 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A DeepLearning Framework for Dynamic Estimation of Origin-Destination Sequence
Jul 11, 2023
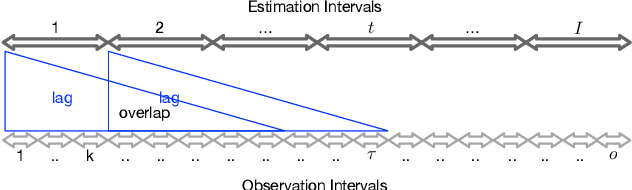
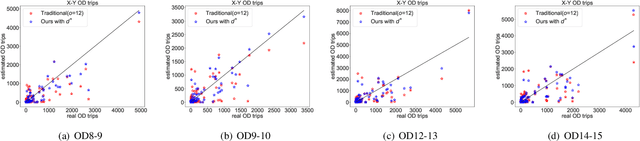
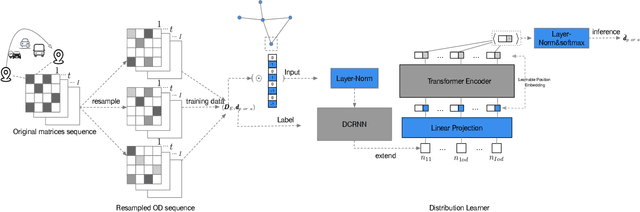

OD matrix estimation is a critical problem in the transportation domain. The principle method uses the traffic sensor measured information such as traffic counts to estimate the traffic demand represented by the OD matrix. The problem is divided into two categories: static OD matrix estimation and dynamic OD matrices sequence(OD sequence for short) estimation. The above two face the underdetermination problem caused by abundant estimated parameters and insufficient constraint information. In addition, OD sequence estimation also faces the lag challenge: due to different traffic conditions such as congestion, identical vehicle will appear on different road sections during the same observation period, resulting in identical OD demands correspond to different trips. To this end, this paper proposes an integrated method, which uses deep learning methods to infer the structure of OD sequence and uses structural constraints to guide traditional numerical optimization. Our experiments show that the neural network(NN) can effectively infer the structure of the OD sequence and provide practical constraints for numerical optimization to obtain better results. Moreover, the experiments show that provided structural information contains not only constraints on the spatial structure of OD matrices but also provides constraints on the temporal structure of OD sequence, which solve the effect of the lagging problem well.
