 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduction of Supervision for Biomedical Knowledge Discovery
Apr 13, 2025Knowledge discovery is hindered by the increasing volume of publications and the scarcity of extensive annotated data. To tackle the challenge of information overload, it is essential to employ automated methods for knowledge extraction and processing. Finding the right balance between the level of supervision and the effectiveness of models poses a significant challenge. While supervised techniques generally result in better performance, they have the major drawback of demanding labeled data. This requirement is labor-intensive and time-consuming and hinders scalability when exploring new domains. In this context, our study addresses the challenge of identifying semantic relationships between biomedical entities (e.g., diseases, proteins) in unstructured text while minimizing dependency on supervision. We introduce a suite of unsupervised algorithms based on dependency trees and attention mechanisms and employ a range of pointwise binary classification methods. Transitioning from weakly supervised to fully unsupervised settings, we assess the methods' ability to learn from data with noisy labels. The evaluation on biomedical benchmark datasets explores the effectiveness of the methods. Our approach tackles a central issue in knowledge discovery: balancing performance with minimal supervision. By gradually decreasing supervision, we assess the robustness of pointwise binary classification techniques in handling noisy labels, revealing their capability to shift from weakly supervised to entirely unsupervised scenarios. Comprehensive benchmarking offers insights into the effectiveness of these techniques, suggesting an encouraging direction toward adaptable knowledge discovery systems, representing progress in creating data-efficient methodologies for extracting useful insights when annotated data is limited.
Evaluating the Predictive Features of Person-Centric Knowledge Graph Embeddings: Unfolding Ablation Studies
Aug 29, 2024

Developing novel predictive models with complex biomedical information is challenging due to various idiosyncrasies related to heterogeneity, standardization or sparseness of the data. We previously introduced a person-centric ontology to organize information about individual patients, and a representation learning framework to extract person-centric knowledge graphs (PKGs) and to train Graph Neural Networks (GNNs). In this paper, we propose a systematic approach to examine the results of GNN models trained with both structured and unstructured information from the MIMIC-III dataset. Through ablation studies on different clinical, demographic, and social data, we show the robustness of this approach in identifying predictive features in PKGs for the task of readmission prediction.
* Published in the 34th Medical Informatics Europe Conference
Fast-and-Frugal Text-Graph Transformers are Effective Link Predictors
Aug 13, 2024



Link prediction models can benefit from incorporating textual descriptions of entities and relations, enabling fully inductive learning and flexibility in dynamic graphs. We address the challenge of also capturing rich structured information about the local neighbourhood of entities and their relations, by introducing a Transformer-based approach that effectively integrates textual descriptions with graph structure, reducing the reliance on resource-intensive text encoders. Our experiments on three challenging datasets show that our Fast-and-Frugal Text-Graph (FnF-TG) Transformers achieve superior performance compared to the previous state-of-the-art methods, while maintaining efficiency and scalability.
Enhancing Biomedical Knowledge Discovery for Diseases: An End-To-End Open-Source Framework
Jul 18, 2024



The ever-growing volume of biomedical publications creates a critical need for efficient knowledge discovery. In this context, we introduce an open-source end-to-end framework designed to construct knowledge around specific diseases directly from raw text. To facilitate research in disease-related knowledge discovery, we create two annotated datasets focused on Rett syndrome and Alzheimer's disease, enabling the identification of semantic relations between biomedical entities. Extensive benchmarking explores various ways to represent relations and entity representations, offering insights into optimal modeling strategies for semantic relation detection and highlighting language models' competence in knowledge discovery. We also conduct probing experiments using different layer representations and attention scores to explore transformers' ability to capture semantic relations.
GADePo: Graph-Assisted Declarative Pooling Transformers for Document-Level Relation Extraction
Aug 28, 2023Document-level relation extraction aims to identify relationships between entities within a document. Current methods rely on text-based encoders and employ various hand-coded pooling heuristics to aggregate information from entity mentions and associated contexts. In this paper, we replace these rigid pooling functions with explicit graph relations by leveraging the intrinsic graph processing capabilities of the Transformer model. We propose a joint text-graph Transformer model, and a graph-assisted declarative pooling (GADePo) specification of the input which provides explicit and high-level instructions for information aggregation. This allows the pooling process to be guided by domain-specific knowledge or desired outcomes but still learned by the Transformer, leading to more flexible and customizable pooling strategies. We extensively evaluate our method across diverse datasets and models, and show that our approach yields promising results that are comparable to those achieved by the hand-coded pooling functions.
Representation Learning for Person or Entity-centric Knowledge Graphs: An Application in Healthcare
May 10, 2023



