 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Continual Vision-and-Language Navigation
Mar 22, 2024
Vision-and-Language Navigation (VLN) agents navigate to a destination using natural language instructions and the visual information they observe. Existing methods for training VLN agents presuppose fixed datasets, leading to a significant limitation: the introduction of new environments necessitates retraining with previously encountered environments to preserve their knowledge. This makes it difficult to train VLN agents that operate in the ever-changing real world. To address this limitation, we present the Continual Vision-and-Language Navigation (CVLN) paradigm, designed to evaluate agents trained through a continual learning process. For the training and evaluation of CVLN agents, we re-arrange existing VLN datasets to propose two datasets: CVLN-I, focused on navigation via initial-instruction interpretation, and CVLN-D, aimed at navigation through dialogue with other agents. Furthermore, we propose two novel rehearsal-based methods for CVLN, Perplexity Replay (PerpR) and Episodic Self-Replay (ESR). PerpR prioritizes replaying challenging episodes based on action perplexity, while ESR replays previously predicted action logits to preserve learned behaviors. We demonstrate the effectiveness of the proposed methods on CVLN through extensive experiments.
Boosting Meta-Training with Base Class Information for Few-Shot Learning
Mar 06, 2024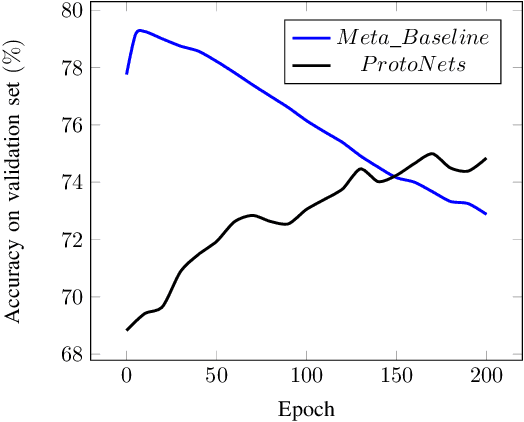
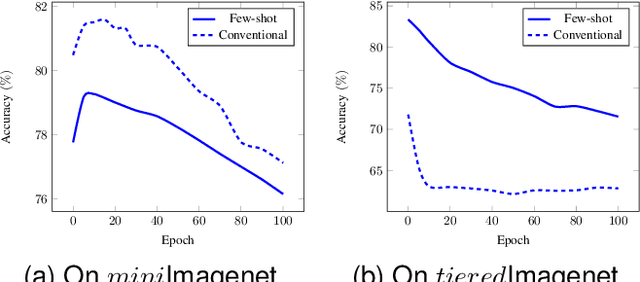
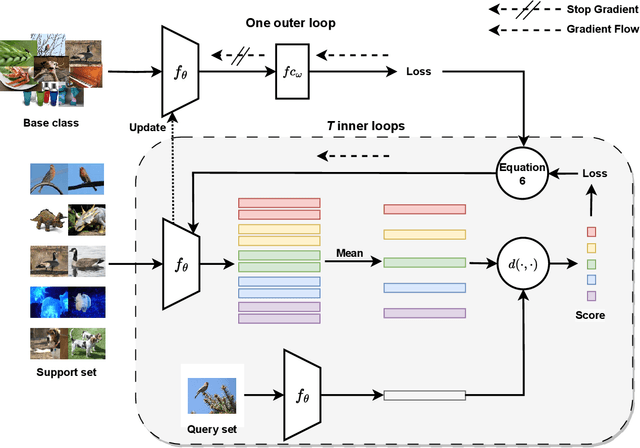
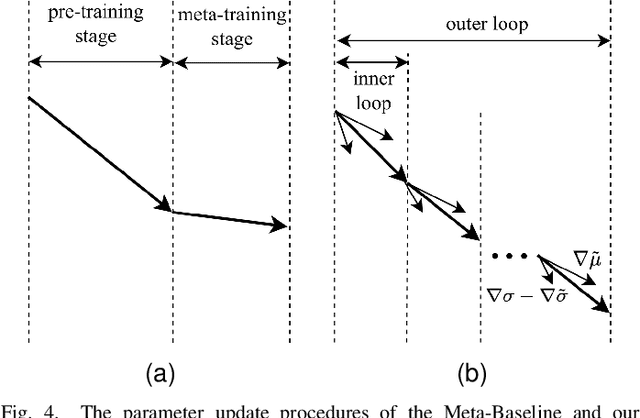
Few-shot learning, a challenging task in machine learning, aims to learn a classifier adaptable to recognize new, unseen classes with limited labeled examples. Meta-learning has emerged as a prominent framework for few-shot learning. Its training framework is originally a task-level learning method, such as Model-Agnostic Meta-Learning (MAML) and Prototypical Networks. And a recently proposed training paradigm called Meta-Baseline, which consists of sequential pre-training and meta-training stages, gains state-of-the-art performance. However, as a non-end-to-end training method, indicating the meta-training stage can only begin after the completion of pre-training, Meta-Baseline