 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exchanging-based Multimodal Fusion with Transformer
Sep 05, 2023

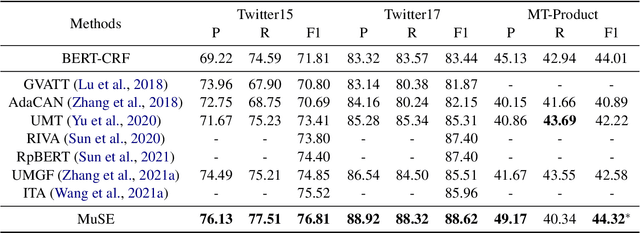
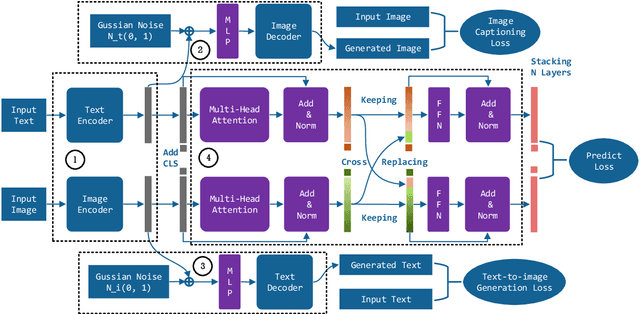
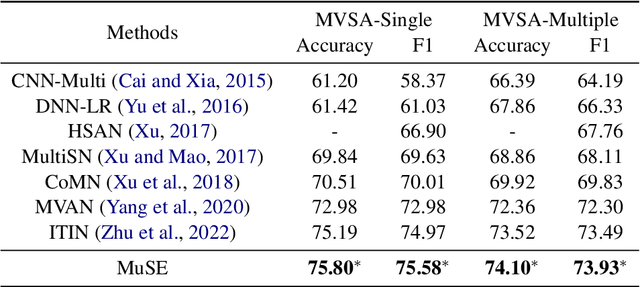
We study the problem of multimodal fusion in this paper. Recent exchanging-based methods have been proposed for vision-vision fusion, which aim to exchange embeddings learned from one modality to the other. However, most of them project inputs of multimodalities into different low-dimensional spaces and cannot be applied to the sequential input data. To solve these issues, in this paper, we propose a novel exchanging-based multimodal fusion model MuSE for text-vision fusion based on Transformer. We first use two encoders to separately map multimodal inputs into different low-dimensional spaces. Then we employ two decoders to regularize the embeddings and pull them into the same space. The two decoders capture the correlations between texts and images with the image captioning task and the text-to-image generation task, respectively. Further, based on the regularized embeddings, we present CrossTransformer, which uses two Transformer encoders with shared parameters as the backbone model to exchange knowledge between multimodalities. Specifically, CrossTransformer first learns the global contextual information of the inputs in the shallow layers. After that, it performs inter-modal exchange by selecting a proportion of tokens in one modality and replacing their embeddings with the average of embeddings in the other modality. We conduct extensive experiments to evaluate the performance of MuSE on the Multimodal Named Entity Recognition task and the Multimodal Sentiment Analysis task. Our results show the superiority of MuSE against other competitors. Our code and data are provided at https://github.com/RecklessRonan/MuSE.
