 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond expectations: Residual Dynamic Mode Decomposition and Variance for Stochastic Dynamical Systems
Aug 21, 2023
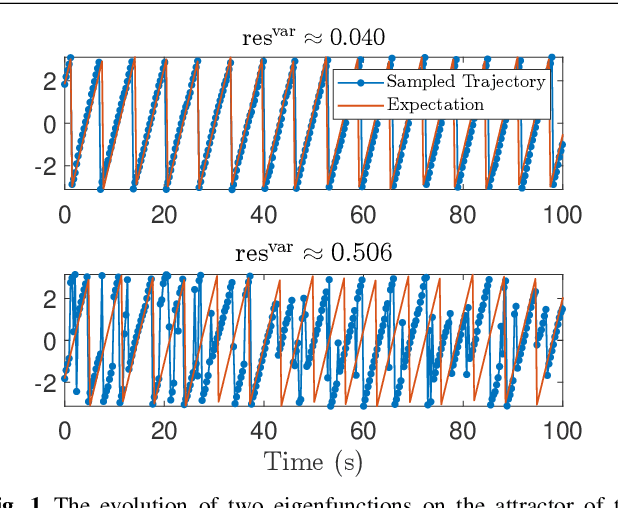
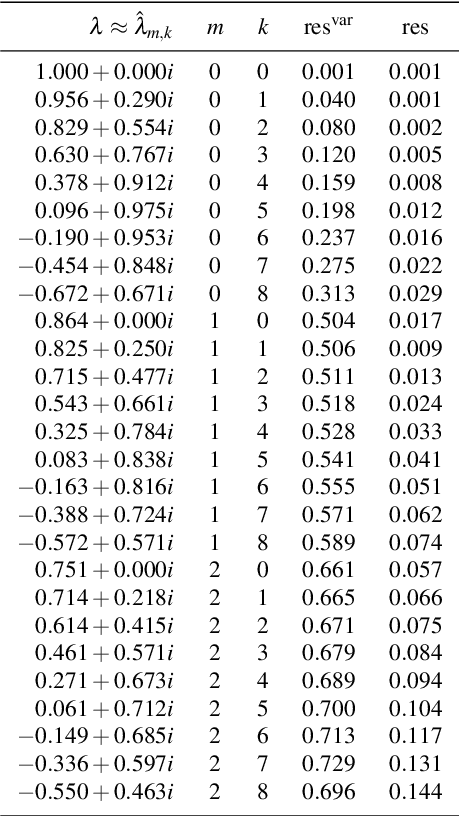
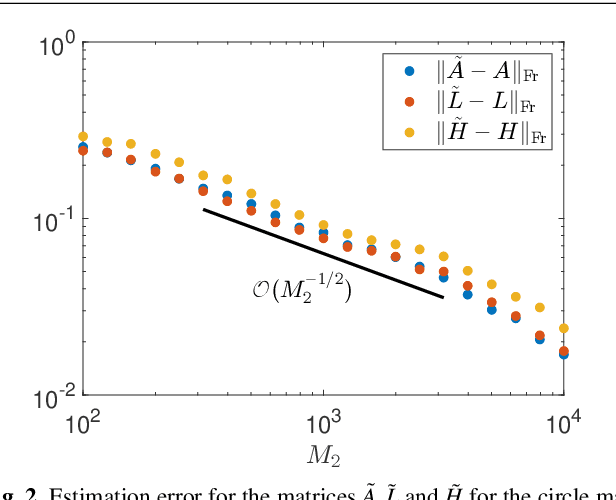
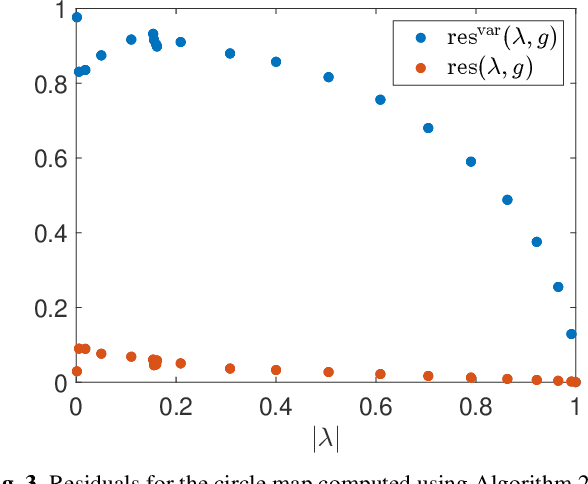
Koopman operators linearize nonlinear dynamical systems, making their spectral information of crucial interest. Numerous algorithms have been developed to approximate these spectral properties, and Dynamic Mode Decomposition (DMD) stands out as the poster child of projection-based methods. Although the Koopman operator itself is linear, the fact that it acts in an infinite-dimensional space of observables poses various challenges. These include spurious modes, essential spectra, and the verification of Koopman mode decompositions. While recent work has addressed these challenges for deterministic systems, there remains a notable gap in verified DMD methods tailored for stochastic systems, where the Koopman operator measures the expectation of observables. We show that it is necessary to go beyond expectations to address these issues. By incorporating variance into the Koopman framework, we address these challenges. Through an additional DMD-type matrix, we approximate the sum of a squared residual and a variance term, each of which can be approximated individually using batched snapshot data. This allows verified computation of the spectral properties of stochastic Koopman operators, controlling the projection error. We also introduce the concept of variance-pseudospectra to gauge statistical coherency. Finally, we present a suite of convergence results for the spectral quantities of stochastic Koopman operators. Our study concludes with practical applications using both simulated and experimental data. In neural recordings from awake mice, we demonstrate how variance-pseudospectra can reveal physiologically significant information unavailable to standard expectation-based dynamical models.
