 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Prototype Implementation of Rate Splitting Multiple Access using Software-Defined Radios
May 12, 2023
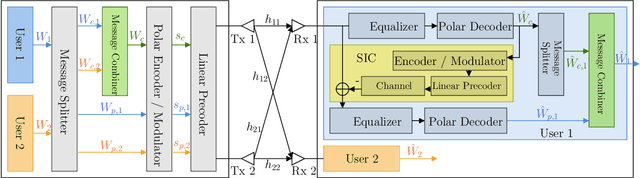
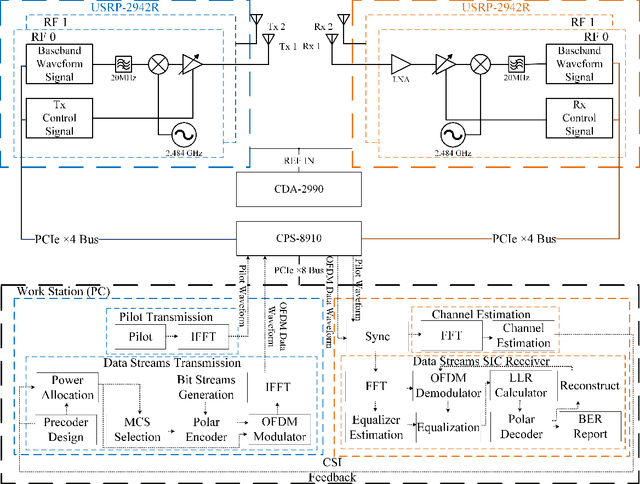
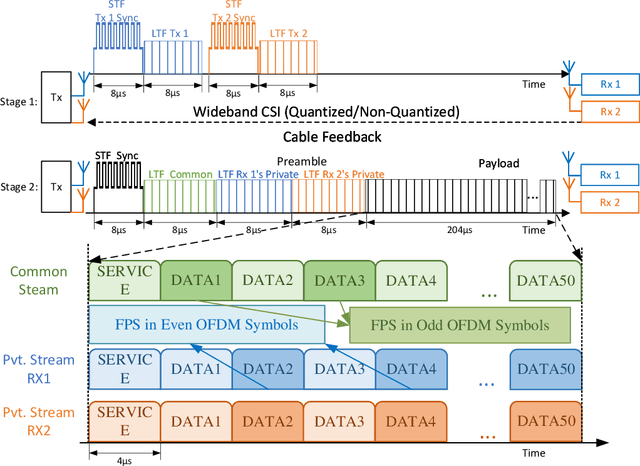
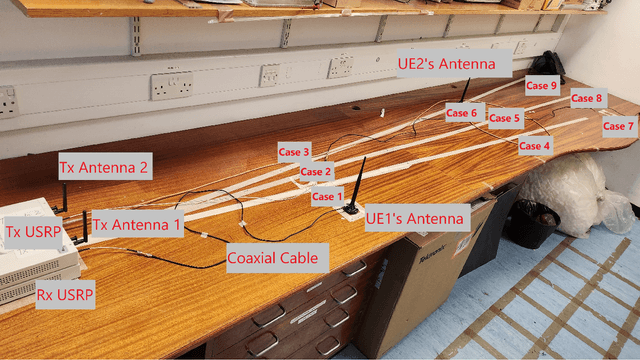
For interference-limited multi-user communications, many papers have demonstrated, in theory, the effectiveness of Rate Splitting Multiple Access (RSMA) in suppressing the interference and achieving better outcomes (w.r.t spectral efficiency, fairness etc.) than the conventional Space Division Multiple Access (SDMA) used in present-day standards. However, an experimental demonstration of RSMA's benefits is missing in the literature. In this paper, we address this gap by realizing an RSMA prototype using software-defined radios. For the two-user multiple-input single-output (MISO) scenario, we measure the throughput performance of SDMA and RSMA in nine different scenarios that vary in terms of the channel pathloss and spatial correlation experienced by the users. Emulating perfect channel state information (CSI) at the transmitter through unquantized CSI feedback, we observe that RSMA achieves a higher sum throughput (upto 57%) and more fairness than SDMA when the user channels have high spatial correlation. Similarly, emulating imperfect CSI through quantized feedback, RSMA - along with the above trend - also experiences a smaller sum throughput loss, relative to the unquantized case (37%, on average, as opposed to 44% for SDMA). These outcomes are consistent with theoretical predictions, and demonstrate the feasibility and potential of RSMA for next generation wireless networks (e.g., 6G).
