 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EDDense-Net: Fully Dense Encoder Decoder Network for Joint Segmentation of Optic Cup and Disc
Aug 20, 2023
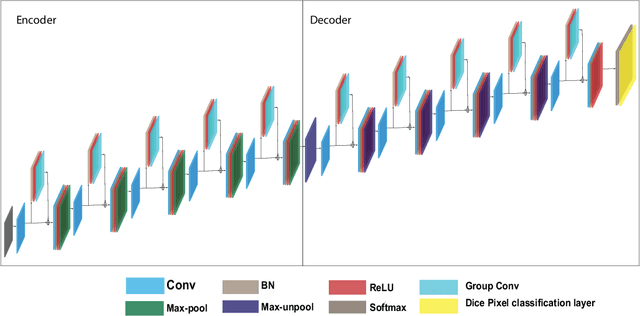
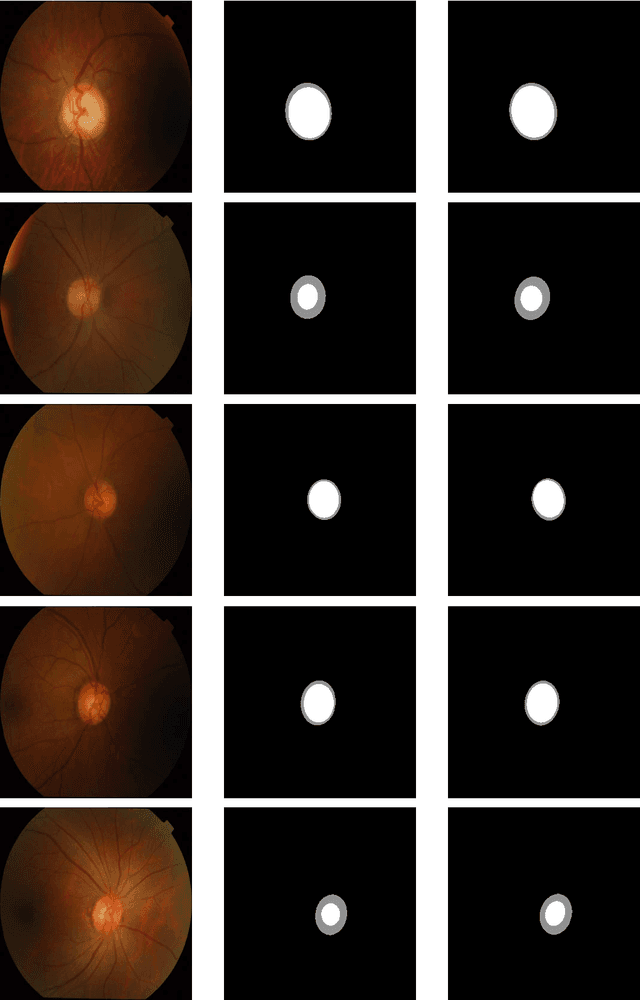
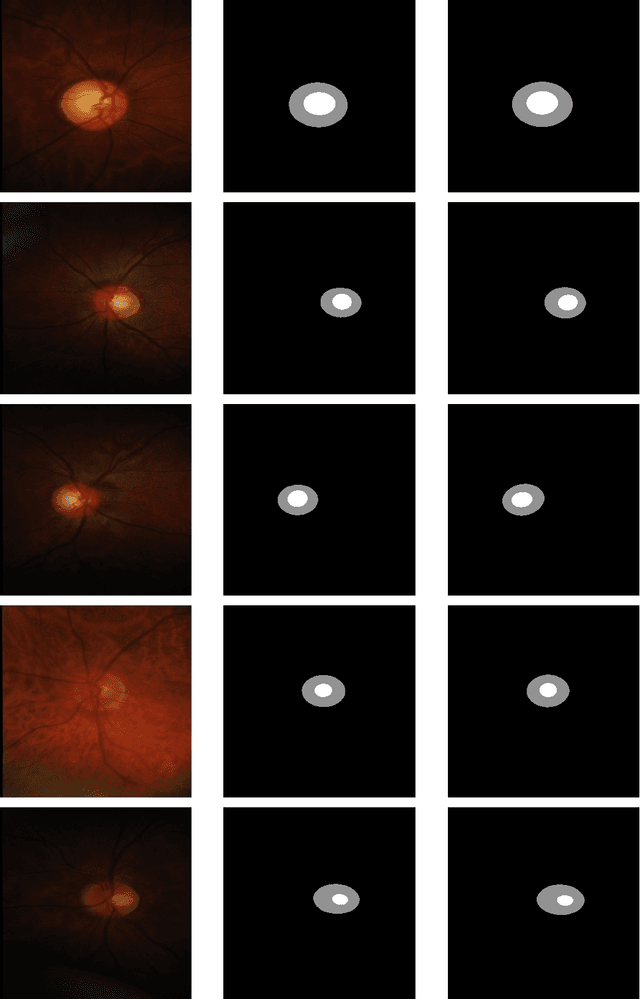
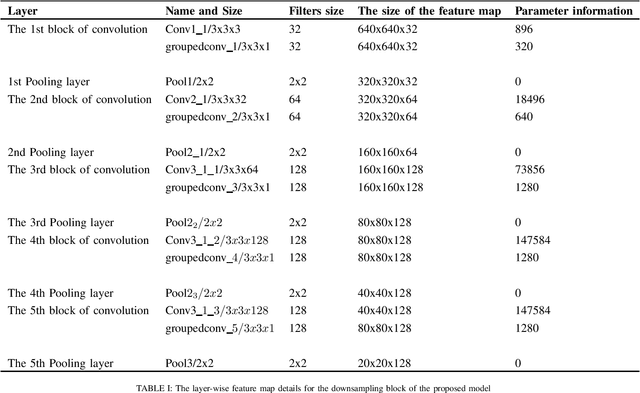
Glaucoma is an eye disease that causes damage to the optic nerve, which can lead to visual loss and permanent blindness. Early glaucoma detection is therefore critical in order to avoid permanent blindness. The estimation of the cup-to-disc ratio (CDR) during an examination of the optical disc (OD) is used for the diagnosis of glaucoma. In this paper, we present the EDDense-Net segmentation network for the joint segmentation of OC and OD. The encoder and decoder in this network are made up of dense blocks with a grouped convolutional layer in each block, allowing the network to acquire and convey spatial information from the image while simultaneously reducing the network's complexity. To reduce spatial information loss, the optimal number of filters in all convolution layers were utilised. In semantic segmentation, dice pixel classification is employed in the decoder to alleviate the problem of class imbalance. The proposed network was evaluated on two publicly available datasets where it outperformed existing state-of-the-art methods in terms of accuracy and efficiency. For the diagnosis and analysis of glaucoma, this method can be used as a second opinion system to assist medical ophthalmologists.
Spatio-temporal MLP-graph network for 3D human pose estimation
