 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Are current long-term video understanding datasets long-term?
Aug 22, 2023

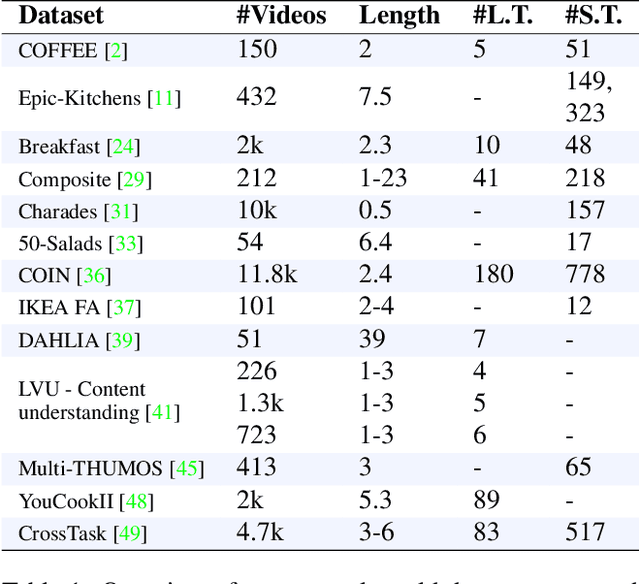
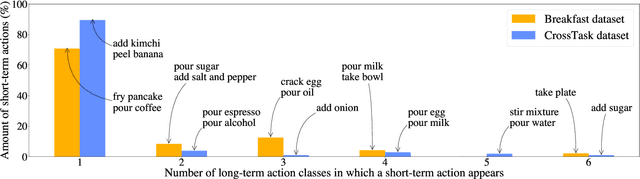
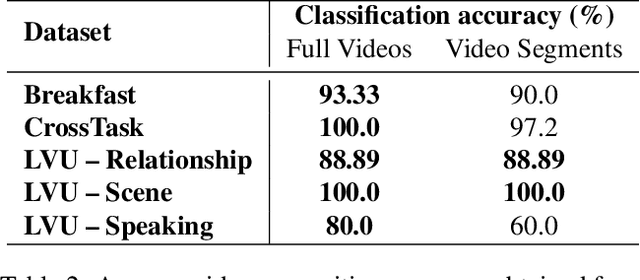
Many real-world applications, from sport analysis to surveillance, benefit from automatic long-term action recognition. In the current deep learning paradigm for automatic action recognition, it is imperative that models are trained and tested on datasets and tasks that evaluate if such models actually learn and reason over long-term information. In this work, we propose a method to evaluate how suitable a video dataset is to evaluate models for long-term action recognition. To this end, we define a long-term action as excluding all the videos that can be correctly recognized using solely short-term information. We test this definition on existing long-term classification tasks on three popular real-world datasets, namely Breakfast, CrossTask and LVU, to determine if these datasets are truly evaluating long-term recognition. Our study reveals that these datasets can be effectively solved using shortcuts based on short-term information. Following this finding, we encourage long-term action recognition researchers to make use of datasets that need long-term information to be solved.
Learning Strong Graph Neural Networks with Weak Information
May 29, 2023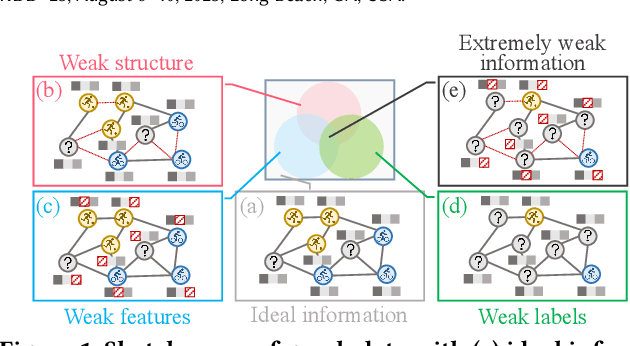
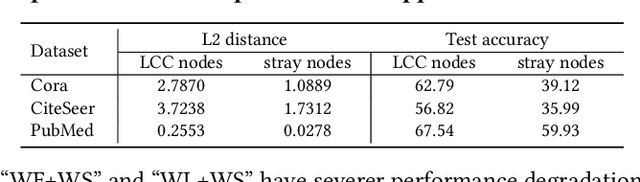
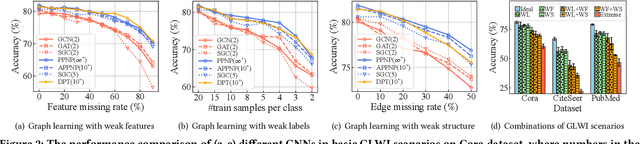
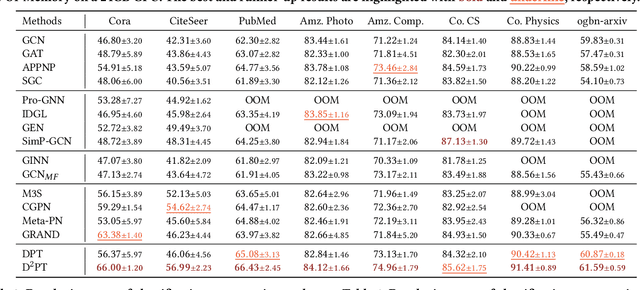
Graph Neural Networks (GNNs) have exhibited impressive performance in many graph learning tasks. Nevertheless, the performance of GNNs can deteriorate when the input graph data suffer from weak information, i.e., incomplete structure, incomplete features, and insufficient labels. Most prior studies, which attempt to learn from the graph data with a specific type of weak information, are far from effective in dealing with the scenario where diverse data deficiencies exist and mutually affect each other. To fill the gap, in this paper, we aim to develop an effective and principled approach to the problem of graph learning with weak information (GLWI). Based on the findings from our empirical analysis, we derive two design focal points for solving the problem of GLWI, i.e., enabling long-range propagation in GNNs and allowing information propagation to those stray nodes isolated from the largest connected component. Accordingly, we propose D$^2$PT, a dual-channel GNN framework that performs long-range information propagation not only on the input graph with incomplete structure, but also on a global graph that encodes global semantic similarities. We further develop a prototype contrastive alignment algorithm that aligns the class-level prototypes learned from two channels, such that the two different information propagation processes can mutually benefit from each other and the finally learned model can well handle the GLWI problem. Extensive experiments on eight real-world benchmark datasets demonstrate the effectiveness and efficiency of our proposed methods in various GLWI scenarios.