Generative Algorithms for Fusion of Physics-Based Wildfire Spread Models with Satellite Data for Initializing Wildfire Forecasts
Sep 05, 2023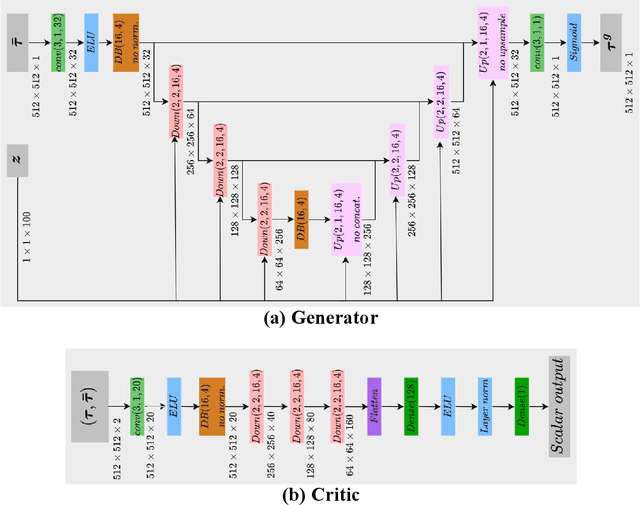

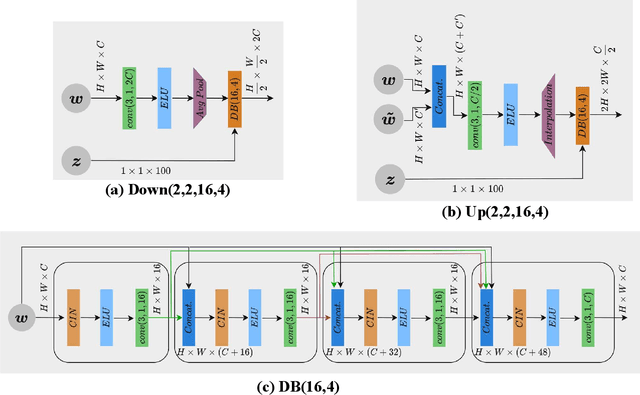
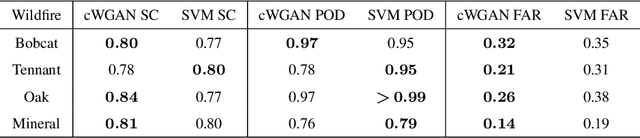
Increases in wildfire activity and the resulting impacts have prompted the development of high-resolution wildfire behavior models for forecasting fire spread. Recent progress in using satellites to detect fire locations further provides the opportunity to use measurements to improve fire spread forecasts from numerical models through data assimilation. This work develops a method for inferring the history of a wildfire from satellite measurements, providing the necessary information to initialize coupled atmosphere-wildfire models from a measured wildfire state in a physics-informed approach. The fire arrival time, which is the time the fire reaches a given spatial location, acts as a succinct representation of the history of a wildfire. In this work, a conditional Wasserstein Generative Adversarial Network (cWGAN), trained with WRF-SFIRE simulations, is used to infer the fire arrival time from satellite active fire data. The cWGAN is used to produce samples of likely fire arrival times from the conditional distribution of arrival times given satellite active fire detections. Samples produced by the cWGAN are further used to assess the uncertainty of predictions. The cWGAN is tested on four California wildfires occurring between 2020 and 2022, and predictions for fire extent are compared against high resolution airborne infrared measurements. Further, the predicted ignition times are compared with reported ignition times. An average Sorensen's coefficient of 0.81 for the fire perimeters and an average ignition time error of 32 minutes suggest that the method is highly accurate.
