 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scene Style Text Editing
Apr 20, 2023
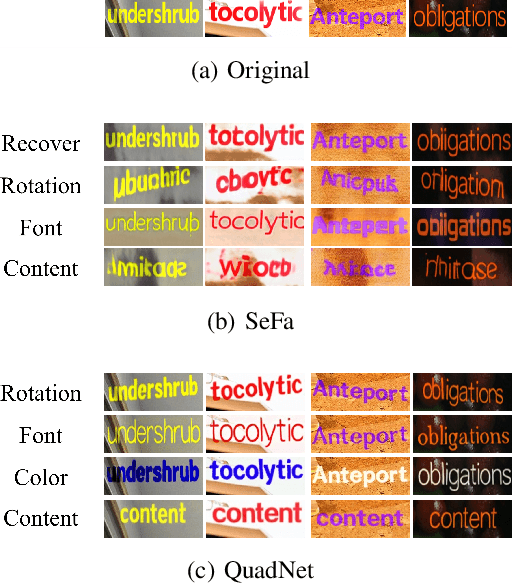
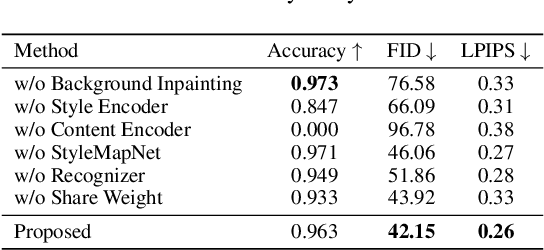
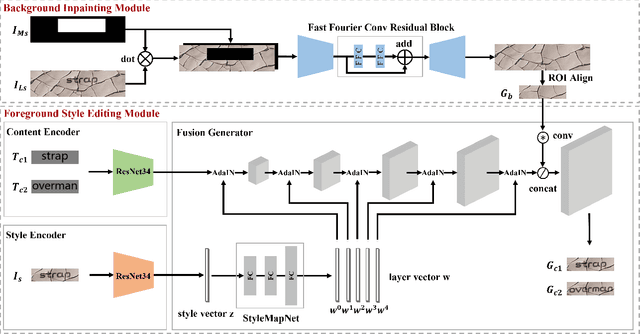
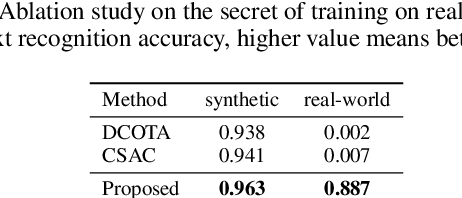
In this work, we propose a task called "Scene Style Text Editing (SSTE)", changing the text content as well as the text style of the source image while keeping the original text scene. Existing methods neglect to fine-grained adjust the style of the foreground text, such as its rotation angle, color, and font type. To tackle this task, we propose a quadruple framework named "QuadNet" to embed and adjust foreground text styles in the latent feature space. Specifically, QuadNet consists of four parts, namely background inpainting, style encoder, content encoder, and fusion generator. The background inpainting erases the source text content and recovers the appropriate background with a highly authentic texture. The style encoder extracts the style embedding of the foreground text. The content encoder provides target text representations in the latent feature space to implement the content edits. The fusion generator combines the information yielded from the mentioned parts and generates the rendered text images. Practically, our method is capable of performing promisingly on real-world datasets with merely string-level annotation. To the best of our knowledge, our work is the first to finely manipulate the foreground text content and style by deeply semantic editing in the latent feature space. Extensive experiments demonstrate that QuadNet has the ability to generate photo-realistic foreground text and avoid source text shadows in real-world scenes when editing text content.
