 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SCA-PVNet: Self-and-Cross Attention Based Aggregation of Point Cloud and Multi-View for 3D Object Retrieval
Jul 20, 2023
To address 3D object retrieval, substantial efforts have been made to generate highly discriminative descriptors of 3D objects represented by a single modality, e.g., voxels, point clouds or multi-view images. It is promising to leverage the complementary information from multi-modality representations of 3D objects to further improve retrieval performance. However, multi-modality 3D object retrieval is rarely developed and analyzed on large-scale datasets. In this paper, we propose self-and-cross attention based aggregation of point cloud and multi-view images (SCA-PVNet) for 3D object retrieval. With deep features extracted from point clouds and multi-view images, we design two types of feature aggregation modules, namely the In-Modality Aggregation Module (IMAM) and the Cross-Modality Aggregation Module (CMAM), for effective feature fusion. IMAM leverages a self-attention mechanism to aggregate multi-view features while CMAM exploits a cross-attention mechanism to interact point cloud features with multi-view features. The final descriptor of a 3D object for object retrieval can be obtained via concatenating the aggregated features from both modules. Extensive experiments and analysis are conducted on three datasets, ranging from small to large scale, to show the superiority of the proposed SCA-PVNet over the state-of-the-art methods.
Meta-Transformer: A Unified Framework for Multimodal Learning
Jul 20, 2023
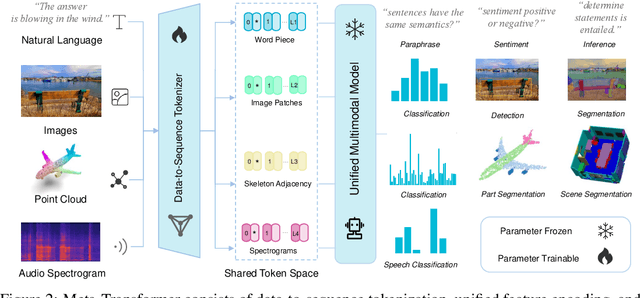
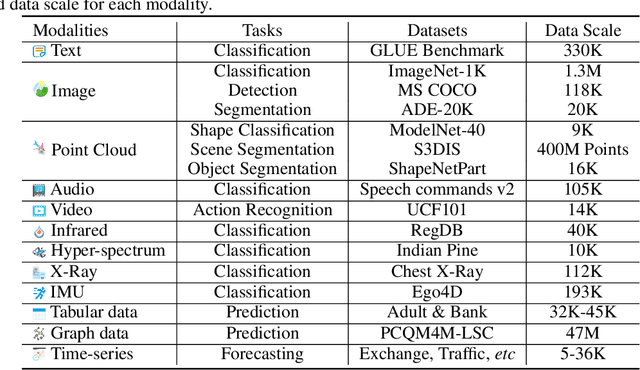
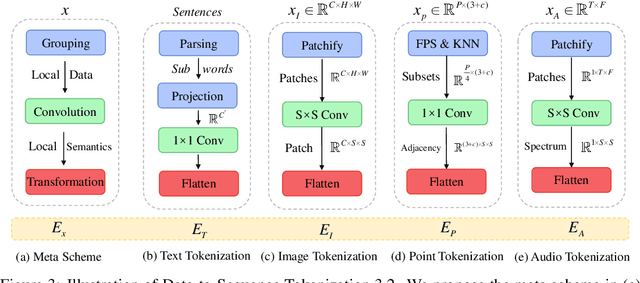
Multimodal learning aims to build models that can process and relate information from multiple modalities. Despite years of development in this field, it still remains challenging to design a unified network for processing various modalities ($\textit{e.g.