ExFaceGAN: Exploring Identity Directions in GAN's Learned Latent Space for Synthetic Identity Generation
Jul 11, 2023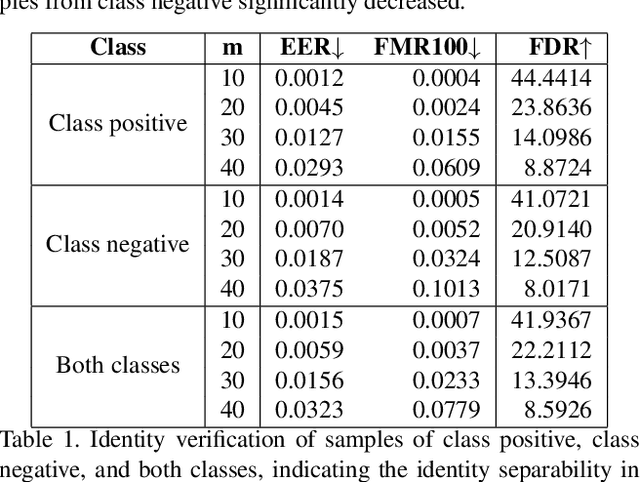
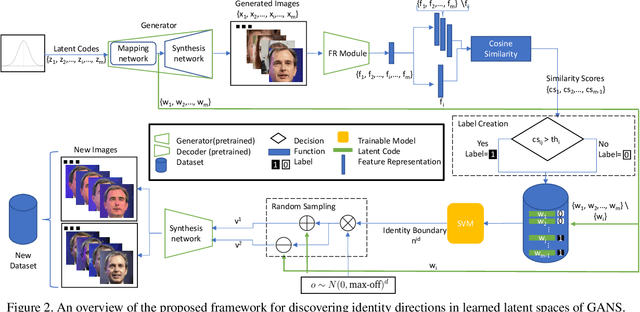
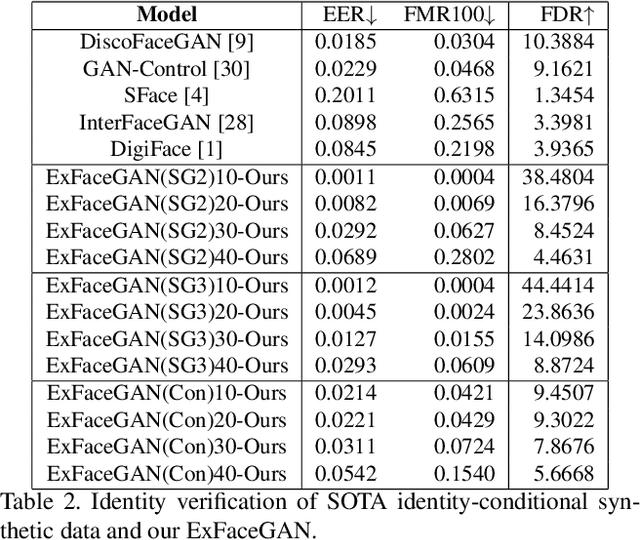
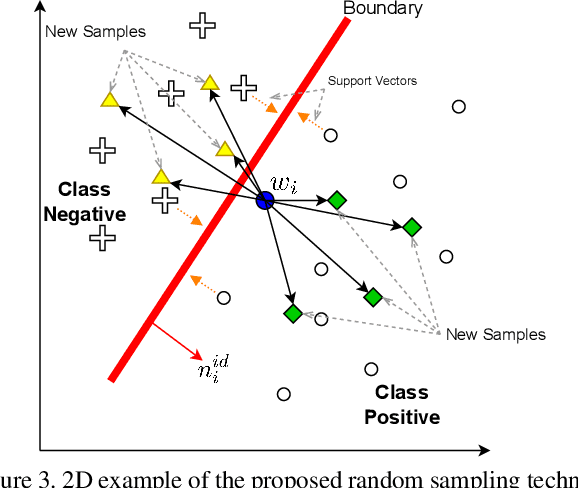
Deep generative models have recently presented impressive results in generating realistic face images of random synthetic identities. To generate multiple samples of a certain synthetic identity, several previous works proposed to disentangle the latent space of GANs by incorporating additional supervision or regularization, enabling the manipulation of certain attributes, e.g. identity, hairstyle, pose, or expression. Most of these works require designing special loss functions and training dedicated network architectures. Others proposed to disentangle specific factors in unconditional pretrained GANs latent spaces to control their output, which also requires supervision by attribute classifiers. Moreover, these attributes are entangled in GAN's latent space, making it difficult to manipulate them without affecting the identity information. We propose in this work a framework, ExFaceGAN, to disentangle identity information in state-of-the-art pretrained GANs latent spaces, enabling the generation of multiple samples of any synthetic identity. The variations in our generated images are not limited to specific attributes as ExFaceGAN explicitly aims at disentangling identity information, while other visual attributes are randomly drawn from a learned GAN latent space. As an example of the practical benefit of our ExFaceGAN, we empirically prove that data generated by ExFaceGAN can be successfully used to train face recognition models.