Multi-Relational Hyperbolic Word Embeddings from Natural Language Definitions
May 12, 2023
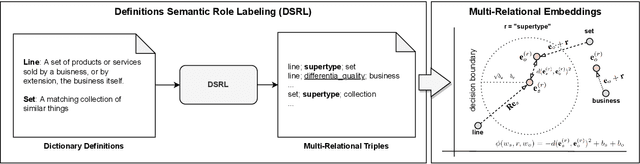

Neural-based word embeddings using solely distributional information have consistently produced useful meaning representations for downstream tasks. However, existing approaches often result in representations that are hard to interpret and control. Natural language definitions, on the other side, possess a recursive, self-explanatory semantic structure that can support novel representation learning paradigms able to preserve explicit conceptual relations and constraints in the vector space. This paper proposes a neuro-symbolic, multi-relational framework to learn word embeddings exclusively from natural language definitions by jointly mapping defined and defining terms along with their corresponding semantic relations. By automatically extracting the relations from definitions corpora and formalising the learning problem via a translational objective, we specialise the framework in hyperbolic space to capture the hierarchical and multi-resolution structure induced by the definitions. An extensive empirical analysis demonstrates that the framework can help impose the desired structural constraints while preserving the mapping required for controllable and interpretable semantic navigation. Moreover, the experiments reveal the superiority of the hyperbolic word embeddings over the euclidean counterparts and demonstrate that the multi-relational framework can obtain competitive results when compared to state-of-the-art neural approaches (including Transformers), with the advantage of being significantly more efficient and intrinsically interpretable.
Multi-Modal 3D Object Detection by Box Matching
May 12, 2023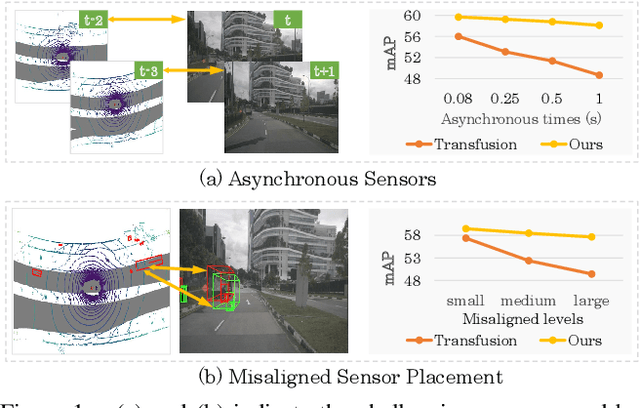
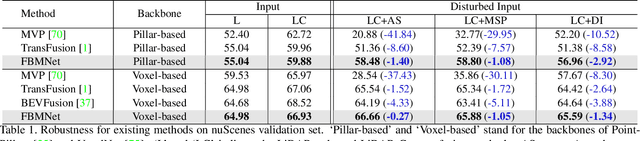
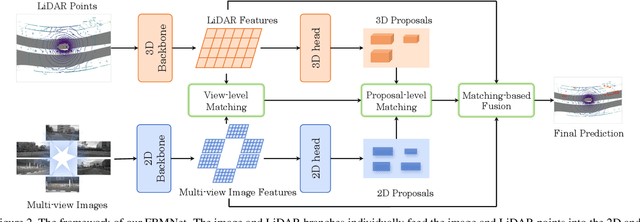
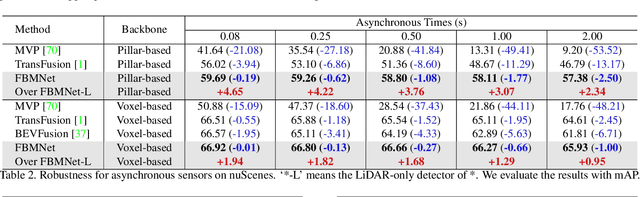
