 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CVNN-based Channel Estimation and Equalization in OFDM Systems Without Cyclic Prefix
Aug 25, 2023
In modern communication systems operating with Orthogonal Frequency-Division Multiplexing (OFDM), channel estimation requires minimal complexity with one-tap equalizers. However, this depends on cyclic prefixes, which must be sufficiently large to cover the channel impulse response. Conversely, the use of cyclic prefix (CP) decreases the useful information that can be conveyed in an OFDM frame, thereby degrading the spectral efficiency of the system. In this context, we study the impact of CPs on channel estimation with complex-valued neural networks (CVNNs). We show that the phase-transmittance radial basis function neural network offers superior results, in terms of required energy per bit, compared to classical minimum mean-squared error and least squares algorithms in scenarios without CP.
Leveraging Knowledge and Reinforcement Learning for Enhanced Reliability of Language Models
Aug 25, 2023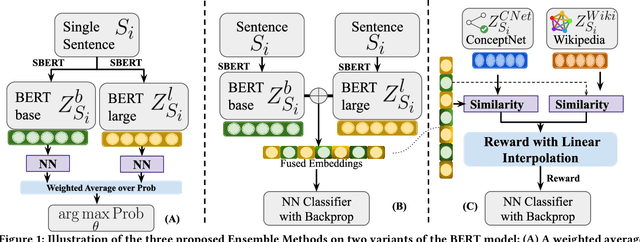
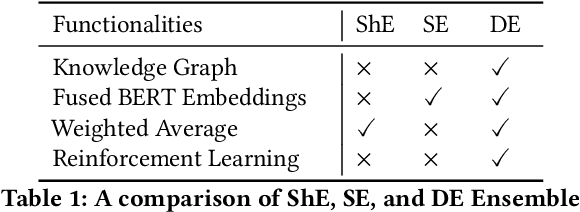
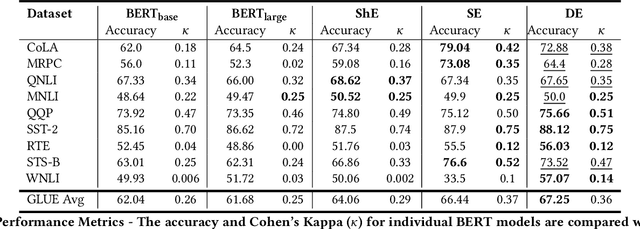
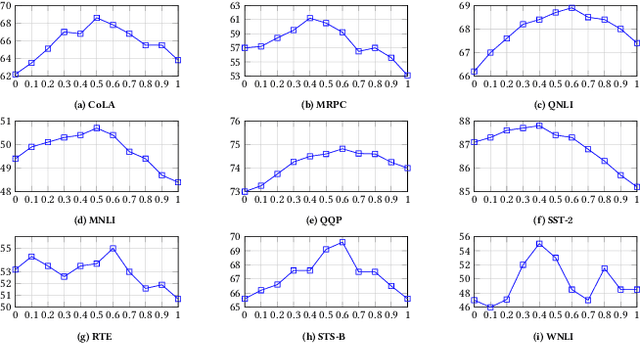
The Natural Language Processing(NLP) community has been using crowd sourcing techniques to create benchmark datasets such as General Language Understanding and Evaluation(GLUE) for training modern Language Models such as BERT. GLUE tasks measure the reliability scores using inter annotator metrics i.e. Cohens Kappa. However, the reliability aspect of LMs has often been overlooked. To counter this problem, we explore a knowledge-guided LM ensembling approach that leverages reinforcement learning to integrate knowledge from ConceptNet and Wikipedia as knowledge graph embeddings. This approach mimics human annotators resorting to external knowledge to compensate for information deficits in the datasets. Across nine GLUE datasets, our research shows that ensembling strengthens reliability and accuracy scores, outperforming state of the art.