Incorporating Dictionaries into a Neural Network Architecture to Extract COVID-19 Medical Concepts From Social Media
Sep 05, 2023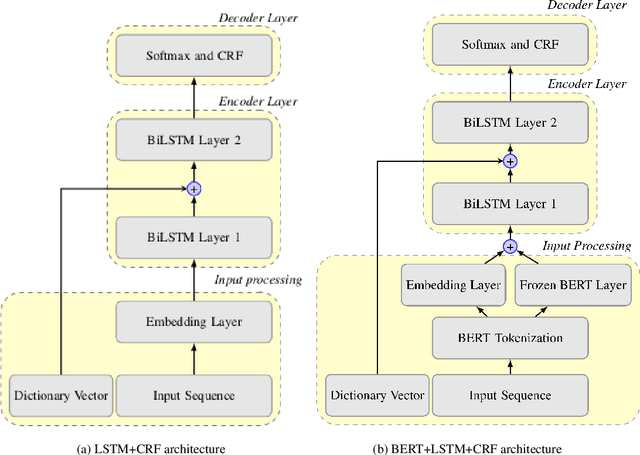
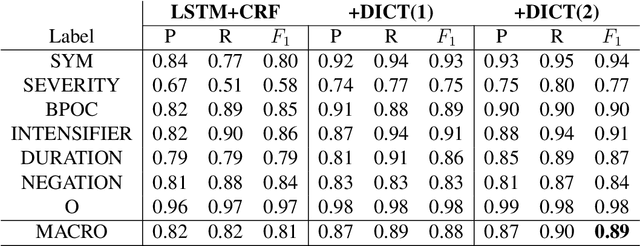
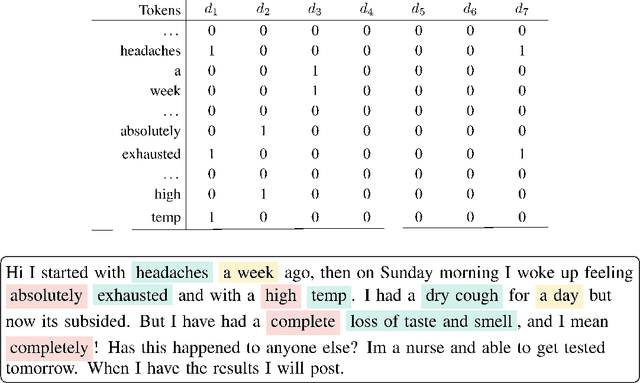
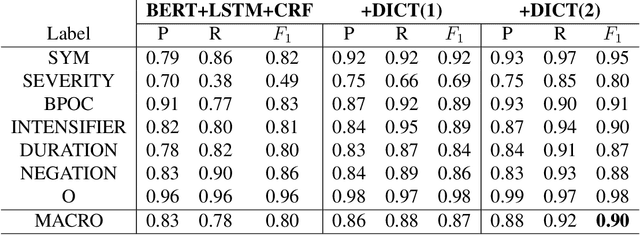
We investigate the potential benefit of incorporating dictionary information into a neural network architecture for natural language processing. In particular, we make use of this architecture to extract several concepts related to COVID-19 from an on-line medical forum. We use a sample from the forum to manually curate one dictionary for each concept. In addition, we use MetaMap, which is a tool for extracting biomedical concepts, to identify a small number of semantic concepts. For a supervised concept extraction task on the forum data, our best model achieved a macro $F_1$ score of 90\%. A major difficulty in medical concept extraction is obtaining labelled data from which to build supervised models. We investigate the utility of our models to transfer to data derived from a different source in two ways. First for producing labels via weak learning and second to perform concept extraction. The dataset we use in this case comprises COVID-19 related tweets and we achieve an $F_1$ score 81\% for symptom concept extraction trained on weakly labelled data. The utility of our dictionaries is compared with a COVID-19 symptom dictionary that was constructed directly from Twitter. Further experiments that incorporate BERT and a COVID-19 version of BERTweet demonstrate that the dictionaries provide a commensurate result. Our results show that incorporating small domain dictionaries to deep learning models can improve concept extraction tasks. Moreover, models built using dictionaries generalize well and are transferable to different datasets on a similar task.