Emoji Promotes Developer Participation and Issue Resolution on GitHub
Sep 07, 2023


Although remote working is increasingly adopted during the pandemic, many are concerned by the low-efficiency in the remote working. Missing in text-based communication are non-verbal cues such as facial expressions and body language, which hinders the effective communication and negatively impacts the work outcomes. Prevalent on social media platforms, emojis, as alternative non-verbal cues, are gaining popularity in the virtual workspaces well. In this paper, we study how emoji usage influences developer participation and issue resolution in virtual workspaces. To this end, we collect GitHub issues for a one-year period and apply causal inference techniques to measure the causal effect of emojis on the outcome of issues, controlling for confounders such as issue content, repository, and author information. We find that emojis can significantly reduce the resolution time of issues and attract more user participation. We also compare the heterogeneous effect on different types of issues. These findings deepen our understanding of the developer communities, and they provide design implications on how to facilitate interactions and broaden developer participation.
BNS-Net: A Dual-channel Sarcasm Detection Method Considering Behavior-level and Sentence-level Conflicts
Sep 07, 2023Sarcasm detection is a binary classification task that aims to determine whether a given utterance is sarcastic. Over the past decade, sarcasm detection has evolved from classical pattern recognition to deep learning approaches, where features such as user profile, punctuation and sentiment words have been commonly employed for sarcasm detection. In real-life sarcastic expressions, behaviors without explicit sentimental cues often serve as carriers of implicit sentimental meanings. Motivated by this observation, we proposed a dual-channel sarcasm detection model named BNS-Net. The model considers behavior and sentence conflicts in two channels. Channel 1: Behavior-level Conflict Channel reconstructs the text based on core verbs while leveraging the modified attention mechanism to highlight conflict information. Channel 2: Sentence-level Conflict Channel introduces external sentiment knowledge to segment the text into explicit and implicit sentences, capturing conflicts between them. To validate the effectiveness of BNS-Net, several comparative and ablation experiments are conducted on three public sarcasm datasets. The analysis and evaluation of experimental results demonstrate that the BNS-Net effectively identifies sarcasm in text and achieves the state-of-the-art performance.