Nougat: Neural Optical Understanding for Academic Documents
Aug 25, 2023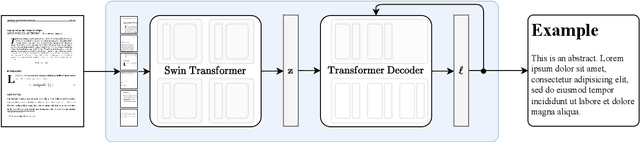
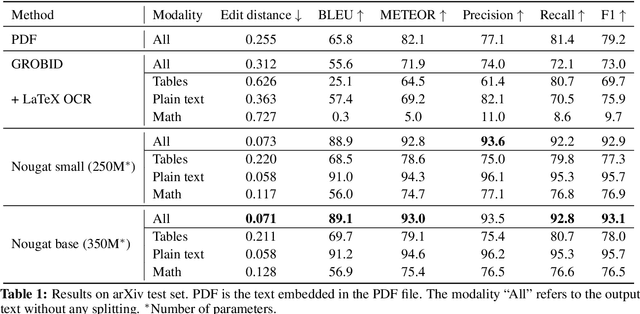


Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.
MaScQA: A Question Answering Dataset for Investigating Materials Science Knowledge of Large Language Models
Aug 17, 2023
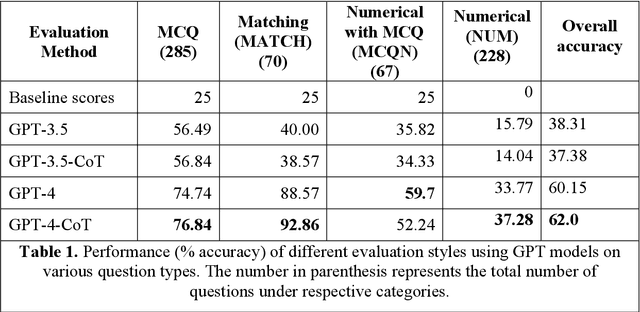
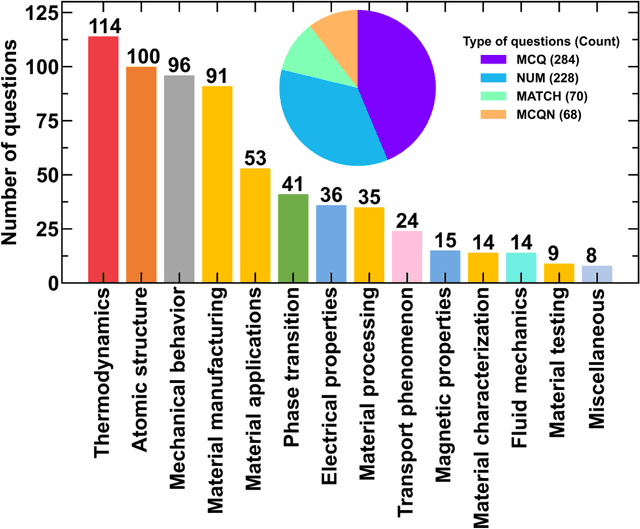
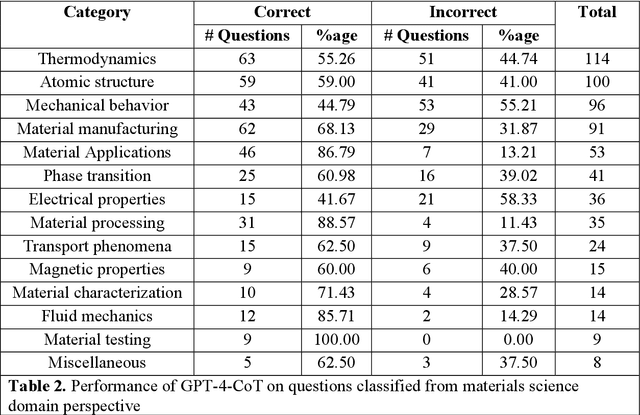
Information extraction and textual comprehension from materials literature are vital for developing an exhaustive knowledge base that enables accelerated materials discovery. Language models have demonstrated their capability to answer domain-specific questions and retrieve information from knowledge bases. However, there are no benchmark datasets in the materials domain that can evaluate the understanding of the key concepts by these language models. In this work, we curate a dataset of 650 challenging questions from the materials domain that require the knowledge and skills of a materials student who has cleared their undergraduate degree. We classify