 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The IMPTC Dataset: An Infrastructural Multi-Person Trajectory and Context Dataset
Jul 12, 2023
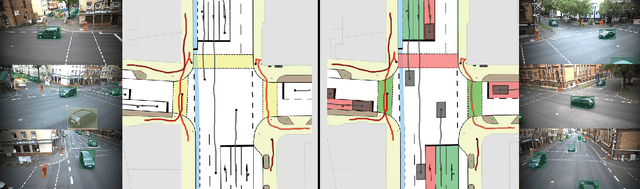
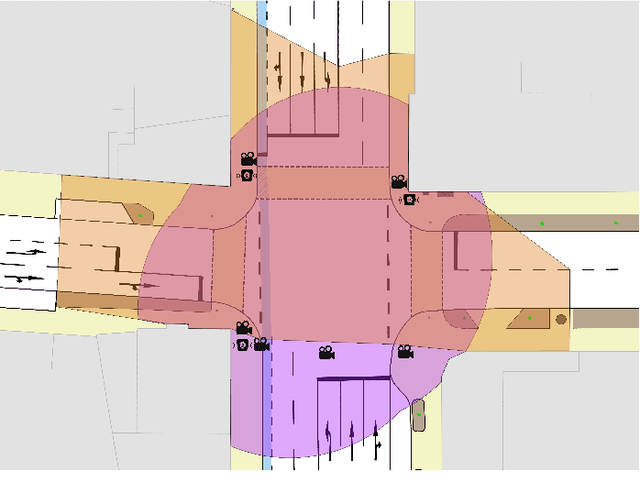

Inner-city intersections are among the most critical traffic areas for injury and fatal accidents. Automated vehicles struggle with the complex and hectic everyday life within those areas. Sensor-equipped smart infrastructures, which can cooperate with vehicles, can benefit automated traffic by extending the perception capabilities of drivers and vehicle perception systems. Additionally, they offer the opportunity to gather reproducible and precise data of a holistic scene understanding, including context information as a basis for training algorithms for various applications in automated traffic. Therefore, we introduce the Infrastructural Multi-Person Trajectory and Context Dataset (IMPTC). We use an intelligent public inner-city intersection in Germany with visual sensor technology. A multi-view camera and LiDAR system perceives traffic situations and road users' behavior. Additional sensors monitor contextual information like weather, lighting, and traffic light signal status. The data acquisition system focuses on Vulnerable Road Users (VRUs) and multi-agent interaction. The resulting dataset consists of eight hours of measurement data. It contains over 2,500 VRU trajectories, including pedestrians, cyclists, e-scooter riders, strollers, and wheelchair users, and over 20,000 vehicle trajectories at different day times, weather conditions, and seasons. In addition, to enable the entire stack of research capabilities, the dataset includes all data, starting from the sensor-, calibration- and detection data until trajectory and context data. The dataset is continuously expanded and is available online for non-commercial research at https://github.com/kav-institute/imptc-dataset.