Affine-Transformation-Invariant Image Classification by Differentiable Arithmetic Distribution Module
Sep 01, 2023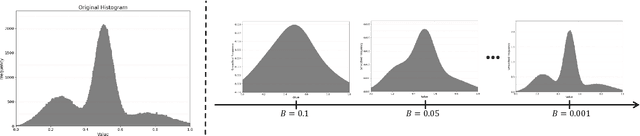
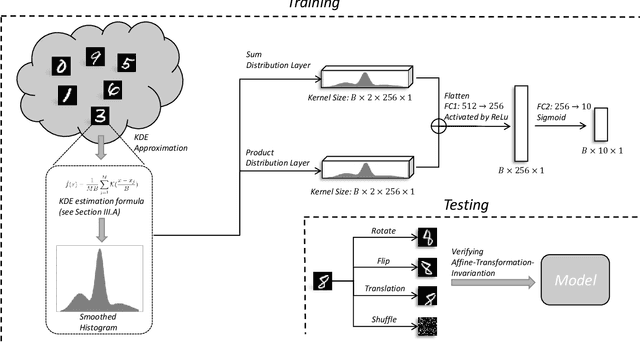
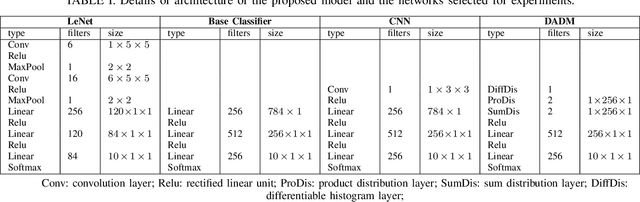

Although Convolutional Neural Networks (CNNs) have achieved promising results in image classification, they still are vulnerable to affine transformations including rotation, translation, flip and shuffle. The drawback motivates us to design a module which can alleviate the impact from different affine transformations. Thus, in this work, we introduce a more robust substitute by incorporating distribution learning techniques, focusing particularly on learning the spatial distribution information of pixels in images. To rectify the issue of non-differentiability of prior distribution learning methods that rely on traditional histograms, we adopt the Kernel Density Estimation (KDE) to formulate differentiable histograms. On this foundation, we present a novel Differentiable Arithmetic Distribution Module (DADM), which is designed to extract the intrinsic probability distributions from images. The proposed approach is able to enhance the model's robustness to affine transformations without sacrificing its feature extraction capabilities, thus bridging the gap between traditional CNNs and distribution-based learning. We validate the effectiveness of the proposed approach through ablation study and comparative experiments with LeNet.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023
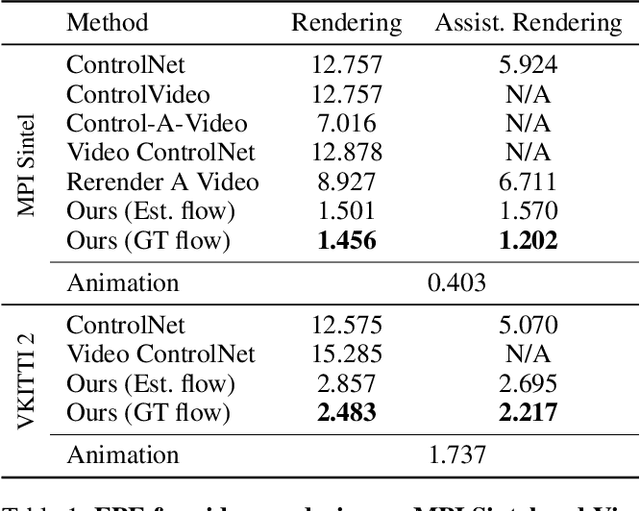
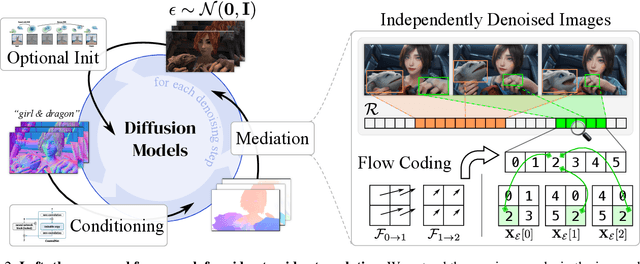
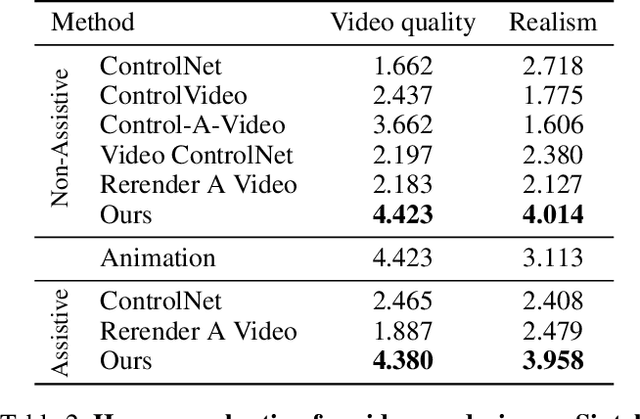
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io
Why do universal adversarial attacks work on large language models?: Geometry might be the answer