these questions based on their structure and the materials science domain-based subcategories. Further, we evaluate the performance of GPT-3.5 and GPT-4 models on solving these questions via zero-shot and chain of thought prompting. It is observed that GPT-4 gives the best performance (~62% accuracy) as compared to GPT-3.5. Interestingly, in contrast to the general observation, no significant improvement in accuracy is observed with the chain of thought prompting. To evaluate the limitations, we performed an error analysis, which revealed conceptual errors (~64%) as the major contributor compared to computational errors (~36%) towards the reduced performance of LLMs. We hope that the dataset and analysis performed in this work will promote further research in developing better materials science domain-specific LLMs and strategies for information extraction.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Aug 17, 2023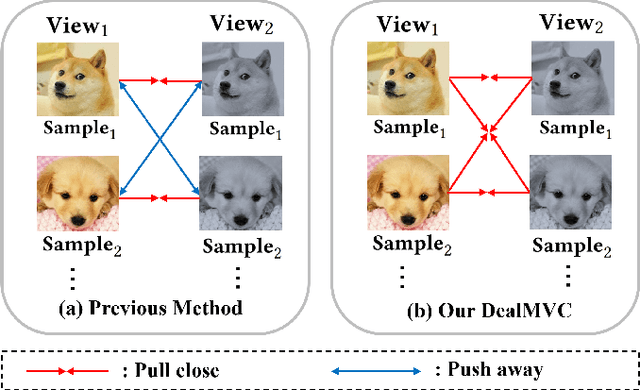

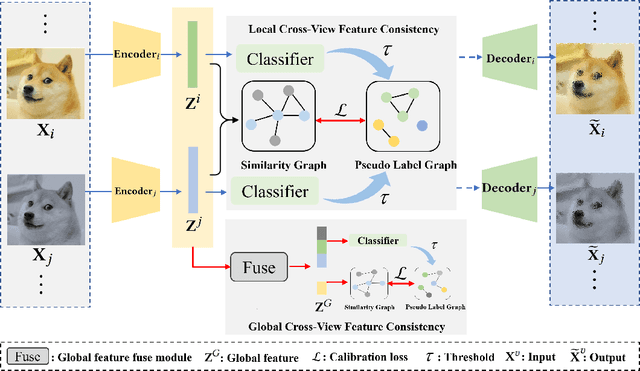
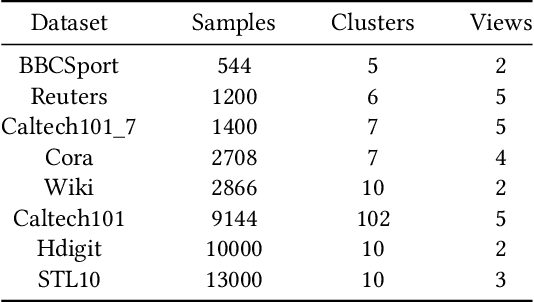
Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.