Robust Weighted Sum-Rate Maximization for Transmissive RIS Transmitter Enabled RSMA Networks
Jul 23, 2023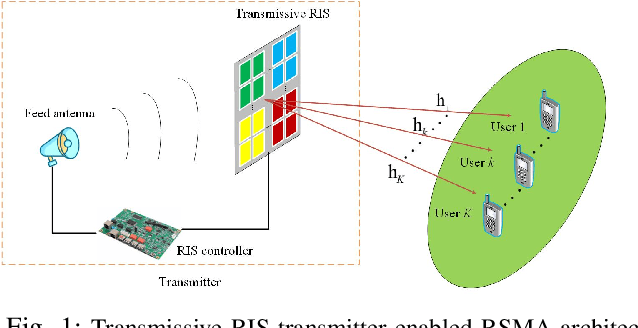
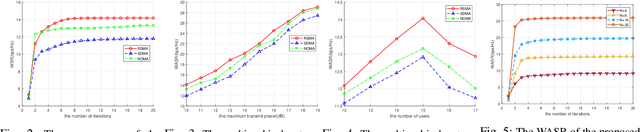
Due to the low power consumption and low cost nature of transmissive reconfigurable intelligent surface (RIS),in this paper, we propose a downlink multi-user rate-splitting multiple access (RSMA) architecture based on the transmissive RIS transmitter, where the channel state information (CSI) is only accquired partially. We investigate the weighted sum-rate maximization problem by jointly optimizing the power, RIS transmissive coefficients and common rate allocated to each user. Due to the coupling of optimization variables, the problem is nonconvex, and it is difficult to directly obtain the optimal solution. Hence, a block coordinate descent (BCD) algorithm based on sample average approximation (SAA) and weighted minimum mean square error (WMMSE) is proposed to tackle it. Numerical results illustrate that the transmissive RIS transmitter with ratesplitting architecture has advantages over conventional space division multiple access (SDMA) and non-orthgonal multiple access (NOMA).
Multi-Modal Machine Learning for Assessing Gaming Skills in Online Streaming: A Case Study with CS:GO
Jul 23, 2023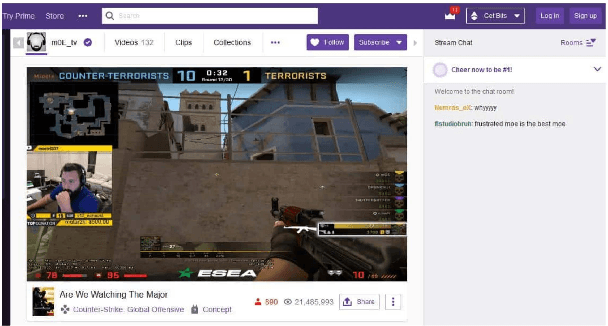
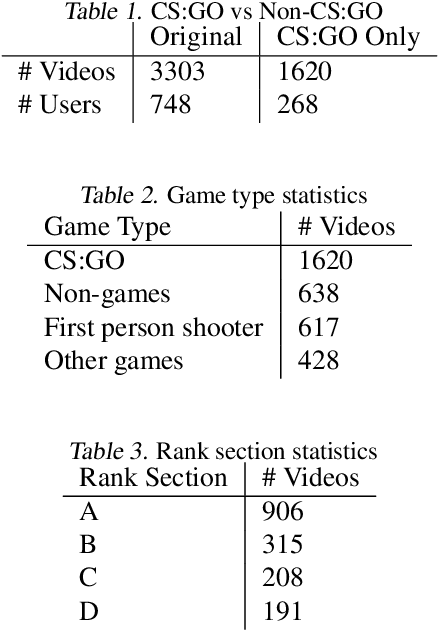
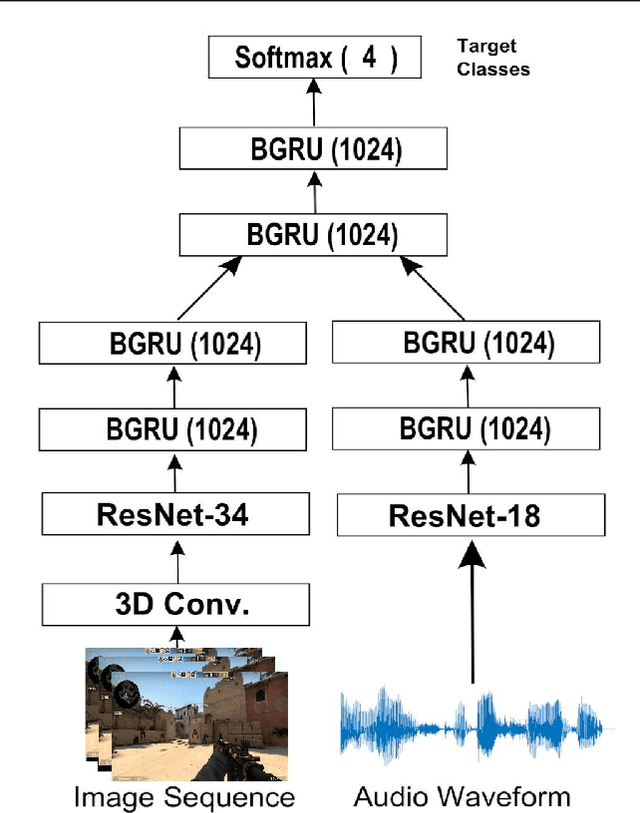
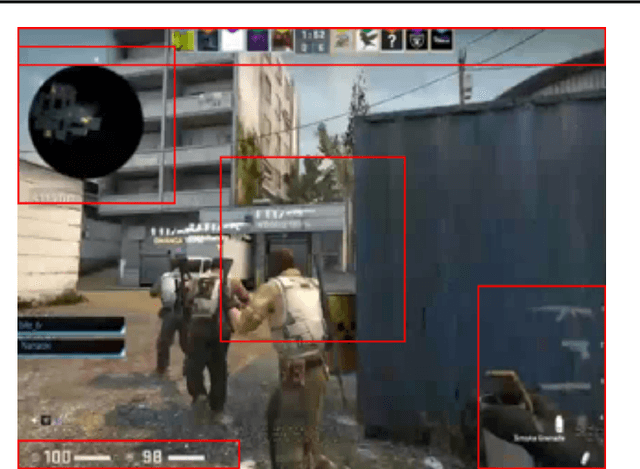
Online streaming is an emerging market that address much attention. Assessing gaming skills from videos is an important task for streaming service providers to discover talented gamers. Service providers require the information to offer customized recommendation and service promotion to their customers. Meanwhile, this is also an important multi-modal machine learning tasks since online streaming combines vision, audio and text modalities. In this study we begin by identifying flaws in the dataset and proceed to clean it manually. Then we propose several variants of latest end-to-end models to learn joint representation of multiple modalities. Through our extensive experimentation, we demonstrate the efficacy of our proposals. Moreover, we identify that our proposed models is prone to identifying users instead of learning meaningful representations. We purpose future work to address the issue in the end.