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
Apr 03, 2023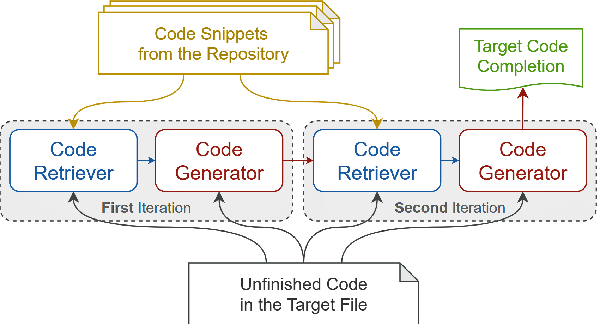
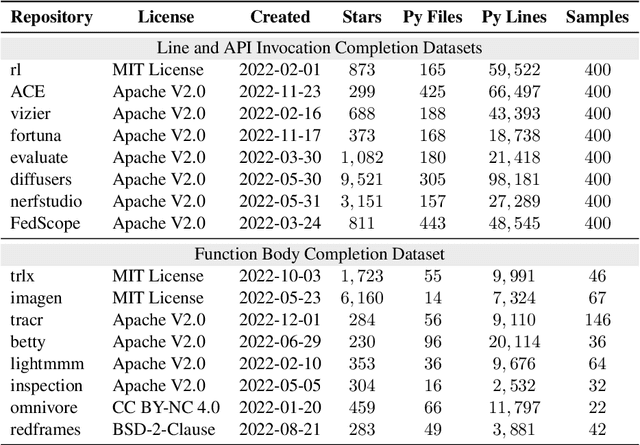
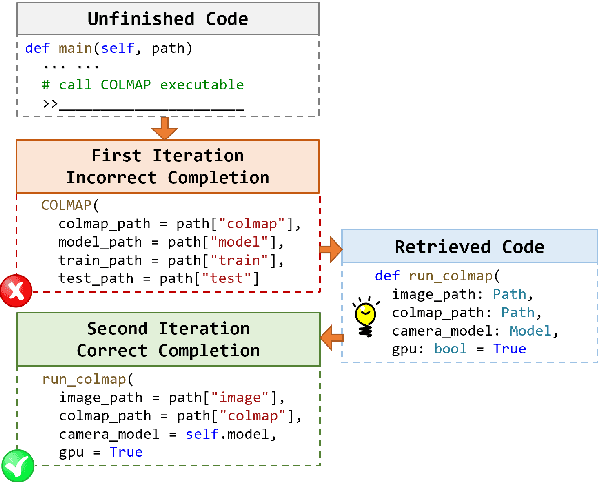
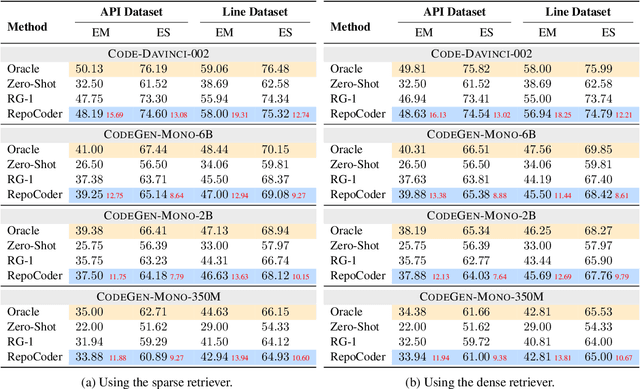
The task of repository-level code completion is to continue writing the unfinished code based on a broader context of the repository. While for automated code completion tools, it is difficult to utilize the useful information scattered in different files. We propose RepoCoder, a simple, generic, and effective framework to address the challenge. It streamlines the repository-level code completion process by incorporating a similarity-based retriever and a pre-trained code language model, which allows for the effective utilization of repository-level information for code completion and grants the ability to generate code at various levels of granularity. Furthermore, RepoCoder utilizes a novel iterative retrieval-generation paradigm that bridges the gap between retrieval context and the intended completion target. We also propose a new benchmark RepoEval, which consists of the latest and high-quality real-world repositories covering line, API invocation, and function body completion scenarios. We test the performance of RepoCoder by using various combinations of code retrievers and generators. Experimental results indicate that RepoCoder significantly improves the zero-shot code completion baseline by over 10% in all settings and consistently outperforms the vanilla retrieval-augmented code completion approach. Furthermore, we validate the effectiveness of RepoCoder through comprehensive analysis, providing valuable insights for future research.
Multi-Modal Perceiver Language Model for Outcome Prediction in Emergency Department
Apr 03, 2023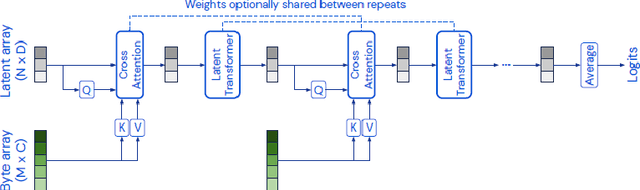

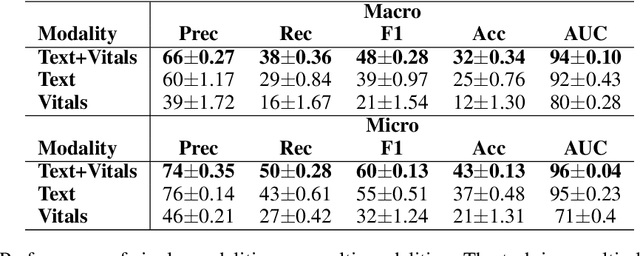
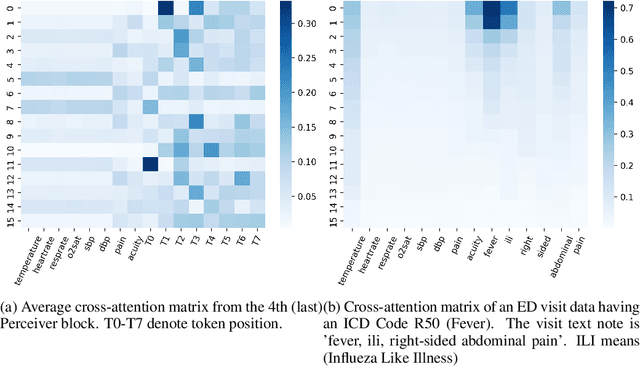
Language modeling have shown impressive progress in generating compelling text with good accuracy and high semantic coherence. An interesting research direction is to augment these powerful models for specific applications using contextual information. In this work, we explore multi-modal language modeling for healthcare applications. We are interested in outcome prediction and patient triage in hospital emergency department based on text information in chief