 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modify Training Directions in Function Space to Reduce Generalization Error
Jul 25, 2023
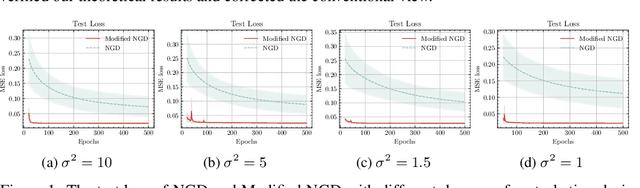
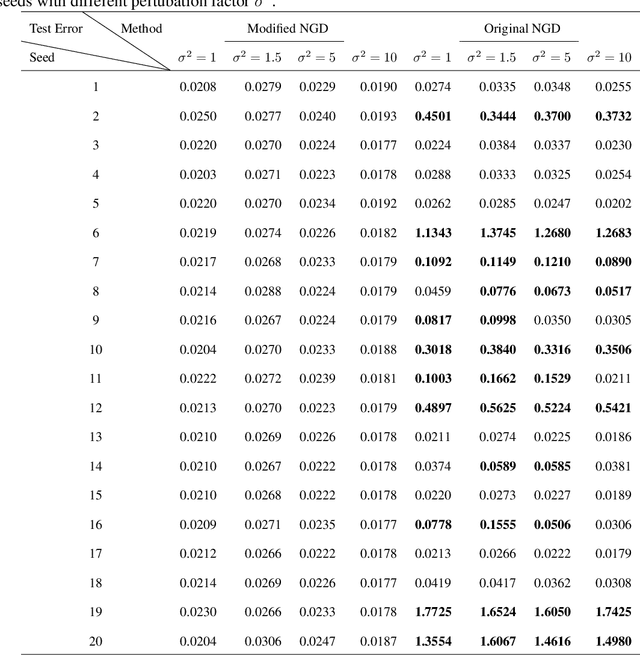
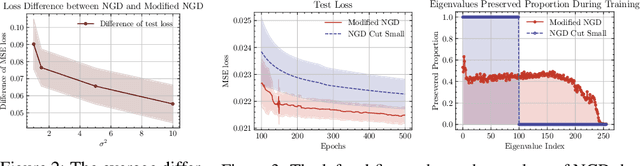
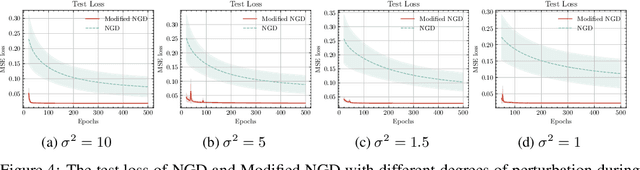
We propose theoretical analyses of a modified natural gradient descent method in the neural network function space based on the eigendecompositions of neural tangent kernel and Fisher information matrix. We firstly present analytical expression for the function learned by this modified natural gradient under the assumptions of Gaussian distribution and infinite width limit. Thus, we explicitly derive the generalization error of the learned neural network function using theoretical methods from eigendecomposition and statistics theory. By decomposing of the total generalization error attributed to different eigenspace of the kernel in function space, we propose a criterion for balancing the errors stemming from training set and the distribution discrepancy between the training set and the true data. Through this approach, we establish that modifying the training direction of the neural network in function space leads to a reduction in the total generalization error. Furthermore, We demonstrate that this theoretical framework is capable to explain many existing results of generalization enhancing methods. These theoretical results are also illustrated by numerical examples on synthetic data.
