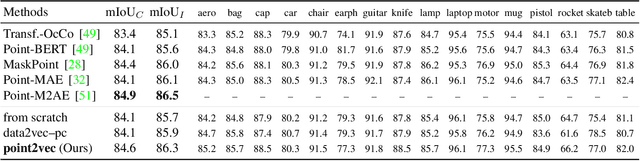
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds. To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.