complaints and vital signs recorded at triage. We adapt Perceiver - a modality-agnostic transformer-based model that has shown promising results in several applications. Since vital-sign modality is represented in tabular format, we modified Perceiver position encoding to ensure permutation invariance. We evaluated the multi-modal language model for the task of diagnosis code prediction using MIMIC-IV ED dataset on 120K visits. In the experimental analysis, we show that mutli-modality improves the prediction performance compared with models trained solely on text or vital signs. We identified disease categories for which multi-modality leads to performance improvement and show that for these categories, vital signs have added predictive power. By analyzing the cross-attention layer, we show how multi-modality contributes to model predictions. This work gives interesting insights on the development of multi-modal language models for healthcare applications.
Worst-Case Control and Learning Using Partial Observations Over an Infinite Time-Horizon
Mar 31, 2023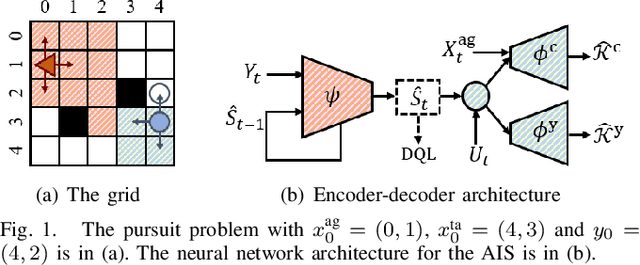
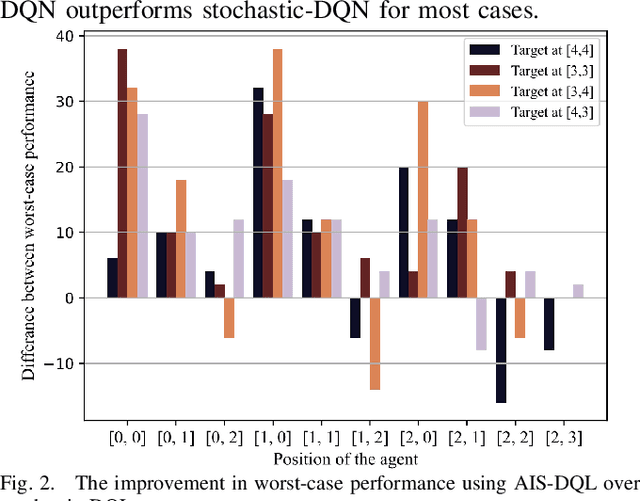
Safety-critical cyber-physical systems require control strategies whose worst-case performance is robust against adversarial disturbances and modeling uncertainties. In this paper, we present a framework for approximate control and learning in partially observed systems to minimize the worst-case discounted cost over an infinite time horizon. We model disturbances to the system as finite-valued uncertain variables with unknown probability distributions. For problems with known system dynamics, we construct a dynamic programming (DP) decomposition to compute the optimal control strategy. Our first contribution is to define information states that improve the computational tractability of this DP without loss of optimality. Then, we describe a simplification for a class of problems where the incurred cost is observable at each time instance. Our second contribution is defining an approximate information state that can be constructed or learned directly from observed data for problems with observable costs. We derive bounds on the performance loss of the resulting approximate control strategy and illustrate the effectiveness of our approach in partially observed decision-making problems with a numerical example.