suffers from higher training cost and suboptimal performance due to the inherent conflicts of the two training stages. To address these limitations, we propose an end-to-end training paradigm consisting of two alternative loops. In the outer loop, we calculate cross entropy loss on the entire training set while updating only the final linear layer. In the inner loop, we employ the original meta-learning training mode to calculate the loss and incorporate gradients from the outer loss to guide the parameter updates. This training paradigm not only converges quickly but also outperforms existing baselines, indicating that information from the overall training set and the meta-learning training paradigm could mutually reinforce one another. Moreover, being model-agnostic, our framework achieves significant performance gains, surpassing the baseline systems by approximate 1%.
Grounding Spatial Relations in Text-Only Language Models
Mar 20, 2024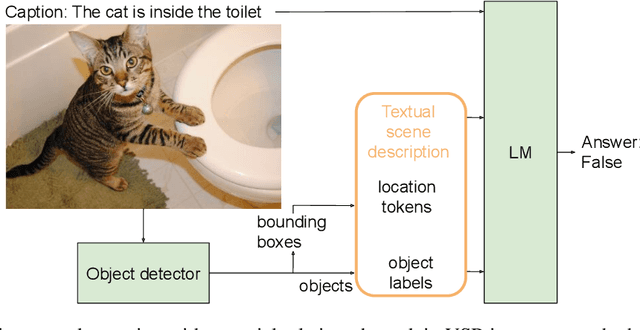
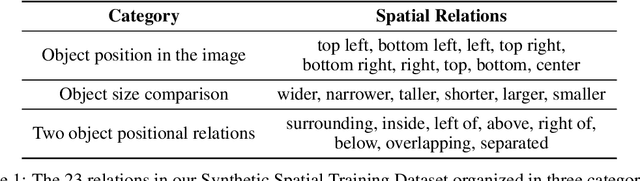


This paper shows that text-only Language Models (LM) can learn to ground spatial relations like "left of" or "below" if they are provided with explicit location information of objects and they are properly trained to leverage those locations. We perform experiments on a verbalized version of the Visual Spatial Reasoning (VSR) dataset, where images are coupled with textual statements which contain real or fake spatial relations between two objects of the image. We verbalize the images using an off-the-shelf object detector, adding location tokens to every object label to represent their bounding boxes in textual form. Given the small size of VSR, we do not observe any improvement when using locations, but pretraining the LM over a synthetic dataset automatically derived by us improves results significantly when using location tokens. We thus show that locations allow LMs to ground spatial relations, with our text-only LMs outperforming Vision-and-Language Models and setting the new state-of-the-art for the VSR dataset. Our analysis show that our text-only LMs can generalize beyond the relations seen in the synthetic dataset to some extent, learning also more useful information than that encoded in the spatial rules we used to create the synthetic dataset itself.