Cascade-DETR: Delving into High-Quality Universal Object Detection
Jul 20, 2023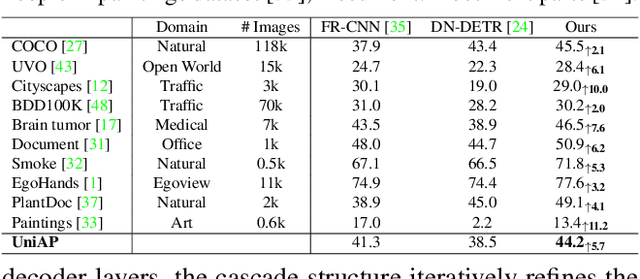
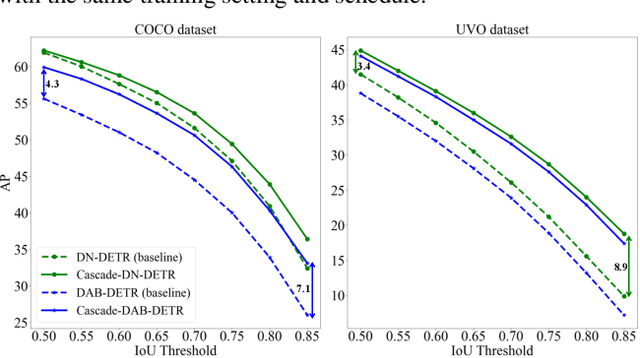

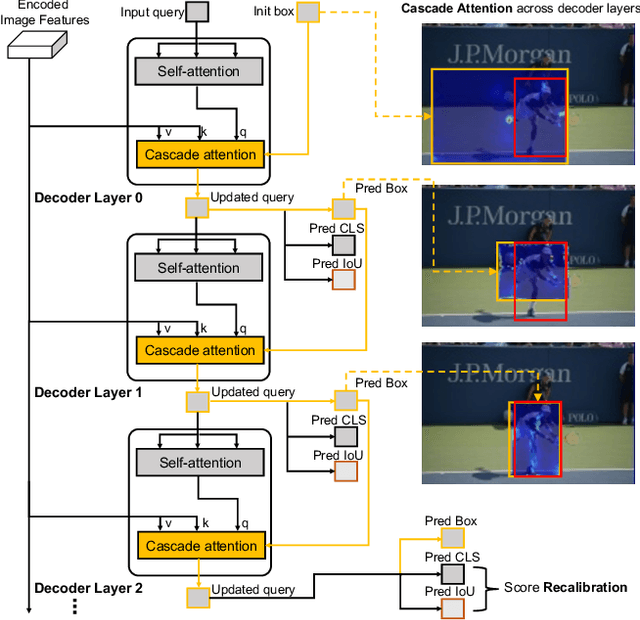
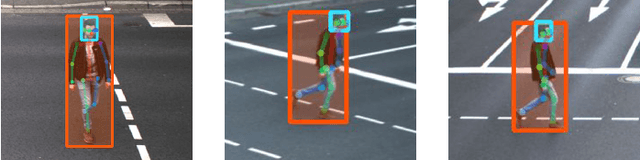
Object localization in general environments is a fundamental part of vision systems. While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains. Moreover, these methods still struggle to very accurately estimate the object bounding boxes in complex environments. We introduce Cascade-DETR for high-quality universal object detection. We jointly tackle the generalization to diverse domains and localization accuracy by proposing the Cascade Attention layer, which explicitly integrates object-centric information into the detection decoder by limiting the attention to the previous box prediction. To further enhance accuracy, we also revisit the scoring of queries. Instead of relying on classification scores, we predict the expected IoU of the query, leading to substantially more well-calibrated confidences. Lastly, we introduce a universal object detection benchmark, UDB10, that contains 10 datasets from diverse domains. While also advancing the state-of-the-art on COCO, Cascade-DETR substantially improves DETR-based detectors on all datasets in UDB10, even by over 10 mAP in some cases. The improvements under stringent quality requirements are even more pronounced. Our code and models will be released at https://github.com/SysCV/cascade-detr.
Reference-based Painterly Inpainting via Diffusion: Crossing the Wild Reference Domain Gap
Jul 20, 2023
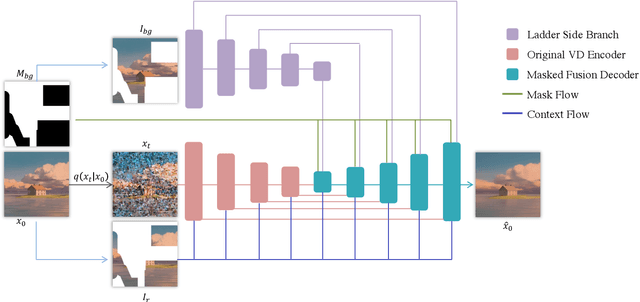

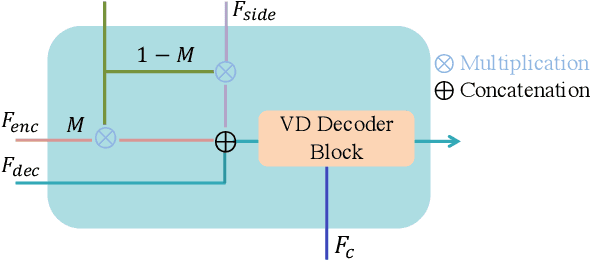
Have you ever imagined how it would look if we placed new objects into paintings? For example, what would it look like if we placed a basketball into Claude Monet's ``Water Lilies, Evening Effect''? We propose Reference-based Painterly Inpainting, a novel task that crosses the wild reference domain gap and implants novel objects into artworks. Although previous works have examined reference-based inpainting, they are not designed for large domain discrepancies between the target and the reference, such as inpainting an