Implicit Neural Feature Fusion Function for Multispectral and Hyperspectral Image Fusion
Jul 14, 2023Multispectral and Hyperspectral Image Fusion (MHIF) is a practical task that aims to fuse a high-resolution multispectral image (HR-MSI) and a low-resolution hyperspectral image (LR-HSI) of the same scene to obtain a high-resolution hyperspectral image (HR-HSI). Benefiting from powerful inductive bias capability, CNN-based methods have achieved great success in the MHIF task. However, they lack certain interpretability and require convolution structures be stacked to enhance performance. Recently, Implicit Neural Representation (INR) has achieved good performance and interpretability in 2D tasks due to its ability to locally interpolate samples and utilize multimodal content such as pixels and coordinates. Although INR-based approaches show promise, they require extra construction of high-frequency information (\emph{e.g.,} positional encoding). In this paper, inspired by previous work of MHIF task, we realize that HR-MSI could serve as a high-frequency detail auxiliary input, leading us to propose a novel INR-based hyperspectral fusion function named Implicit Neural Feature Fusion Function (INF). As an elaborate structure, it solves the MHIF task and addresses deficiencies in the INR-based approaches. Specifically, our INF designs a Dual High-Frequency Fusion (DHFF) structure that obtains high-frequency information twice from HR-MSI and LR-HSI, then subtly fuses them with coordinate information. Moreover, the proposed INF incorporates a parameter-free method named INR with cosine similarity (INR-CS) that uses cosine similarity to generate local weights through feature vectors. Based on INF, we construct an Implicit Neural Fusion Network (INFN) that achieves state-of-the-art performance for MHIF tasks of two public datasets, \emph{i.e.,} CAVE and Harvard. The code will soon be made available on GitHub.