Multimodality Fusion for Smart Healthcare: a Journey from Data, Information, Knowledge to Wisdom
Jun 25, 2023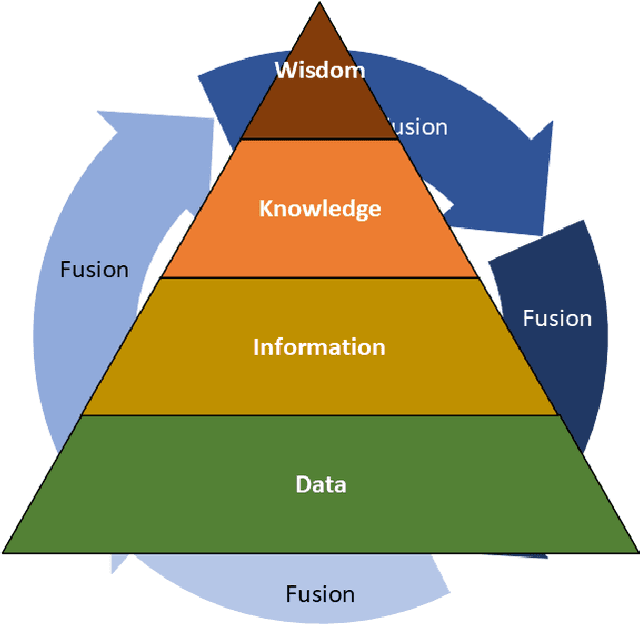
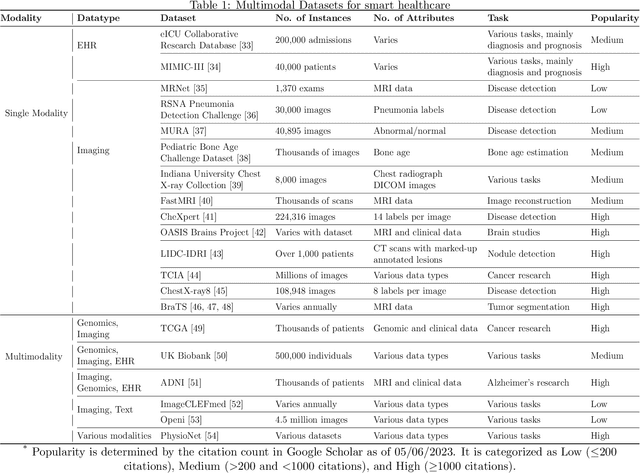
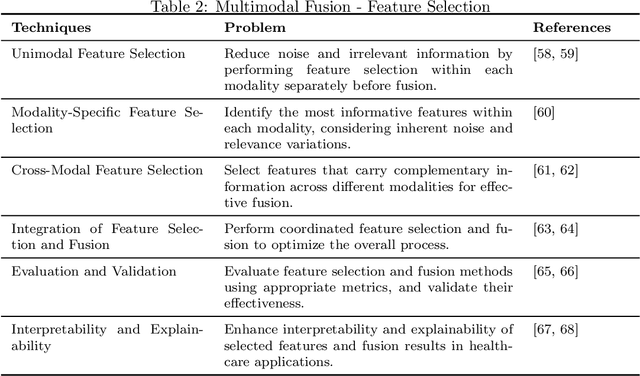
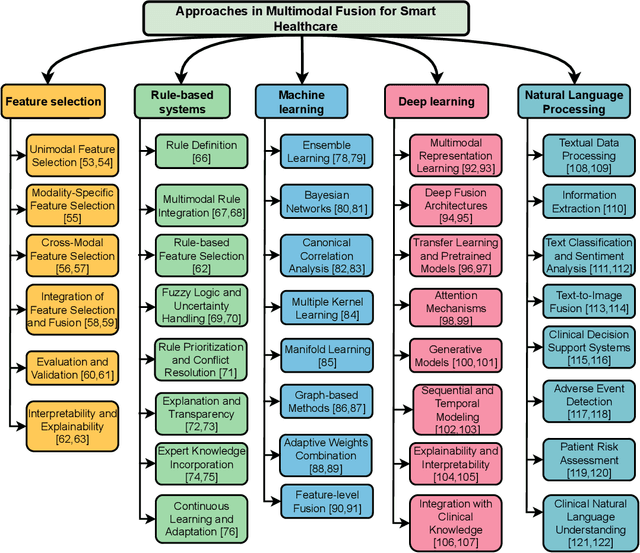
Multimodal medical data fusion has emerged as a transformative approach in smart healthcare, enabling a comprehensive understanding of patient health and personalized treatment plans. In this paper, a journey from data, information, and knowledge to wisdom (DIKW) is explored through multimodal fusion for smart healthcare. A comprehensive review of multimodal medical data fusion focuses on the integration of various data modalities are presented. It explores different approaches such as Feature selection, Rule-based systems, Machine learning, Deep learning, and Natural Language Processing for fusing and analyzing multimodal data. The paper also highlights the challenges associated with multimodal fusion in healthcare. By synthesizing the reviewed frameworks and insights, a generic framework for multimodal medical data fusion is proposed while aligning with the DIKW mechanism. Moreover, it discusses future directions aligned with the four pillars of healthcare: Predictive, Preventive, Personalized, and Participatory approaches based on the DIKW and the generic framework. The components from this comprehensive survey form the foundation for the successful implementation of multimodal fusion in smart healthcare. The findings of this survey can guide researchers and practitioners in leveraging the power of multimodal fusion with the approaches to revolutionize healthcare and improve patient outcomes.