3DRP-Net: 3D Relative Position-aware Network for 3D Visual Grounding
Jul 25, 2023
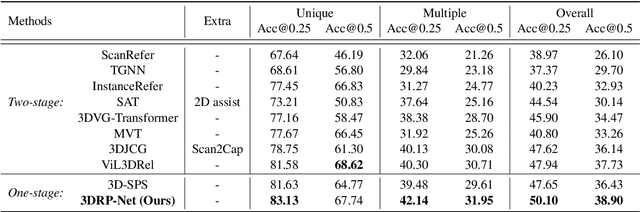
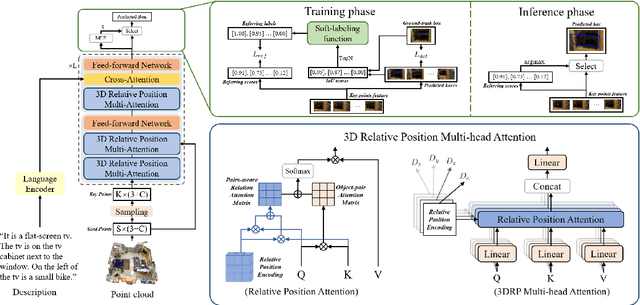
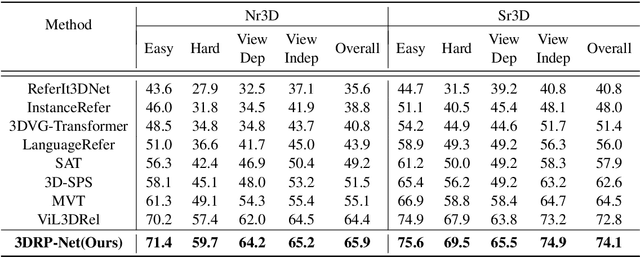
3D visual grounding aims to localize the target object in a 3D point cloud by a free-form language description. Typically, the sentences describing the target object tend to provide information about its relative relation between other objects and its position within the whole scene. In this work, we propose a relation-aware one-stage framework, named 3D Relative Position-aware Network (3DRP-Net), which can effectively capture the relative spatial relationships between objects and enhance object attributes. Specifically, 1) we propose a 3D Relative Position Multi-head Attention (3DRP-MA) module to analyze relative relations from different directions in the context of object pairs, which helps the model to focus on the specific object relations mentioned in the sentence. 2) We designed a soft-labeling strategy to alleviate the spatial ambiguity caused by redundant points, which further stabilizes and enhances the learning process through a constant and discriminative distribution. Extensive experiments conducted on three benchmarks (i.e., ScanRefer and Nr3D/Sr3D) demonstrate that our method outperforms all the state-of-the-art methods in general. The source code will be released on GitHub.
Resolution-Aware Design of Atrous Rates for Semantic Segmentation Networks
Jul 26, 2023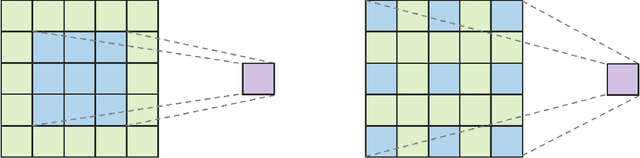
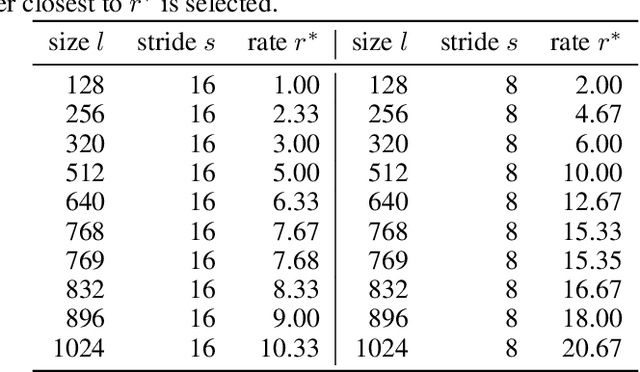
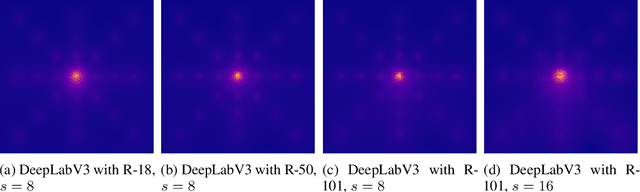

DeepLab is a widely used deep neural network for semantic segmentation, whose success is attributed to its parallel architecture called atrous spatial pyramid pooling (ASPP). ASPP uses multiple atrous convolutions with different atrous rates to extract both local and global information. However, fixed values of atrous rates are used for the ASPP module, which restricts the size of its field of view. In principle, atrous rate should be a hyperparameter to change the field of view size according to the target task or dataset. However, the manipulation of atrous rate is not governed by any guidelines. This study proposes practical guidelines for obtaining an optimal atrous rate. First, an effective receptive field for semantic segmentation is introduced to analyze the inner behavior of segmentation networks. We observed that the use of ASPP module yielded a specific pattern in the effective receptive field, which was traced to reveal the module's underlying mechanism. Accordingly, we derive practical guidelines for obtaining the optimal atrous rate, which should be controlled based on the size of input image. Compared to other values, using the optimal atrous rate consistently improved the segmentation results across multiple datasets, including the STARE, CHASE_DB1, HRF, Cityscapes, and iSAID datasets.
