 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Partial-Information Multiple Access Protocol for Orthogonal Transmissions
Apr 24, 2023
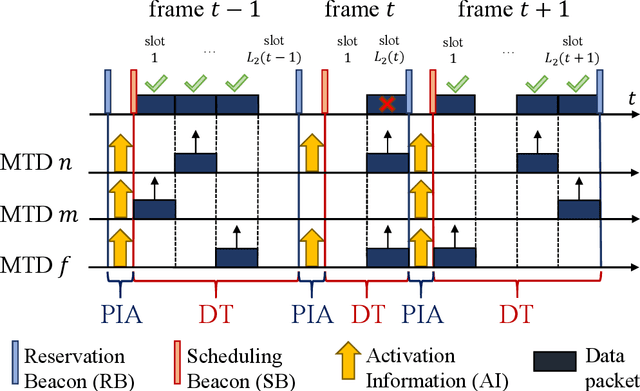
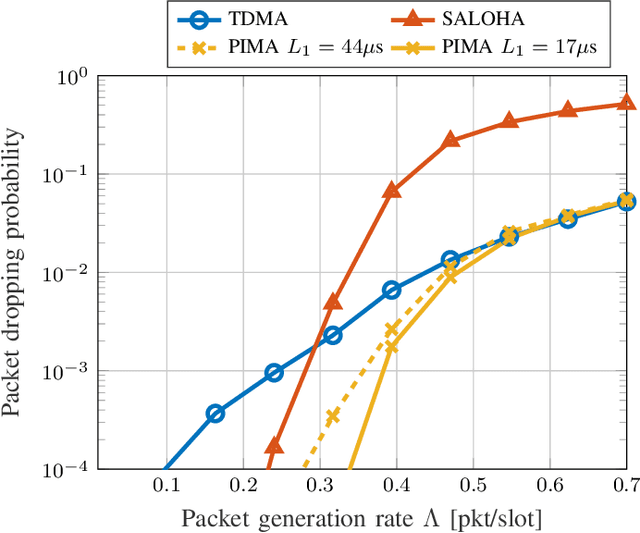
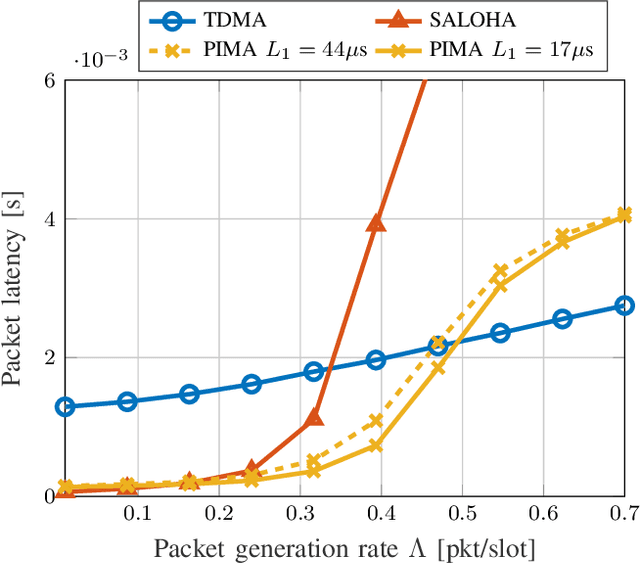
With the stringent requirements introduced by the new sixth-generation (6G) internet-of-things (IoT) use cases, traditional approaches to multiple access control have started to show their limitations. A new wave of grant-free (GF) approaches have been therefore proposed as a viable alternative. However, a definitive solution is still to be accomplished. In our work, we propose a new semi-GF coordinated random access (RA) protocol, denoted as partial-information multiple access (PIMA), to reduce packet loss and latency, particularly in the presence of sporadic activations. We consider a machine-type communications (MTC) scenario, wherein devices need to transmit data packets in the uplink to a base station (BS). When using PIMA, the BS can acquire partial information on the instantaneous traffic conditions and, using compute-over-the-air techniques, estimate the number of devices with packets waiting for transmission in their queue. Based on this knowledge, the BS assigns to each device a single slot for transmission. However, since each slot may still be assigned to multiple users, collisions may occur. Both the total number of allocated slots and the user assignments are optimized, based on the estimated number of active users, to reduce collisions and improve the efficiency of the multiple access scheme. To prove the validity of our solution, we compare PIMA to time-division multiple-access (TDMA) and slotted ALOHA (SALOHA) schemes, the ideal solutions for orthogonal multiple access (OMA) in the time domain in the case of low and high traffic conditions, respectively. We show that PIMA is able not only to adapt to different traffic conditions and to provide fewer packet drops regardless of the intensity of packet generations, but also able to merge the advantages of both TDMA and SALOHA schemes, thus providing performance improvements in terms of packet loss probability and latency.