Multi-modal 3D object detection has received growing attention as the information from different sensors like LiDAR and cameras are complementary. Most fusion methods for 3D detection rely on an accurate alignment and calibration between 3D point clouds and RGB images. However, such an assumption is not reliable in a real-world self-driving system, as the alignment between different modalities is easily affected by asynchronous sensors and disturbed sensor placement. We propose a novel {F}usion network by {B}ox {M}atching (FBMNet) for multi-modal 3D detection, which provides an alternative way for cross-modal feature alignment by learning the correspondence at the bounding box level to free up the dependency of calibration during inference. With the learned assignments between 3D and 2D object proposals, the fusion for detection can be effectively performed by combing their ROI features. Extensive experiments on the nuScenes dataset demonstrate that our method is much more stable in dealing with challenging cases such as asynchronous sensors, misaligned sensor placement, and degenerated camera images than existing fusion methods. We hope that our FBMNet could provide an available solution to dealing with these challenging cases for safety in real autonomous driving scenarios. Codes will be publicly available at https://github.com/happinesslz/FBMNet.
Influence of Swarm Intelligence in Data Clustering Mechanisms
May 07, 2023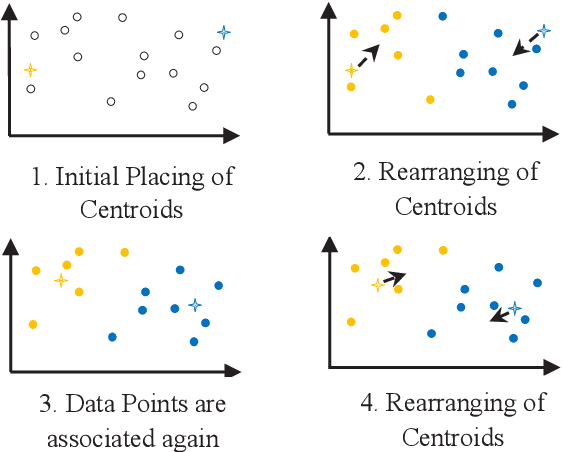

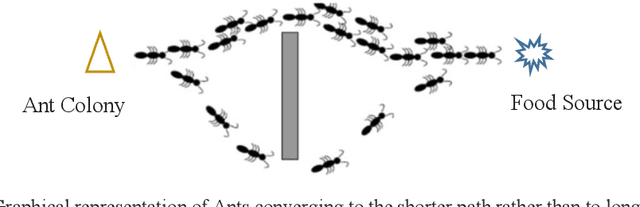
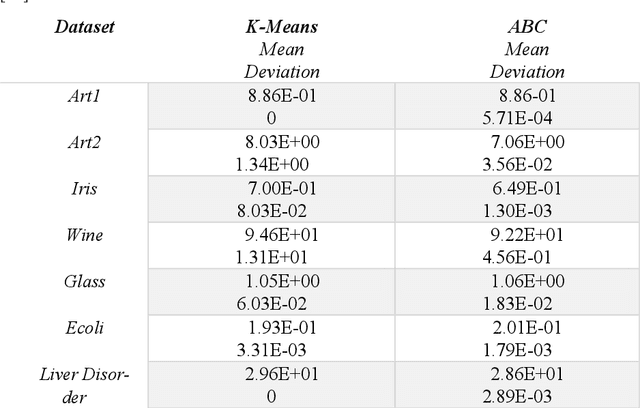
Data mining focuses on discovering interesting, non-trivial and meaningful information from large datasets. Data clustering is one of the unsupervised and descriptive data mining task which group data based on similarity features and physically stored together. As a partitioning clustering method, K-means is widely used due to its simplicity and easiness of implementation. But this method has limitations such as local optimal convergence and initial point sensibility. Due to these impediments, nature inspired Swarm based algorithms such as Artificial Bee Colony Algorithm, Ant Colony Optimization, Firefly Algorithm, Bat Algorithm and etc. are used for data clustering to cope with larger datasets with lack and inconsistency of data. In some cases, those algorithms are used with traditional approaches such as K-means as hybrid approaches to produce better results. This paper reviews the performances of these new approaches and compares which is best for certain problematic situation.