Joint-Relation Transformer for Multi-Person Motion Prediction
Aug 09, 2023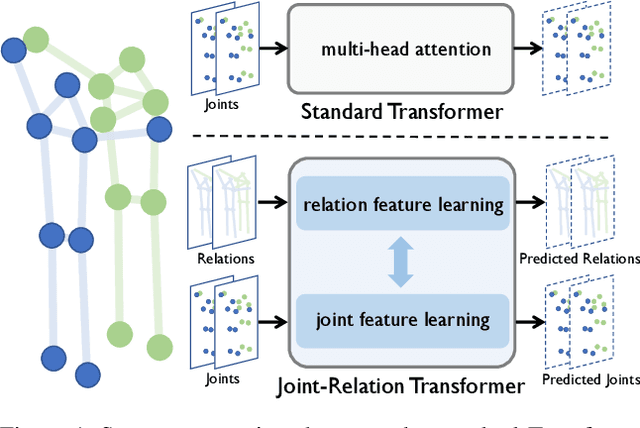
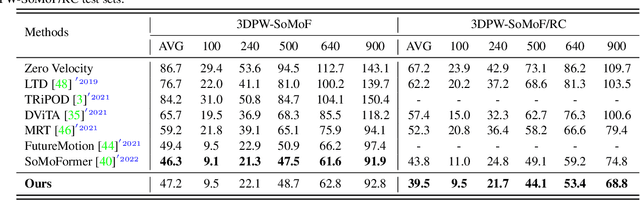
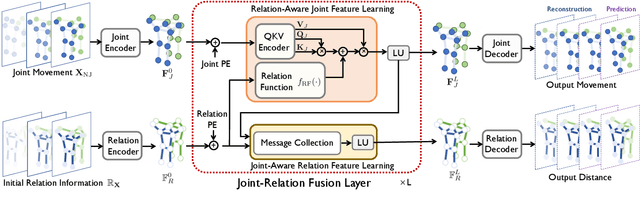
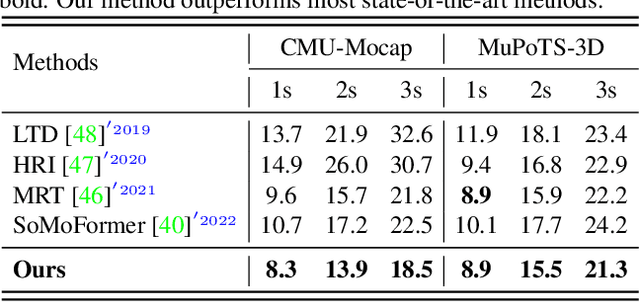
Multi-person motion prediction is a challenging problem due to the dependency of motion on both individual past movements and interactions with other people. Transformer-based methods have shown promising results on this task, but they miss the explicit relation representation between joints, such as skeleton structure and pairwise distance, which is crucial for accurate interaction modeling. In this paper, we propose the Joint-Relation Transformer, which utilizes relation information to enhance interaction modeling and improve future motion prediction. Our relation information contains the relative distance and the intra-/inter-person physical constraints. To fuse relation and joint information, we design a novel joint-relation fusion layer with relation-aware attention to update both features. Additionally, we supervise the relation information by forecasting future distance. Experiments show that our method achieves a 13.4% improvement of 900ms VIM on 3DPW-SoMoF/RC and 17.8%/12.0% improvement of 3s MPJPE on CMU-Mpcap/MuPoTS-3D dataset.
FashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023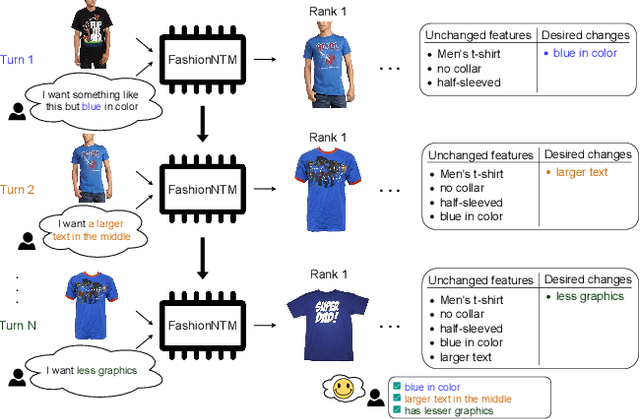
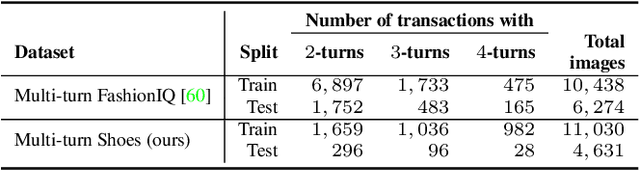
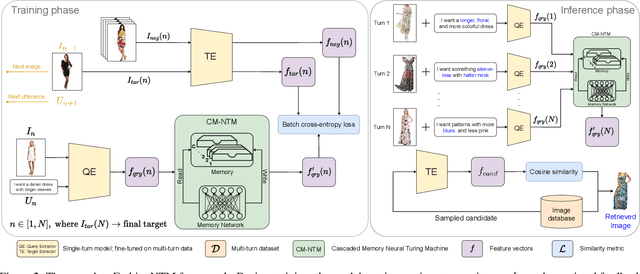
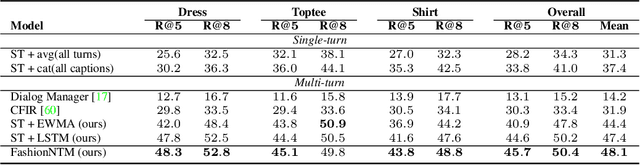
Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
Interactive Design by Integrating a Large Pre-Trained Language Model and Building Information Modeling
Jun 25, 2023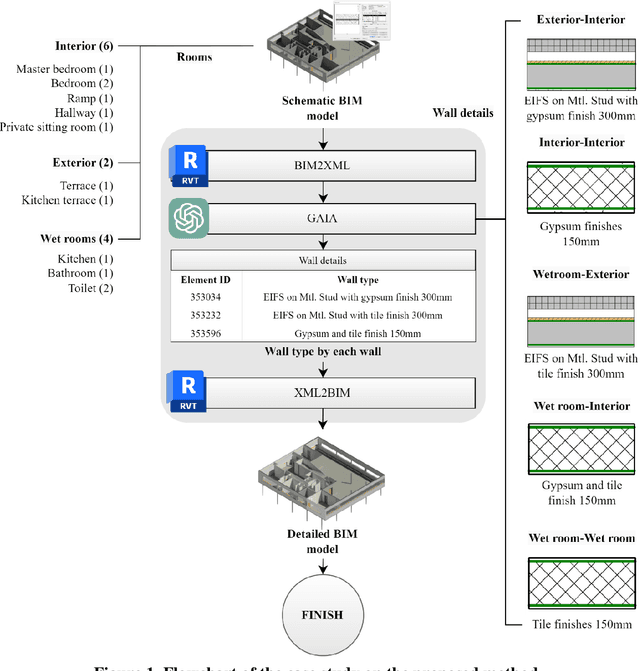

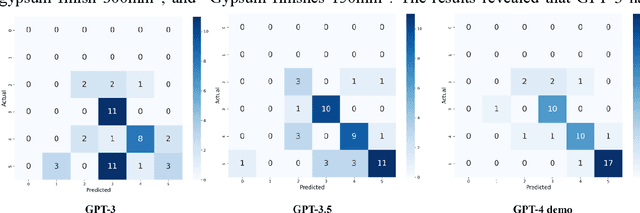
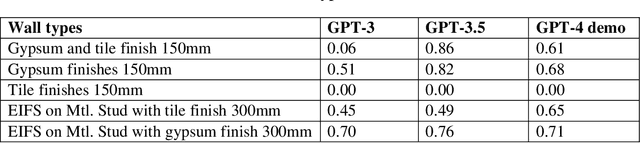
This study explores the potential of generative artificial intelligence (AI) models, specifically OpenAI's generative pre-trained transformer (GPT) series, when integrated with building information modeling (BIM) tools as an interactive design assistant for architectural design. The research involves the development and implementation of three key components: 1) BIM2XML, a component that translates BIM data into extensible markup language (XML) format; 2) Generative AI-enabled Interactive Architectural design (GAIA), a component that refines the input design in XML by identifying designer intent, relevant objects, and their attributes, using pre-trained language models; and 3) XML2BIM, a component that converts AI-generated XML data back into a BIM tool. This study validated the proposed approach through a