Text-to-feature diffusion for audio-visual few-shot learning
Sep 07, 2023
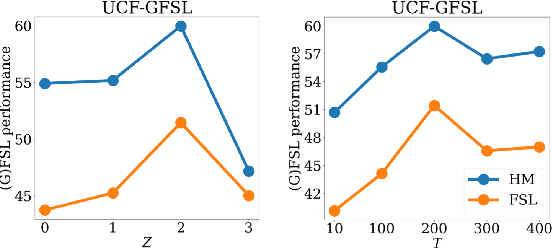
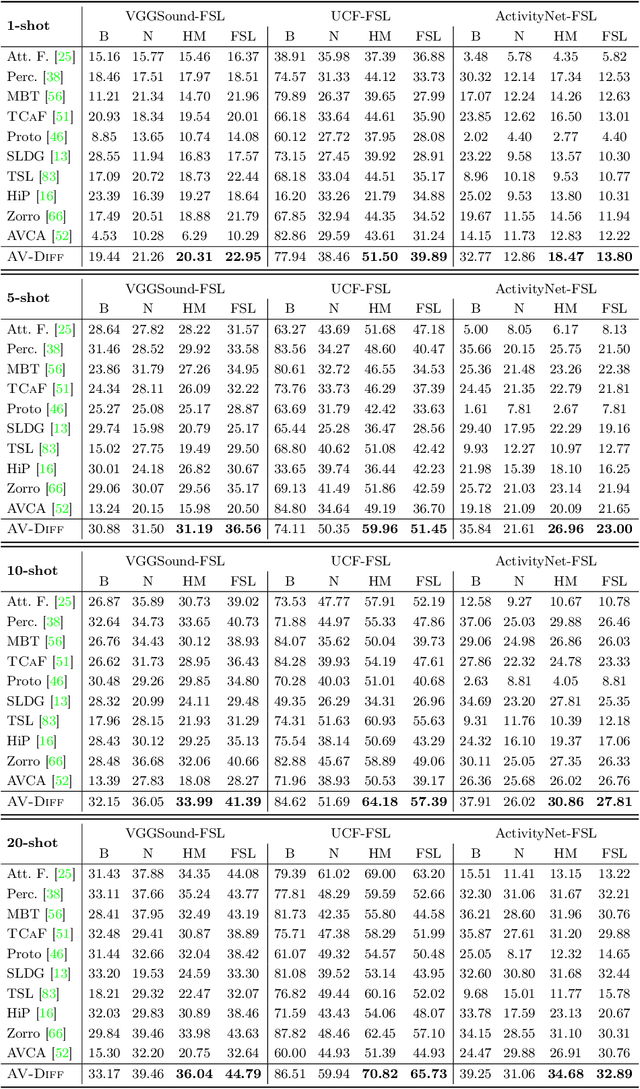
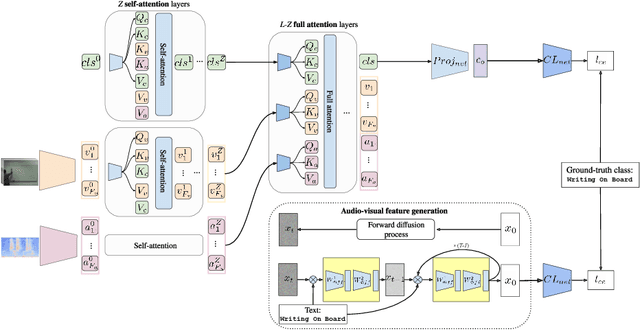
Training deep learning models for video classification from audio-visual data commonly requires immense amounts of labeled training data collected via a costly process. A challenging and underexplored, yet much cheaper, setup is few-shot learning from video data. In particular, the inherently multi-modal nature of video data with sound and visual information has not been leveraged extensively for the few-shot video classification task. Therefore, we introduce a unified audio-visual few-shot video classification benchmark on three datasets, i.e. the VGGSound-FSL, UCF-FSL, ActivityNet-FSL datasets, where we adapt and compare ten methods. In addition, we propose AV-DIFF, a text-to-feature diffusion framework, which first fuses the temporal and audio-visual features via cross-modal attention and then generates multi-modal features for the novel classes. We show that AV-DIFF obtains state-of-the-art performance on our proposed benchmark for audio-visual (generalised) few-shot learning. Our benchmark paves the way for effective audio-visual classification when only limited labeled data is available. Code and data are available at https://github.com/ExplainableML/AVDIFF-GFSL.