WebQAmGaze: A Multilingual Webcam Eye-Tracking-While-Reading Dataset
Apr 14, 2023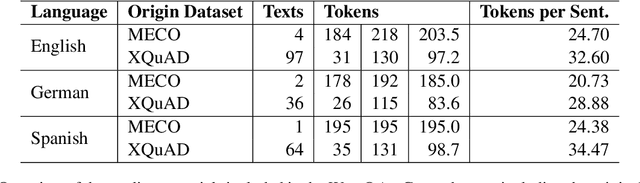
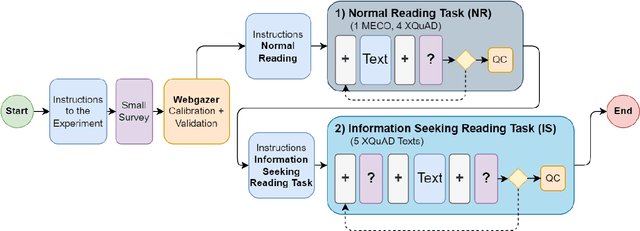
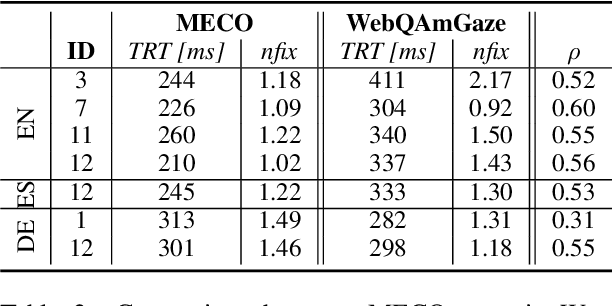
We create WebQAmGaze, a multilingual low-cost eye-tracking-while-reading dataset, designed to support the development of fair and transparent NLP models. WebQAmGaze includes webcam eye-tracking data from 332 participants naturally reading English, Spanish, and German texts. Each participant performs two reading tasks composed of five texts, a normal reading and an information-seeking task. After preprocessing the data, we find that fixations on relevant spans seem to indicate correctness when answering the comprehension questions. Additionally, we perform a comparative analysis of the data collected to high-quality eye-tracking data. The results show a moderate correlation between the features obtained with the webcam-ET compared to those of a commercial ET device. We believe this data can advance webcam-based reading studies and open a way to cheaper and more accessible data collection. WebQAmGaze is useful to learn about the cognitive processes behind question answering (QA) and to apply these insights to computational models of language understanding.
Detection and Estimation of Structural Breaks in High-Dimensional Functional Time Series
Apr 14, 2023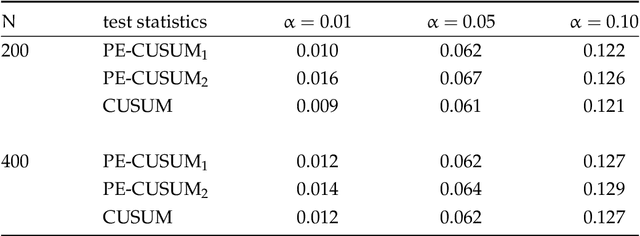
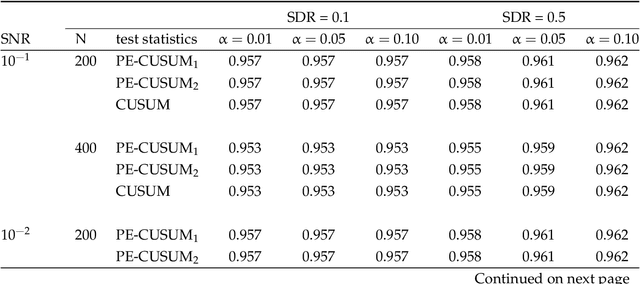
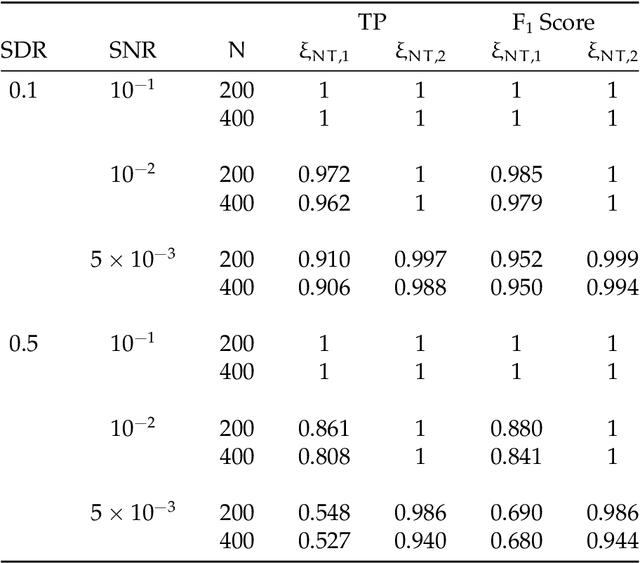
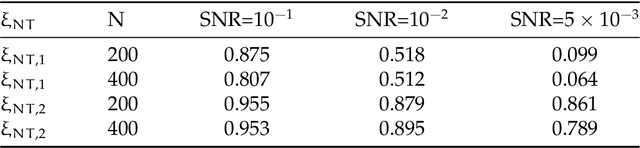
In this paper, we consider detecting and estimating breaks in heterogeneous mean functions of high-dimensional functional time series which are allowed to be cross-sectionally correlated and temporally dependent. A new test statistic combining the functional CUSUM statistic and power enhancement component is proposed with asymptotic null distribution theory comparable to the conventional CUSUM theory derived for a single functional time series. In particular, the extra power enhancement component enlarges the region where the proposed test has power, and results in stable power performance when breaks are sparse in the alternative hypothesis. Furthermore, we impose a latent group structure on the subjects with heterogeneous break points and introduce an easy-to-implement clustering algorithm with an information criterion to consistently estimate the unknown group number and membership. The estimated group structure can subsequently improve the convergence property of the post-clustering break point estimate. Monte-Carlo simulation studies and empirical applications show that the proposed estimation and testing techniques have satisfactory performance in finite samples.