case study involving design detailing, using the GPT series and Revit. Our findings demonstrate the effectiveness of state-of-the-art language models in facilitating dynamic collaboration between architects and AI systems, highlighting the potential for further advancements.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023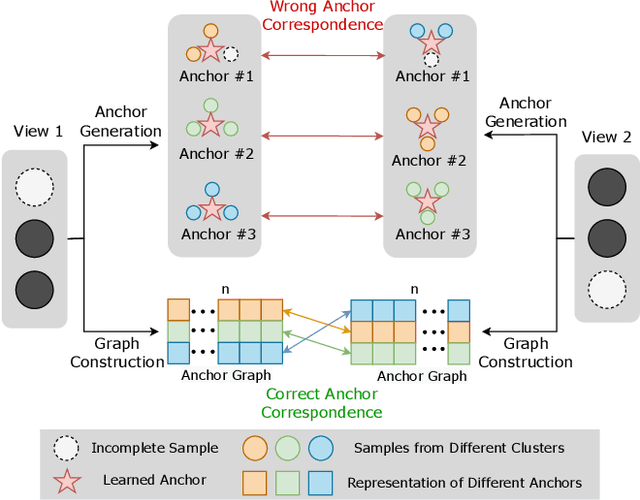
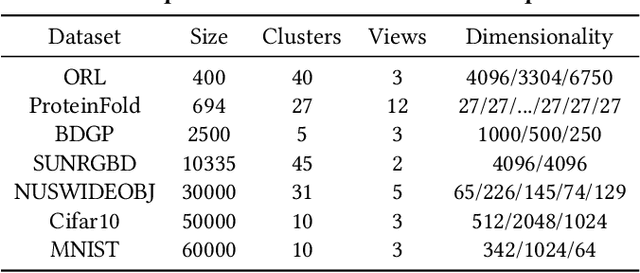
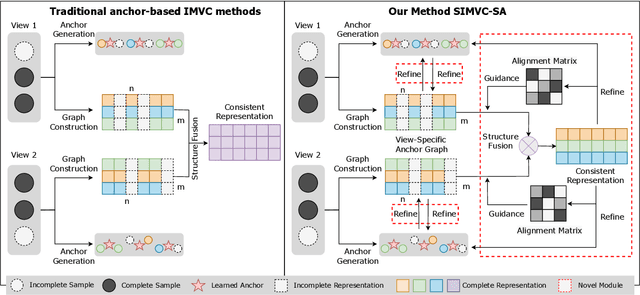
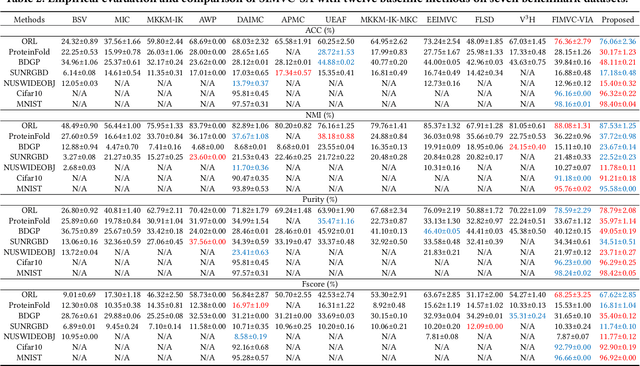
The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
In-class Data Analysis Replications: Teaching Students while Testing Science
Aug 31, 2023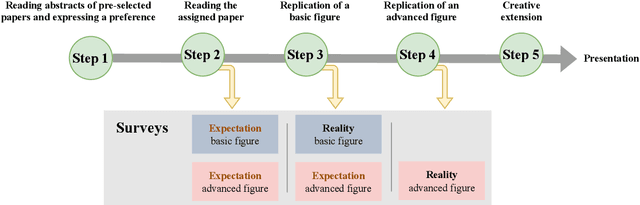

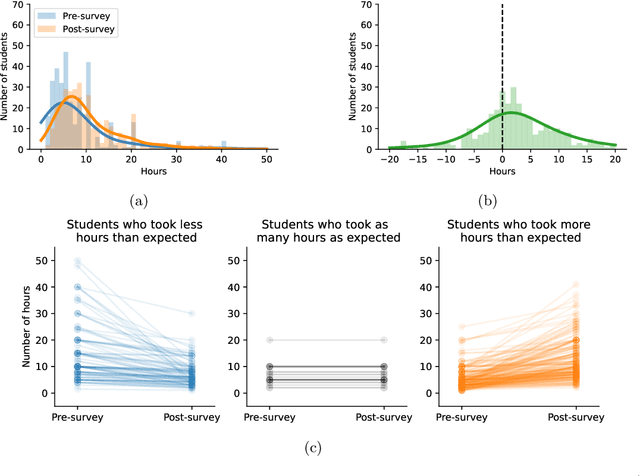
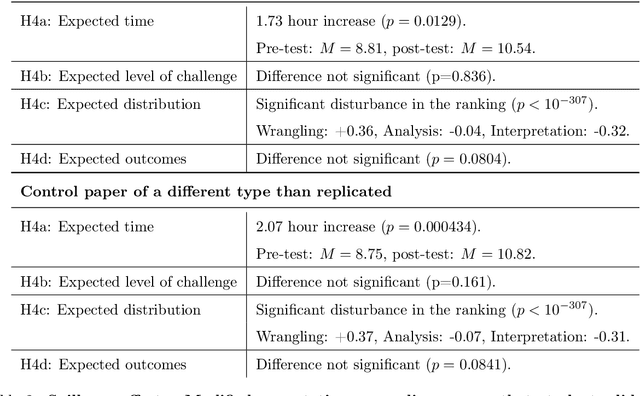
Science is facing a reproducibility crisis. Previous work has proposed incorporating data analysis replications into classrooms as a potential solution. However, despite the potential benefits, it is unclear whether this approach is feasible, and if so, what the involved stakeholders-students, educators, and scientists-should expect from it. Can students perform a data analysis replication over the course of a class? What are the costs and benefits for educators? And how can this solution help benchmark and improve the state of science? In the present study, we incorporated data analysis replications in the project component of the Applied Data Analysis course (CS-401) taught at EPFL (N=354 students). Here we report pre-registered findings based on surveys administered throughout the course. First, we demonstrate that students can replicate previously published scientific papers, most of them qualitatively and some exactly. We find discrepancies between what students expect of data analysis replications and what they experience by doing them along with changes in expectations about reproducibility, which together serve as evidence of attitude shifts to foster students' critical thinking. Second, we provide information for educators about how much overhead is needed to incorporate replications into the classroom and identify concerns that replications bring as compared to more traditional assignments. Third, we identify tangible benefits of the in-class data analysis replications for scientific communities, such as a collection of replication reports and insights about replication barriers in scientific work that should be avoided going forward. Overall, we demonstrate that incorporating replication tasks into a large data science class can increase the reproducibility of scientific work as a by-product of data science instruction, thus benefiting both science and students.