artistic image using a photorealistic reference. This paper proposes a novel diffusion framework, dubbed RefPaint, to ``inpaint more wildly'' by taking such references with large domain gaps. Built with an image-conditioned diffusion model, we introduce a ladder-side branch and a masked fusion mechanism to work with the inpainting mask. By decomposing the CLIP image embeddings at inference time, one can manipulate the strength of semantic and style information with ease. Experiments demonstrate that our proposed RefPaint framework produces significantly better results than existing methods. Our method enables creative painterly image inpainting with reference objects that would otherwise be difficult to achieve. Project page: https://vita-group.github.io/RefPaint/
General Image-to-Image Translation with One-Shot Image Guidance
Jul 20, 2023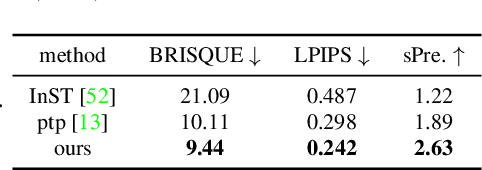
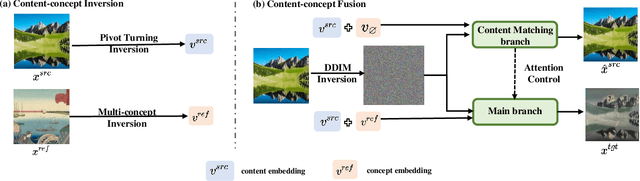
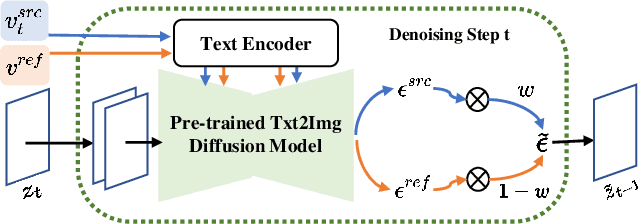
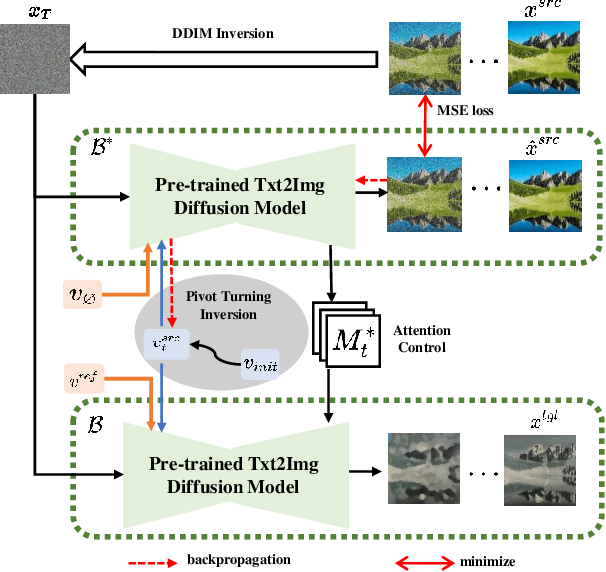
Large-scale text-to-image models pre-trained on massive text-image pairs show excellent performance in image synthesis recently. However, image can provide more intuitive visual concepts than plain text. People may ask: how can we integrate the desired visual concept into an existing image, such as our portrait? Current methods are inadequate in meeting this demand as they lack the ability to preserve content or translate visual concepts effectively. Inspired by this, we propose a novel framework named visual concept translator (VCT) with the ability to preserve content in the source image and translate the visual concepts guided by a single reference image. The proposed VCT contains a content-concept inversion (CCI) process to extract contents and concepts, and a content-concept fusion (CCF) process to gather the extracted information to obtain the target image. Given only one reference image, the proposed VCT can complete a wide range of general image-to-image translation tasks with excellent results. Extensive experiments are conducted to prove the superiority and effectiveness of the proposed methods. Codes are available at https://github.com/CrystalNeuro/visual-concept-translator.