Stroke Extraction of Chinese Character Based on Deep Structure Deformable Image Registration
Jul 10, 2023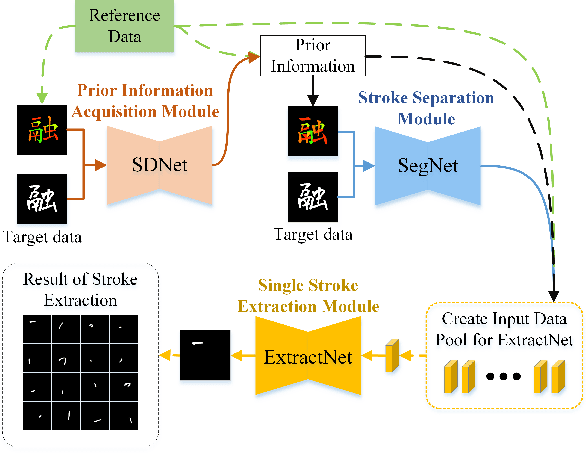
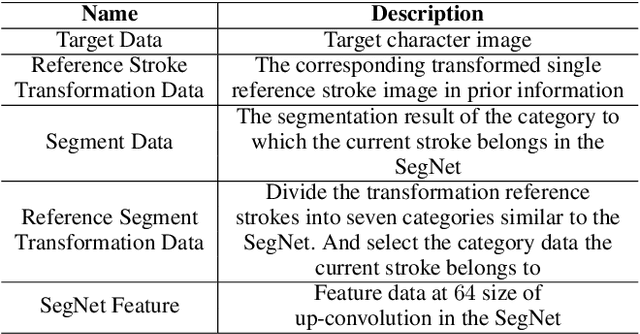
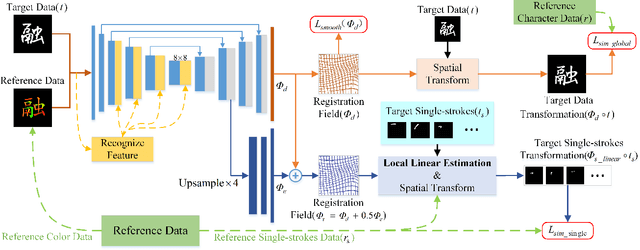
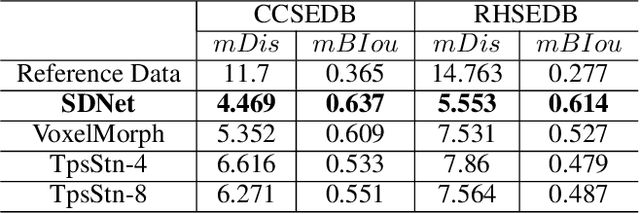
Stroke extraction of Chinese characters plays an important role in the field of character recognition and generation. The most existing character stroke extraction methods focus on image morphological features. These methods usually lead to errors of cross strokes extraction and stroke matching due to rarely using stroke semantics and prior information. In this paper, we propose a deep learning-based character stroke extraction method that takes semantic features and prior information of strokes into consideration. This method consists of three parts: image registration-based stroke registration that establishes the rough registration of the reference strokes and the target as prior information; image semantic segmentation-based stroke segmentation that preliminarily separates target strokes into seven categories; and high-precision extraction of single strokes. In the stroke registration, we propose a structure deformable image registration network to achieve structure-deformable transformation while maintaining the stable morphology of single strokes for character images with complex structures. In order to verify the effectiveness of the method, we construct two datasets respectively for calligraphy characters and regular handwriting characters. The experimental results show that our method strongly outperforms the baselines. Code is available at https://github.com/MengLi-l1/StrokeExtraction.
* 10 pages, 8 figures, published to AAAI-23 (oral)
An Intrinsic Framework of Information Retrieval Evaluation Measures
Apr 02, 2023

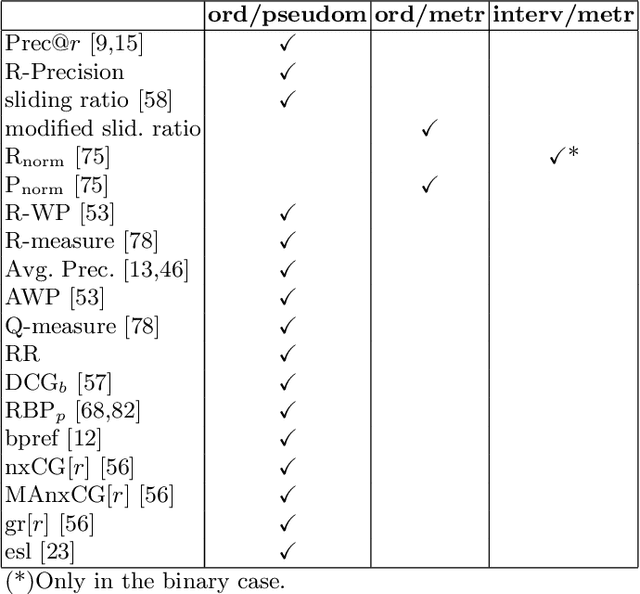
Information retrieval (IR) evaluation measures are cornerstones for determining the suitability and task performance efficiency of retrieval systems. Their metric and scale properties enable to compare one system against another to establish differences or similarities. Based on the representational theory of measurement, this paper determines these properties by exploiting the information contained in a retrieval measure itself. It establishes the intrinsic framework of a retrieval measure, which is the common scenario when the domain set is not explicitly specified. A method to determine the metric and scale properties of any retrieval measure is provided, requiring knowledge of only some of its attained values. The method establishes three main categories of retrieval measures according to their intrinsic properties. Some common user-oriented and system-oriented evaluation measures are classified according to the presented taxonomy.