}$ natural language, 2D images, 3D point clouds, audio, video, time series, tabular data) due to the inherent gaps among them. In this work, we propose a framework, named Meta-Transformer, that leverages a $\textbf{frozen}$ encoder to perform multimodal perception without any paired multimodal training data. In Meta-Transformer, the raw input data from various modalities are mapped into a shared token space, allowing a subsequent encoder with frozen parameters to extract high-level semantic features of the input data. Composed of three main components: a unified data tokenizer, a modality-shared encoder, and task-specific heads for downstream tasks, Meta-Transformer is the first framework to perform unified learning across 12 modalities with unpaired data. Experiments on different benchmarks reveal that Meta-Transformer can handle a wide range of tasks including fundamental perception (text, image, point cloud, audio, video), practical application (X-Ray, infrared, hyperspectral, and IMU), and data mining (graph, tabular, and time-series). Meta-Transformer indicates a promising future for developing unified multimodal intelligence with transformers. Code will be available at https://github.com/invictus717/MetaTransformer
Underwater 3D positioning on smart devices
Jul 20, 2023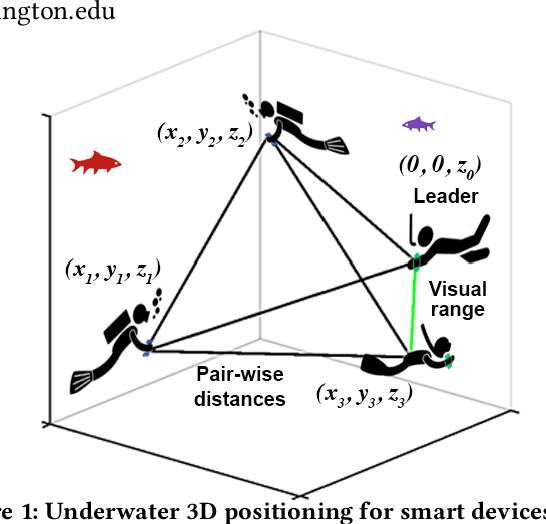

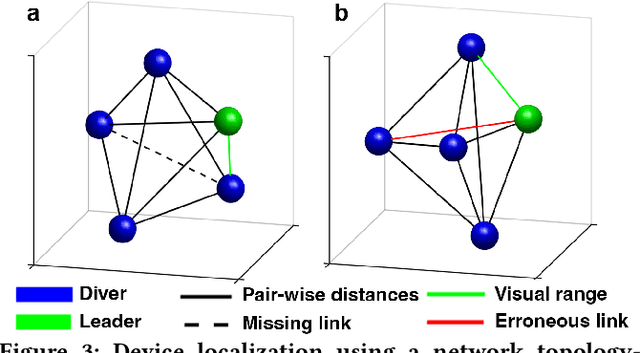
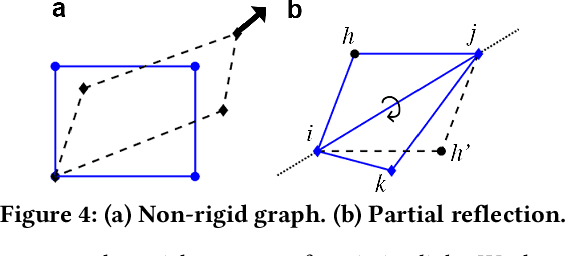
The emergence of water-proof mobile and wearable devices (e.g., Garmin Descent and Apple Watch Ultra) designed for underwater activities like professional scuba diving, opens up opportunities for underwater networking and localization capabilities on these devices. Here, we present the first underwater acoustic positioning system for smart devices. Unlike conventional systems that use floating buoys as anchors at known locations, we design a system where a dive leader can compute the relative positions of all other divers, without any external infrastructure. Our intuition is that in a well-connected network of devices, if we compute the pairwise distances, we can determine the shape of the network topology. By incorporating orientation information about a single diver who is in the visual range of the leader device, we can then estimate the positions of all the remaining