Reducing Network Load via Message Utility Estimation for Decentralized Multirobot Teams
Apr 14, 2023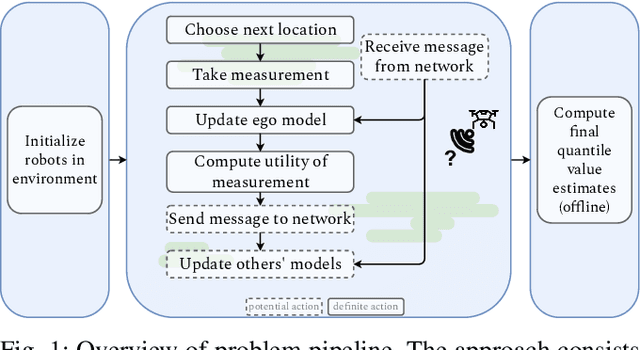
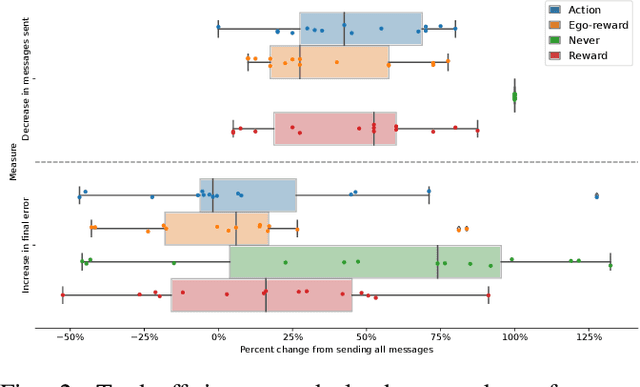
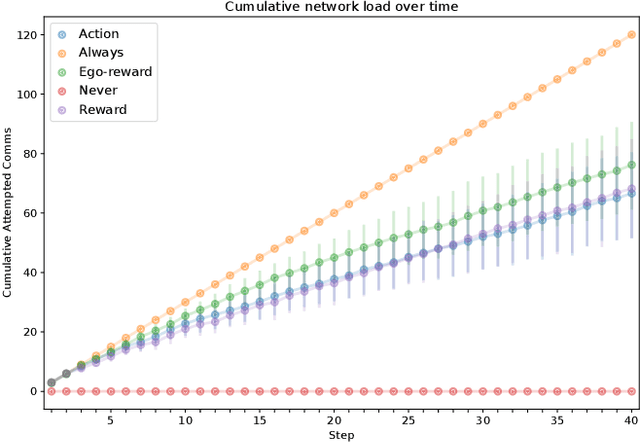
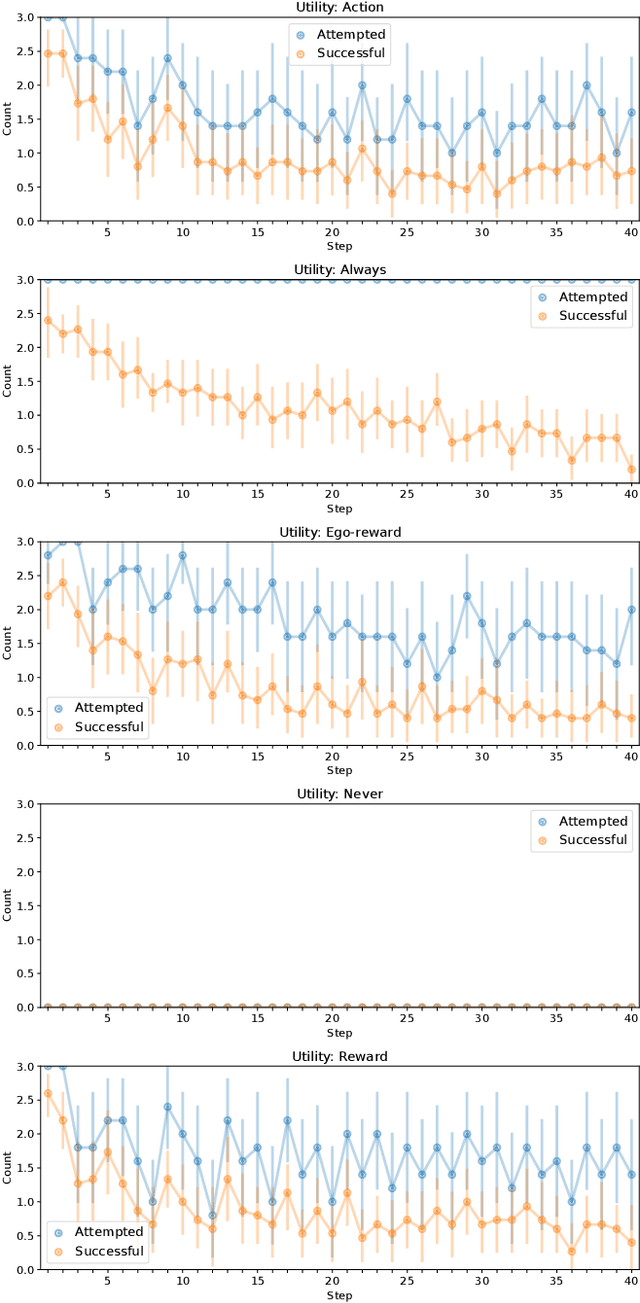
We are motivated by quantile estimation of algae concentration in lakes. We find that multirobot teams improve performance in this task over single robots, and communication-enabled teams further over communication-deprived teams; however, real robots are resource-constrained, and communication networks cannot support arbitrary message loads, making na\"ive, constant information-sharing but also complex modeling and decision-making infeasible. With this in mind, we propose online, locally computable metrics for determining the utility of transmitting a given message to the other team members and a