GPT-3 Models are Few-Shot Financial Reasoners
Jul 26, 2023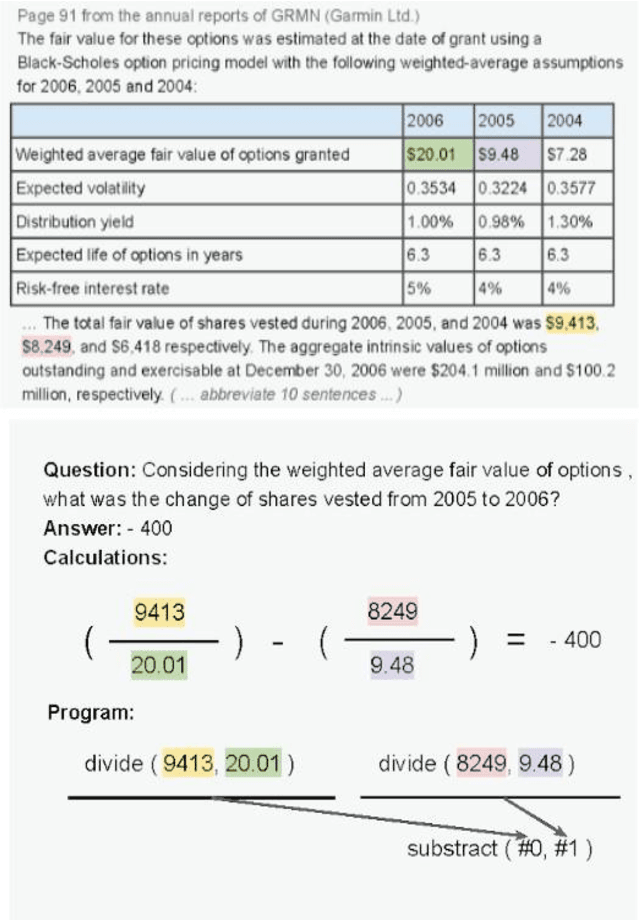

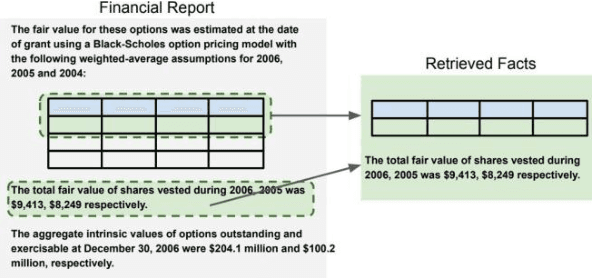

Financial analysis is an important tool for evaluating company performance. Practitioners work to answer financial questions to make profitable investment decisions, and use advanced quantitative analyses to do so. As a result, Financial Question Answering (QA) is a question answering task that requires deep reasoning about numbers. Furthermore, it is unknown how well pre-trained language models can reason in the financial domain. The current state-of-the-art requires a retriever to collect relevant facts about the financial question from the text and a generator to produce a valid financial program and a final answer. However, recently large language models like GPT-3 have achieved state-of-the-art performance on wide variety of tasks with just a few shot examples. We run several experiments with GPT-3 and find that a separate retrieval model and logic engine continue to be essential components to achieving SOTA performance in this task, particularly due to the precise nature of financial questions and the complex information stored in financial documents. With this understanding, our refined prompt-engineering approach on GPT-3 achieves near SOTA accuracy without any fine-tuning.