Unveiling Emotions from EEG: A GRU-Based Approach
Jul 20, 2023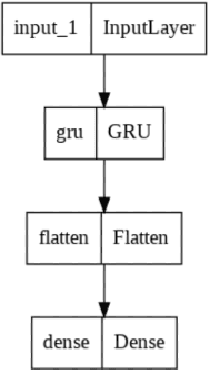
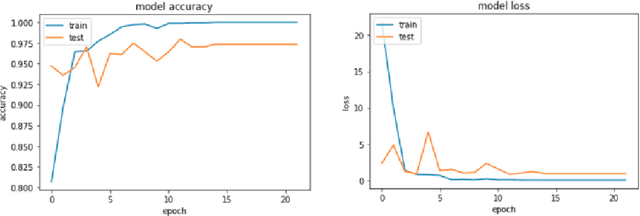
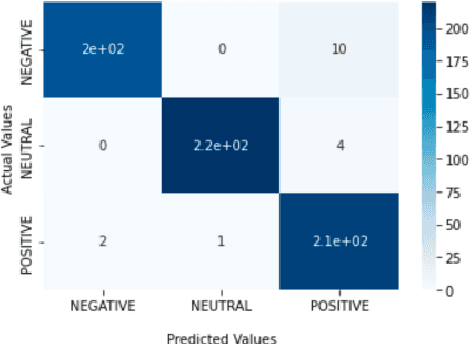
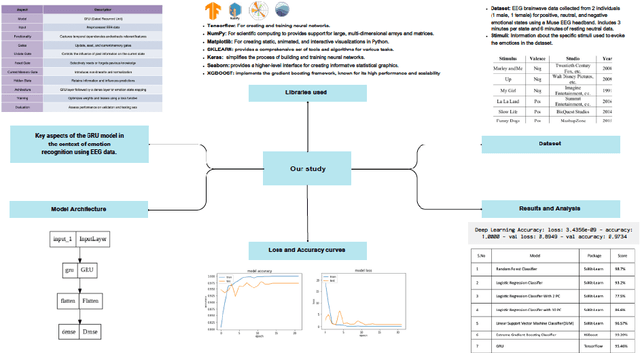
One of the most important study areas in affective computing is emotion identification using EEG data. In this study, the Gated Recurrent Unit (GRU) algorithm, which is a type of Recurrent Neural Networks (RNNs), is tested to see if it can use EEG signals to predict emotional states. Our publicly accessible dataset consists of resting neutral data as well as EEG recordings from people who were exposed to stimuli evoking happy, neutral, and negative emotions. For the best feature extraction, we pre-process the EEG data using artifact removal, bandpass filters, and normalization methods. With 100% accuracy on the validation set, our model produced outstanding results by utilizing the GRU's capacity to capture temporal dependencies. When compared to other machine learning techniques, our GRU model's Extreme Gradient Boosting Classifier had the highest accuracy. Our investigation of the confusion matrix revealed insightful information about the performance of the model, enabling precise emotion classification. This study emphasizes the potential of deep learning models like GRUs for emotion recognition and advances in affective computing. Our findings open up new possibilities for interacting with computers and comprehending how emotions are expressed through brainwave activity.
An Information Extraction Study: Take In Mind the Tokenization!