Line Search for Convex Minimization
Jul 31, 2023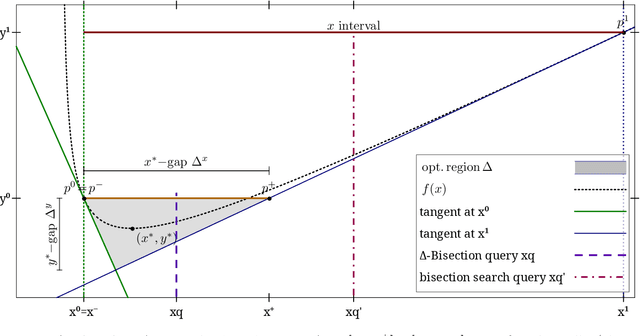
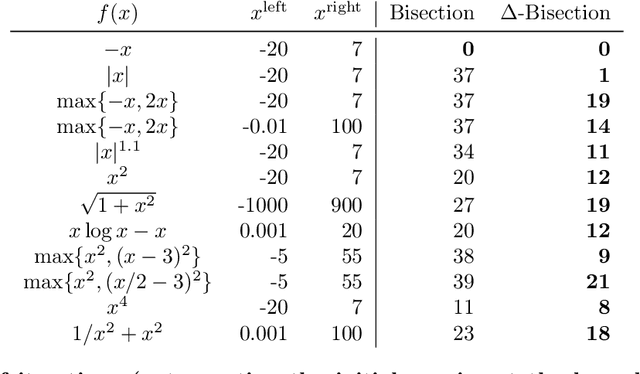
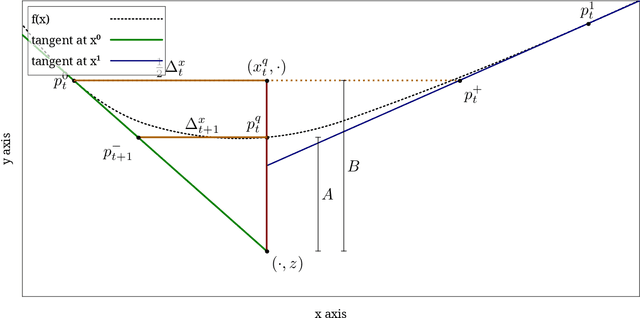

Golden-section search and bisection search are the two main principled algorithms for 1d minimization of quasiconvex (unimodal) functions. The first one only uses function queries, while the second one also uses gradient queries. Other algorithms exist under much stronger assumptions, such as Newton's method. However, to the best of our knowledge, there is no principled exact line search algorithm for general convex functions -- including piecewise-linear and max-compositions of convex functions -- that takes advantage of convexity. We propose two such algorithms: $\Delta$-Bisection is a variant of bisection search that uses (sub)gradient information and convexity to speed up convergence, while $\Delta$-Secant is a variant of golden-section search and uses only function queries. While bisection search reduces the $x$ interval by a factor 2 at every iteration, $\Delta$-Bisection reduces the (sometimes much) smaller $x^*$-gap $\Delta^x$ (the $x$ coordinates of $\Delta$) by at least a factor 2 at every iteration. Similarly, $\Delta$-Secant also reduces the $x^*$-gap by at least a factor 2 every second function query. Moreover, the $y^*$-gap $\Delta^y$ (the $y$ coordinates of $\Delta$) also provides a refined stopping criterion, which can also be used with other algorithms. Experiments on a few convex functions confirm that our algorithms are always faster than their quasiconvex counterparts, often by more than a factor 2. We further design a quasi-exact line search algorithm based on $\Delta$-Secant. It can be used with gradient descent as a replacement for backtracking line search, for which some parameters can be finicky to tune -- and we provide examples to this effect, on strongly-convex and smooth functions. We provide convergence guarantees, and confirm the efficiency of quasi-exact line search on a few single- and multivariate convex functions.