* 15 pages, 8 figures
NeuroHeed: Neuro-Steered Speaker Extraction using EEG Signals
Jul 26, 2023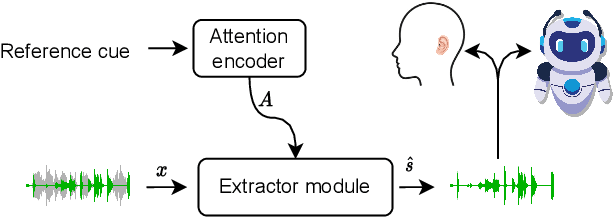
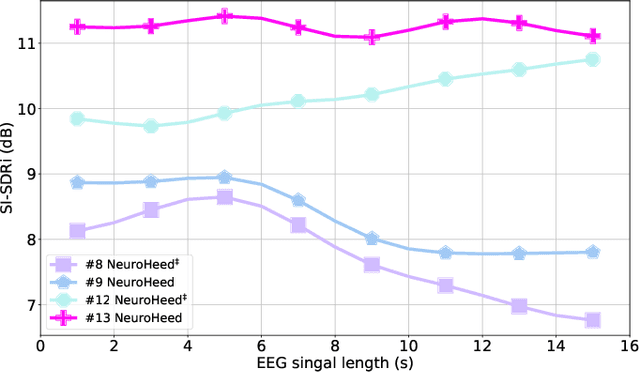
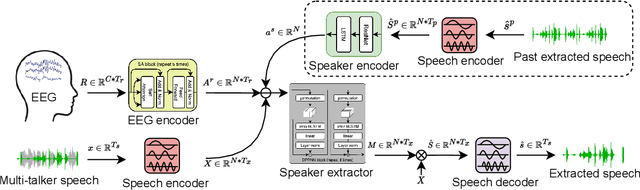
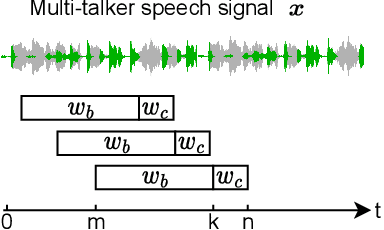
Humans possess the remarkable ability to selectively attend to a single speaker amidst competing voices and background noise, known as selective auditory attention. Recent studies in auditory neuroscience indicate a strong correlation between the attended speech signal and the corresponding brain's elicited neuronal activities, which the latter can be measured using affordable and non-intrusive electroencephalography (EEG) devices. In this study, we present NeuroHeed, a speaker extraction model that leverages EEG signals to establish a neuronal attractor which is temporally associated with the speech stimulus, facilitating the extraction of the attended speech signal in a cocktail party scenario. We propose both an offline and an online NeuroHeed, with the latter designed for real-time inference. In the online NeuroHeed, we additionally propose an autoregressive speaker encoder, which accumulates past extracted speech signals for self-enrollment of the attended speaker information into an auditory attractor, that retains the attentional momentum over time. Online NeuroHeed extracts the current window of the speech signals with guidance from both attractors. Experimental results demonstrate that NeuroHeed effectively extracts brain-attended speech signals, achieving high signal quality, excellent perceptual quality, and intelligibility in a two-speaker scenario.
LIC-GAN: Language Information Conditioned Graph Generative GAN Model
Jun 02, 2023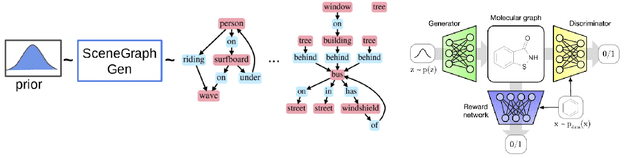
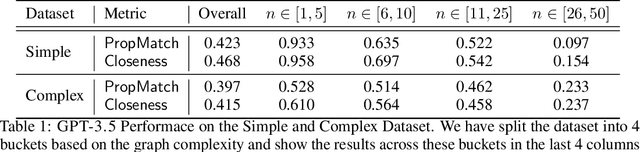
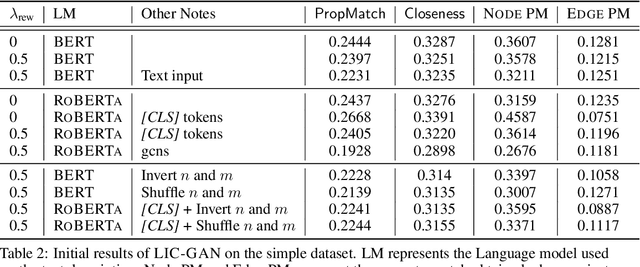
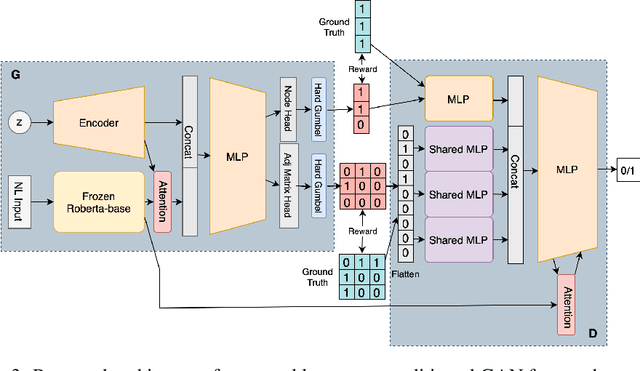
Deep generative models for Natural Language data offer a new angle on the problem of graph synthesis: by optimizing differentiable models that directly generate graphs, it is possible to side-step expensive search procedures in the discrete and vast space of possible graphs. We introduce LIC-GAN, an implicit, likelihood-free generative model for small graphs that circumvents the need for expensive graph matching procedures. Our method takes as input a natural language query and using a combination of language modelling and Generative Adversarial Networks (GANs) and returns a graph that closely matches the description of the query. We combine our approach with a reward network to further enhance the graph generation with desired properties. Our experiments, show that LIC-GAN does well on metrics such as PropMatch and Closeness getting scores of 0.36 and 0.48. We also show that LIC-GAN performs as good as ChatGPT, with ChatGPT getting scores of 0.40 and 0.42. We also conduct a few experiments to demonstrate the robustness of our method, while also highlighting a few interesting caveats of the model.