Sep 01, 2023Transformer based large language models with emergent capabilities are becoming increasingly ubiquitous in society. However, the task of understanding and interpreting their internal workings, in the context of adversarial attacks, remains largely unsolved. Gradient-based universal adversarial attacks have been shown to be highly effective on large language models and potentially dangerous due to their input-agnostic nature. This work presents a novel geometric perspective explaining universal adversarial attacks on large language models. By attacking the 117M parameter GPT-2 model, we find evidence indicating that universal adversarial triggers could be embedding vectors which merely approximate the semantic information in their adversarial training region. This hypothesis is supported by white-box model analysis comprising dimensionality reduction and similarity measurement of hidden representations. We believe this new geometric perspective on the underlying mechanism driving universal attacks could help us gain deeper insight into the internal workings and failure modes of LLMs, thus enabling their mitigation.
BarlowRL: Barlow Twins for Data-Efficient Reinforcement Learning
Aug 28, 2023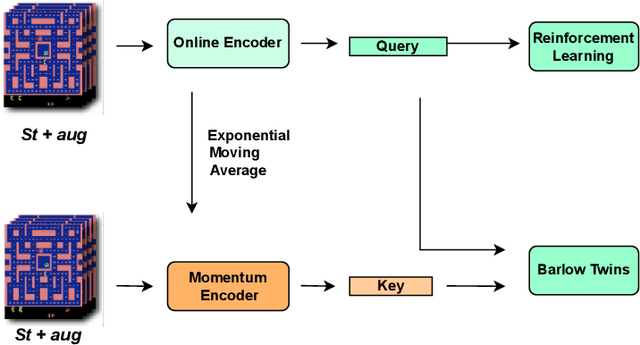
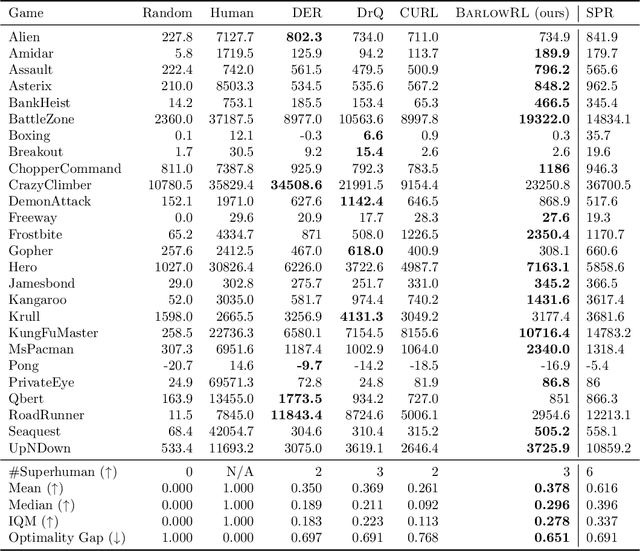


This paper introduces BarlowRL, a data-efficient reinforcement learning agent that combines the Barlow Twins self-supervised learning framework with DER (Data-Efficient Rainbow) algorithm. BarlowRL outperforms both DER and its contrastive counterpart CURL on the Atari 100k benchmark. BarlowRL avoids dimensional collapse by enforcing information spread to the whole space. This helps RL algorithms to utilize uniformly spread state representation that eventually results in a remarkable performance. The integration of Barlow Twins with DER enhances data efficiency and achieves superior performance in the RL tasks. BarlowRL demonstrates the potential of incorporating self-supervised learning techniques to improve RL algorithms.