DocParser: End-to-end OCR-free Information Extraction from Visually Rich Documents
May 01, 2023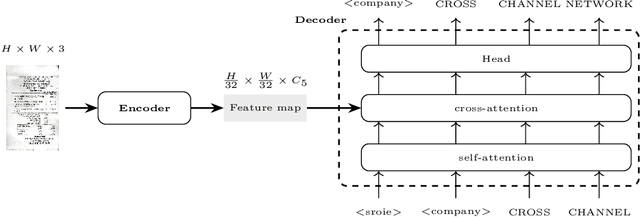
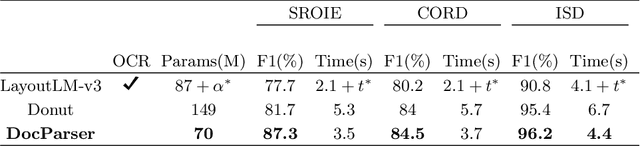
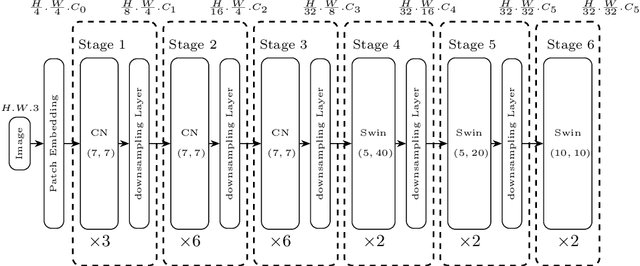

Information Extraction from visually rich documents is a challenging task that has gained a lot of attention in recent years due to its importance in several document-control based applications and its widespread commercial value. The majority of the research work conducted on this topic to date follow a two-step pipeline. First, they read the text using an off-the-shelf Optical Character Recognition (OCR) engine, then, they extract the fields of interest from the obtained text. The main drawback of these approaches is their dependence on an external OCR system, which can negatively impact both performance and computational speed. Recent OCR-free methods were proposed to address the previous issues. Inspired by their promising results, we propose in this paper an OCR-free end-to-end information extraction model named DocParser. It differs from prior end-to-end approaches by its ability to better extract discriminative character features. DocParser achieves state-of-the-art results on various datasets, while still being faster than previous works.
Adversarial Agents For Attacking Inaudible Voice Activated Devices
Jul 23, 2023

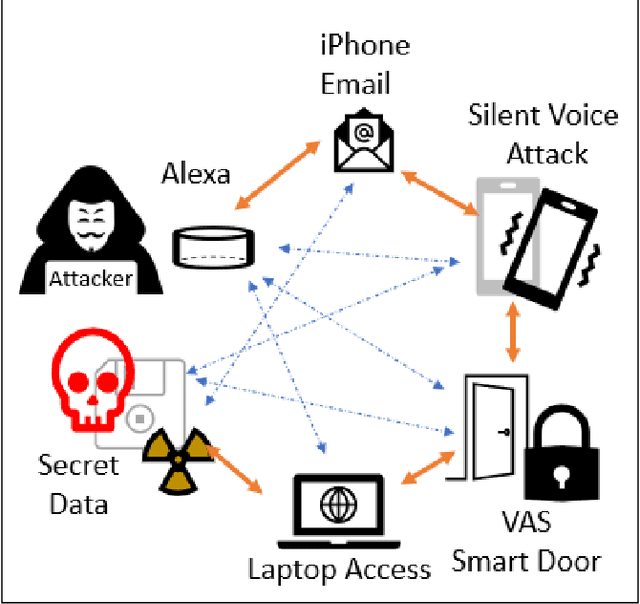
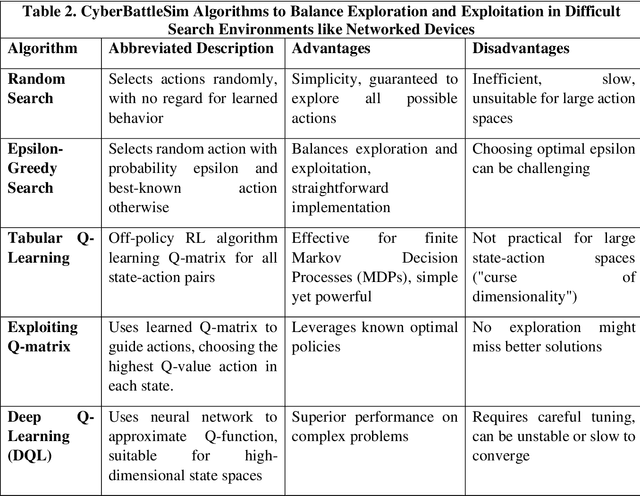
Our analysis of inaudible attacks on voice-activated devices confirms the alarming risk factor of 7.6 out of 10, underlining significant security vulnerabilities scored independently by NIST National Vulnerability Database (NVD). Our baseline network model showcases a scenario in which an attacker uses inaudible voice commands to gain unauthorized access to confidential information on a secured laptop. We simulated many attack scenarios on this baseline network model, revealing the potential for mass exploitation of interconnected devices to discover and own privileged information through physical access without adding new hardware or amplifying device skills. Using Microsoft's CyberBattleSim framework, we evaluated six reinforcement learning algorithms and found that Deep-Q learning with exploitation proved optimal, leading to rapid ownership of all nodes in fewer steps. Our findings underscore the critical need for