ELiOT : End-to-end Lidar Odometry using Transformer Framework
Jul 22, 2023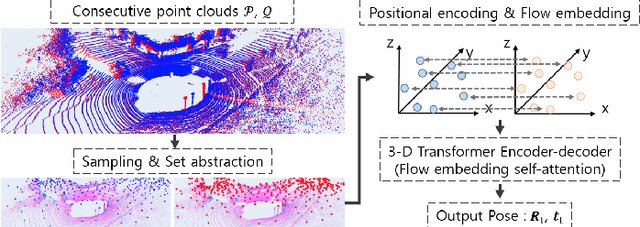
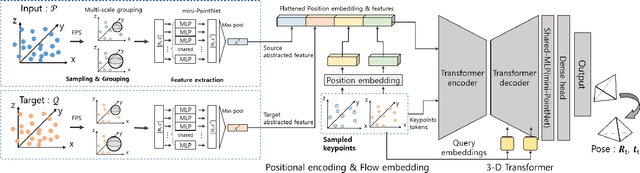
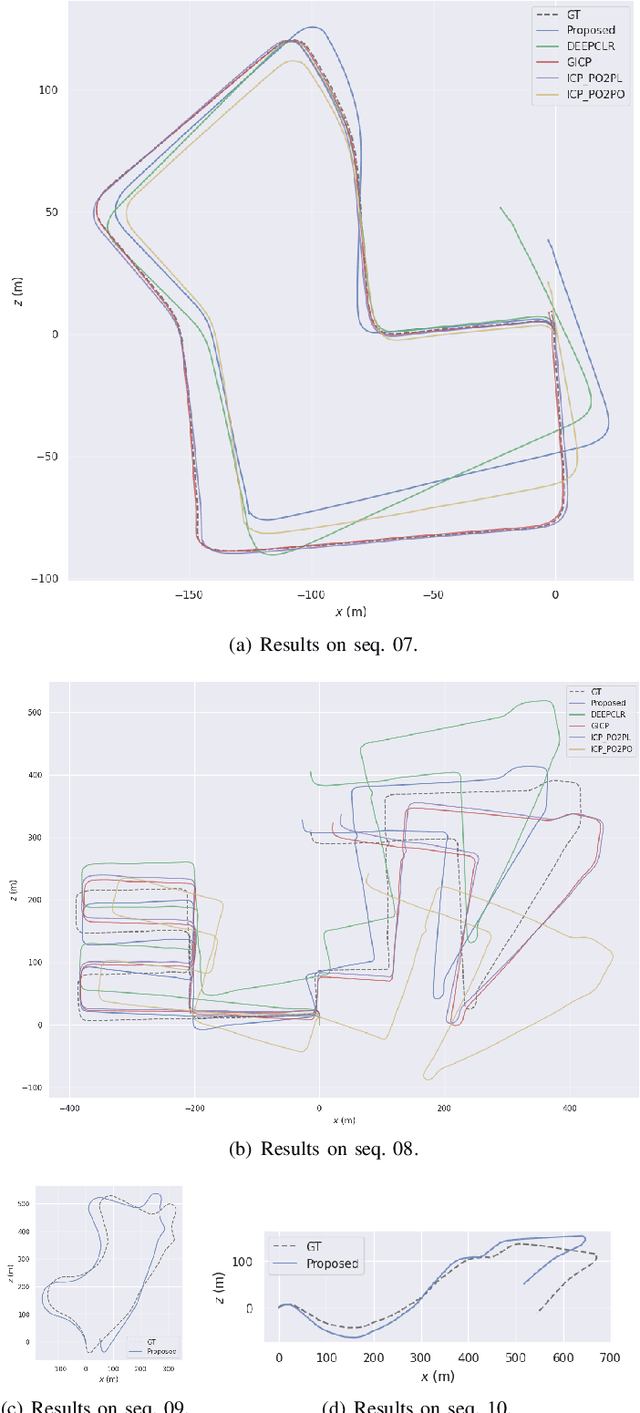
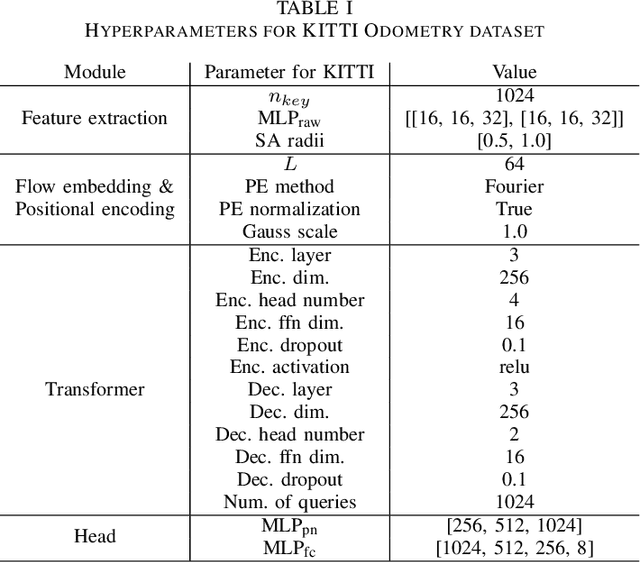
In recent years, deep-learning-based point cloud registration methods have shown significant promise. Furthermore, learning-based 3D detectors have demonstrated their effectiveness in encoding semantic information from LiDAR data. In this paper, we introduce ELiOT, an end-to-end LiDAR odometry framework built on a transformer architecture. Our proposed Self-Attention Flow Embedding Network implicitly represents the motion of sequential LiDAR scenes, bypassing the need for 3D-2D projections traditionally used in such tasks. The network pipeline, composed of a 3D transformer encoder-decoder, has shown effectiveness in predicting poses on urban datasets. In terms of translational and rotational errors, our proposed method yields encouraging results, with 7.59% and 2.67% respectively on the KITTI odometry dataset. This is achieved with an end-to-end approach that foregoes the need for conventional geometric concepts.
AcousTac: Tactile sensing with acoustic resonance for electronics-free soft skin
Jul 19, 2023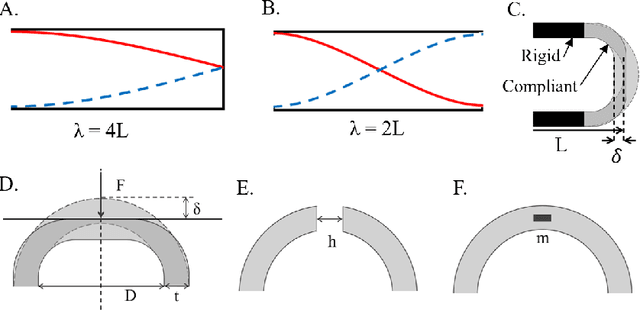
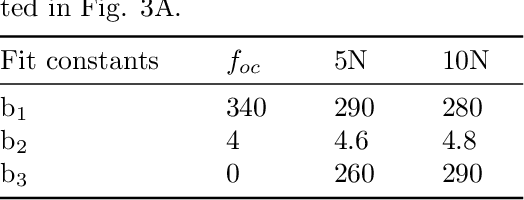
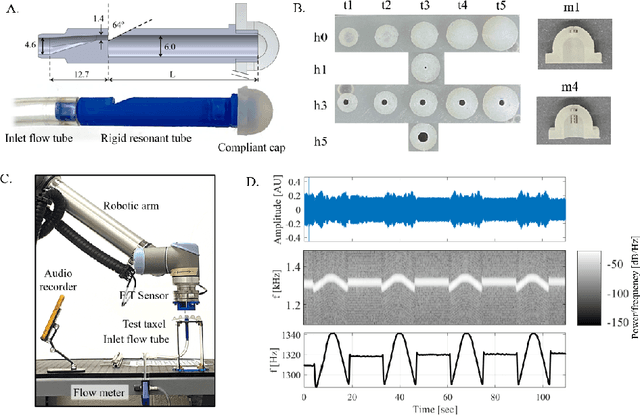
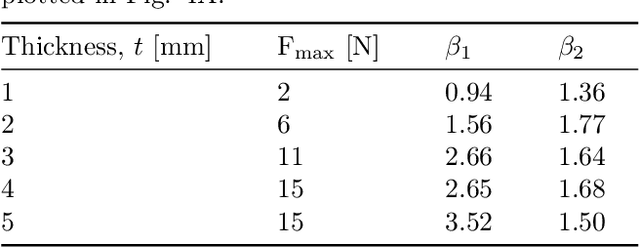