divers, even if they are not within sight. We address various practical problems including detecting erroneous distance estimates, addressing rotational and flipping ambiguities as well as designing a distributed timestamp protocol that scales linearly with the number of devices. Our evaluations show that our distributed system running on underwater deployments of 4-5 commodity smart devices can perform pairwise ranging and localization with median errors of 0.5-0.9 m and 0.9-1.6 m
Vesper: A Compact and Effective Pretrained Model for Speech Emotion Recognition
Jul 20, 2023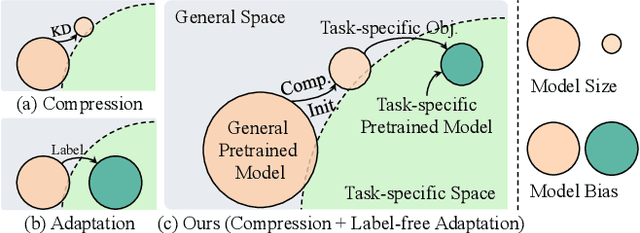
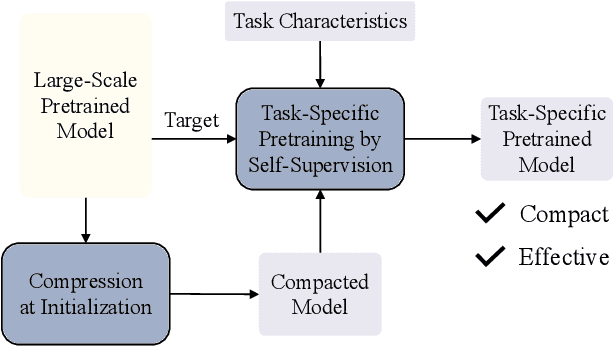
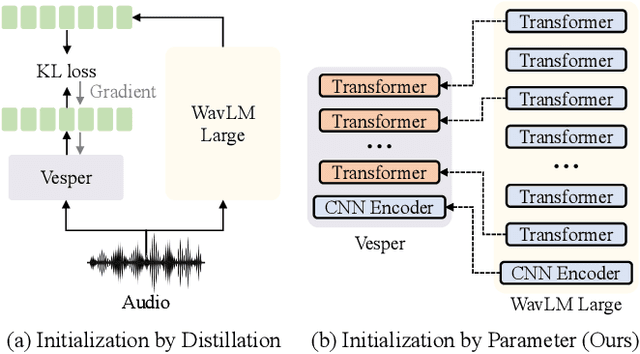
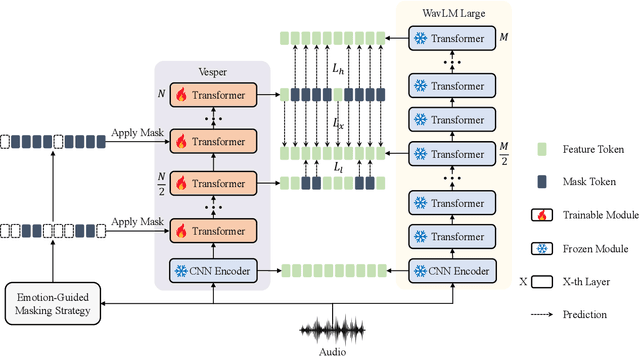
This paper presents a paradigm that adapts general large-scale pretrained models (PTMs) to speech emotion recognition task. Although PTMs shed new light on artificial general intelligence, they are constructed with general tasks in mind, and thus, their efficacy for specific tasks can be further improved. Additionally, employing PTMs in practical applications can be challenging due to their considerable size. Above limitations spawn another research direction, namely, optimizing large-scale PTMs for specific tasks to generate task-specific PTMs that are both compact and effective. In this paper, we focus on the speech emotion recognition task and propose an improved emotion-specific pretrained encoder called Vesper. Vesper is pretrained on a speech dataset based on WavLM and takes into account emotional characteristics. To enhance sensitivity to emotional information, Vesper employs an emotion-guided masking strategy to identify the regions that need masking. Subsequently, Vesper employs hierarchical and cross-layer self-supervision to improve its ability to capture acoustic and semantic representations, both of which are crucial for emotion recognition. Experimental results on the IEMOCAP, MELD, and CREMA-D datasets demonstrate that Vesper with 4 layers outperforms WavLM Base with 12 layers, and the performance of Vesper with 12 layers surpasses that of WavLM Large with 24 layers.