understanding non-conventional networks and new cybersecurity measures in an ever-expanding digital landscape, particularly those characterized by mobile devices, voice activation, and non-linear microphones susceptible to malicious actors operating stealth attacks in the near-ultrasound or inaudible ranges. By 2024, this new attack surface might encompass more digital voice assistants than people on the planet yet offer fewer remedies than conventional patching or firmware fixes since the inaudible attacks arise inherently from the microphone design and digital signal processing.
GLSFormer: Gated - Long, Short Sequence Transformer for Step Recognition in Surgical Videos
Jul 20, 2023Automated surgical step recognition is an important task that can significantly improve patient safety and decision-making during surgeries. Existing state-of-the-art methods for surgical step recognition either rely on separate, multi-stage modeling of spatial and temporal information or operate on short-range temporal resolution when learned jointly. However, the benefits of joint modeling of spatio-temporal features and long-range information are not taken in account. In this paper, we propose a vision transformer-based approach to jointly learn spatio-temporal features directly from sequence of frame-level patches. Our method incorporates a gated-temporal attention mechanism that intelligently combines short-term and long-term spatio-temporal feature representations. We extensively evaluate our approach on two cataract surgery video datasets, namely Cataract-101 and D99, and demonstrate superior performance compared to various state-of-the-art methods. These results validate the suitability of our proposed approach for automated surgical step recognition. Our code is released at: https://github.com/nisargshah1999/GLSFormer
LA-Net: Landmark-Aware Learning for Reliable Facial Expression Recognition under Label Noise
Jul 20, 2023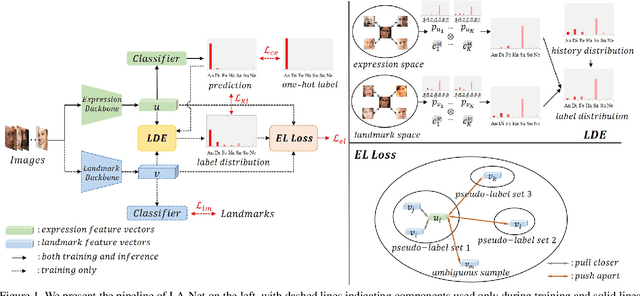
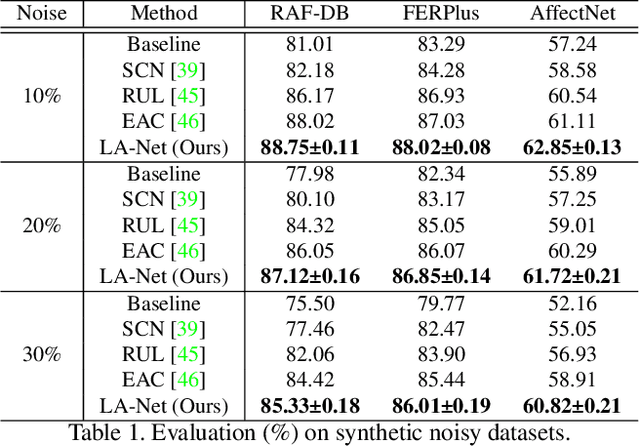
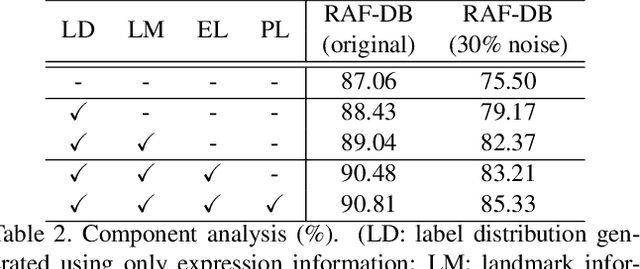
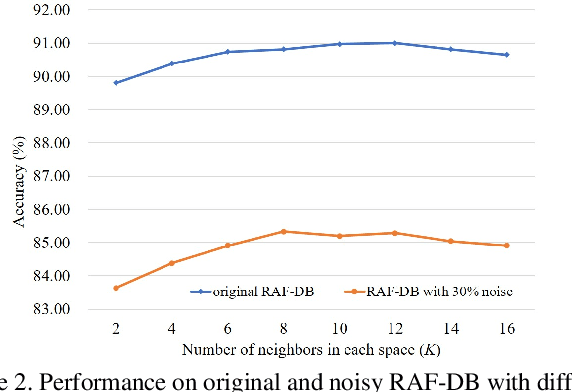