Sound is a rich information medium that transmits through air; people communicate through speech and can even discern material through tapping and listening. To capture frequencies in the human hearing range, commercial microphones typically have a sampling rate of over 40kHz. These accessible acoustic technologies are not yet widely adopted for the explicit purpose of giving robots a sense of touch. Some researchers have used sound to sense tactile information, both monitoring ambient soundscape and with embedded speakers and microphones to measure sounds within structures. However, these options commonly do not provide a direct measure of steady state force, or require electronics integrated somewhere near the contact location. In this work, we present AcousTac, an acoustic tactile sensor for electronics-free force sensitive soft skin. Compliant silicone caps and plastic tubes compose the resonant chambers that emit pneumatic-driven sound measurable with a conventional off-board microphone. The resulting frequency changes depend on the external loads on the compliant end caps. We can tune each AcousTac taxel to specific force and frequency ranges, based on geometric parameters, including tube length and end-cap geometry and thus uniquely sense each taxel simultaneously in an array. We demonstrate AcousTac's functionality on two robotic systems: a 4-taxel array and a 3-taxel astrictive gripper. AcousTac is a promising concept for force sensing on soft robotic surfaces, especially in situations where electronics near the contact are not suitable. Equipping robots with tactile sensing and soft skin provides them with a sense of touch and the ability to safely interact with their surroundings.