Aug 29, 2023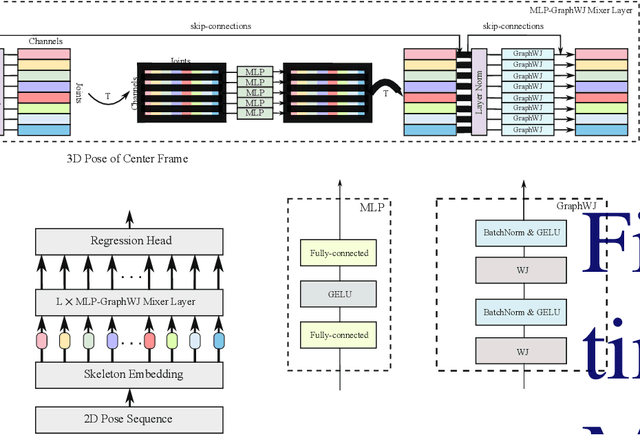
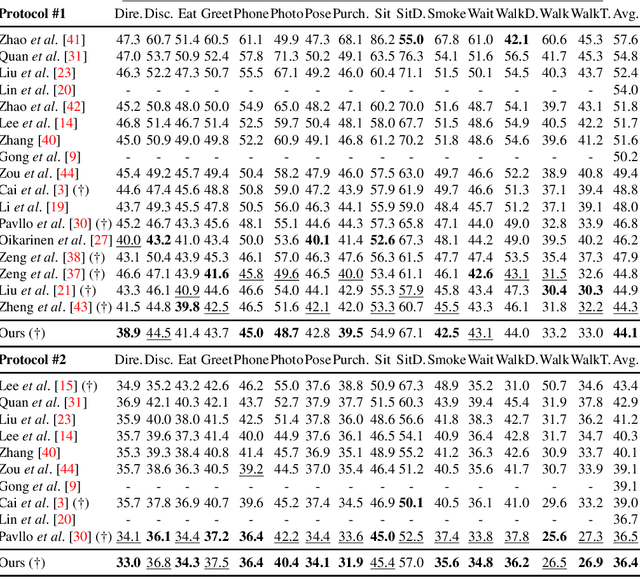
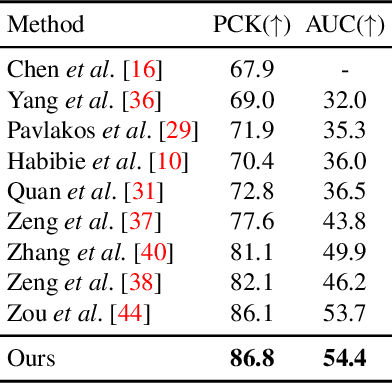
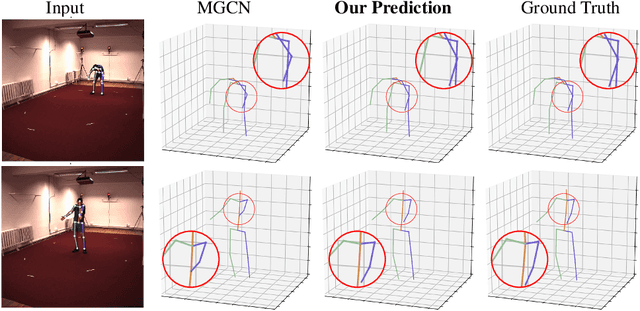
Graph convolutional networks and their variants have shown significant promise in 3D human pose estimation. Despite their success, most of these methods only consider spatial correlations between body joints and do not take into account temporal correlations, thereby limiting their ability to capture relationships in the presence of occlusions and inherent ambiguity. To address this potential weakness, we propose a spatio-temporal network architecture composed of a joint-mixing multi-layer perceptron block that facilitates communication among different joints and a graph weighted Jacobi network block that enables communication among various feature channels. The major novelty of our approach lies in a new weighted Jacobi feature propagation rule obtained through graph filtering with implicit fairing. We leverage temporal information from the 2D pose sequences, and integrate weight modulation into the model to enable untangling of the feature transformations of distinct nodes. We also employ adjacency modulation with the aim of learning meaningful correlations beyond defined linkages between body joints by altering the graph topology through a learnable modulation matrix. Extensive experiments on two benchmark datasets demonstrate the effectiveness of our model, outperforming recent state-of-the-art methods for 3D human pose estimation.