VacancySBERT: the approach for representation of titles and skills for semantic similarity search in the recruitment domain
Jul 31, 2023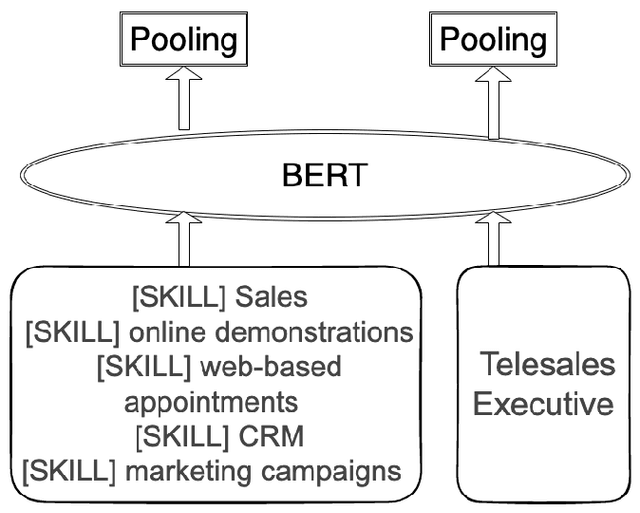
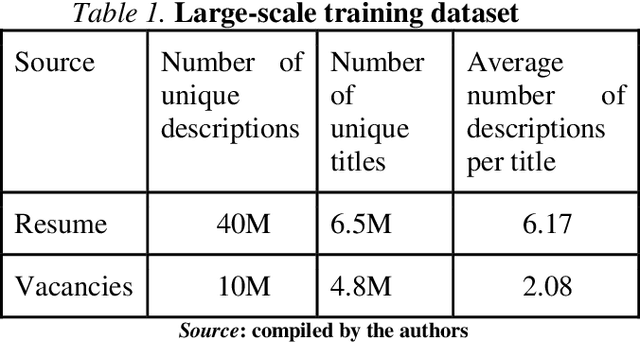
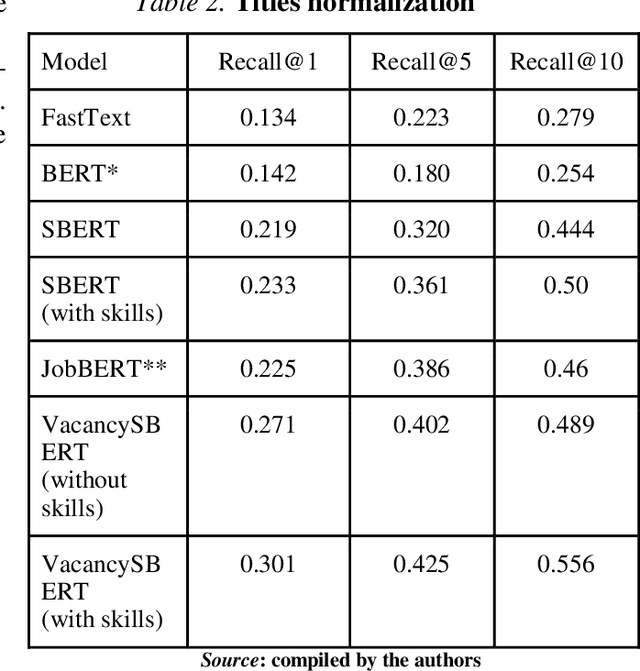
The paper focuses on deep learning semantic search algorithms applied in the HR domain. The aim of the article is developing a novel approach to training a Siamese network to link the skills mentioned in the job ad with the title. It has been shown that the title normalization process can be based either on classification or similarity comparison approaches. While classification algorithms strive to classify a sample into predefined set of categories, similarity search algorithms take a more flexible approach, since they are designed to find samples that are similar to a given query sample, without requiring pre-defined classes and labels. In this article semantic similarity search to find candidates for title normalization has been used. A pre-trained language model has been adapted while teaching it to match titles and skills based on co-occurrence information. For the purpose of this research fifty billion title-descriptions pairs had been collected for training the model and thirty three thousand title-description-normalized title triplets, where normalized job title was picked up manually by job ad creator for testing purposes. As baselines FastText, BERT, SentenceBert and JobBert have been used. As a metric of the accuracy of the designed algorithm is Recall in top one, five and ten model's suggestions. It has been shown that the novel training objective lets it achieve significant improvement in comparison to other generic and specific text encoders. Two settings with treating titles as standalone strings, and with included skills as additional features during inference have been used and the results have been compared in this article. Improvements by 10% and 21.5% have been achieved using VacancySBERT and VacancySBERT (with skills) respectively. The benchmark has been developed as open-source to foster further research in the area.