Goal-oriented Tensor: Beyond Age of Information Towards Semantics-Empowered Goal-Oriented Communications
Jul 02, 2023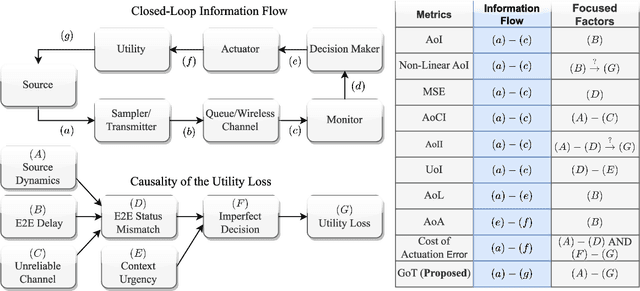
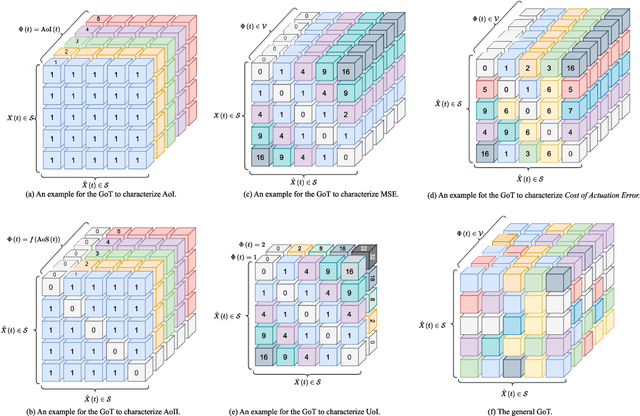
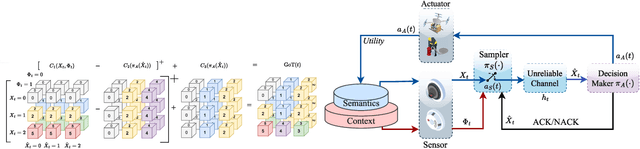
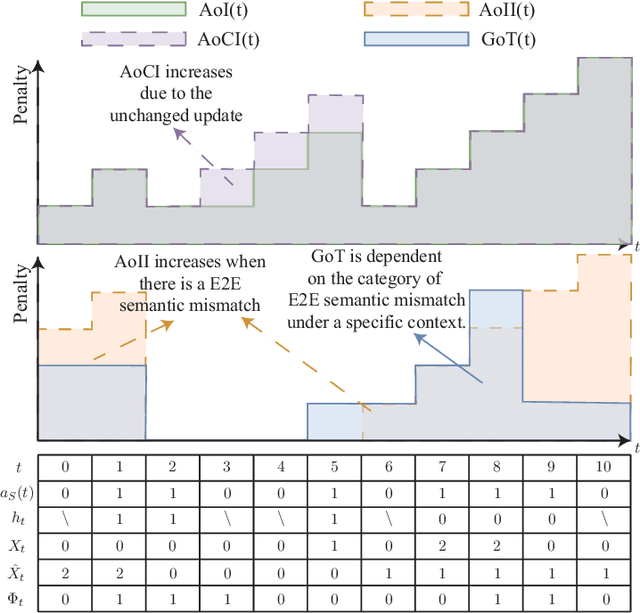
Optimizations premised on open-loop metrics such as Age of Information (AoI) indirectly enhance the system's decision-making utility. We therefore propose a novel closed-loop metric named Goal-oriented Tensor (GoT) to directly quantify the impact of semantic mismatches on goal-oriented decision-making utility. Leveraging the GoT, we consider a sampler & decision-maker pair that works collaboratively and distributively to achieve a shared goal of communications. We formulate a two-agent infinite-horizon Decentralized Partially Observable Markov Decision Process (Dec-POMDP) to conjointly deduce the optimal deterministic sampling policy and decision-making policy. To circumvent the curse of dimensionality in obtaining an optimal deterministic joint policy through Brute-Force-Search, a sub-optimal yet computationally efficient algorithm is developed. This algorithm is predicated on the search for a Nash Equilibrium between the sampler and the decision-maker. Simulation results reveal that the proposed sampler & decision-maker co-design surpasses the current literature on AoI and its variants in terms of both goal achievement utility and sparse sampling rate, signifying progress in the semantics-conscious, goal-driven sparse sampling design.