Robust Transceiver Design for Covert Integrated Sensing and Communications With Imperfect CSI
Aug 29, 2023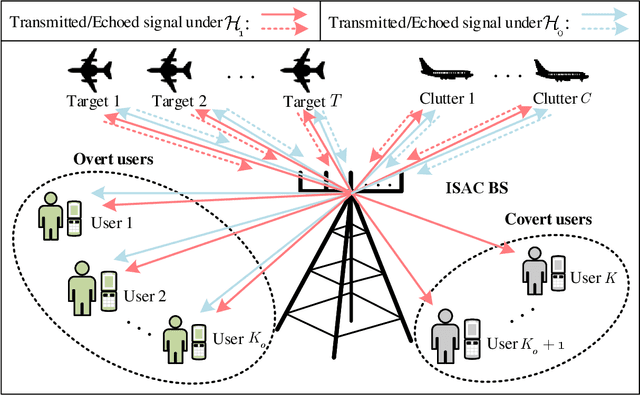
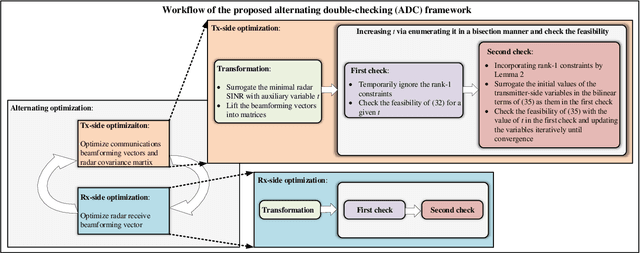
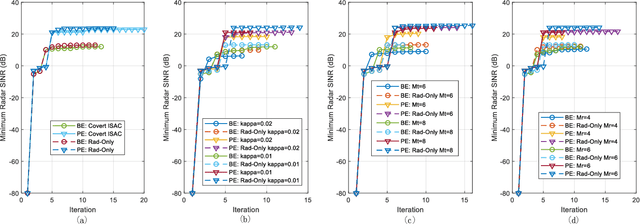
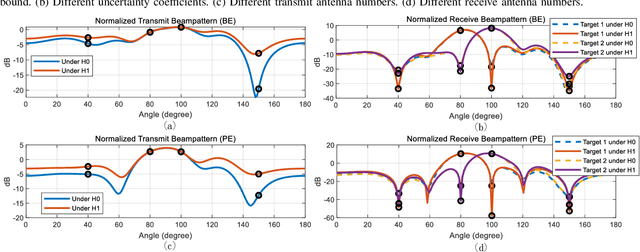
We propose a robust transceiver design for a covert integrated sensing and communications (ISAC) system with imperfect channel state information (CSI). Considering both bounded and probabilistic CSI error models, we formulate worst-case and outage-constrained robust optimization problems of joint trasceiver beamforming and radar waveform design to balance the radar performance of multiple targets while ensuring communications performance and covertness of the system. The optimization problems are challenging due to the non-convexity arising from the semi-infinite constraints (SICs) and the coupled transceiver variables. In an effort to tackle the former difficulty, S-procedure and Bernstein-type inequality are introduced for converting the SICs into finite convex linear matrix inequalities (LMIs) and second-order cone constraints. A robust alternating optimization framework referred to alternating double-checking is developed for decoupling the transceiver design problem into feasibility-checking transmitter- and receiver-side subproblems, transforming the rank-one constraints into a set of LMIs, and verifying the feasibility of beamforming by invoking the matrix-lifting scheme. Numerical results are provided to demonstrate the effectiveness and robustness of the proposed algorithm in improving the performance of covert ISAC systems.