Mar 27, 2023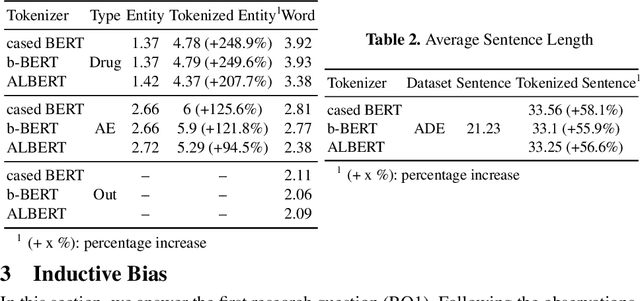
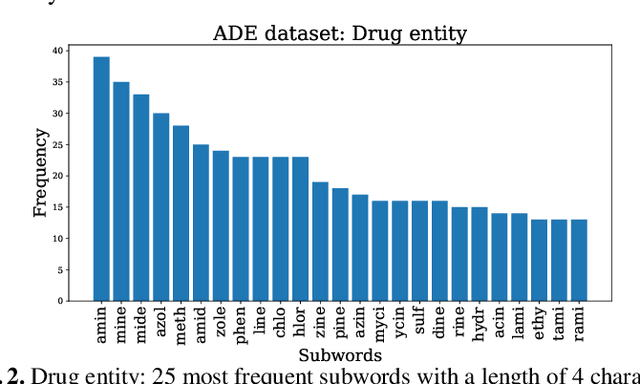
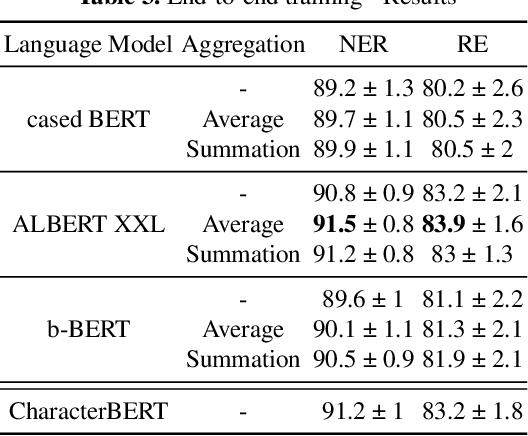
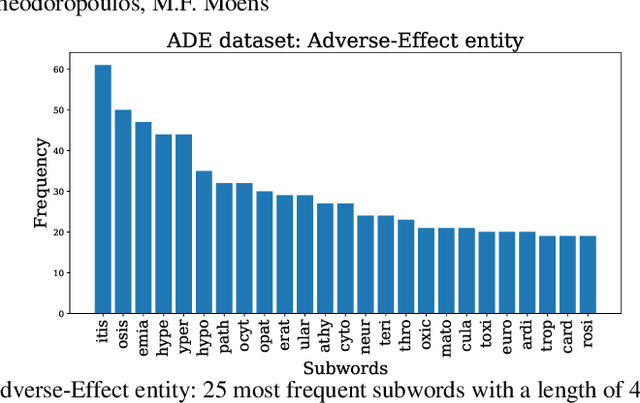
Current research on the advantages and trade-offs of using characters, instead of tokenized text, as input for deep learning models, has evolved substantially. New token-free models remove the traditional tokenization step; however, their efficiency remains unclear. Moreover, the effect of tokenization is relatively unexplored in sequence tagging tasks. To this end, we investigate the impact of tokenization when extracting information from documents and present a comparative study and analysis of subword-based and character-based models. Specifically, we study Information Extraction (IE) from biomedical texts. The main outcome is twofold: tokenization patterns can introduce inductive bias that results in state-of-the-art performance, and the character-based models produce promising results; thus, transitioning to token-free IE models is feasible.