Enhancing Language Representation with Constructional Information for Natural Language Understanding
Jun 05, 2023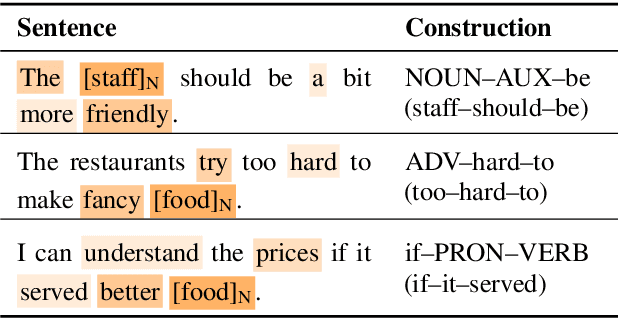
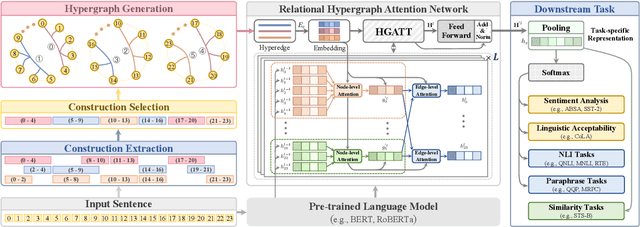

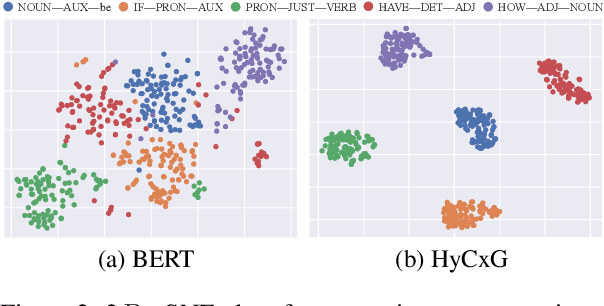
Natural language understanding (NLU) is an essential branch of natural language processing, which relies on representations generated by pre-trained language models (PLMs). However, PLMs primarily focus on acquiring lexico-semantic information, while they may be unable to adequately handle the meaning of constructions. To address this issue, we introduce construction grammar (CxG), which highlights the pairings of form and meaning, to enrich language representation. We adopt usage-based construction grammar as the basis of our work, which is highly compatible with statistical models such as PLMs. Then a HyCxG framework is proposed to enhance language representation through a three-stage solution. First, all constructions are extracted from sentences via a slot-constraints approach. As constructions can overlap with each other, bringing redundancy and imbalance, we formulate the conditional max coverage problem for selecting the discriminative constructions. Finally, we propose a relational hypergraph attention network to acquire representation from constructional information by capturing high-order word interactions among constructions. Extensive experiments demonstrate the superiority of the proposed model on a variety of NLU tasks.
Multiscale Residual Learning of Graph Convolutional Sequence Chunks for Human Motion Prediction
Aug 31, 2023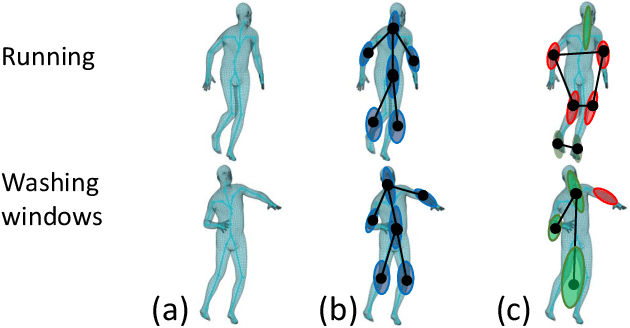
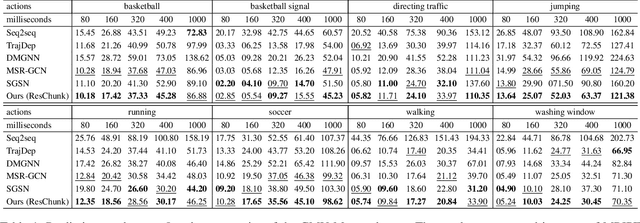
