 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PAD-Phys: Exploiting Physiology for Presentation Attack Detection in Face Biometrics
Oct 03, 2023
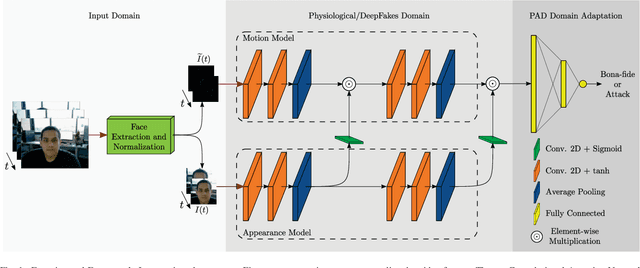
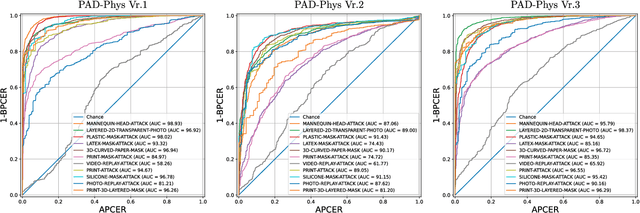
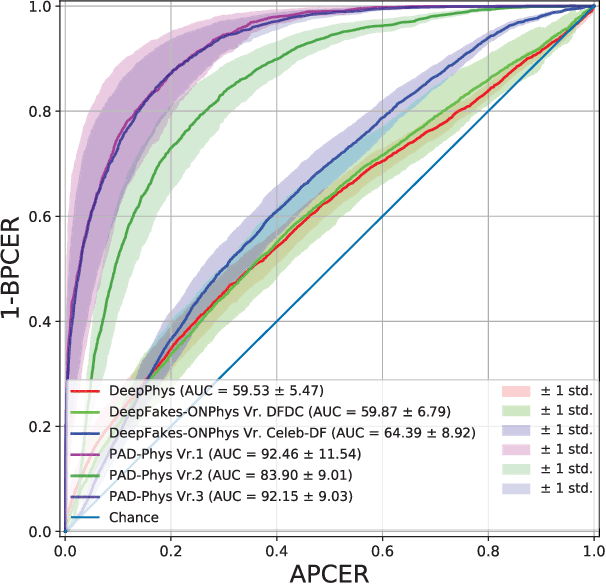
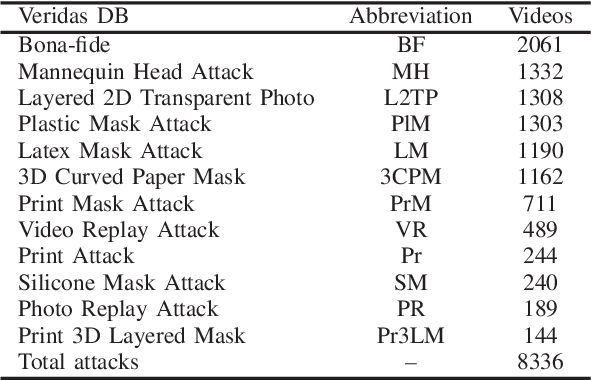
Presentation Attack Detection (PAD) is a crucial stage in facial recognition systems to avoid leakage of personal information or spoofing of identity to entities. Recently, pulse detection based on remote photoplethysmography (rPPG) has been shown to be effective in face presentation attack detection. This work presents three different approaches to the presentation attack detection based on rPPG: (i) The physiological domain, a domain using rPPG-based models, (ii) the Deepfakes domain, a domain where models were retrained from the physiological domain to specific Deepfakes detection tasks; and (iii) a new Presentation Attack domain was trained by applying transfer learning from the two previous domains to improve the capability to differentiate between bona-fides and attacks. The results show the efficiency of the rPPG-based models for presentation attack detection, evidencing a 21.70% decrease in average classification error rate (ACER) (from 41.03% to 19.32%) when the presentation attack domain is compared to the physiological and Deepfakes domains. Our experiments highlight the efficiency of transfer learning in rPPG-based models and perform well in presentation attack detection in instruments that do not allow copying of this physiological feature.