Learning Variational Neighbor Labels for Test-Time Domain Generalization
Jul 08, 2023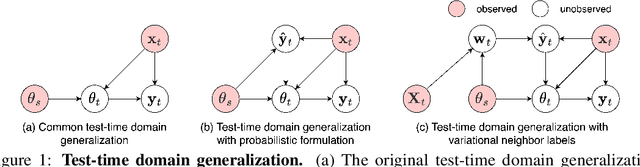
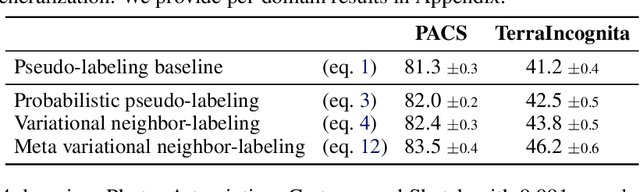
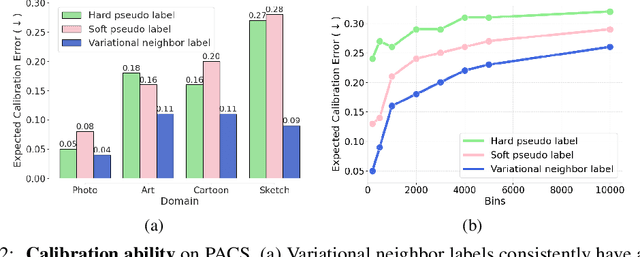
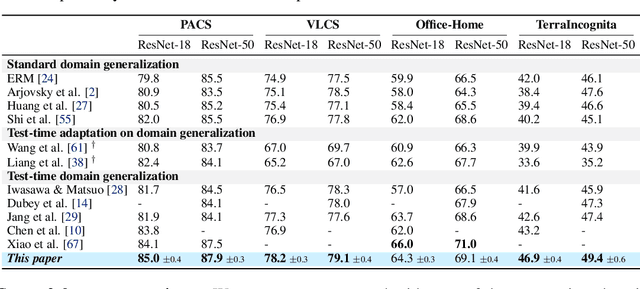
This paper strives for domain generalization, where models are trained exclusively on source domains before being deployed at unseen target domains. We follow the strict separation of source training and target testing but exploit the value of the unlabeled target data itself during inference. We make three contributions. First, we propose probabilistic pseudo-labeling of target samples to generalize the source-trained model to the target domain at test time. We formulate the generalization at test time as a variational inference problem by modeling pseudo labels as distributions to consider the uncertainty during generalization and alleviate the misleading signal of inaccurate pseudo labels. Second, we learn variational neighbor labels that incorporate the information of neighboring target samples to generate more robust pseudo labels. Third, to learn the ability to incorporate more representative target information and generate more precise and robust variational neighbor labels, we introduce a meta-generalization stage during training to simulate the generalization procedure. Experiments on six widely-used datasets demonstrate the benefits, abilities, and effectiveness of our proposal.
Enhancing LLM with Evolutionary Fine Tuning for News Summary Generation
Jul 08, 2023News summary generation is an important task in the field of intelligence analysis, which can provide accurate and comprehensive information to help people better understand and respond to complex real-world events. However, traditional news summary generation methods face some challenges, which are limited by the model itself and the amount of training data, as well as the influence of text noise, making it difficult to generate reliable information accurately. In this paper, we propose a new paradigm for news summary generation using LLM with powerful natural language understanding and generative capabilities. We use LLM to extract multiple structured event patterns from the events contained in news paragraphs, evolve the event pattern population with genetic algorithm, and select the most adaptive event pattern to input into the LLM to generate news summaries. A News Summary Generator (NSG) is designed to select and evolve the event pattern populations and generate news summaries. The experimental results show that the news summary generator is able to generate accurate and reliable news summaries with some generalization ability.
Reading Between the Lanes: Text VideoQA on the Road
Jul 08, 2023

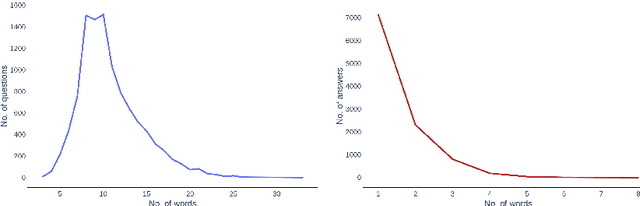
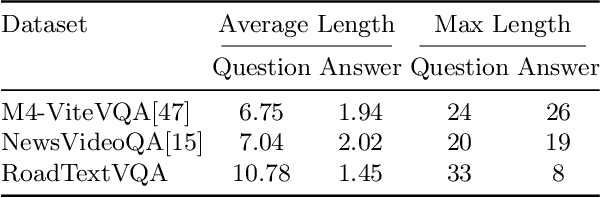