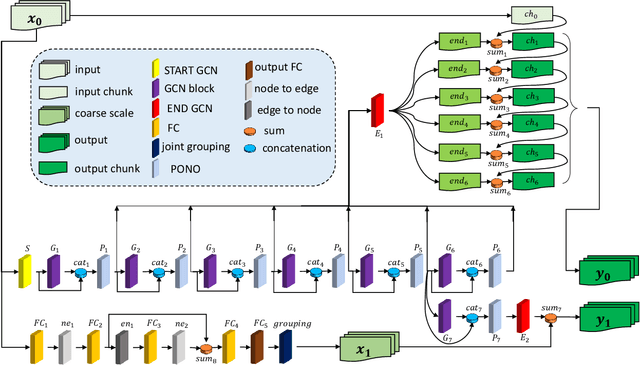

A new method is proposed for human motion prediction by learning temporal and spatial dependencies. Recently, multiscale graphs have been developed to model the human body at higher abstraction levels, resulting in more stable motion prediction. Current methods however predetermine scale levels and combine spatially proximal joints to generate coarser scales based on human priors, even though movement patterns in different motion sequences vary and do not fully comply with a fixed graph of spatially connected joints. Another problem with graph convolutional methods is mode collapse, in which predicted poses converge around a mean pose with no discernible movements, particularly in long-term predictions. To tackle these issues, we propose ResChunk, an end-to-end network which explores dynamically correlated body components based on the pairwise relationships between all joints in individual sequences. ResChunk is trained to learn the residuals between target sequence chunks in an autoregressive manner to enforce the temporal connectivities between consecutive chunks. It is hence a sequence-to-sequence prediction network which considers dynamic spatio-temporal features of sequences at multiple levels. Our experiments on two challenging benchmark datasets, CMU Mocap and Human3.6M, demonstrate that our proposed method is able to effectively model the sequence information for motion prediction and outperform other techniques to set a new state-of-the-art. Our code is available at https://github.com/MohsenZand/ResChunk.
MS23D: A 3D Object Detection Method Using Multi-Scale Semantic Feature Points to Construct 3D Feature Layers