HyperFusion: A Hypernetwork Approach to Multimodal Integration of Tabular and Medical Imaging Data for Predictive Modeling
Mar 20, 2024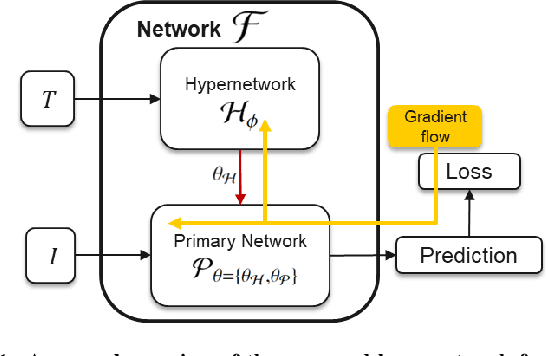
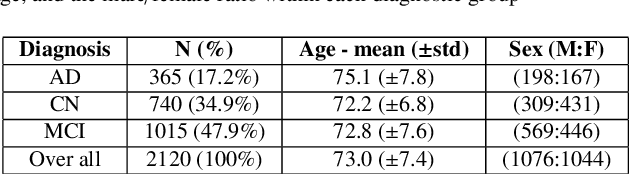
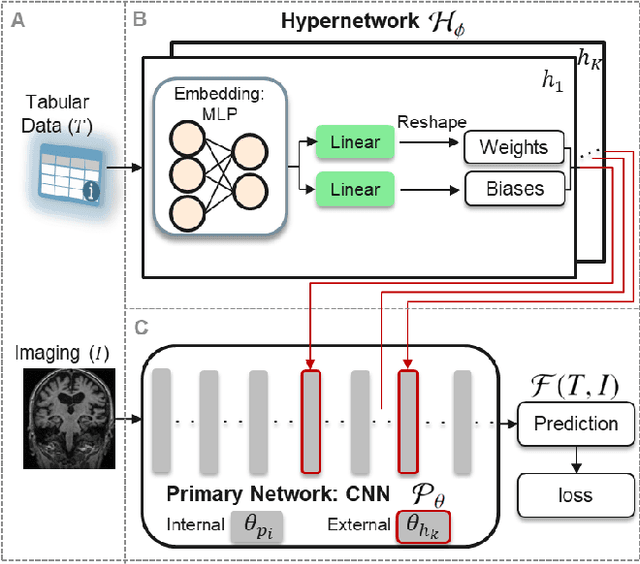
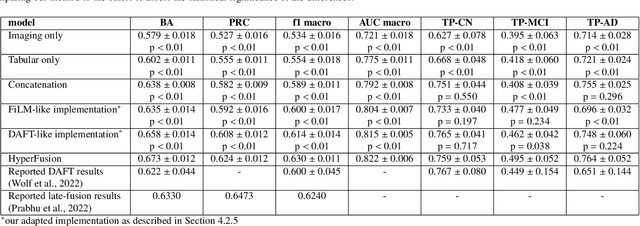
The integration of diverse clinical modalities such as medical imaging and the tabular data obtained by the patients' Electronic Health Records (EHRs) is a crucial aspect of modern healthcare. The integrative analysis of multiple sources can provide a comprehensive understanding of a patient's condition and can enhance diagnoses and treatment decisions. Deep Neural Networks (DNNs) consistently showcase outstanding performance in a wide range of multimodal tasks in the medical domain. However, the complex endeavor of effectively merging medical imaging with clinical, demographic and genetic information represented as numerical tabular data remains a highly active and ongoing research pursuit. We present a novel framework based on hypernetworks to fuse clinical imaging and tabular data by conditioning the image processing on the EHR's values and measurements. This approach aims to leverage the complementary information present in these modalities to enhance the accuracy of various medical applications. We demonstrate the strength and the generality of our method on two different brain Magnetic Resonance Imaging (MRI) analysis tasks, namely, brain age prediction conditioned by subject's sex, and multiclass Alzheimer's Disease (AD) classification conditioned by tabular data. We show that our framework outperforms both single-modality models and state-of-the-art MRI-tabular data fusion methods. The code, enclosed to this manuscript will be made publicly available.