LAMBO: Large Language Model Empowered Edge Intelligence
Aug 29, 2023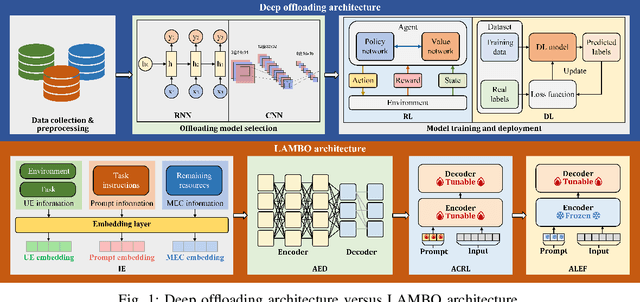
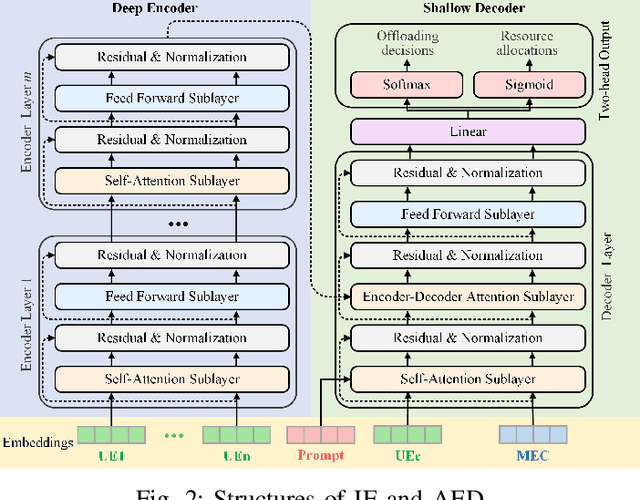
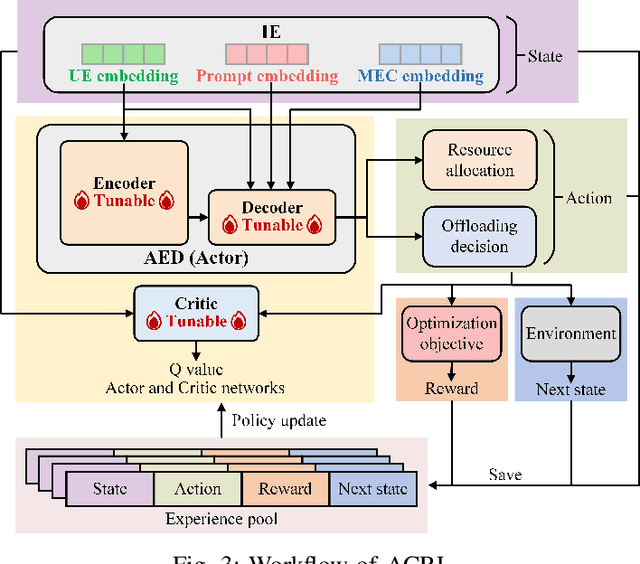
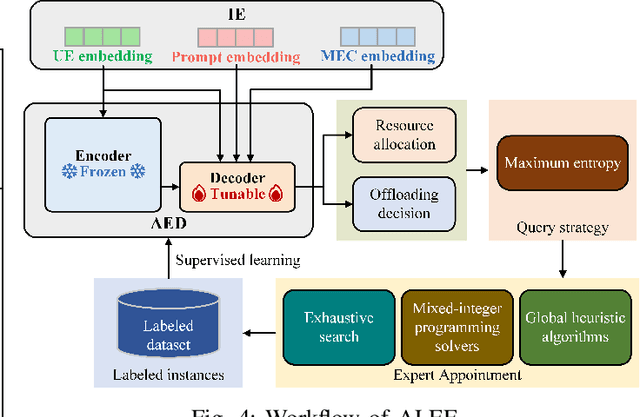
Next-generation edge intelligence is anticipated to bring huge benefits to various applications, e.g., offloading systems. However, traditional deep offloading architectures face several issues, including heterogeneous constraints, partial perception, uncertain generalization, and lack of tractability. In this context, the integration of offloading with large language models (LLMs) presents numerous advantages. Therefore, we propose an LLM-Based Offloading (LAMBO) framework for mobile edge computing (MEC), which comprises four components: (i) Input embedding (IE), which is used to represent the information of the offloading system with constraints and prompts through learnable vectors with high quality; (ii) Asymmetric encoderdecoder (AED) model, which is a decision-making module with a deep encoder and a shallow decoder. It can achieve high performance based on multi-head self-attention schemes; (iii) Actor-critic reinforcement learning (ACRL) module, which is employed to pre-train the whole AED for different optimization tasks under corresponding prompts; and (iv) Active learning from expert feedback (ALEF), which can be used to finetune the decoder part of the AED while adapting to dynamic environmental changes. Our simulation results corroborate the advantages of the proposed LAMBO framework.