Aug 31, 2023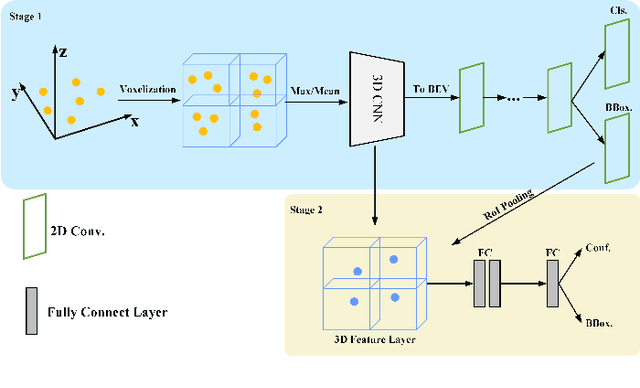
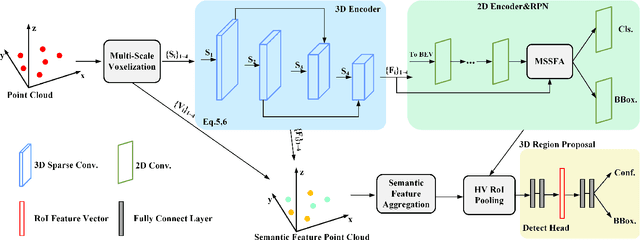
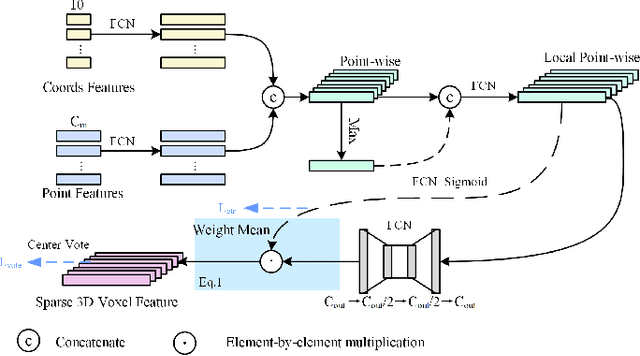
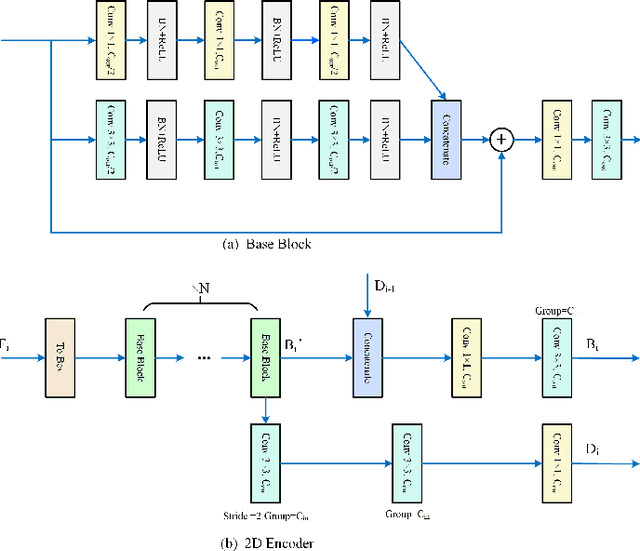
Lidar point clouds, as a type of data with accurate distance perception, can effectively represent the motion and posture of objects in three-dimensional space. However, the sparsity and disorderliness of point clouds make it challenging to extract features directly from them. Many studies have addressed this issue by transforming point clouds into regular voxel representations. However, these methods often lead to the loss of fine-grained local feature information due to downsampling. Moreover, the sparsity of point clouds poses difficulties in efficiently aggregating features in 3D feature layers using voxel-based two-stage methods. To address these issues, this paper proposes a two-stage 3D detection framework called MS$^{2}$3D. In MS$^{2}$3D, we utilize small-sized voxels to extract fine-grained local features and large-sized voxels to capture long-range local features. Additionally, we propose a method for constructing 3D feature layers using multi-scale semantic feature points, enabling the transformation of sparse 3D feature layers into more compact representations. Furthermore, we compute the offset between feature points in the 3D feature layers and the centroid of objects, aiming to bring them as close as possible to the object's center. It significantly enhances the efficiency of feature aggregation. To validate the effectiveness of our method, we evaluated our method on the KITTI dataset and ONCE dataset together.
Physics-Based Trajectory Design for Cellular-Connected UAV in Rainy Environments Based on Deep Reinforcement Learning