decision-theoretic approach that chooses to transmit only the most useful messages, using a decentralized and independent framework for maintaining beliefs of other teammates. We validate our approach in simulation on a real-world aquatic dataset, and show that restricting communication via a utility estimation method based on the expected impact of a message on future teammate behavior results in a 44% decrease in network load while increasing quantile estimation error by only 2.16%.
Time Reversal Enabled Fiber-Optic Time Synchronization
Apr 14, 2023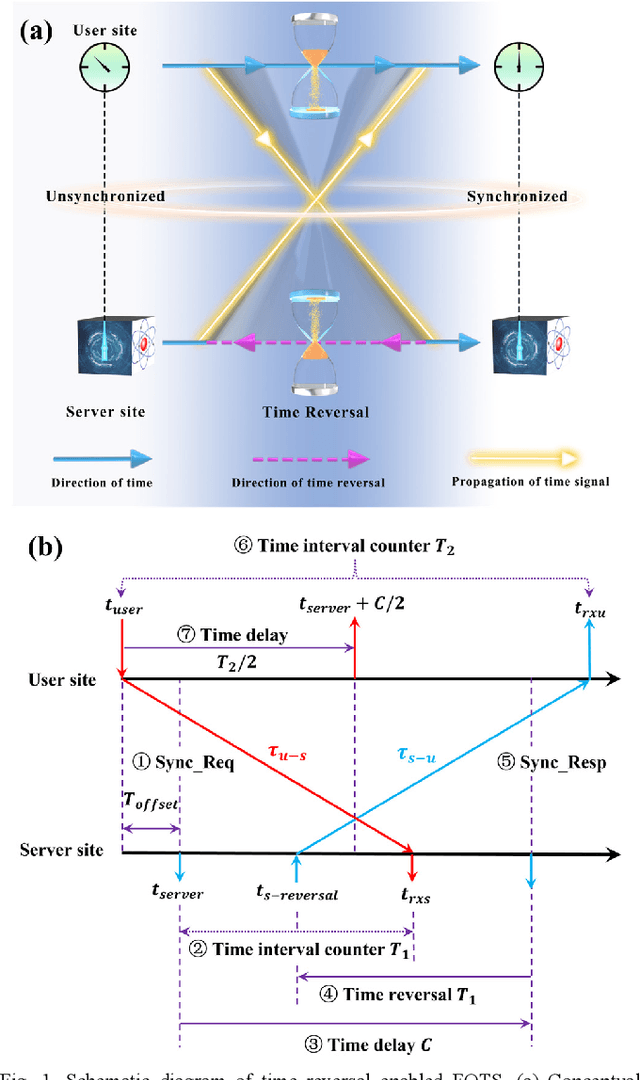
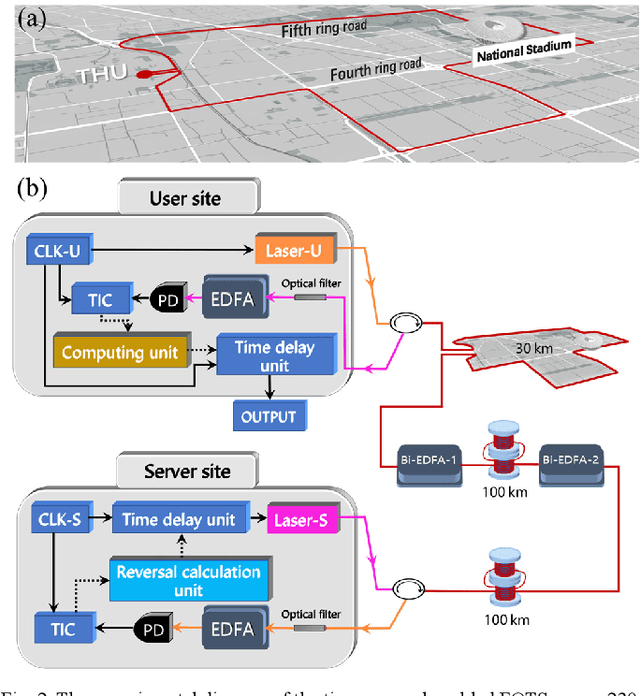
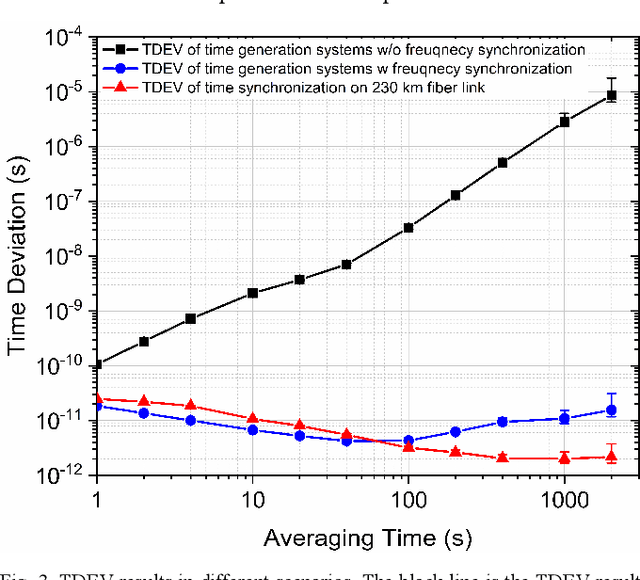
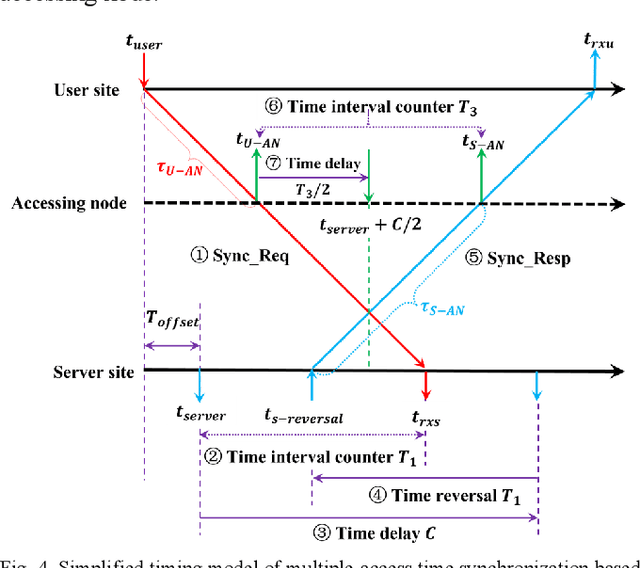
Over the past few decades, fiber-optic time synchronization (FOTS) has provided fundamental support for the efficient operation of modern society. Looking toward the future beyond fifth-generation/sixth-generation (B5G/6G) scenarios and very large radio telescope arrays, developing high-precision, low-complexity and scalable FOTS technology is crucial for building a large-scale time synchronization network. However, the traditional two-way FOTS method needs a data layer to exchange time delay information. This increases the complexity of system and makes it impossible to realize multiple-access time synchronization. In this paper, a time reversal enabled FOTS method is proposed. It measures the clock difference between two locations without involving a data layer, which can reduce the complexity of the system. Moreover, it can also achieve multiple-access time synchronization along the fiber link. Tests over a 230 km fiber link have been carried out to demonstrate the high performance of the proposed method.