Multi-stage feature decorrelation constraints for improving CNN classification performance
Aug 24, 2023
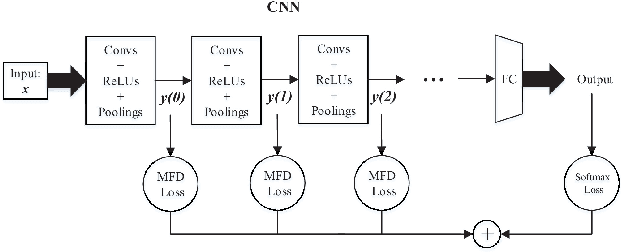
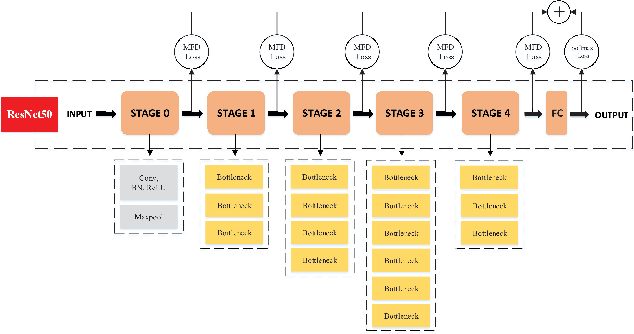

For the convolutional neural network (CNN) used for pattern classification, the training loss function is usually applied to the final output of the network, except for some regularization constraints on the network parameters. However, with the increasing of the number of network layers, the influence of the loss function on the network front layers gradually decreases, and the network parameters tend to fall into local optimization. At the same time, it is found that the trained network has significant information redundancy at all stages of features, which reduces the effectiveness of feature mapping at all stages and is not conducive to the change of the subsequent parameters of the network in the direction of optimality. Therefore, it is possible to obtain a more optimized solution of the network and further improve the classification accuracy of the network by designing a loss function for restraining the front stage features and eliminating the information redundancy of the front stage features .For CNN, this article proposes a multi-stage feature decorrelation loss (MFD Loss), which refines effective features and eliminates information redundancy by constraining the correlation of features at all stages. Considering that there are many layers in CNN, through experimental comparison and analysis, MFD Loss acts on multiple front layers of CNN, constrains the output features of each layer and each channel, and performs supervision training jointly with classification loss function during network training. Compared with the single Softmax Loss supervised learning, the experiments on several commonly used datasets on several typical CNNs prove that the classification performance of Softmax Loss+MFD Loss is significantly better. Meanwhile, the comparison experiments before and after the combination of MFD Loss and some other typical loss functions verify its good universality.
Pedestrian Environment Model for Automated Driving
Aug 17, 2023Besides interacting correctly with other vehicles, automated vehicles should also be able to react in a safe manner to vulnerable road users like pedestrians or cyclists. For a safe interaction between pedestrians and automated vehicles, the vehicle must be able to interpret the pedestrian's behavior. Common environment models do not contain information like body poses used to understand the pedestrian's intent. In this work, we propose an environment model that includes the position of the pedestrians as well as their pose information. We only use images from a monocular camera and the vehicle's localization data as input to our pedestrian environment model. We extract the skeletal information with a neural network human pose estimator from the image. Furthermore, we track the skeletons with a simple tracking algorithm based on the Hungarian algorithm and an ego-motion compensation. To obtain the 3D information of the position, we aggregate the data from consecutive frames in conjunction with the vehicle position. We demonstrate our pedestrian environment model on data generated with the CARLA simulator and the nuScenes dataset. Overall, we reach a relative position error of around 16% on both datasets.