Control as Probabilistic Inference as an Emergent Communication Mechanism in Multi-Agent Reinforcement Learning
Jul 11, 2023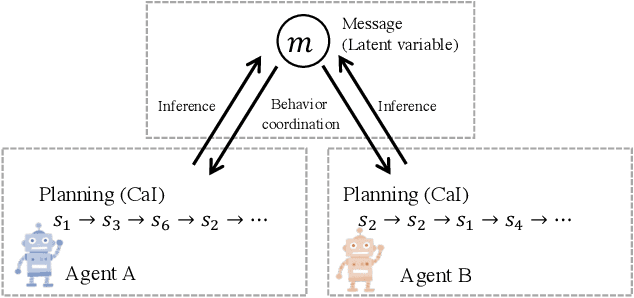

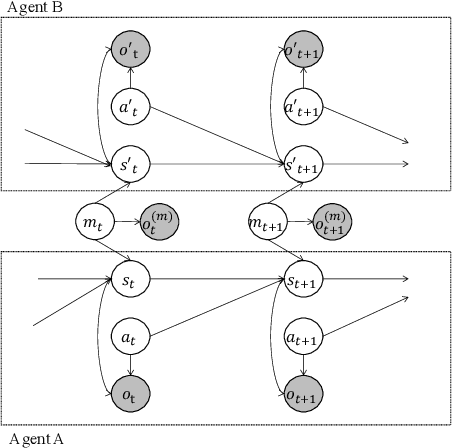
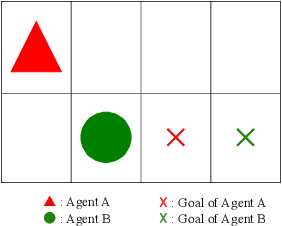
This paper proposes a generative probabilistic model integrating emergent communication and multi-agent reinforcement learning. The agents plan their actions by probabilistic inference, called control as inference, and communicate using messages that are latent variables and estimated based on the planned actions. Through these messages, each agent can send information about its actions and know information about the actions of another agent. Therefore, the agents change their actions according to the estimated messages to achieve cooperative tasks. This inference of messages can be considered as communication, and this procedure can be formulated by the Metropolis-Hasting naming game. Through experiments in the grid world environment, we show that the proposed PGM can infer meaningful messages to achieve the cooperative task.