Classification Tree Pruning Under Covariate Shift
May 07, 2023
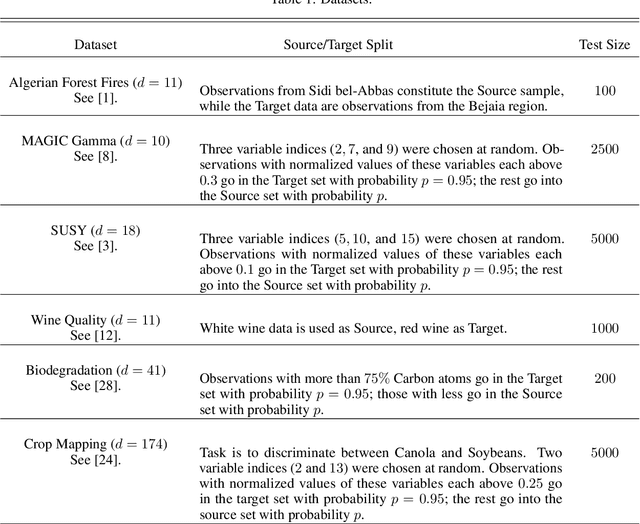
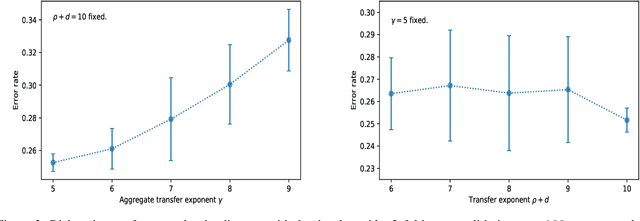
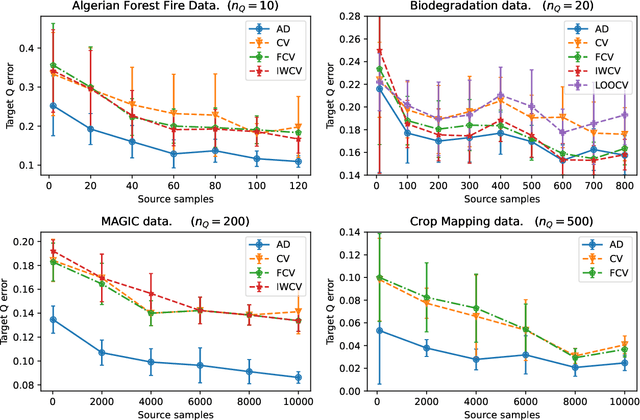
We consider the problem of \emph{pruning} a classification tree, that is, selecting a suitable subtree that balances bias and variance, in common situations with inhomogeneous training data. Namely, assuming access to mostly data from a distribution $P_{X, Y}$, but little data from a desired distribution $Q_{X, Y}$ with different $X$-marginals, we present the first efficient procedure for optimal pruning in such situations, when cross-validation and other penalized variants are grossly inadequate. Optimality is derived with respect to a notion of \emph{average discrepancy} $P_{X} \to Q_{X}$ (averaged over $X$ space) which significantly relaxes a recent notion -- termed \emph{transfer-exponent} -- shown to tightly capture the limits of classification under such a distribution shift. Our relaxed notion can be viewed as a measure of \emph{relative dimension} between distributions, as it relates to existing notions of information such as the Minkowski and Renyi dimensions.