Facial expression recognition (FER) remains a challenging task due to the ambiguity of expressions. The derived noisy labels significantly harm the performance in real-world scenarios. To address this issue, we present a new FER model named Landmark-Aware Net~(LA-Net), which leverages facial landmarks to mitigate the impact of label noise from two perspectives. Firstly, LA-Net uses landmark information to suppress the uncertainty in expression space and constructs the label distribution of each sample by neighborhood aggregation, which in turn improves the quality of training supervision. Secondly, the model incorporates landmark information into expression representations using the devised expression-landmark contrastive loss. The enhanced expression feature extractor can be less susceptible to label noise. Our method can be integrated with any deep neural network for better training supervision without introducing extra inference costs. We conduct extensive experiments on both in-the-wild datasets and synthetic noisy datasets and demonstrate that LA-Net achieves state-of-the-art performance.
Synthetic Cross-language Information Retrieval Training Data
Apr 29, 2023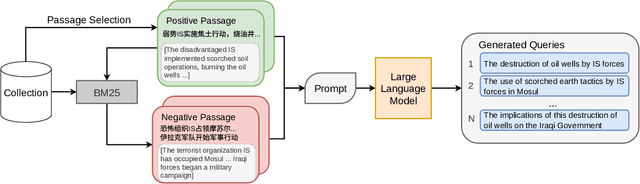
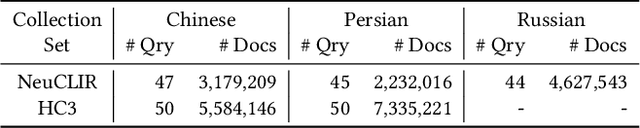
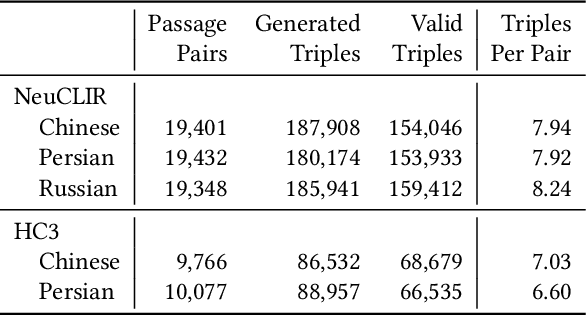

A key stumbling block for neural cross-language information retrieval (CLIR) systems has been the paucity of training data. The appearance of the MS MARCO monolingual training set led to significant advances in the state of the art in neural monolingual retrieval. By translating the MS MARCO documents into other languages using machine translation, this resource has been made useful to the CLIR community. Yet such translation suffers from a number of problems. While MS MARCO is a large resource, it is of fixed size; its genre and domain of discourse are fixed; and the translated documents are not written in the language of a native speaker of the language, but rather in translationese. To address these problems, we introduce the JH-POLO CLIR training set creation methodology. The approach begins by selecting a pair of non-English passages. A generative large language model is then used to produce an English query for which the first passage is relevant and the second passage is not relevant. By repeating this process, collections of arbitrary size can be created in the style of MS MARCO but using naturally-occurring documents in any desired genre and domain of discourse. This paper describes the methodology in detail, shows its use in creating new CLIR training sets, and describes experiments using the newly created training data.
Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
Jul 21, 2023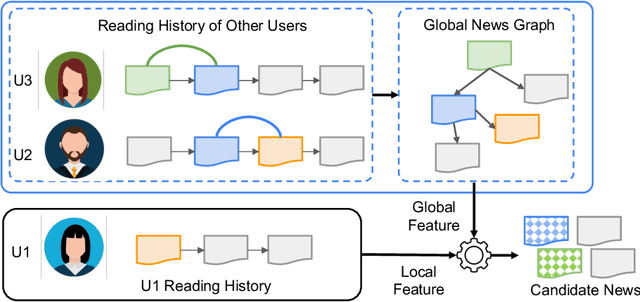
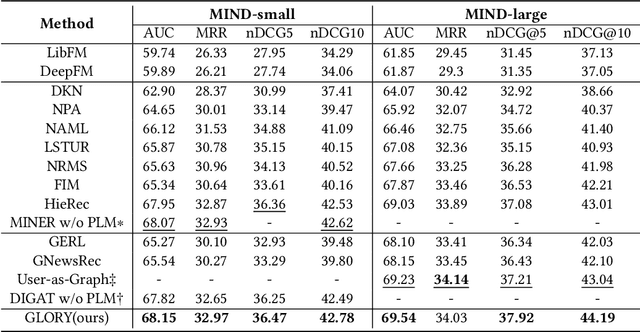
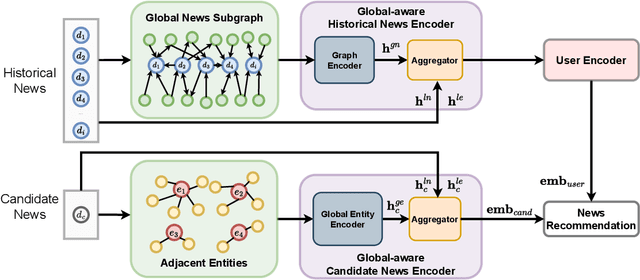
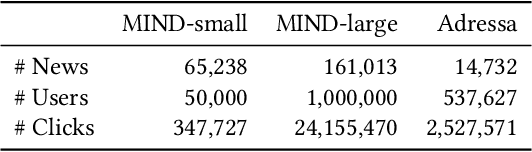
Precisely recommending candidate news articles to users has always been a core challenge for personalized news recommendation systems. Most recent works primarily focus on using advanced natural language processing techniques to extract semantic information from rich textual data, employing content-based methods derived from local historical news. However, this approach lacks a global perspective, failing to account for users' hidden motivations and behaviors beyond semantic information. To address this challenge, we propose a novel model called GLORY (Global-LOcal news Recommendation sYstem), which combines global representations learned from other users with local representations to enhance personalized recommendation systems. We accomplish this by constructing a Global-aware Historical News Encoder, which includes a global news graph and employs gated graph neural networks to enrich news representations, thereby fusing historical news representations by a historical news aggregator. Similarly, we extend this approach to a Global Candidate News Encoder, utilizing a global entity graph and a candidate news aggregator to enhance candidate news representation. Evaluation results on two public news datasets demonstrate that our method outperforms existing approaches. Furthermore, our model offers more diverse recommendations.
VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception
Aug 03, 2023
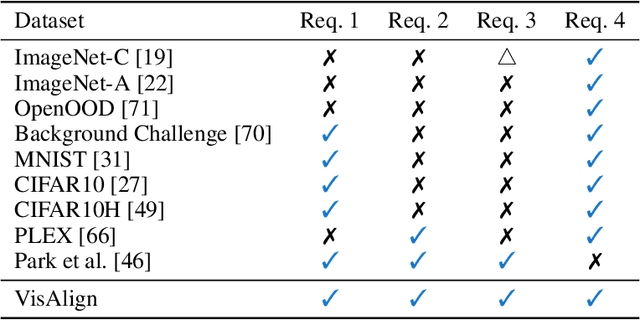
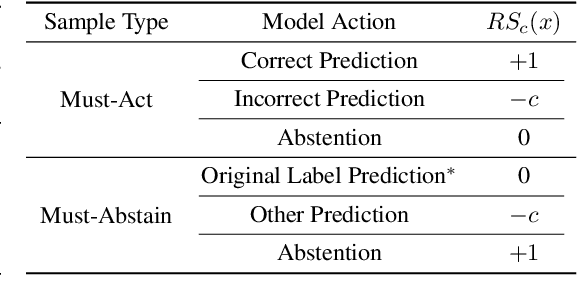

AI alignment refers to models acting towards human-intended goals, preferences, or ethical principles. Given that most large-scale deep learning models act as black boxes and cannot be manually controlled, analyzing the similarity between models and humans can be a proxy measure for ensuring AI safety. In this paper, we focus on the models' visual perception alignment with humans, further referred to as AI-human visual alignment. Specifically, we propose a new dataset for measuring AI-human visual alignment in terms of image classification, a fundamental task in machine perception. In order to evaluate AI-human visual alignment, a dataset should encompass samples with various scenarios that may arise in the real world and have gold human perception labels. Our dataset consists of three groups of samples, namely Must-Act (i.e., Must-Classify), Must-Abstain, and Uncertain, based on the quantity and clarity of visual information in an image and further divided into eight categories. All samples have a gold human perception label; even Uncertain (severely blurry) sample labels were obtained via crowd-sourcing. The validity of our dataset is verified by sampling theory, statistical theories related to survey design, and experts in the related fields. Using our dataset, we analyze the visual alignment and reliability of five popular visual perception models and seven abstention methods. Our code and data is available at \url{https://github.com/jiyounglee-0523/VisAlign}.
Deep Learning with Passive Optical Nonlinear Mapping
Jul 18, 2023Deep learning has fundamentally transformed artificial intelligence, but the ever-increasing complexity in deep learning models calls for specialized hardware accelerators. Optical accelerators can potentially offer enhanced performance, scalability, and energy efficiency. However, achieving nonlinear mapping, a critical component of neural networks, remains challenging optically. Here, we introduce a design that leverages multiple scattering in a reverberating cavity to passively induce optical nonlinear random mapping, without the need for additional laser power. A key advantage emerging from our work is that we show we can perform optical data compression, facilitated by multiple scattering in the cavity, to efficiently compress and retain vital information while also decreasing data dimensionality. This allows rapid optical information processing and generation of low dimensional mixtures of highly nonlinear features. These are particularly useful for applications demanding high-speed analysis and responses such as in edge computing devices. Utilizing rapid optical information processing capabilities, our optical platforms could potentially offer more efficient and real-time processing solutions for a broad range of applications. We demonstrate the efficacy of our design in improving computational performance across tasks, including classification, image reconstruction, key-point detection, and object detection, all achieved through optical data compression combined with a digital decoder. Notably, we observed high performance, at an extreme compression ratio, for real-time pedestrian detection. Our findings pave the way for novel algorithms and architectural designs for optical computing.
Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment for Markup-to-Image Generation
Aug 02, 2023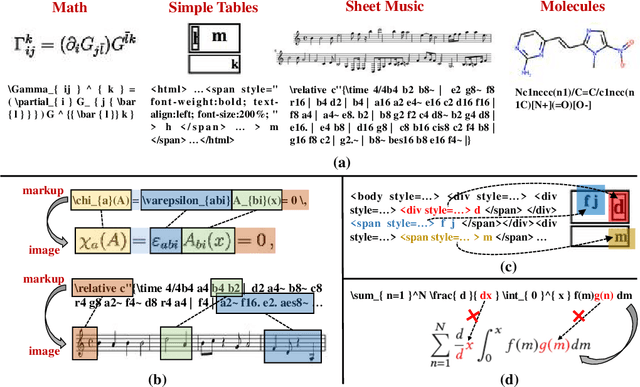
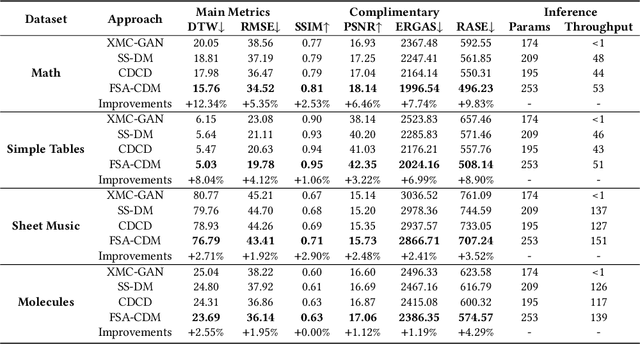
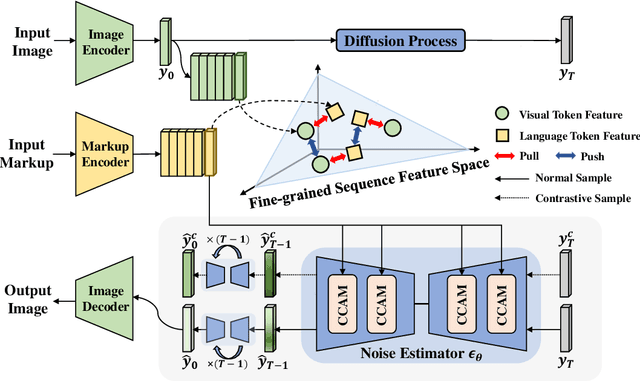
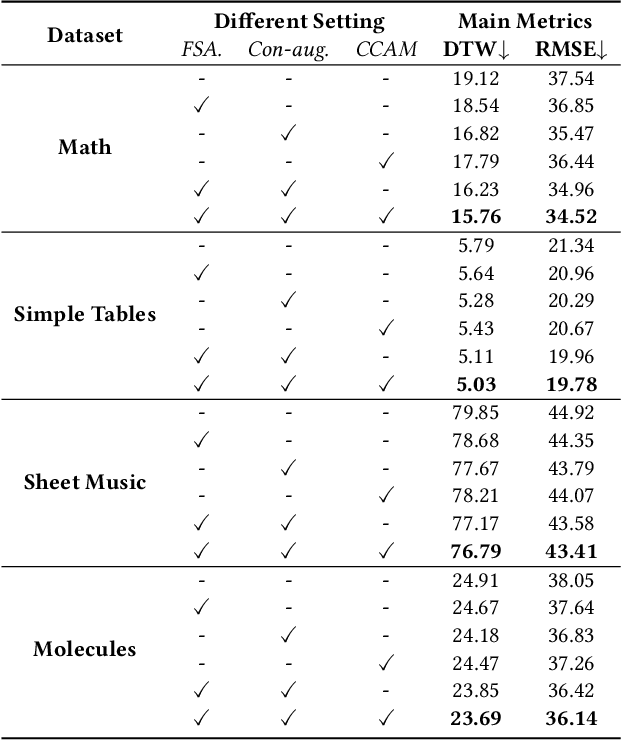
The recently rising markup-to-image generation poses greater challenges as compared to natural image generation, due to its low tolerance for errors as well as the complex sequence and context correlations between markup and rendered image. This paper proposes a novel model named "Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment" (FSA-CDM), which introduces contrastive positive/negative samples into the diffusion model to boost performance for markup-to-image generation. Technically, we design a fine-grained cross-modal alignment module to well explore the sequence similarity between the two modalities for learning robust feature representations. To improve the generalization ability, we propose a contrast-augmented diffusion model to explicitly explore positive and negative samples by maximizing a novel contrastive variational objective, which is mathematically inferred to provide a tighter bound for the model's optimization. Moreover, the context-aware cross attention module is developed to capture the contextual information within markup language during the denoising process, yielding better noise prediction results. Extensive experiments are conducted on four benchmark datasets from different domains, and the experimental results demonstrate the effectiveness of the proposed components in FSA-CDM, significantly exceeding state-of-the-art performance by about 2%-12% DTW improvements. The code will be released at https://github.com/zgj77/FSACDM.