 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence of Swarm Intelligence in Data Clustering Mechanisms
May 07, 2023



Data mining focuses on discovering interesting, non-trivial and meaningful information from large datasets. Data clustering is one of the unsupervised and descriptive data mining task which group data based on similarity features and physically stored together. As a partitioning clustering method, K-means is widely used due to its simplicity and easiness of implementation. But this method has limitations such as local optimal convergence and initial point sensibility. Due to these impediments, nature inspired Swarm based algorithms such as Artificial Bee Colony Algorithm, Ant Colony Optimization, Firefly Algorithm, Bat Algorithm and etc. are used for data clustering to cope with larger datasets with lack and inconsistency of data. In some cases, those algorithms are used with traditional approaches such as K-means as hybrid approaches to produce better results. This paper reviews the performances of these new approaches and compares which is best for certain problematic situation.
Document-aware Positional Encoding and Linguistic-guided Encoding for Abstractive Multi-document Summarization
Sep 13, 2022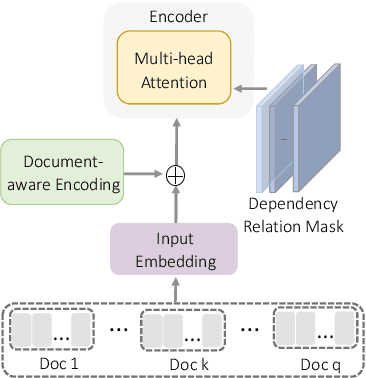
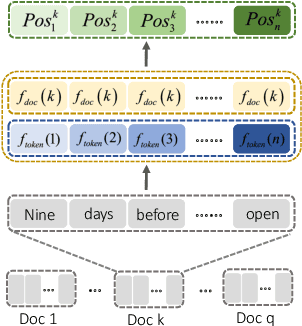
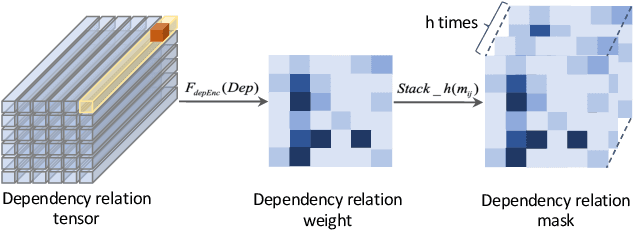
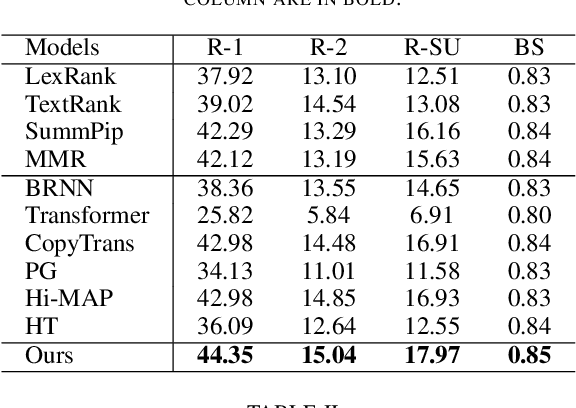
One key challenge in multi-document summarization is to capture the relations among input documents that distinguish between single document summarization (SDS) and multi-document summarization (MDS). Few existing MDS works address this issue. One effective way is to encode document positional information to assist models in capturing cross-document relations. However, existing MDS models, such as Transformer-based models, only consider token-level positional information. Moreover, these models fail to capture sentences' linguistic structure, which inevitably causes confusions in the generated summaries. Therefore, in this paper, we propose document-aware positional encoding and linguistic-guided encoding that can be fused with Transformer architecture for MDS. For document-aware positional encoding, we introduce a general protocol to guide the selection of document encoding functions. For linguistic-guided encoding, we propose to embed syntactic dependency relations into the dependency relation mask with a simple but effective non-linear encoding learner for feature learning. Extensive experiments show the proposed model can generate summaries with high quality.