When Do Program-of-Thoughts Work for Reasoning?
Aug 29, 2023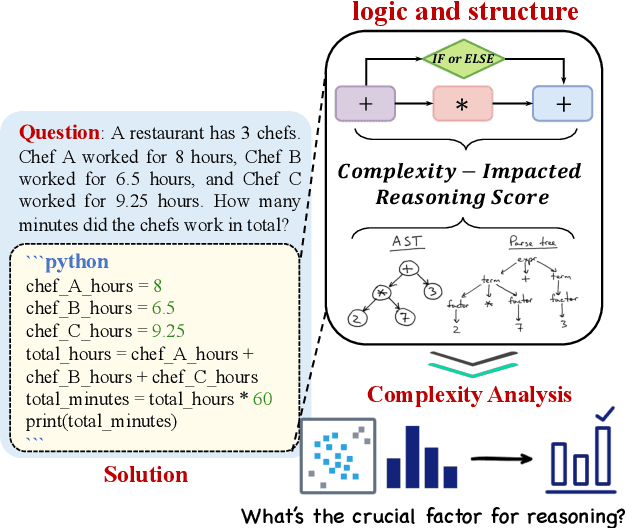
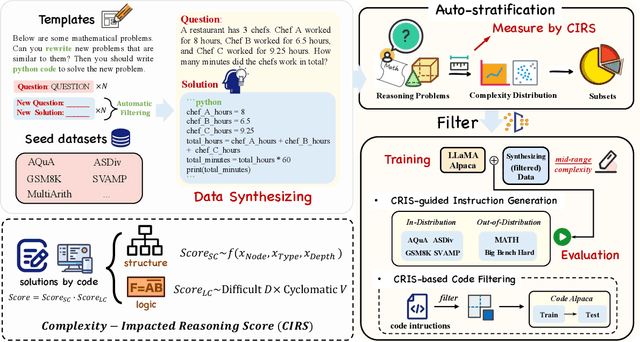
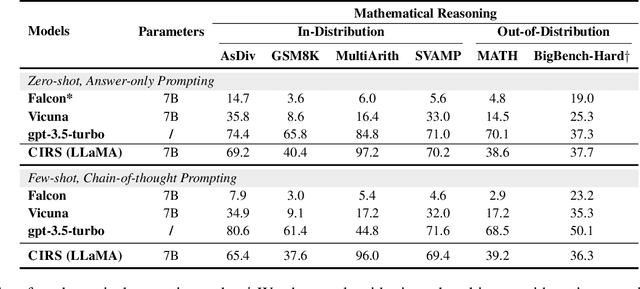
The reasoning capabilities of Large Language Models (LLMs) play a pivotal role in the realm of embodied artificial intelligence. Although there are effective methods like program-of-thought prompting for LLMs which uses programming language to tackle complex reasoning tasks, the specific impact of code data on the improvement of reasoning capabilities remains under-explored. To address this gap, we propose complexity-impacted reasoning score (CIRS), which combines structural and logical attributes, to measure the correlation between code and reasoning abilities. Specifically, we use the abstract syntax tree to encode the structural information and calculate logical complexity by considering the difficulty and the cyclomatic complexity. Through an empirical analysis, we find not all code data of complexity can be learned or understood by LLMs. Optimal level of complexity is critical to the improvement of reasoning abilities by program-aided prompting. Then we design an auto-synthesizing and stratifying algorithm, and apply it to instruction generation for mathematical reasoning and code data filtering for code generation tasks. Extensive results demonstrates the effectiveness of our proposed approach. Code will be integrated into the EasyInstruct framework at https://github.com/zjunlp/EasyInstruct.