Predicting human motion intention for pHRI assistive control
Jul 20, 2023This work addresses human intention identification during physical Human-Robot Interaction (pHRI) tasks to include this information in an assistive controller. To this purpose, human intention is defined as the desired trajectory that the human wants to follow over a finite rolling prediction horizon so that the robot can assist in pursuing it. This work investigates a Recurrent Neural Network (RNN), specifically, Long-Short Term Memory (LSTM) cascaded with a Fully Connected layer. In particular, we propose an iterative training procedure to adapt the model. Such an iterative procedure is powerful in reducing the prediction error. Still, it has the drawback that it is time-consuming and does not generalize to different users or different co-manipulated objects. To overcome this issue, Transfer Learning (TL) adapts the pre-trained model to new trajectories, users, and co-manipulated objects by freezing the LSTM layer and fine-tuning the last FC layer, which makes the procedure faster. Experiments show that the iterative procedure adapts the model and reduces prediction error. Experiments also show that TL adapts to different users and to the co-manipulation of a large object. Finally, to check the utility of adopting the proposed method, we compare the proposed controller enhanced by the intention prediction with the other two standard controllers of pHRI.
RCVaR: an Economic Approach to Estimate Cyberattacks Costs using Data from Industry Reports
Jul 20, 2023Digitization increases business opportunities and the risk of companies being victims of devastating cyberattacks. Therefore, managing risk exposure and cybersecurity strategies is essential for digitized companies that want to survive in competitive markets. However, understanding company-specific risks and quantifying their associated costs is not trivial. Current approaches fail to provide individualized and quantitative monetary estimations of cybersecurity impacts. Due to limited resources and technical expertise, SMEs and even large companies are affected and struggle to quantify their cyberattack exposure. Therefore, novel approaches must be placed to support the understanding of the financial loss due to cyberattacks. This article introduces the Real Cyber Value at Risk (RCVaR), an economical approach for estimating cybersecurity costs using