Text and signs around roads provide crucial information for drivers, vital for safe navigation and situational awareness. Scene text recognition in motion is a challenging problem, while textual cues typically appear for a short time span, and early detection at a distance is necessary. Systems that exploit such information to assist the driver should not only extract and incorporate visual and textual cues from the video stream but also reason over time. To address this issue, we introduce RoadTextVQA, a new dataset for the task of video question answering (VideoQA) in the context of driver assistance. RoadTextVQA consists of $3,222$ driving videos collected from multiple countries, annotated with $10,500$ questions, all based on text or road signs present in the driving videos. We assess the performance of state-of-the-art video question answering models on our RoadTextVQA dataset, highlighting the significant potential for improvement in this domain and the usefulness of the dataset in advancing research on in-vehicle support systems and text-aware multimodal question answering. The dataset is available at http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtextvqa
K-Space-Aware Cross-Modality Score for Synthesized Neuroimage Quality Assessment
Jul 10, 2023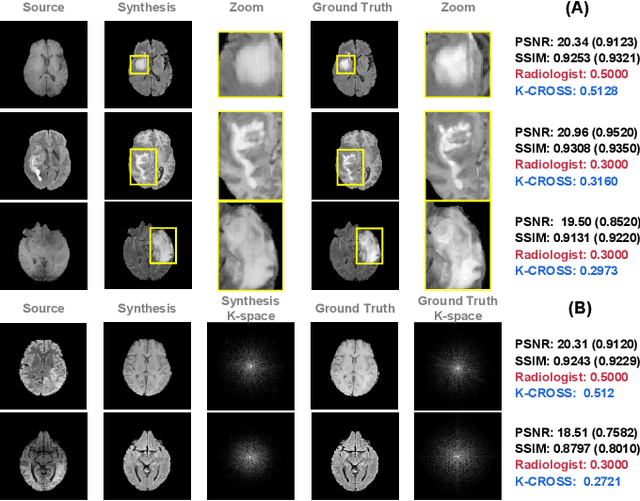
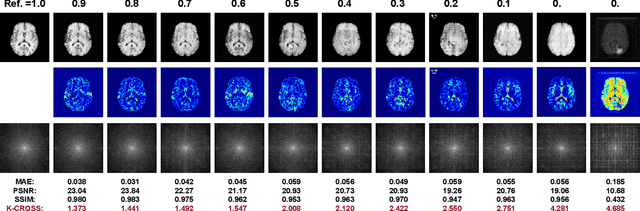
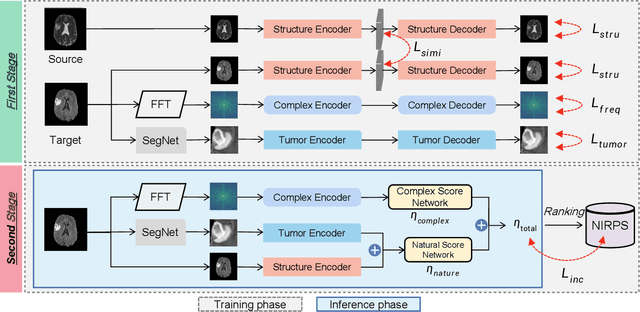
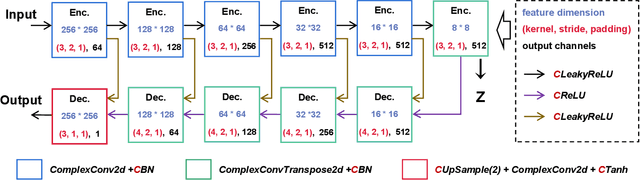
The problem of how to assess cross-modality medical image synthesis has been largely unexplored. The most used measures like PSNR and SSIM focus on analyzing the structural features but neglect the crucial lesion location and fundamental k-space speciality of medical images. To overcome this problem, we propose a new metric K-CROSS to spur progress on this challenging problem. Specifically, K-CROSS uses a pre-trained multi-modality segmentation network to predict the lesion location, together with a tumor encoder for representing features, such as texture details and brightness intensities. To further reflect the frequency-specific information from the magnetic resonance imaging principles, both k-space features and vision features are obtained and employed in our comprehensive encoders with a frequency reconstruction penalty. The structure-shared encoders are designed and constrained with a similarity loss to capture the intrinsic common structural information for both modalities. As a consequence, the features learned from lesion regions, k-space, and anatomical structures are all captured, which serve as our quality evaluators. We evaluate the performance by constructing a large-scale cross-modality neuroimaging perceptual similarity (NIRPS) dataset with 6,000 radiologist judgments. Extensive experiments demonstrate that the proposed method outperforms other metrics, especially in comparison with the radiologists on NIRPS.