A stochastic block model for community detection in attributed networks
Aug 31, 2023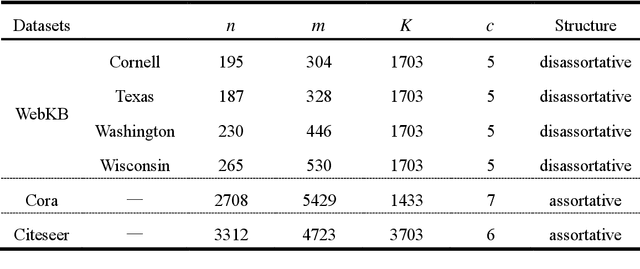
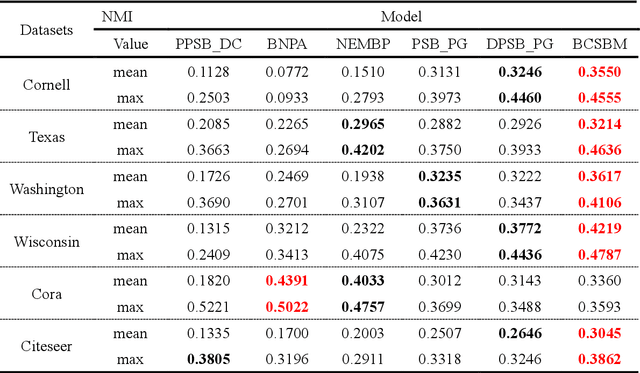
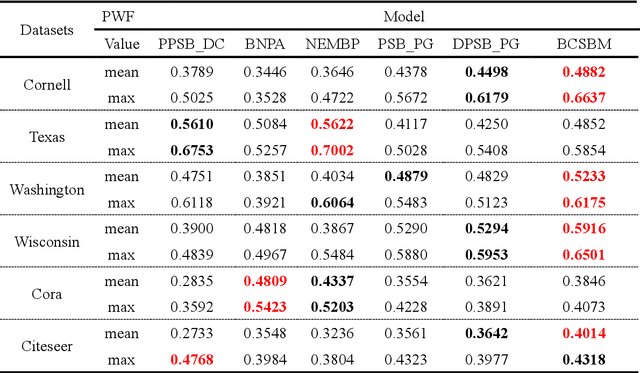
Community detection is an important content in complex network analysis. The existing community detection methods in attributed networks mostly focus on only using network structure, while the methods of integrating node attributes is mainly for the traditional community structures, and cannot detect multipartite structures and mixture structures in network. In addition, the model-based community detection methods currently proposed for attributed networks do not fully consider unique topology information of nodes, such as betweenness centrality and clustering coefficient. Therefore, a stochastic block model that integrates betweenness centrality and clustering coefficient of nodes for community detection in attributed networks, named BCSBM, is proposed in this paper. Different from other generative models for attributed networks, the generation process of links and attributes in BCSBM model follows the Poisson distribution, and the probability between community is considered based on the stochastic block model. Moreover, the betweenness centrality and clustering coefficient of nodes are introduced into the process of links and attributes generation. Finally, the expectation maximization algorithm is employed to estimate the parameters of the BCSBM model, and the node-community memberships is obtained through the hard division process, so the community detection is completed. By experimenting on six real-work networks containing different network structures, and comparing with the community detection results of five algorithms, the experimental results show that the BCSBM model not only inherits the advantages of the stochastic block model and can detect various network structures, but also has good data fitting ability due to introducing the betweenness centrality and clustering coefficient of nodes. Overall, the performance of this model is superior to other five compared algorithms.
Towards Hierarchical Regional Transformer-based Multiple Instance Learning
Aug 24, 2023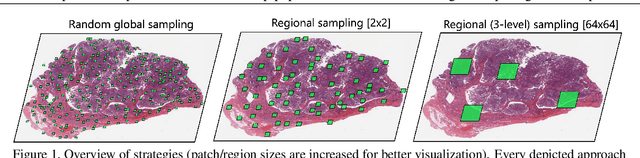
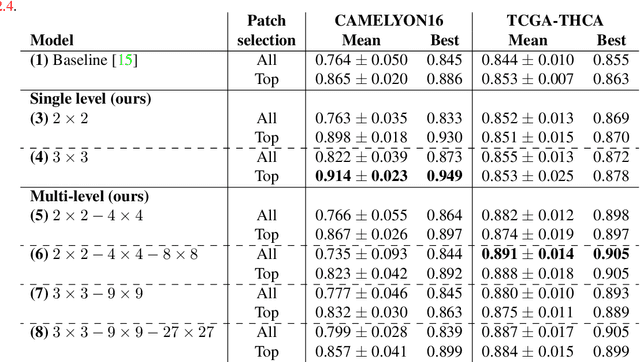
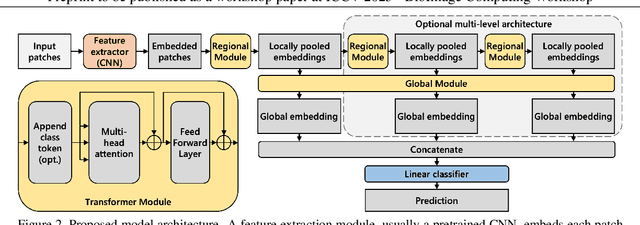
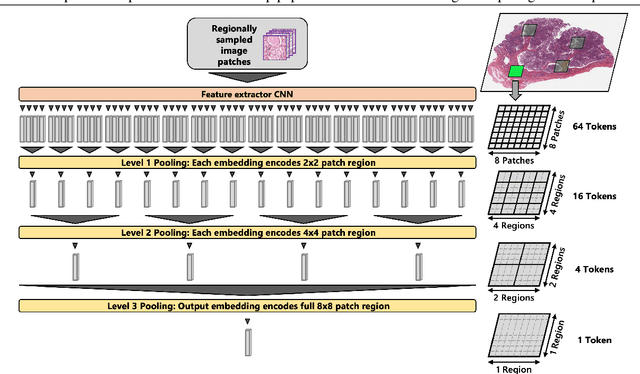
The classification of gigapixel histopathology images with deep multiple instance learning models has become a critical task in digital pathology and precision medicine. In this work, we propose a Transformer-based multiple instance learning approach that replaces the traditional learned attention mechanism with a regional, Vision Transformer inspired self-attention mechanism. We present a method that fuses regional patch information to derive slide-level predictions and show how this regional aggregation can be stacked to hierarchically process features on different distance levels. To increase predictive accuracy, especially for datasets with small, local morphological features, we introduce a method to focus the image processing on high attention regions during inference. Our approach is able to significantly improve performance over the baseline on two histopathology datasets and points towards promising directions for further research.