real-world information from public cybersecurity reports. RCVaR identifies the most significant cyber risk factors from various sources and combines their quantitative results to estimate specific cyberattacks costs for companies. Furthermore, RCVaR extends current methods to achieve cost and risk estimations based on historical real-world data instead of only probability-based simulations. The evaluation of the approach on unseen data shows the accuracy and efficiency of the RCVaR in predicting and managing cyber risks. Thus, it shows that the RCVaR is a valuable addition to cybersecurity planning and risk management processes.
Towards General Game Representations: Decomposing Games Pixels into Content and Style
Jul 20, 2023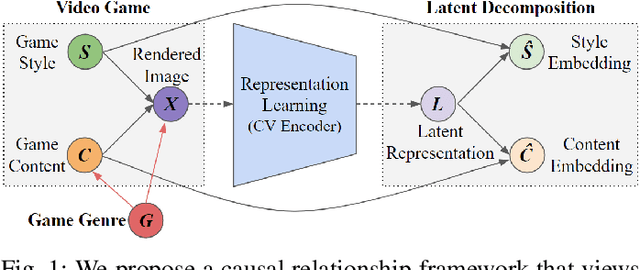
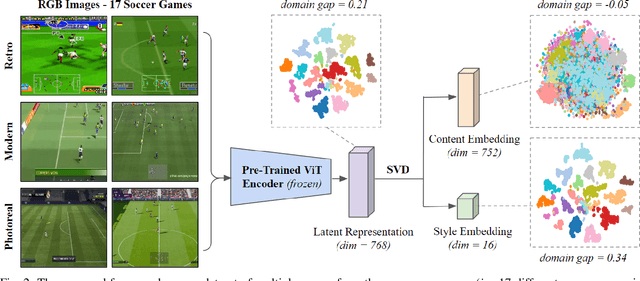
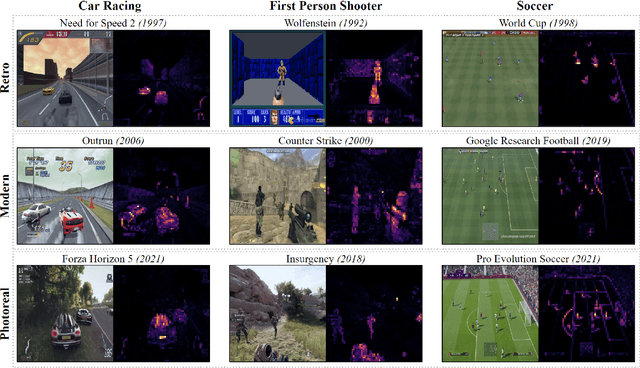
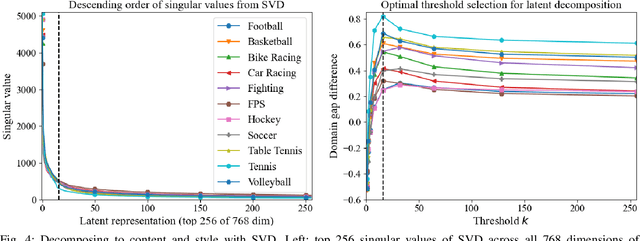
On-screen game footage contains rich contextual information that players process when playing and experiencing a game. Learning pixel representations of games can benefit artificial intelligence across several downstream tasks including game-playing agents, procedural content generation, and player modelling. The generalizability of these methods, however, remains a challenge, as learned representations should ideally be shared across games with similar game mechanics. This could allow, for instance, game-playing agents trained on one game to perform well in similar games with no re-training. This paper explores how generalizable pre-trained computer vision encoders can be for such tasks, by decomposing the latent space into content embeddings and style embeddings. The goal is to minimize the domain gap between games of the same genre when it comes to game content critical for downstream tasks, and ignore differences in graphical style. We employ a pre-trained Vision Transformer encoder and a decomposition technique based on game genres to obtain separate content and style embeddings. Our findings show that the decomposed embeddings achieve style invariance across multiple games while still maintaining strong content extraction capabilities. We argue that the proposed decomposition of content and style offers better generalization capacities across game environments independently of the downstream task.
Transfer Learning and Bias Correction with Pre-trained Audio Embeddings