Linearization of ReLU Activation Function for Neural Network-Embedded Optimization:Optimal Day-Ahead Energy Scheduling
Oct 03, 2023Neural networks have been widely applied in the power system area. They can be used for better predicting input information and modeling system performance with increased accuracy. In some applications such as battery degradation neural network-based microgrid day-ahead energy scheduling, the input features of the trained learning model are variables to be solved in optimization models that enforce limits on the output of the same learning model. This will create a neural network-embedded optimization problem; the use of nonlinear activation functions in the neural network will make such problems extremely hard to solve if not unsolvable. To address this emerging challenge, this paper investigated different methods for linearizing the nonlinear activation functions with a particular focus on the widely used rectified linear unit (ReLU) function. Four linearization methods tailored for the ReLU activation function are developed, analyzed and compared in this paper. Each method employs a set of linear constraints to replace the ReLU function, effectively linearizing the optimization problem, which can overcome the computational challenges associated with the nonlinearity of the neural network model. These proposed linearization methods provide valuable tools for effectively solving optimization problems that integrate neural network models with ReLU activation functions.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023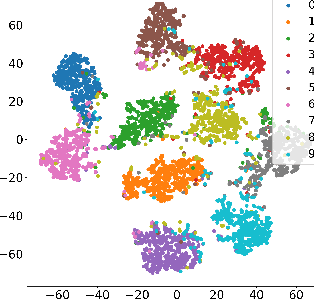
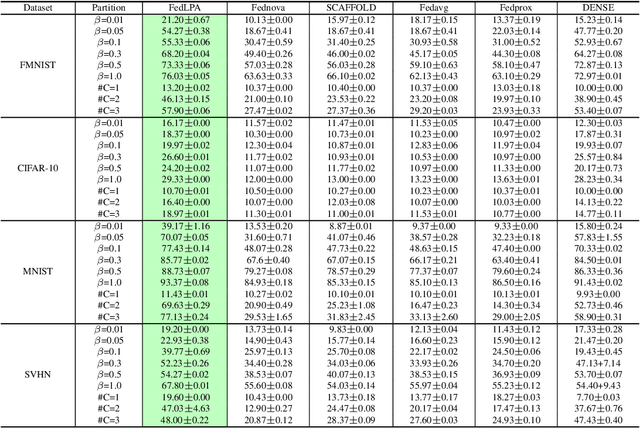
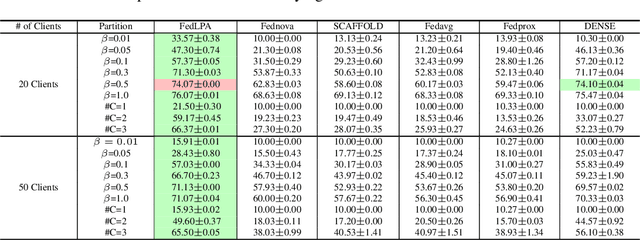