Learning Bayesian Networks with Heterogeneous Agronomic Data Sets via Mixed-Effect Models and Hierarchical Clustering
Aug 29, 2023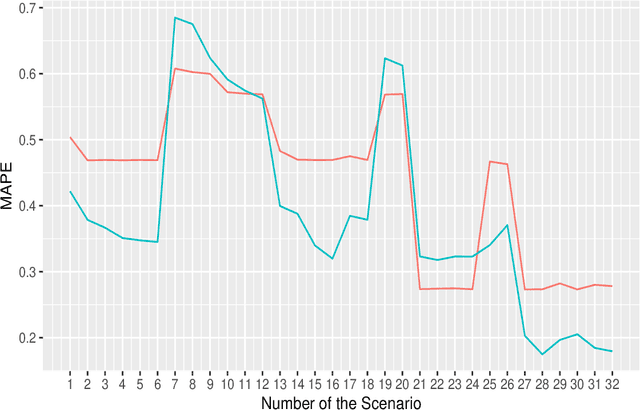
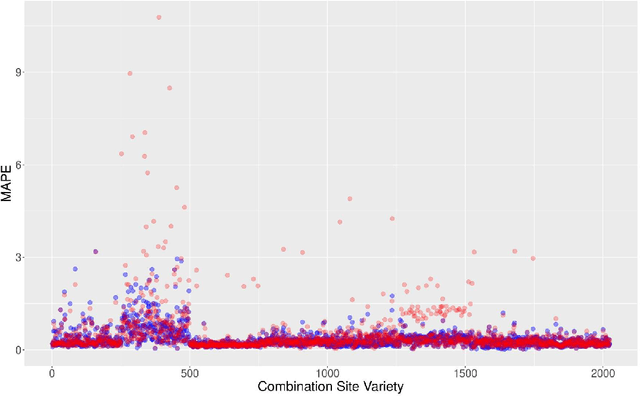
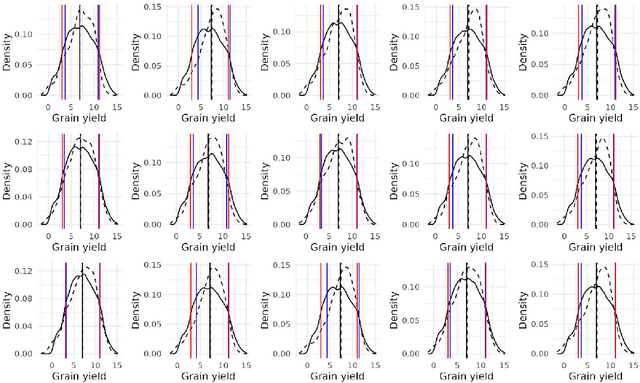
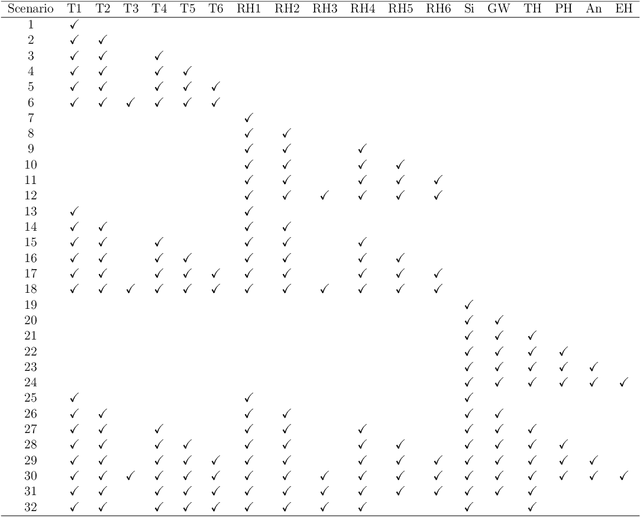
Research involving diverse but related data sets, where associations between covariates and outcomes may vary, is prevalent in various fields including agronomic studies. In these scenarios, hierarchical models, also known as multilevel models, are frequently employed to assimilate information from different data sets while accommodating their distinct characteristics. However, their structure extend beyond simple heterogeneity, as variables often form complex networks of causal relationships. Bayesian networks (BNs) provide a powerful framework for modelling such relationships using directed acyclic graphs to illustrate the connections between variables. This study introduces a novel approach that integrates random effects into BN learning. Rooted in linear mixed-effects models, this approach is particularly well-suited for handling hierarchical data. Results from a real-world agronomic trial suggest that employing this approach enhances structural learning, leading to the discovery of new connections and the improvement of improved model specification. Furthermore, we observe a reduction in prediction errors from 28% to 17%. By extending the applicability of BNs to complex data set structures, this approach contributes to the effective utilisation of BNs for hierarchical agronomic data. This, in turn, enhances their value as decision-support tools in the field.