Boosting Weakly-Supervised Temporal Action Localization with Text Information
May 01, 2023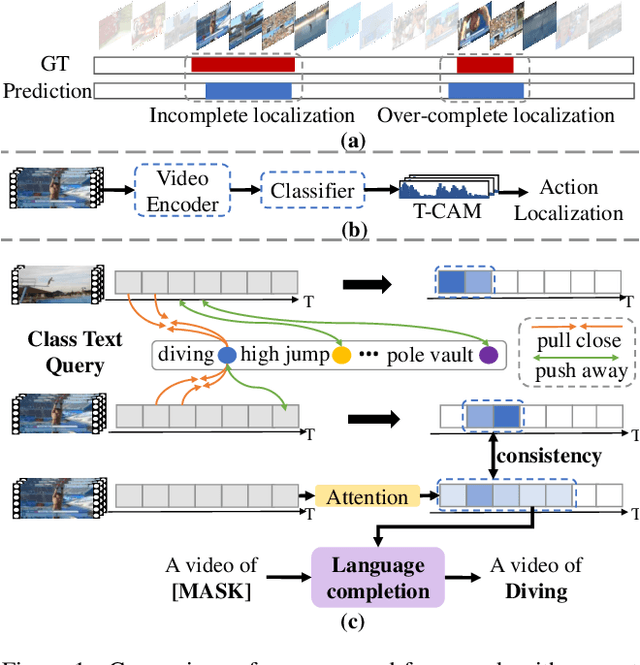
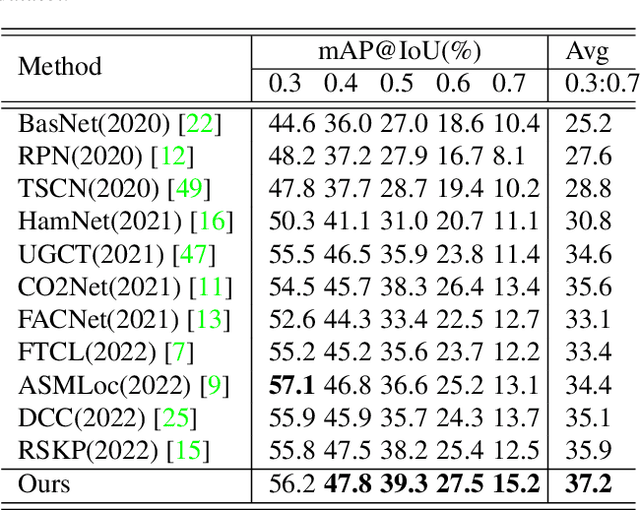
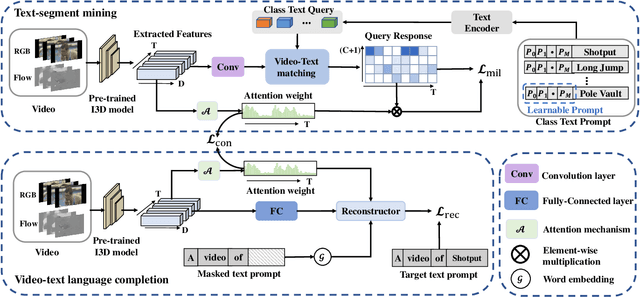
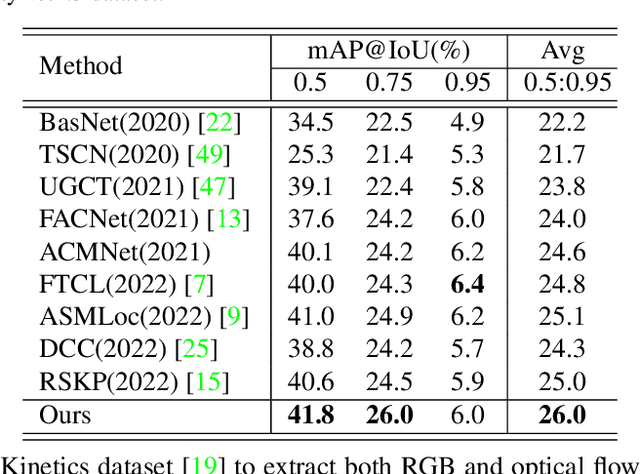
Due to the lack of temporal annotation, current Weakly-supervised Temporal Action Localization (WTAL) methods are generally stuck into over-complete or incomplete localization. In this paper, we aim to leverage the text information to boost WTAL from two aspects, i.e., (a) the discriminative objective to enlarge the inter-class difference, thus reducing the over-complete; (b) the generative objective to enhance the intra-class integrity, thus finding more complete temporal boundaries. For the discriminative objective, we propose a Text-Segment Mining (TSM) mechanism, which constructs a text description based on the action class label, and regards the text as the query to mine all class-related segments. Without the temporal annotation of actions, TSM compares the text query with the entire videos across the dataset to mine the best matching segments while ignoring irrelevant ones. Due to the shared sub-actions in different categories of videos, merely applying TSM is too strict to neglect the semantic-related segments, which results in incomplete localization. We further introduce a generative objective named Video-text Language Completion (VLC), which focuses on all semantic-related segments from videos to complete the text sentence. We achieve the state-of-the-art performance on THUMOS14 and ActivityNet1.3. Surprisingly, we also find our proposed method can be seamlessly applied to existing methods, and improve their performances with a clear margin. The code is available at https://github.com/lgzlIlIlI/Boosting-WTAL.