Injecting Spatial Information for Monaural Speech Enhancement via Knowledge Distillation
Dec 02, 2022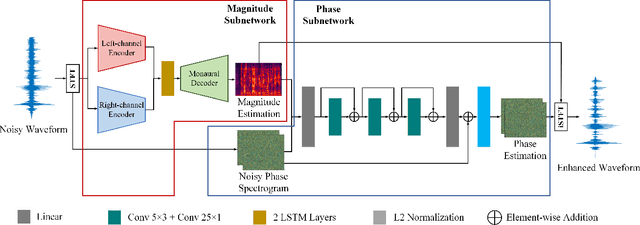
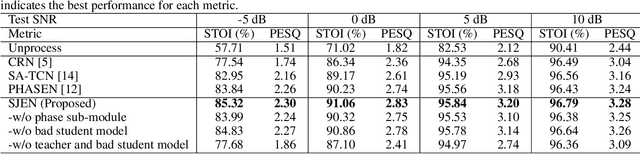
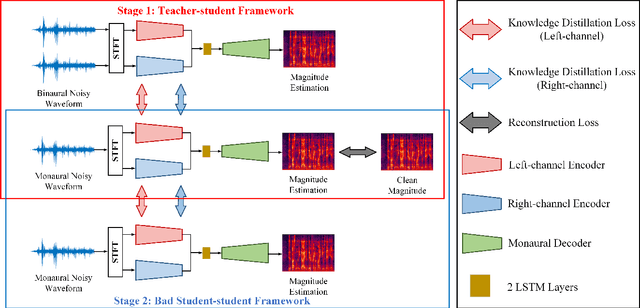
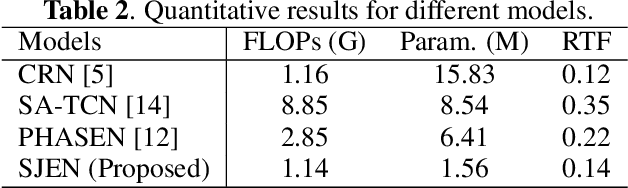
Monaural speech enhancement (SE) provides a versatile and cost-effective approach to SE tasks by utilizing recordings from a single microphone. However, the monaural SE lags performance behind multi-channel SE as the monaural SE methods are unable to extract spatial information from one-channel recordings, which greatly limits their application scenarios. To address this issue, we inject spatial information into the monaural SE model and propose a knowledge distillation strategy to enable the monaural SE model to learn binaural speech features from the binaural SE model, which makes monaural SE model possible to reconstruct higher intelligibility and quality enhanced speeches under low signal-to-noise ratio (SNR) conditions. Extensive experiments show that our proposed monaural SE model by injecting spatial information via knowledge distillation achieves favorable performance against other monaural SE models with fewer parameters.
Sensitive Data Detection with High-Throughput Machine Learning Models in Electrical Health Records
Apr 30, 2023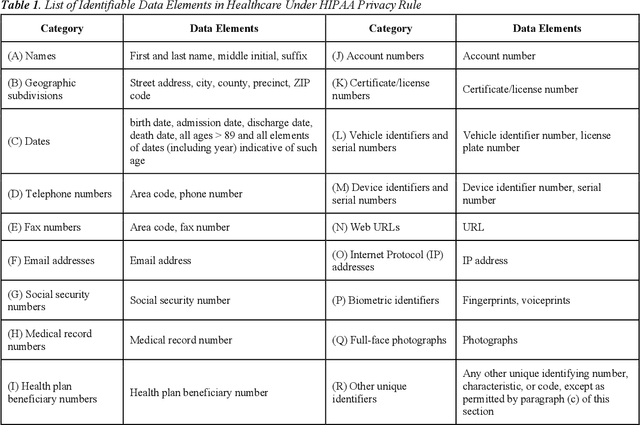
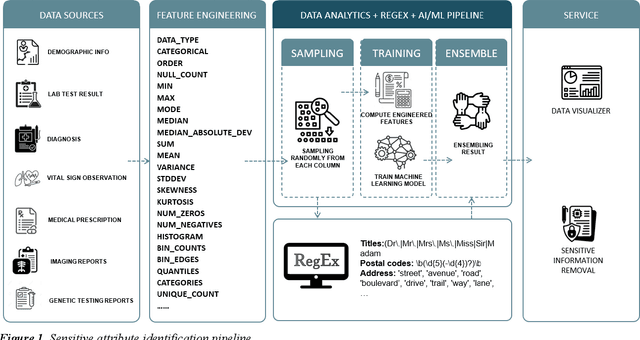

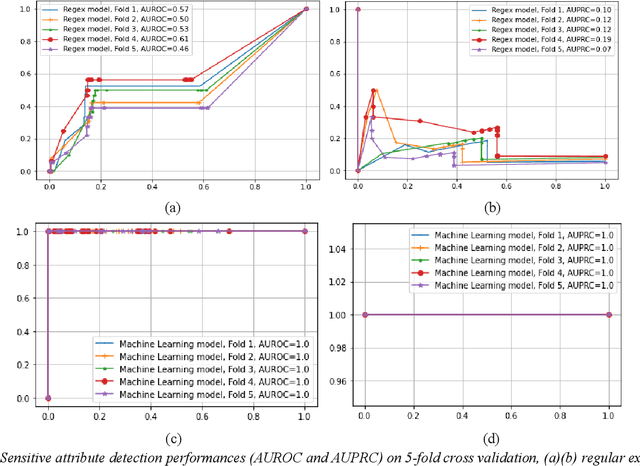
In the era of big data, there is an increasing need for healthcare providers, communities, and researchers to share data and collaborate to improve health outcomes, generate valuable insights, and advance research. The Health Insurance Portability and Accountability Act of 1996 (HIPAA) is a federal law designed to protect sensitive health information by defining regulations for protected health information (PHI). However, it does not provide efficient tools for detecting or removing PHI before data sharing. One of the challenges in this area of research is the heterogeneous nature of PHI fields in data across different parties. This variability makes rule-based sensitive variable identification systems that work on one database fail on another. To address this issue, our paper explores the use of machine learning algorithms to identify sensitive