Distribution-Aligned Diffusion for Human Mesh Recovery
Aug 25, 2023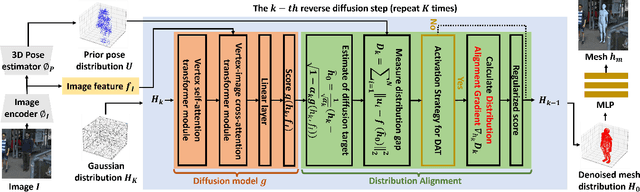
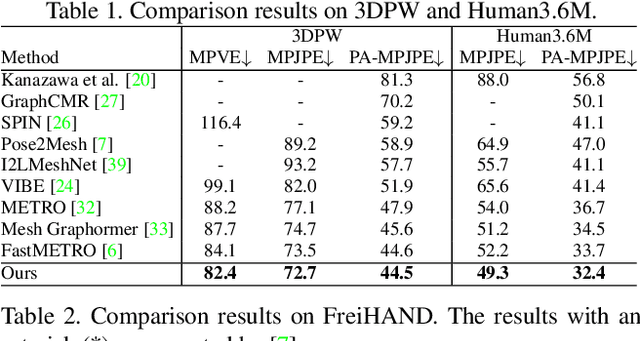
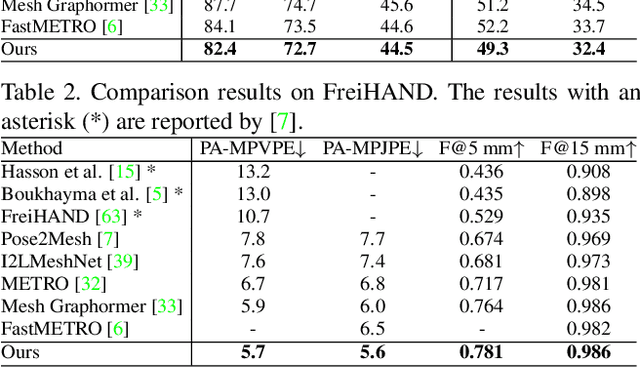

Recovering a 3D human mesh from a single RGB image is a challenging task due to depth ambiguity and self-occlusion, resulting in a high degree of uncertainty. Meanwhile, diffusion models have recently seen much success in generating high-quality outputs by progressively denoising noisy inputs. Inspired by their capability, we explore a diffusion-based approach for human mesh recovery, and propose a Human Mesh Diffusion (HMDiff) framework which frames mesh recovery as a reverse diffusion process. We also propose a Distribution Alignment Technique (DAT) that injects input-specific distribution information into the diffusion process, and provides useful prior knowledge to simplify the mesh recovery task. Our method achieves state-of-the-art performance on three widely used datasets. Project page: https://gongjia0208.github.io/HMDiff/.
Multi-scale Promoted Self-adjusting Correlation Learning for Facial Action Unit Detection
Aug 15, 2023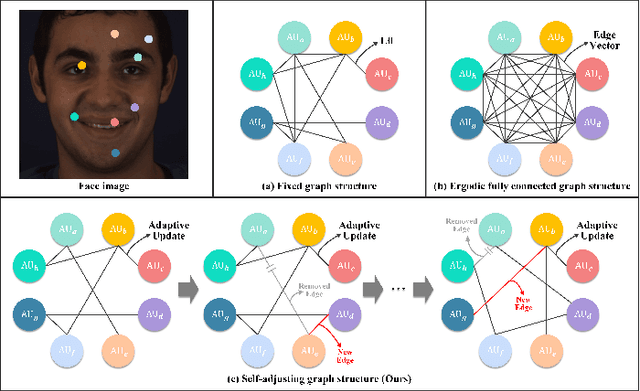
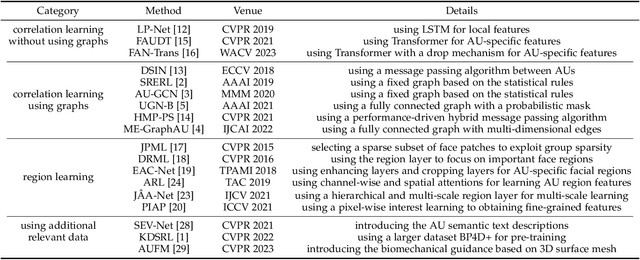
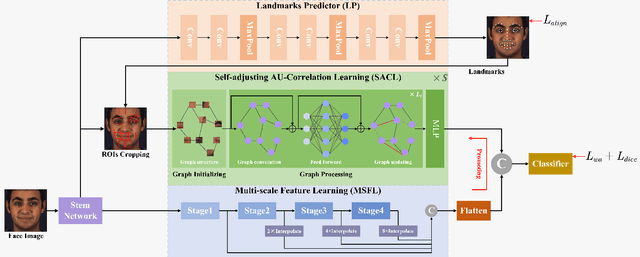
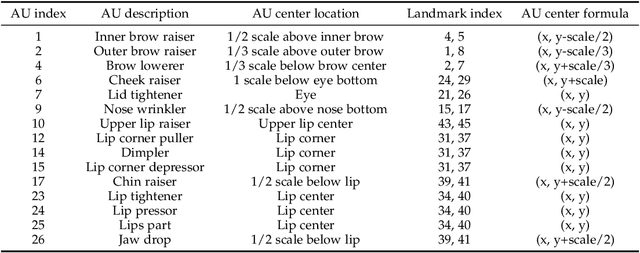
Facial Action Unit (AU) detection is a crucial task in affective computing and social robotics as it helps to identify emotions expressed through facial expressions. Anatomically, there are innumerable correlations between AUs, which contain rich information and are vital for AU detection. Previous methods used fixed AU correlations based on expert experience or statistical rules on specific benchmarks, but it is challenging to comprehensively reflect complex correlations between AUs via hand-crafted settings. There are alternative methods that employ a fully connected graph to learn these dependencies exhaustively. However, these approaches can result in a computational explosion and high dependency with a large dataset. To address these challenges, this paper proposes a novel self-adjusting AU-correlation learning (SACL) method with less computation for AU detection. This method adaptively learns and updates AU correlation graphs by efficiently leveraging the characteristics of different levels of AU motion and emotion representation information extracted in different stages of the network. Moreover, this paper explores the role of multi-scale learning in correlation information extraction, and design a simple yet effective multi-scale feature learning (MSFL) method to promote better performance in AU detection. By integrating AU correlation information with multi-scale features, the proposed method obtains a more robust feature representation for the final AU detection. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on widely used AU detection benchmark datasets, with only 28.7\% and 12.0\% of the parameters and FLOPs of the best method, respectively. The code for this method is available at \url{https://github.com/linuxsino/Self-adjusting-AU}.