ARTxAI: Explainable Artificial Intelligence Curates Deep Representation Learning for Artistic Images using Fuzzy Techniques
Aug 29, 2023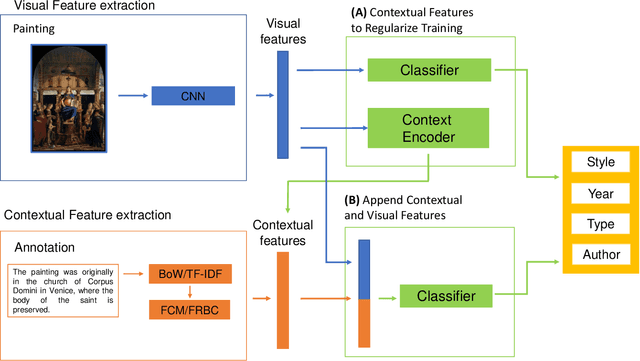
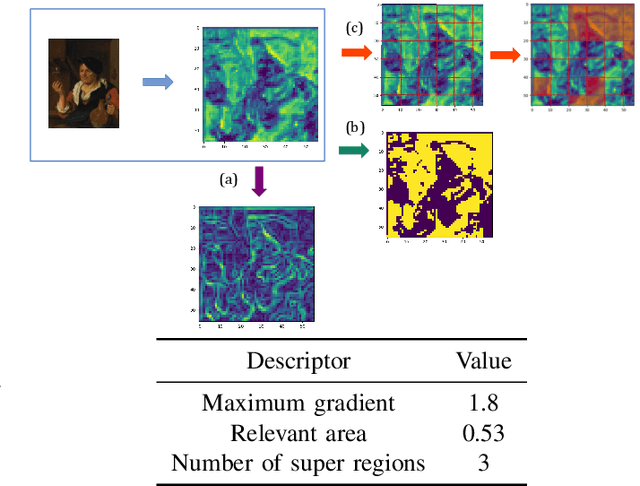
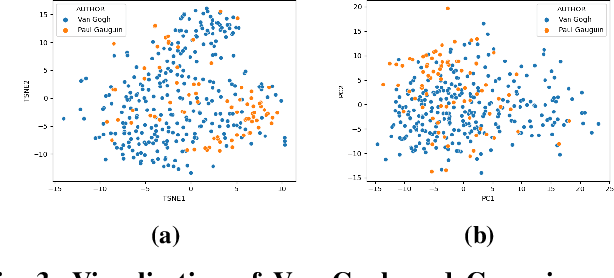

Automatic art analysis employs different image processing techniques to classify and categorize works of art. When working with artistic images, we need to take into account further considerations compared to classical image processing. This is because such artistic paintings change drastically depending on the author, the scene depicted, and their artistic style. This can result in features that perform very well in a given task but do not grasp the whole of the visual and symbolic information contained in a painting. In this paper, we show how the features obtained from different tasks in artistic image classification are suitable to solve other ones of similar nature. We present different methods to improve the generalization capabilities and performance of artistic classification systems. Furthermore, we propose an explainable artificial intelligence method to map known visual traits of an image with the features used by the deep learning model considering fuzzy rules. These rules show the patterns and variables that are relevant to solve each task and how effective is each of the patterns found. Our results show that our proposed context-aware features can achieve up to $6\%$ and $26\%$ more accurate results than other context- and non-context-aware solutions, respectively, depending on the specific task. We also show that some of the features used by these models can be more clearly correlated to visual traits in the original image than others.