Jul 20, 2023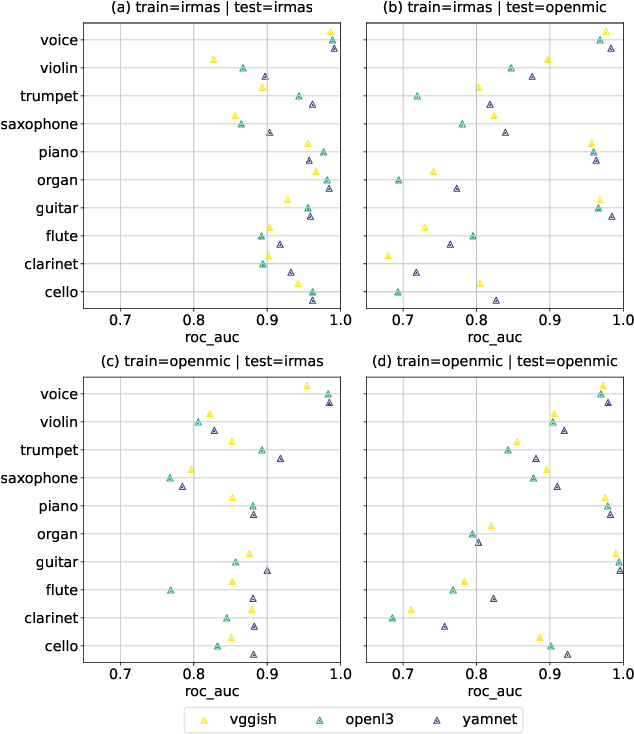
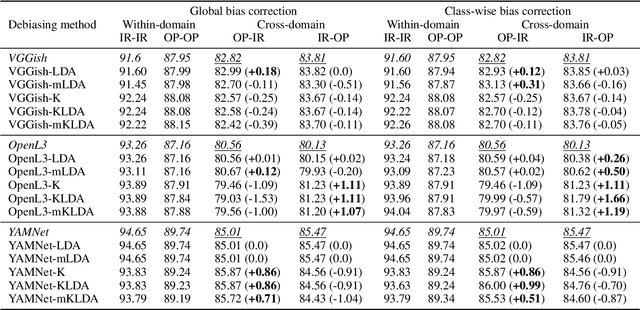
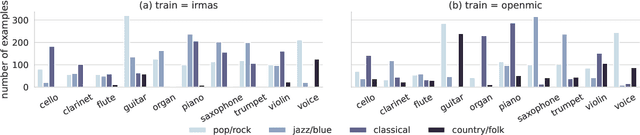
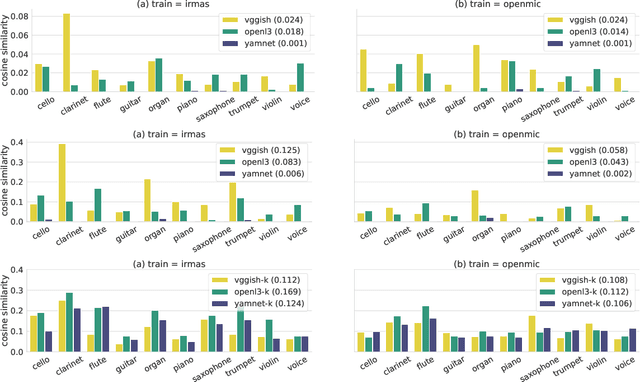
Deep neural network models have become the dominant approach to a large variety of tasks within music information retrieval (MIR). These models generally require large amounts of (annotated) training data to achieve high accuracy. Because not all applications in MIR have sufficient quantities of training data, it is becoming increasingly common to transfer models across domains. This approach allows representations derived for one task to be applied to another, and can result in high accuracy with less stringent training data requirements for the downstream task. However, the properties of pre-trained audio embeddings are not fully understood. Specifically, and unlike traditionally engineered features, the representations extracted from pre-trained deep networks may embed and propagate biases from the model's training regime. This work investigates the phenomenon of bias propagation in the context of pre-trained audio representations for the task of instrument recognition. We first demonstrate that three different pre-trained representations (VGGish, OpenL3, and YAMNet) exhibit comparable performance when constrained to a single dataset, but differ in their ability to generalize across datasets (OpenMIC and IRMAS). We then investigate dataset identity and genre distribution as potential sources of bias. Finally, we propose and evaluate post-processing countermeasures to mitigate the effects of bias, and improve generalization across datasets.
Decoding the Enigma: Benchmarking Humans and AIs on the Many Facets of Working Memory
Jul 20, 2023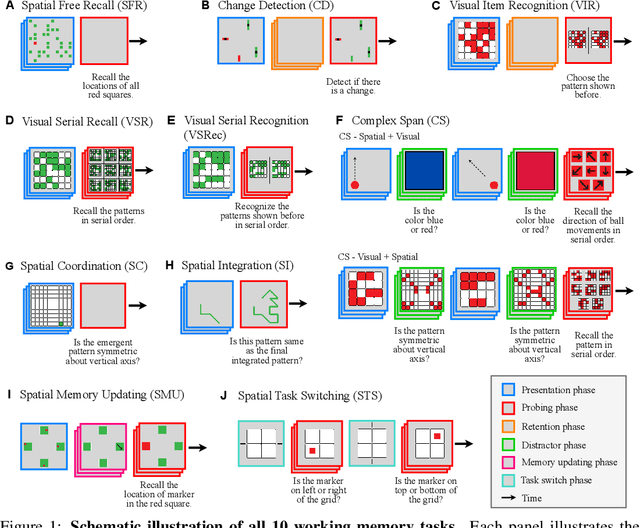
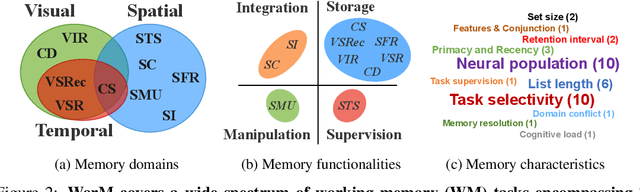
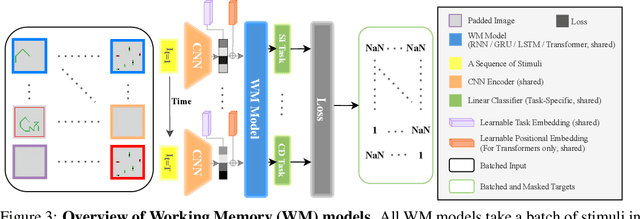
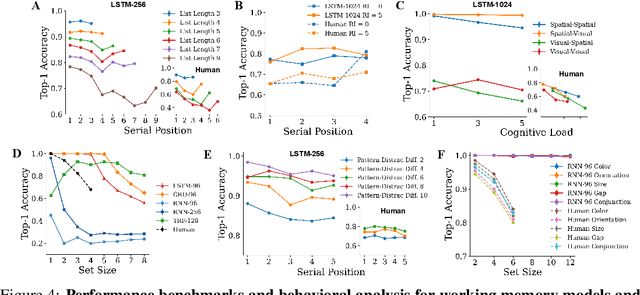
Working memory (WM), a fundamental cognitive process facilitating the temporary storage, integration, manipulation, and retrieval of information, plays a vital role in reasoning and decision-making tasks. Robust benchmark datasets that capture the multifaceted nature of WM are crucial for the effective development and evaluation of AI WM models. Here, we introduce a comprehensive Working Memory (WorM) benchmark dataset for this purpose. WorM comprises 10 tasks and a total of 1 million trials, assessing 4 functionalities, 3 domains, and 