Document Author Classification Using Parsed Language Structure
Mar 20, 2024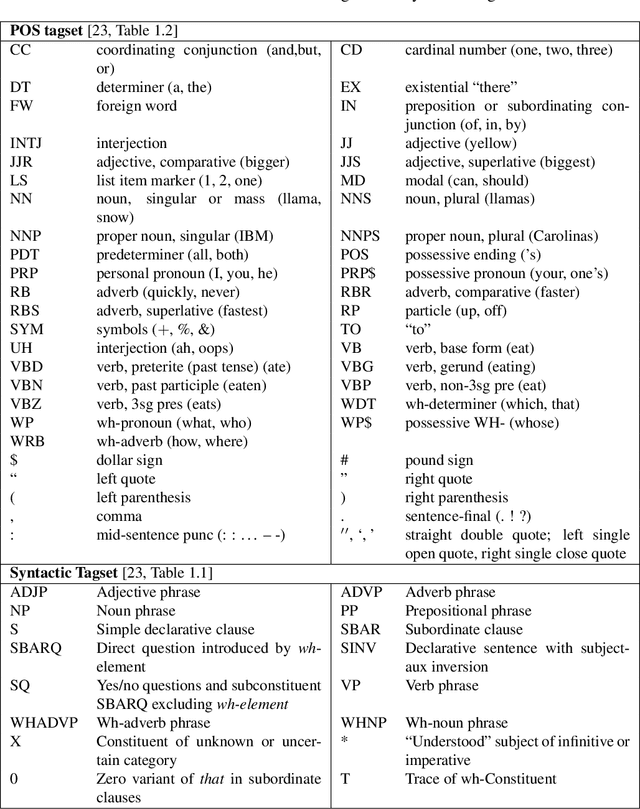
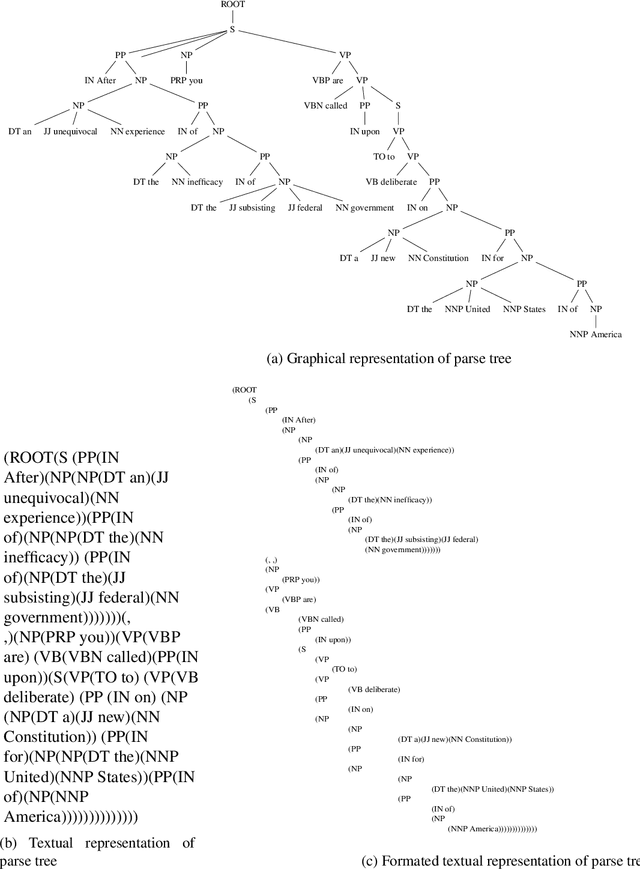
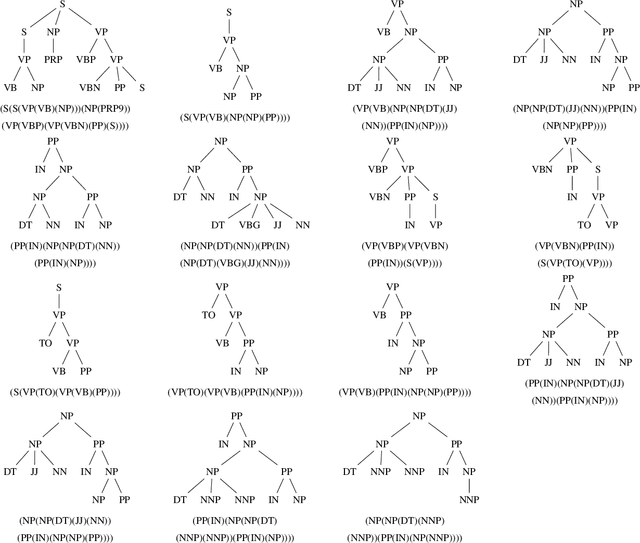
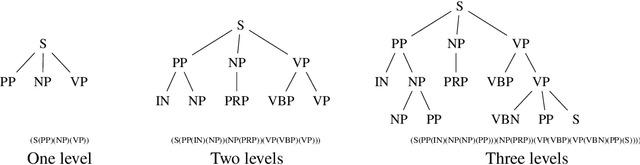
Over the years there has been ongoing interest in detecting authorship of a text based on statistical properties of the text, such as by using occurrence rates of noncontextual words. In previous work, these techniques have been used, for example, to determine authorship of all of \emph{The Federalist Papers}. Such methods may be useful in more modern times to detect fake or AI authorship. Progress in statistical natural language parsers introduces the possibility of using grammatical structure to detect authorship. In this paper we explore a new possibility for detecting authorship using grammatical structural information extracted using a statistical natural language parser. This paper provides a proof of concept, testing author classification based on grammatical structure on a set of "proof texts," The Federalist Papers and Sanditon which have been as test cases in previous authorship detection studies. Several features extracted from the statistical natural language parser were explored: all subtrees of some depth from any level; rooted subtrees of some depth, part of speech, and part of speech by level in the parse tree. It was found to be helpful to project the features into a lower dimensional space. Statistical experiments on these documents demonstrate that information from a statistical parser can, in fact, assist in distinguishing authors.