Aug 31, 2023
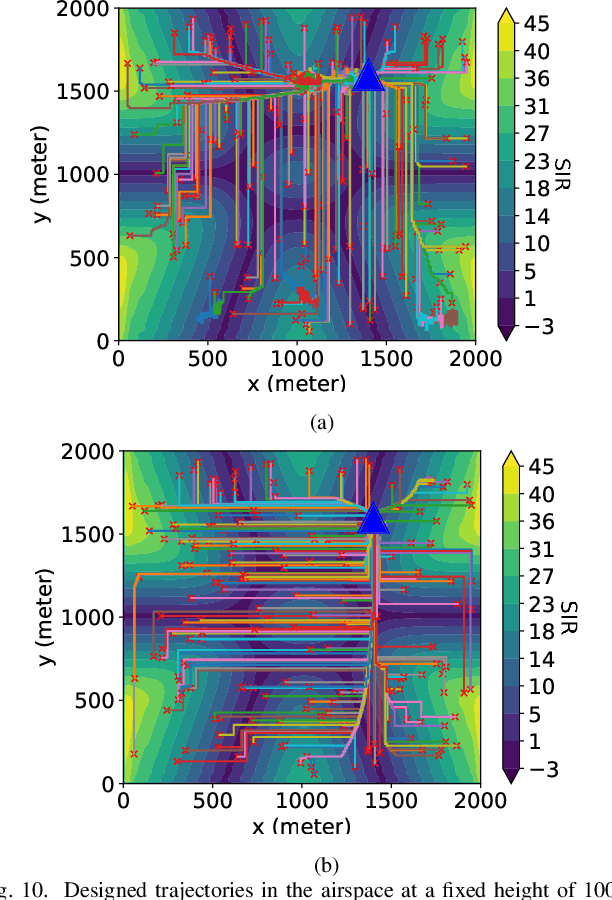
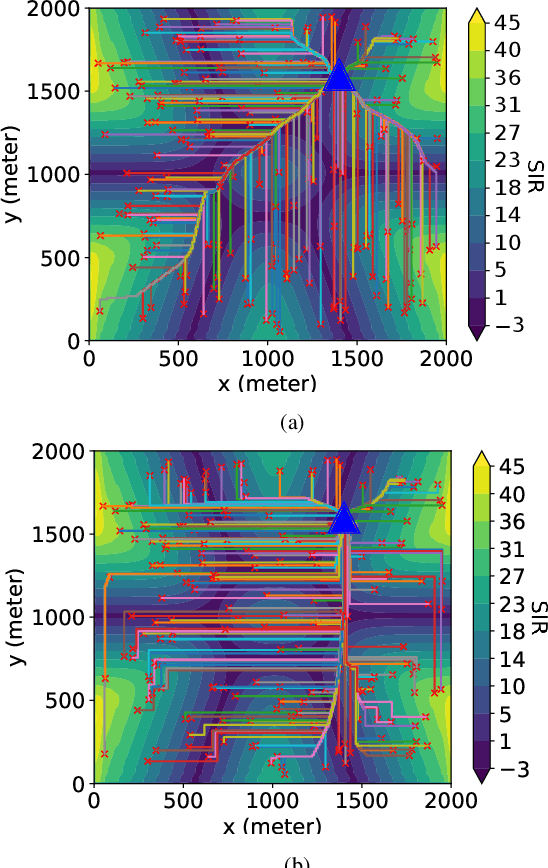
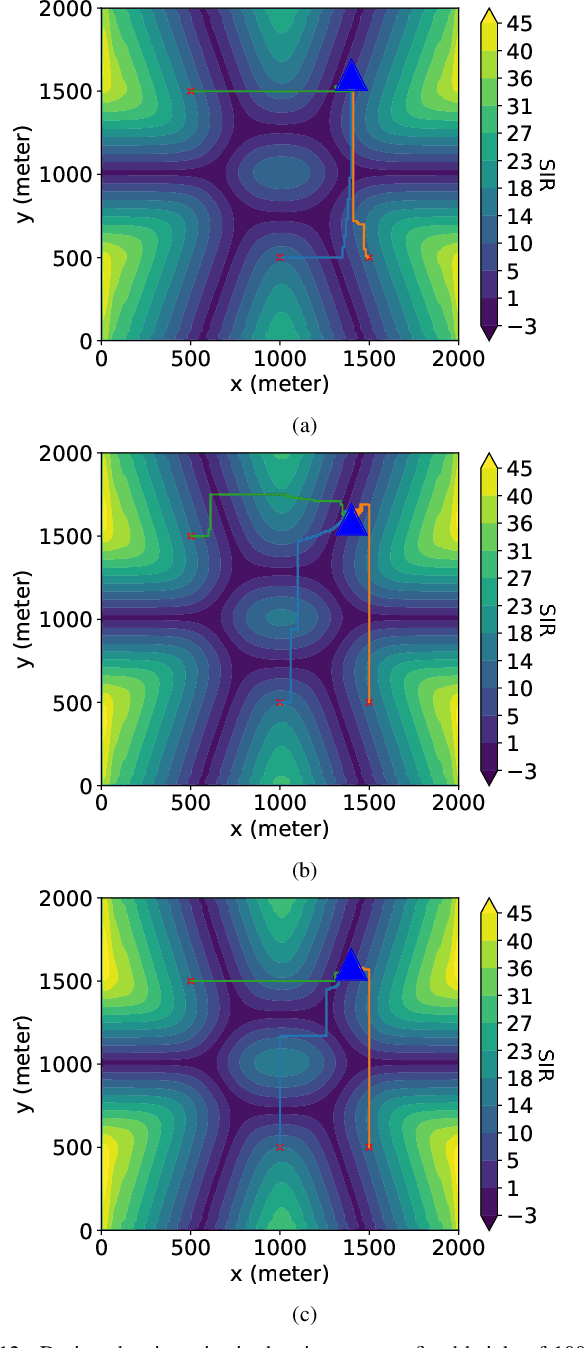
Cellular-connected unmanned aerial vehicles (UAVs) have gained increasing attention due to their potential to enhance conventional UAV capabilities by leveraging existing cellular infrastructure for reliable communications between UAVs and base stations. They have been used for various applications, including weather forecasting and search and rescue operations. However, under extreme weather conditions such as rainfall, it is challenging for the trajectory design of cellular UAVs, due to weak coverage regions in the sky, limitations of UAV flying time, and signal attenuation caused by raindrops. To this end, this paper proposes a physics-based trajectory design approach for cellular-connected UAVs in rainy environments. A physics-based electromagnetic simulator is utilized to take into account detailed environment information and the impact of rain on radio wave propagation. The trajectory optimization problem is formulated to jointly consider UAV flying time and signal-to-interference ratio, and is solved through a Markov decision process using deep reinforcement learning algorithms based on multi-step learning and double Q-learning. Optimal UAV trajectories are compared in examples with homogeneous atmosphere medium and rain medium. Additionally, a thorough study of varying weather conditions on trajectory design is provided, and the impact of weight coefficients in the problem formulation is discussed. The proposed approach has demonstrated great potential for UAV trajectory design under rainy weather conditions.