Context-Aware 3D Object Localization from Single Calibrated Images: A Study of Basketballs
Sep 07, 2023
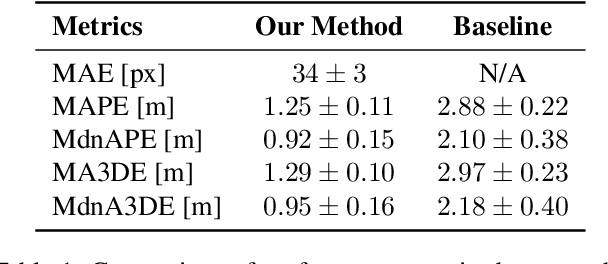

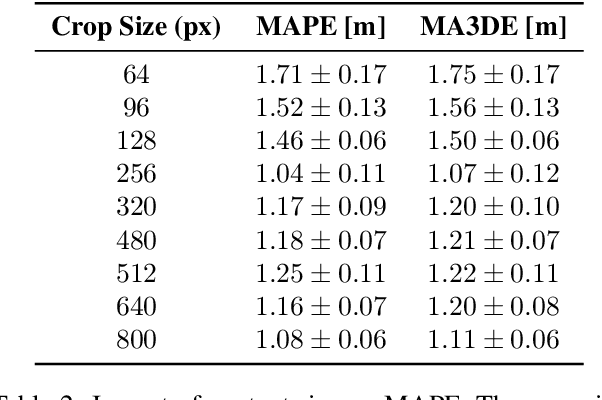
Accurately localizing objects in three dimensions (3D) is crucial for various computer vision applications, such as robotics, autonomous driving, and augmented reality. This task finds another important application in sports analytics and, in this work, we present a novel method for 3D basketball localization from a single calibrated image. Our approach predicts the object's height in pixels in image space by estimating its projection onto the ground plane within the image, leveraging the image itself and the object's location as inputs. The 3D coordinates of the ball are then reconstructed by exploiting the known projection matrix. Extensive experiments on the public DeepSport dataset, which provides ground truth annotations for 3D ball location alongside camera calibration information for each image, demonstrate the effectiveness of our method, offering substantial accuracy improvements compared to recent work. Our work opens up new possibilities for enhanced ball tracking and understanding, advancing computer vision in diverse domains. The source code of this work is made publicly available at \url{https://github.com/gabriel-vanzandycke/deepsport}.
Punctate White Matter Lesion Segmentation in Preterm Infants Powered by Counterfactually Generative Learning
Sep 07, 2023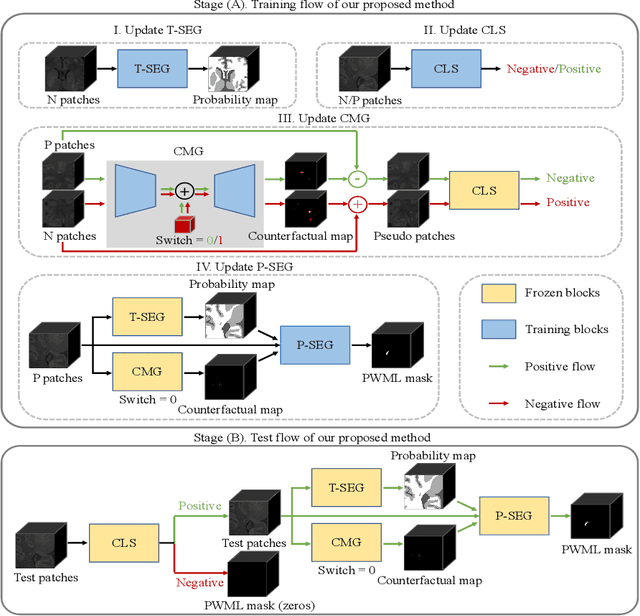
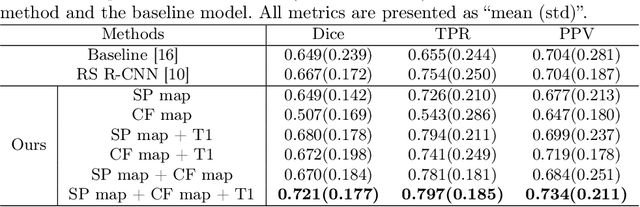
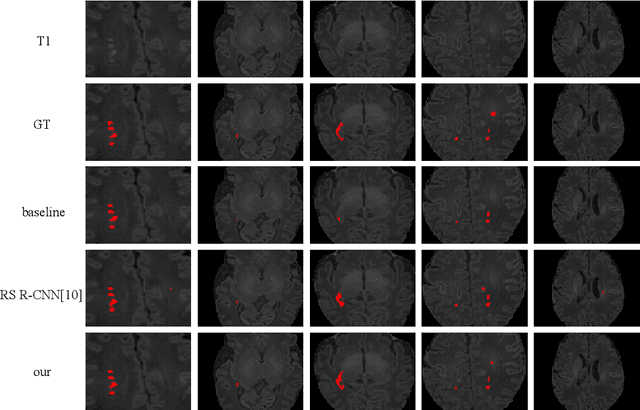
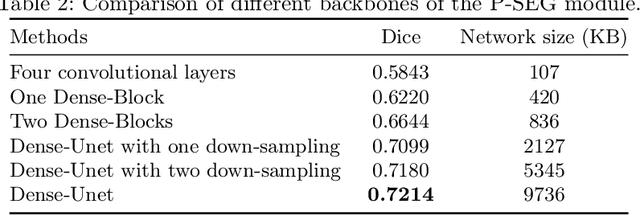
Accurate segmentation of punctate white matter lesions (PWMLs) are fundamental for the timely diagnosis and treatment of related developmental disorders. Automated PWMLs segmentation from infant brain MR images is challenging, considering that the lesions are typically small and low-contrast, and the number of lesions may dramatically change across subjects. Existing learning-based methods directly apply general network architectures to this challenging task, which may fail to capture detailed positional information of PWMLs, potentially leading to severe under-segmentations. In this paper, we propose to leverage the idea of counterfactual reasoning coupled with the auxiliary task of brain tissue segmentation to learn fine-grained positional and morphological representations of PWMLs for accurate localization and segmentation. A simple and easy-to-implement deep-learning framework (i.e., DeepPWML) is accordingly designed. It combines the lesion counterfactual map with the tissue probability map to train a lightweight PWML segmentation network, demonstrating state-of-the-art performance on a real-clinical dataset of infant T1w MR images. The code is available at \href{https://github.com/ladderlab-xjtu/DeepPWML}{https://github.com/ladderlab-xjtu/DeepPWML}.