Dated Data: Tracing Knowledge Cutoffs in Large Language Models
Mar 19, 2024

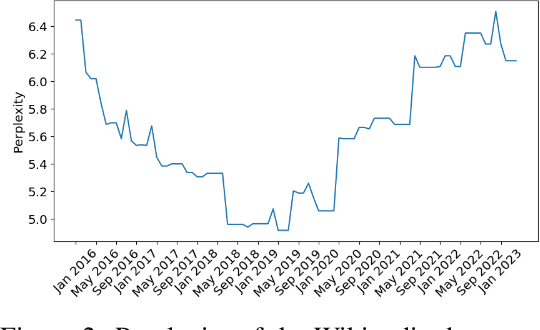

Released Large Language Models (LLMs) are often paired with a claimed knowledge cutoff date, or the dates at which training data was gathered. Such information is crucial for applications where the LLM must provide up to date information. However, this statement only scratches the surface: do all resources in the training data share the same knowledge cutoff date? Does the model's demonstrated knowledge for these subsets closely align to their cutoff dates? In this work, we define the notion of an effective cutoff. This is distinct from the LLM designer reported cutoff and applies separately to sub-resources and topics. We propose a simple approach to estimate effective cutoffs on the resource-level temporal alignment of an LLM by probing across versions of the data. Using this analysis, we find that effective cutoffs often differ from reported cutoffs. To understand the root cause of this observation, we conduct a direct large-scale analysis on open pre-training datasets. Our analysis reveals two reasons for these inconsistencies: (1) temporal biases of CommonCrawl data due to non-trivial amounts of old data in new dumps and (2) complications in LLM deduplication schemes involving semantic duplicates and lexical near-duplicates. Overall, our results show that knowledge cutoffs are not as simple as they have seemed and that care must be taken both by LLM dataset curators as well as practitioners who seek to use information from these models.
SmartRefine: A Scenario-Adaptive Refinement Framework for Efficient Motion Prediction
Mar 19, 2024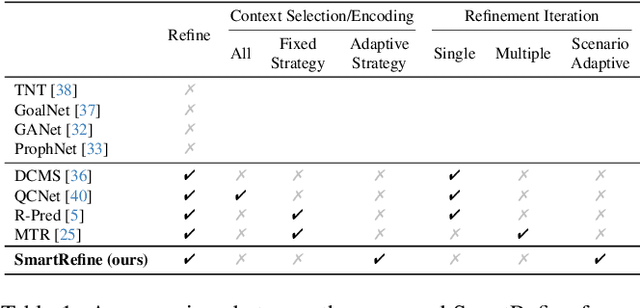
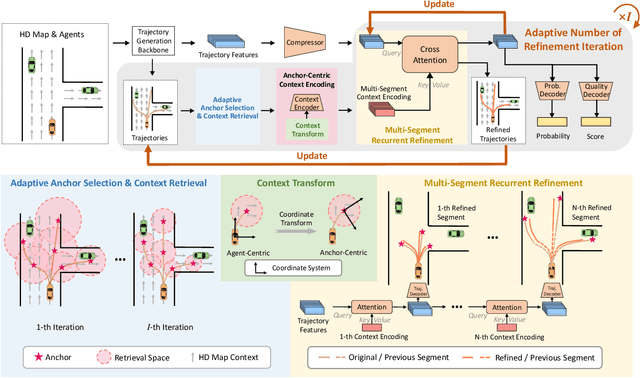
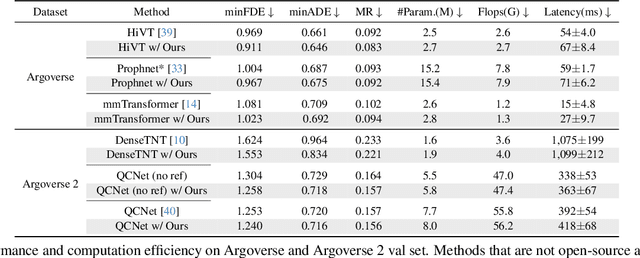
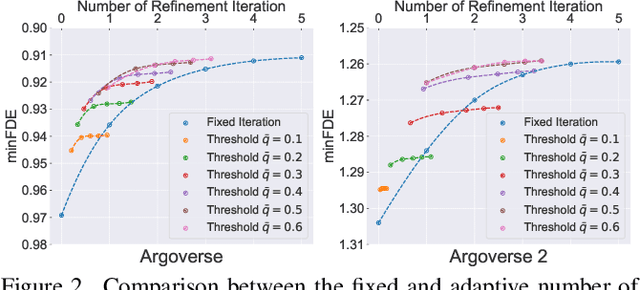
Predicting the future motion of surrounding agents is essential for autonomous vehicles (AVs) to operate safely in dynamic, human-robot-mixed environments. Context information, such as road maps and surrounding agents' states, provides crucial geometric and semantic information for motion behavior prediction. To this end, recent works explore two-stage prediction