11 behavioral and neural characteristics of WM. We jointly trained and tested state-of-the-art recurrent neural networks and transformers on all these tasks. We also include human behavioral benchmarks as an upper bound for comparison. Our results suggest that AI models replicate some characteristics of WM in the brain, most notably primacy and recency effects, and neural clusters and correlates specialized for different domains and functionalities of WM. In the experiments, we also reveal some limitations in existing models to approximate human behavior. This dataset serves as a valuable resource for communities in cognitive psychology, neuroscience, and AI, offering a standardized framework to compare and enhance WM models, investigate WM's neural underpinnings, and develop WM models with human-like capabilities. Our source code and data are available at https://github.com/ZhangLab-DeepNeuroCogLab/WorM.
Neuron Sensitivity Guided Test Case Selection for Deep Learning Testing
Jul 20, 2023Deep Neural Networks~(DNNs) have been widely deployed in software to address various tasks~(e.g., autonomous driving, medical diagnosis). However, they could also produce incorrect behaviors that result in financial losses and even threaten human safety. To reveal the incorrect behaviors in DNN and repair them, DNN developers often collect rich unlabeled datasets from the natural world and label them to test the DNN models. However, properly labeling a large number of unlabeled datasets is a highly expensive and time-consuming task. To address the above-mentioned problem, we propose NSS, Neuron Sensitivity guided test case Selection, which can reduce the labeling time by selecting valuable test cases from unlabeled datasets. NSS leverages the internal neuron's information induced by test cases to select valuable test cases, which have high confidence in causing the model to behave incorrectly. We evaluate NSS with four widely used datasets and four well-designed DNN models compared to SOTA baseline methods. The results show that NSS performs well in assessing the test cases' probability of fault triggering and model improvement capabilities. Specifically, compared with baseline approaches, NSS obtains a higher fault detection rate~(e.g., when selecting 5\% test case from the unlabeled dataset in MNIST \& LeNet1 experiment, NSS can obtain 81.8\% fault detection rate, 20\% higher than baselines).