Knowledge graphs (KGs) are a popular way to organise information based on ontologies or schemas and have been used across a variety of scenarios from search to recommendation. Despite advances in KGs, representing knowledge remains a non-trivial task across industries and it is especially challenging in the biomedical and healthcare domains due to complex interdependent relations between entities, heterogeneity, lack of standardization, and sparseness of data. KGs are used to discover diagnoses or prioritize genes relevant to disease, but they often rely on schemas that are not centred around a node or entity of interest, such as a person. Entity-centric KGs are relatively unexplored but hold promise in representing important facets connected to a central node and unlocking downstream tasks beyond graph traversal and reasoning, such as generating graph embeddings and training graph neural networks for a wide range of predictive tasks. This paper presents an end-to-end representation learning framework to extract entity-centric KGs from structured and unstructured data. We introduce a star-shaped ontology to represent the multiple facets of a person and use it to guide KG creation. Compact representations of the graphs are created leveraging graph neural networks and experiments are conducted using different levels of heterogeneity or explicitness. A readmission prediction task is used to evaluate the results of the proposed framework, showing a stable system, robust to missing data, that outperforms a range of baseline machine learning classifiers. We highlight that this approach has several potential applications across domains and is open-sourced. Lastly, we discuss lessons learned, challenges, and next steps for the adoption of the framework in practice.
An Information Extraction Study: Take In Mind the Tokenization!
Apr 01, 2023Current research on the advantages and trade-offs of using characters, instead of tokenized text, as input for deep learning models, has evolved substantially. New token-free models remove the traditional tokenization step; however, their efficiency remains unclear. Moreover, the effect of tokenization is relatively unexplored in sequence tagging tasks. To this end, we investigate the impact of tokenization when extracting information from documents and present a comparative study and analysis of subword-based and character-based models. Specifically, we study Information Extraction (IE) from biomedical texts. The main outcome is twofold: tokenization patterns can introduce inductive bias that results in state-of-the-art performance, and the character-based models produce promising results; thus, transitioning to token-free IE models is feasible.
Imposing Relation Structure in Language-Model Embeddings Using Contrastive Learning
Sep 04, 2021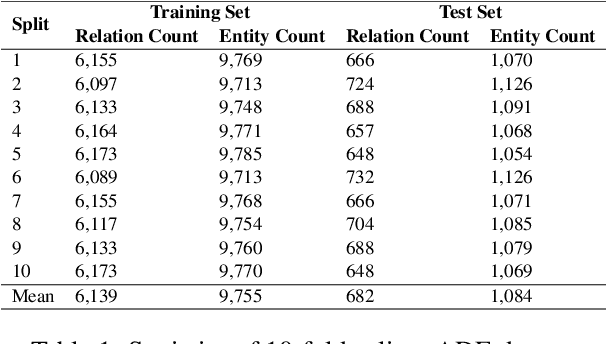
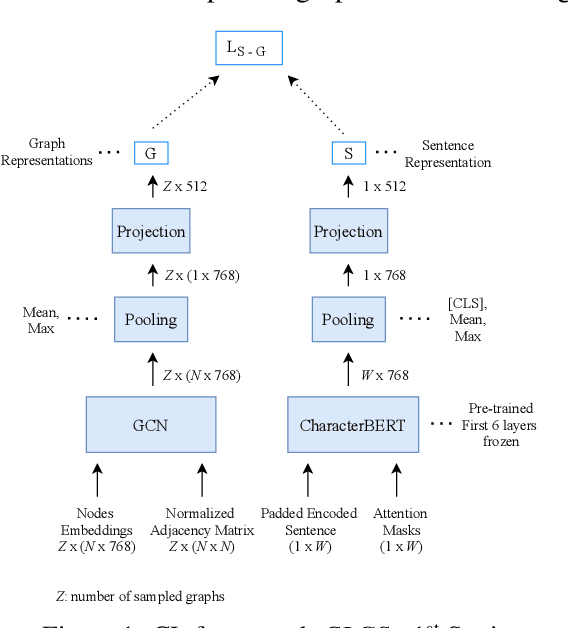
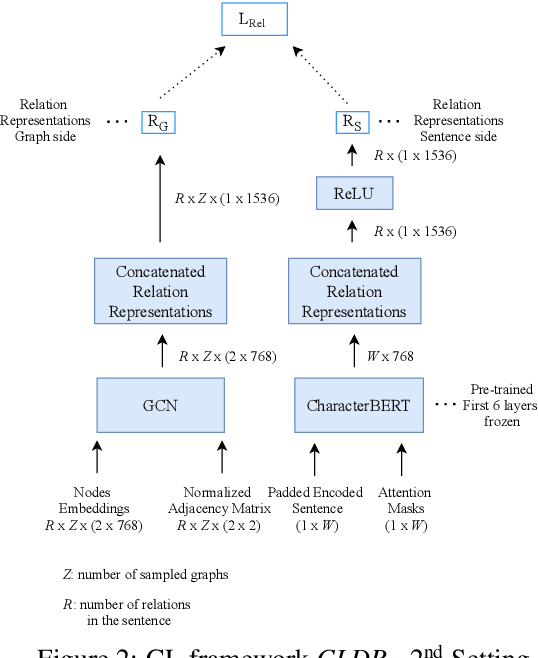
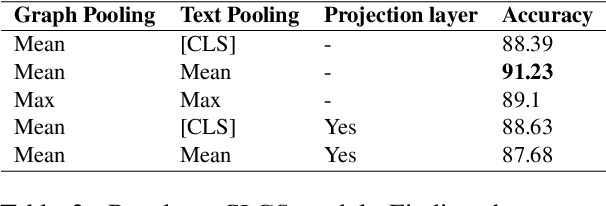
Though language model text embeddings have revolutionized NLP research, their ability to capture high-level semantic information, such as relations between entities in text, is limited. In this paper, we propose a novel contrastive learning framework that trains sentence embeddings to encode the relations in a graph structure. Given a sentence (unstructured text) and its graph, we use contrastive learning to impose relation-related structure on the token-level representations of the sentence obtained with a CharacterBERT (El Boukkouri et al.,2020) model. The resulting relation-aware sentence embeddings achieve state-of-the-art results on the relation extraction task using only a simple KNN classifier, thereby demonstrating the success of the proposed method. Additional visualization by a tSNE analysis shows the effectiveness of the learned representation space compared to baselines. Furthermore, we show that we can learn a different space for named entity recognition, again using a contrastive learning objective, and demonstrate how to successfully combine both representation spaces in an entity-relation task.