variables in structured data, thus facilitating the de-identification process. We made a key observation that the distributions of metadata of PHI fields and non-PHI fields are very different. Based on this novel finding, we engineered over 30 features from the metadata of the original features and used machine learning to build classification models to automatically identify PHI fields in structured Electronic Health Record (EHR) data. We trained the model on a variety of large EHR databases from different data sources and found that our algorithm achieves 99% accuracy when detecting PHI-related fields for unseen datasets. The implications of our study are significant and can benefit industries that handle sensitive data.
Leveraging Large Language Models in Conversational Recommender Systems
May 13, 2023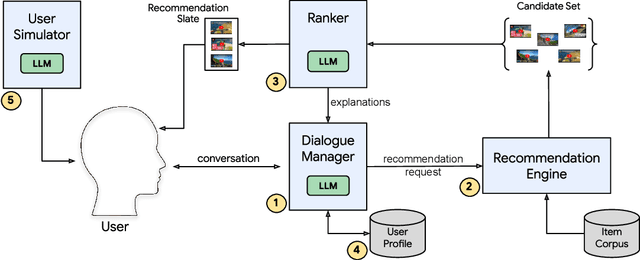



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
Model-agnostic Measure of Generalization Difficulty
May 01, 2023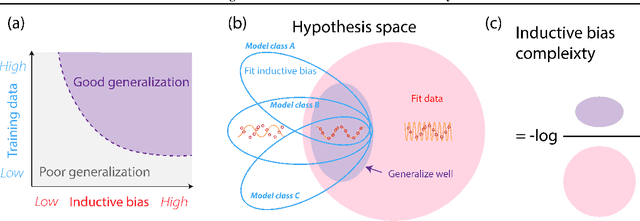
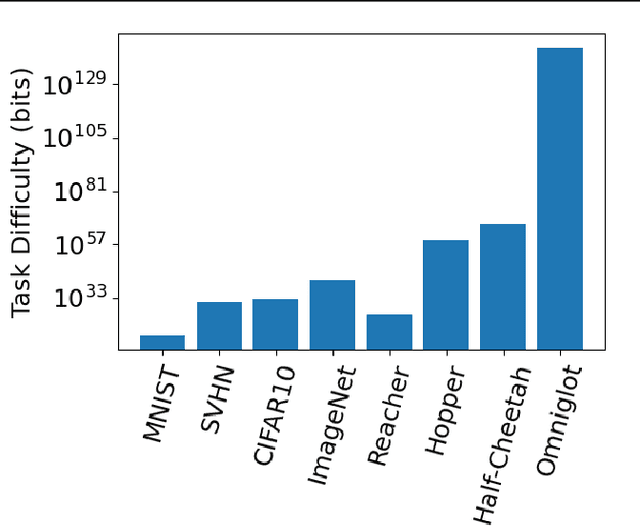
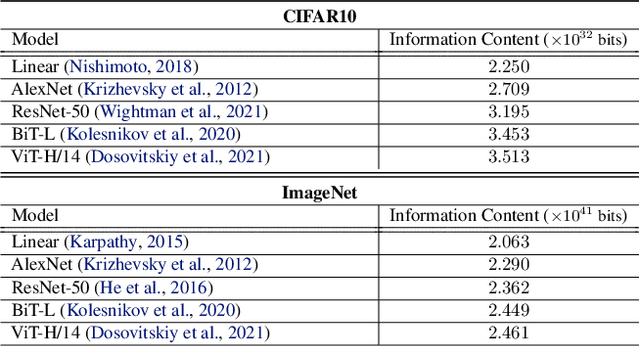
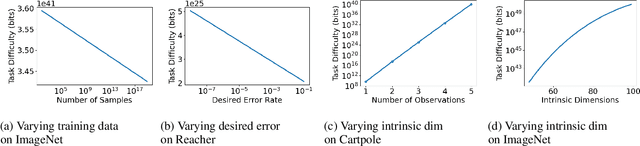
The measure of a machine learning algorithm is the difficulty of the tasks it can perform, and sufficiently difficult tasks are critical drivers of strong machine learning models. However, quantifying the generalization difficulty of machine learning benchmarks has remained challenging. We propose what is to our knowledge the first model-agnostic measure of the inherent generalization difficulty of tasks. Our inductive bias complexity measure quantifies the total information required to generalize well on a task minus the information provided by the data. It does so by measuring the fractional volume occupied by hypotheses that generalize on a task given that they fit the training data. It scales exponentially with the intrinsic dimensionality of the space over which the model must generalize but only polynomially in resolution per dimension, showing that tasks which require generalizing over many dimensions are drastically more difficult than tasks involving more detail in fewer dimensions. Our measure can be applied to compute and compare supervised learning, reinforcement learning and meta-learning generalization difficulties against each