frameworks where coarse trajectories are first proposed, and then used to select critical context information for trajectory refinement. However, they either incur a large amount of computation or bring limited improvement, if not both. In this paper, we introduce a novel scenario-adaptive refinement strategy, named SmartRefine, to refine prediction with minimal additional computation. Specifically, SmartRefine can comprehensively adapt refinement configurations based on each scenario's properties, and smartly chooses the number of refinement iterations by introducing a quality score to measure the prediction quality and remaining refinement potential of each scenario. SmartRefine is designed as a generic and flexible approach that can be seamlessly integrated into most state-of-the-art motion prediction models. Experiments on Argoverse (1 & 2) show that our method consistently improves the prediction accuracy of multiple state-of-the-art prediction models. Specifically, by adding SmartRefine to QCNet, we outperform all published ensemble-free works on the Argoverse 2 leaderboard (single agent track) at submission. Comprehensive studies are also conducted to ablate design choices and explore the mechanism behind multi-iteration refinement. Codes are available at https://github.com/opendilab/SmartRefine/
Speech-Aware Neural Diarization with Encoder-Decoder Attractor Guided by Attention Constraints
Mar 21, 2024End-to-End Neural Diarization with Encoder-Decoder based Attractor (EEND-EDA) is an end-to-end neural model for automatic speaker segmentation and labeling. It achieves the capability to handle flexible number of speakers by estimating the number of attractors. EEND-EDA, however, struggles to accurately capture local speaker dynamics. This work proposes an auxiliary loss that aims to guide the Transformer encoders at the lower layer of EEND-EDA model to enhance the effect of self-attention modules using speaker activity information. The results evaluated on public dataset Mini LibriSpeech, demonstrates the effectiveness of the work, reducing Diarization Error Rate from 30.95% to 28.17%. We will release the source code on GitHub to allow further research and reproducibility.