STAEformer: Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting
Aug 26, 2023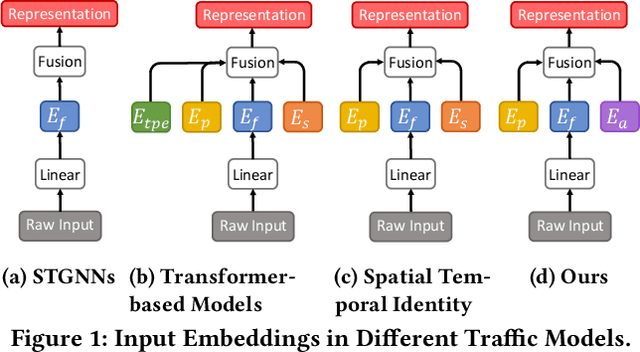
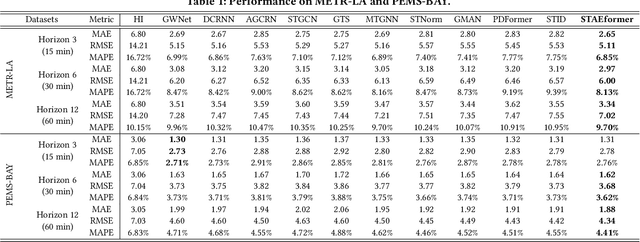
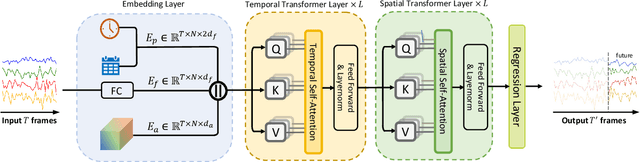
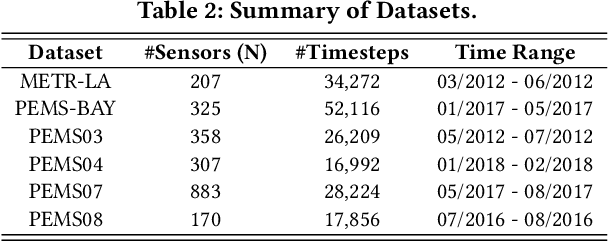
With the rapid development of the Intelligent Transportation System (ITS), accurate traffic forecasting has emerged as a critical challenge. The key bottleneck lies in capturing the intricate spatio-temporal traffic patterns. In recent years, numerous neural networks with complicated architectures have been proposed to address this issue. However, the advancements in network architectures have encountered diminishing performance gains. In this study, we present a novel component called spatio-temporal adaptive embedding that can yield outstanding results with vanilla transformers. Our proposed Spatio-Temporal Adaptive Embedding transformer (STAEformer) achieves state-of-the-art performance on five real-world traffic forecasting datasets. Further experiments demonstrate that spatio-temporal adaptive embedding plays a crucial role in traffic forecasting by effectively capturing intrinsic spatio-temporal relations and chronological information in traffic time series.