other. We show that applied empirically, it formally quantifies intuitively expected trends, e.g. that in terms of required inductive bias, MNIST < CIFAR10 < Imagenet and fully observable Markov decision processes (MDPs) < partially observable MDPs. Further, we show that classification of complex images $<$ few-shot meta-learning with simple images. Our measure provides a quantitative metric to guide the construction of more complex tasks requiring greater inductive bias, and thereby encourages the development of more sophisticated architectures and learning algorithms with more powerful generalization capabilities.
Generating Texture for 3D Human Avatar from a Single Image using Sampling and Refinement Networks
May 01, 2023There has been significant progress in generating an animatable 3D human avatar from a single image. However, recovering texture for the 3D human avatar from a single image has been relatively less addressed. Because the generated 3D human avatar reveals the occluded texture of the given image as it moves, it is critical to synthesize the occluded texture pattern that is unseen from the source image. To generate a plausible texture map for 3D human avatars, the occluded texture pattern needs to be synthesized with respect to the visible texture from the given image. Moreover, the generated texture should align with the surface of the target 3D mesh. In this paper, we propose a texture synthesis method for a 3D human avatar that incorporates geometry information. The proposed method consists of two convolutional networks for the sampling and refining process. The sampler network fills in the occluded regions of the source image and aligns the texture with the surface of the target 3D mesh using the geometry information. The sampled texture is further refined and adjusted by the refiner network. To maintain the clear details in the given image, both sampled and refined texture is blended to produce the final texture map. To effectively guide the sampler network to achieve its goal, we designed a curriculum learning scheme that starts from a simple sampling task and gradually progresses to the task where the alignment needs to be considered. We conducted experiments to show that our method outperforms previous methods qualitatively and quantitatively.