Instance Segmentation of Dislocations in TEM Images
Sep 07, 2023



Quantitative Transmission Electron Microscopy (TEM) during in-situ straining experiment is able to reveal the motion of dislocations -- linear defects in the crystal lattice of metals. In the domain of materials science, the knowledge about the location and movement of dislocations is important for creating novel materials with superior properties. A long-standing problem, however, is to identify the position and extract the shape of dislocations, which would ultimately help to create a digital twin of such materials. In this work, we quantitatively compare state-of-the-art instance segmentation methods, including Mask R-CNN and YOLOv8. The dislocation masks as the results of the instance segmentation are converted to mathematical lines, enabling quantitative analysis of dislocation length and geometry -- important information for the domain scientist, which we then propose to include as a novel length-aware quality metric for estimating the network performance. Our segmentation pipeline shows a high accuracy suitable for all domain-specific, further post-processing. Additionally, our physics-based metric turns out to perform much more consistently than typically used pixel-wise metrics.
SAM3D: Segment Anything Model in Volumetric Medical Images
Sep 07, 2023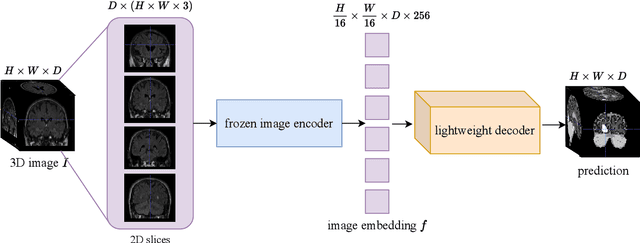
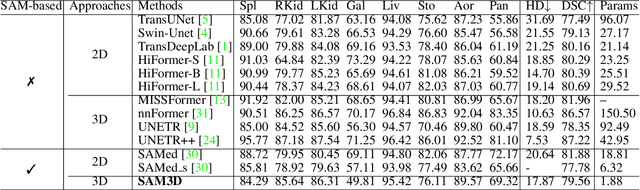
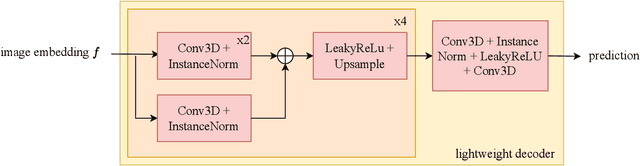
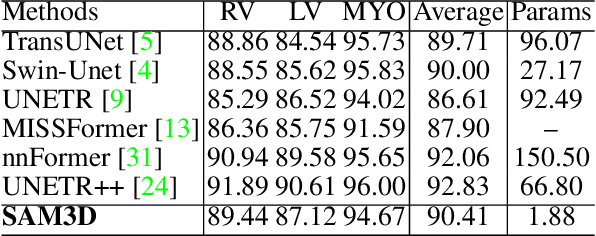
Image segmentation is a critical task in medical image analysis, providing valuable information that helps to make an accurate diagnosis. In recent years, deep learning-based automatic image segmentation methods have achieved outstanding results in medical images. In this paper, inspired by the Segment Anything Model (SAM), a foundation model that has received much attention for its impressive accuracy and powerful generalization ability in 2D still image segmentation, we propose a SAM3D that targets at 3D volumetric medical images and utilizes the pre-trained features from the SAM encoder to capture meaningful representations of input images. Different from other existing SAM-based volumetric segmentation methods that perform the segmentation by dividing the volume into a set of 2D slices, our model takes the whole 3D volume image as input and processes it simply and effectively that avoids training a significant number of parameters. Extensive experiments are conducted on multiple medical image datasets to demonstrate that our network attains competitive results compared with other state-of-the-art methods in 3D medical segmentation tasks while being significantly efficient in terms of parameters.