GNNFormer: A Graph-based Framework for Cytopathology Report Generation
Mar 17, 2023
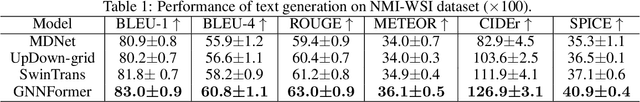
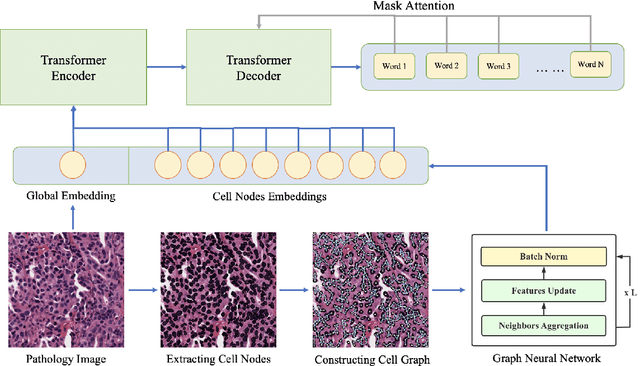
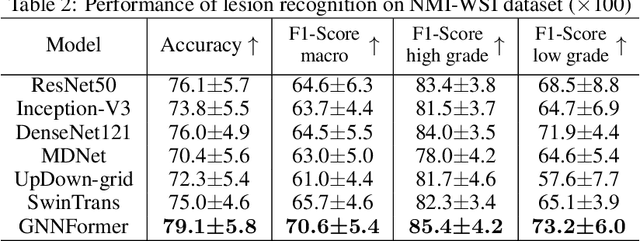
Cytopathology report generation is a necessary step for the standardized examination of pathology images. However, manually writing detailed reports brings heavy workloads for pathologists. To improve efficiency, some existing works have studied automatic generation of cytopathology reports, mainly by applying image caption generation frameworks with visual encoders originally proposed for natural images. A common weakness of these works is that they do not explicitly model the structural information among cells, which is a key feature of pathology images and provides significant information for making diagnoses. In this paper, we propose a novel graph-based framework called GNNFormer, which seamlessly integrates graph neural network (GNN) and Transformer into the same framework, for cytopathology report generation. To the best of our knowledge, GNNFormer is the first report generation method that explicitly models the structural information among cells in pathology images. It also effectively fuses structural information among cells, fine-grained morphology features of cells and background features to generate high-quality reports. Experimental results on the NMI-WSI dataset show that GNNFormer can outperform other state-of-the-art baselines.
Heterogeneous Information Crossing on Graphs for Session-based Recommender Systems
Oct 24, 2022

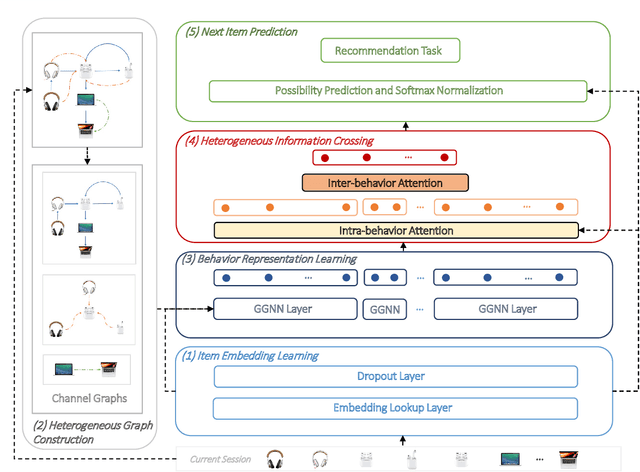
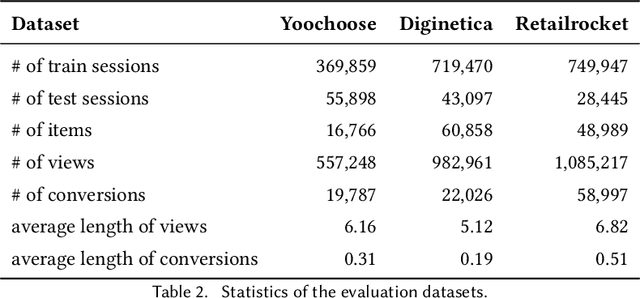
Recommender systems are fundamental information filtering techniques to recommend content or items that meet users' personalities and potential needs. As a crucial solution to address the difficulty of user identification and unavailability of historical information, session-based recommender systems provide recommendation services that only rely on users' behaviors in the current session. However, most existing studies are not well-designed for modeling heterogeneous user behaviors and capturing the relationships between them in practical scenarios. To fill this gap, in this paper, we propose a novel graph-based method, namely Heterogeneous Information Crossing on Graphs (HICG). HICG utilizes multiple types of user behaviors in the sessions to construct heterogeneous graphs, and captures users' current interests with their long-term preferences by effectively crossing the heterogeneous information on the graphs. In addition, we also propose an enhanced version, named HICG-CL, which incorporates contrastive learning (CL) technique to enhance item representation ability. By utilizing the item co-occurrence relationships across different sessions, HICG-CL improves the recommendation performance of HICG. We conduct extensive experiments on three real-world recommendation datasets, and the results verify that (i) HICG achieves the state-of-the-art performance by utilizing multiple types of behaviors on the heterogeneous graph. (ii) HICG-CL further significantly improves the recommendation performance of HICG by the proposed contrastive learning module.