LinkTransformer: A Unified Package for Record Linkage with Transformer Language Models
Sep 02, 2023Linking information across sources is fundamental to a variety of analyses in social science, business, and government. While large language models (LLMs) offer enormous promise for improving record linkage in noisy datasets, in many domains approximate string matching packages in popular softwares such as R and Stata remain predominant. These packages have clean, simple interfaces and can be easily extended to a diversity of languages. Our open-source package LinkTransformer aims to extend the familiarity and ease-of-use of popular string matching methods to deep learning. It is a general purpose package for record linkage with transformer LLMs that treats record linkage as a text retrieval problem. At its core is an off-the-shelf toolkit for applying transformer models to record linkage with four lines of code. LinkTransformer contains a rich repository of pre-trained transformer semantic similarity models for multiple languages and supports easy integration of any transformer language model from Hugging Face or OpenAI. It supports standard functionality such as blocking and linking on multiple noisy fields. LinkTransformer APIs also perform other common text data processing tasks, e.g., aggregation, noisy de-duplication, and translation-free cross-lingual linkage. Importantly, LinkTransformer also contains comprehensive tools for efficient model tuning, to facilitate different levels of customization when off-the-shelf models do not provide the required accuracy. Finally, to promote reusability, reproducibility, and extensibility, LinkTransformer makes it easy for users to contribute their custom-trained models to its model hub. By combining transformer language models with intuitive APIs that will be familiar to many users of popular string matching packages, LinkTransformer aims to democratize the benefits of LLMs among those who may be less familiar with deep learning frameworks.
R-C-P Method: An Autonomous Volume Calculation Method Using Image Processing and Machine Vision
Aug 19, 2023
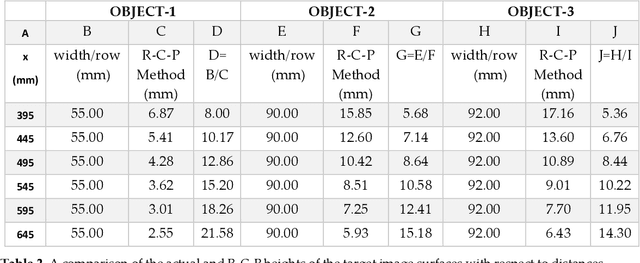

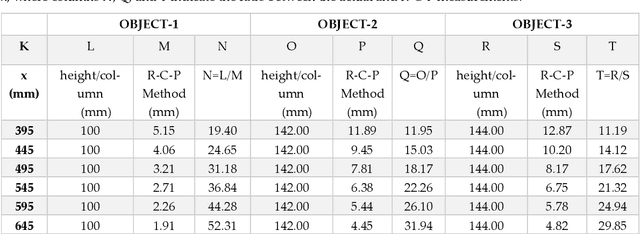
Machine vision and image processing are often used with sensors for situation awareness in autonomous systems, from industrial robots to self-driving cars. The 3D depth sensors, such as LiDAR (Light Detection and Ranging), Radar, are great invention for autonomous systems. Due to the complexity of the setup, LiDAR may not be suitable for some operational environments, for example, a space environment. This study was motivated by a desire to get real-time volumetric and change information with multiple 2D cameras instead of a depth camera. Two cameras were used to measure the dimensions of a rectangular object in real-time. The R-C-P (row-column-pixel) method is developed using image processing and edge detection. In addition to the surface areas, the R-C-P method also detects discontinuous edges or volumes. Lastly, experimental work is presented for illustration of the R-C-P method, which provides the equations for calculating surface area dimensions. Using the equations with given distance information between the object and the camera, the vision system provides the dimensions of actual objects.