Generative-based Fusion Mechanism for Multi-Modal Tracking
Sep 07, 2023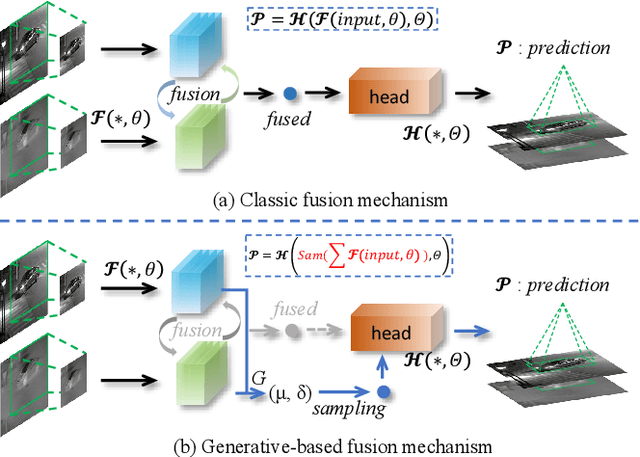

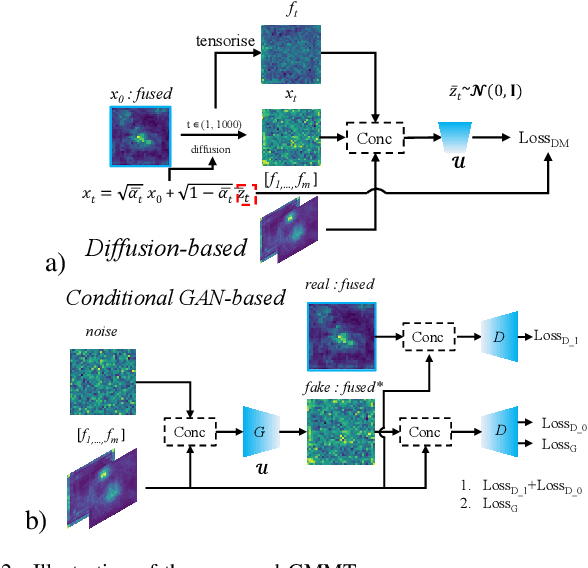

Generative models (GMs) have received increasing research interest for their remarkable capacity to achieve comprehensive understanding. However, their potential application in the domain of multi-modal tracking has remained relatively unexplored. In this context, we seek to uncover the potential of harnessing generative techniques to address the critical challenge, information fusion, in multi-modal tracking. In this paper, we delve into two prominent GM techniques, namely, Conditional Generative Adversarial Networks (CGANs) and Diffusion Models (DMs). Different from the standard fusion process where the features from each modality are directly fed into the fusion block, we condition these multi-modal features with random noise in the GM framework, effectively transforming the original training samples into harder instances. This design excels at extracting discriminative clues from the features, enhancing the ultimate tracking performance. To quantitatively gauge the effectiveness of our approach, we conduct extensive experiments across two multi-modal tracking tasks, three baseline methods, and three challenging benchmarks. The experimental results demonstrate that the proposed generative-based fusion mechanism achieves state-of-the-art performance, setting new records on LasHeR and RGBD1K.