* 8 pages, 3 figures
Anomaly Detection in Industrial Machinery using IoT Devices and Machine Learning: a Systematic Mapping
Jul 28, 2023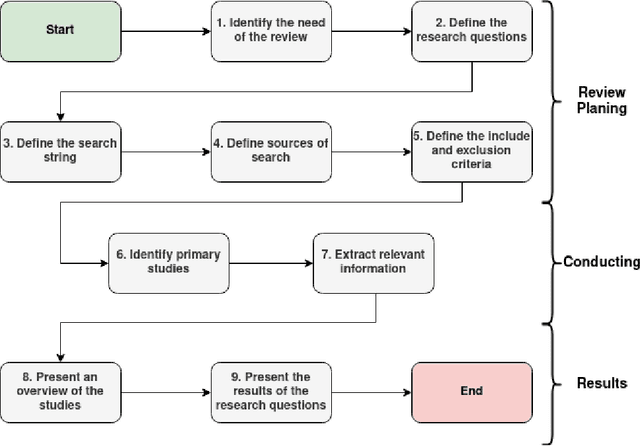

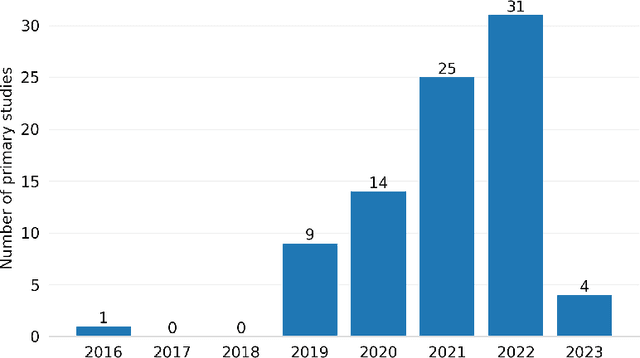

Anomaly detection is critical in the smart industry for preventing equipment failure, reducing downtime, and improving safety. Internet of Things (IoT) has enabled the collection of large volumes of data from industrial machinery, providing a rich source of information for Anomaly Detection. However, the volume and complexity of data generated by the Internet of Things ecosystems make it difficult for humans to detect anomalies manually. Machine learning (ML) algorithms can automate anomaly detection in industrial machinery by analyzing generated data. Besides, each technique has specific strengths and weaknesses based on the data nature and its corresponding systems. However, the current systematic mapping studies on Anomaly Detection primarily focus on addressing network and cybersecurity-related problems, with limited attention given to the industrial sector. Additionally, these studies do not cover the challenges involved in using ML for Anomaly Detection in industrial machinery within the context of the IoT ecosystems. This paper presents a systematic mapping study on Anomaly Detection for industrial machinery using IoT devices and ML algorithms to address this gap. The study comprehensively evaluates 84 relevant studies spanning from 2016 to 2023, providing an extensive review of Anomaly Detection research. Our findings identify the most commonly used algorithms, preprocessing techniques, and sensor types. Additionally, this review identifies application areas and points to future challenges and research opportunities.