Embedded Named Entity Recognition using Probing Classifiers
Mar 18, 2024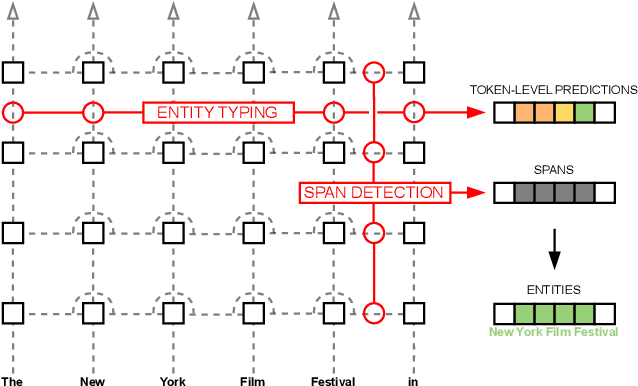
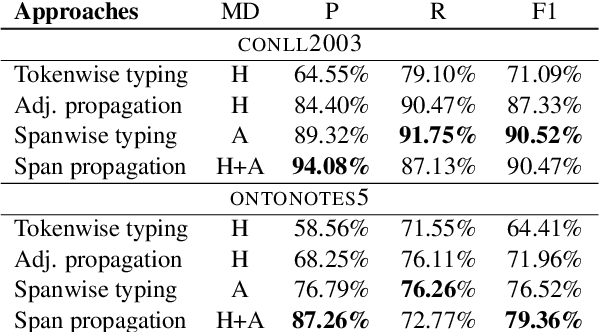
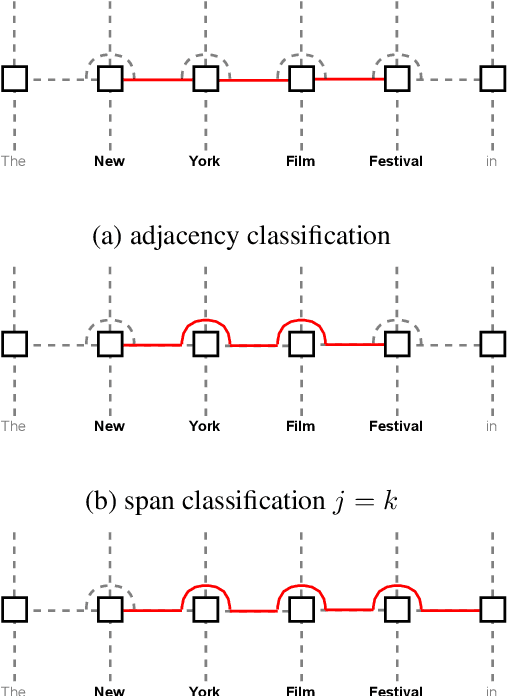
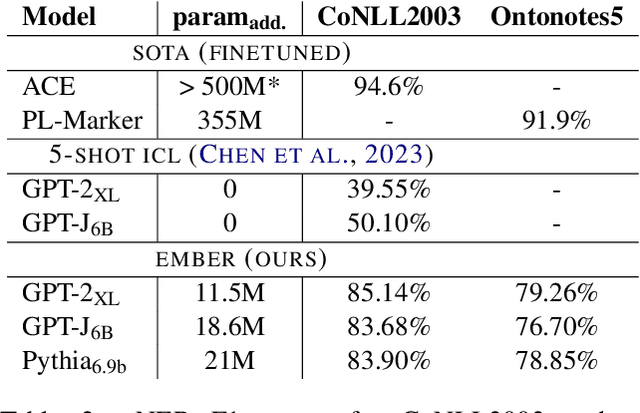
Extracting semantic information from generated text is a useful tool for applications such as automated fact checking or retrieval augmented generation. Currently, this requires either separate models during inference, which increases computational cost, or destructive fine-tuning of the language model. Instead, we propose directly embedding information extraction capabilities into pre-trained language models using probing classifiers, enabling efficient simultaneous text generation and information extraction. For this, we introduce an approach called EMBER and show that it enables named entity recognition in decoder-only language models without fine-tuning them and while incurring minimal additional computational cost at inference time. Specifically, our experiments using GPT-2 show that EMBER maintains high token generation rates during streaming text generation, with only a negligible decrease in speed of around 1% compared to a 43.64% slowdown measured for a baseline using a separate NER model. Code and data are available at https://github.com/nicpopovic/EMBER.
Robust Utility Optimization via a GAN Approach
Mar 22, 2024Robust utility optimization enables an investor to deal with market uncertainty in a structured way, with the goal of maximizing the worst-case outcome. In this work, we propose a generative adversarial network (GAN) approach to (approximately) solve robust utility optimization problems in general and realistic settings. In particular, we model both the investor and the market by neural networks (NN) and train them in a mini-max zero-sum game. This approach is applicable for any continuous utility function and in realistic market settings with trading costs, where only observable information of the market can be used. A large empirical study shows the versatile usability of our method. Whenever an optimal reference strategy is available, our method performs on par with it and in the (many) settings without known optimal strategy, our method outperforms all other reference strategies. Moreover, we can conclude from our study that the trained path-dependent strategies do not outperform Markovian ones. Lastly, we uncover that our generative approach for learning optimal, (non-) robust investments under trading costs generates universally applicable alternatives to well known asymptotic strategies of idealized settings.