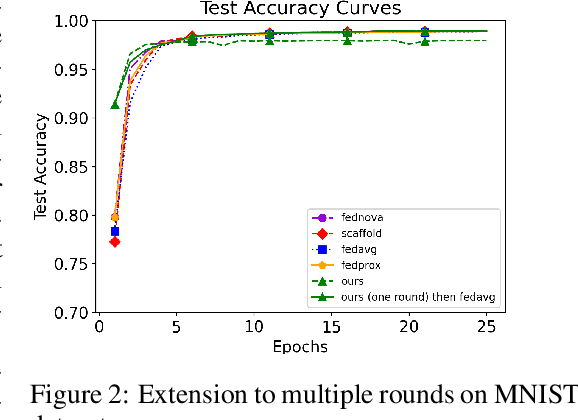
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
Speed and Density Planning for a Speed-Constrained Robot Swarm Through a Virtual Tube
Oct 01, 2023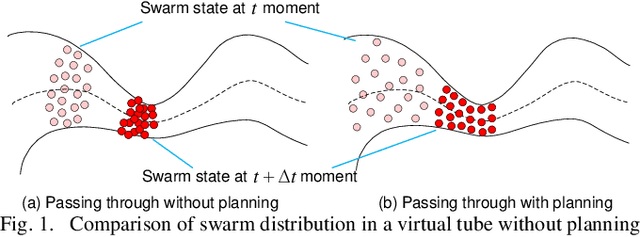
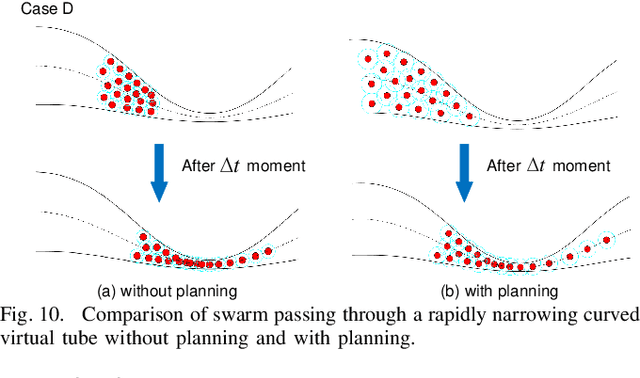
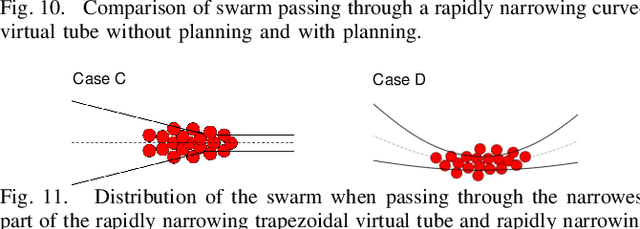
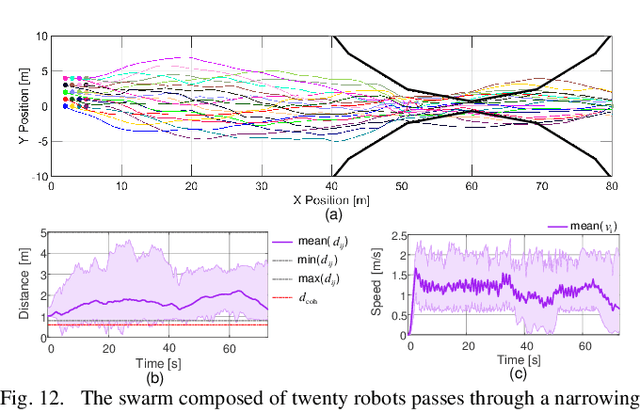
The planning and control of a robot swarm in a complex environment have attracted increasing attention. To this end, the idea of virtual tubes has been taken up in our previous work. Specifically, a virtual tube with varying widths has been planned to avoid collisions with obstacles in a complex environment. Based on the planned virtual tube for a large number of speed-constrained robots, the average forward speed and density along the virtual tube are further planned in this paper to ensure safety and improve efficiency. Compared with the existing methods, the proposed method is based on global information and can be applied to traversing narrow spaces for speed-constrained robot swarms. Numerical simulations and experiments are conducted to show that the safety and efficiency of the passing-through process are improved. A video about simulations and experiments is available on https://youtu.be/lJHdMQMqSpc.
Review of deep learning in healthcare
Oct 01, 2023Given the growing complexity of healthcare data over the last several years, using machine learning techniques like Deep Neural Network (DNN) models has gained increased appeal. In order to extract hidden patterns and other valuable information from the huge quantity of health data, which traditional analytics are unable to do in a reasonable length of time, machine learning (ML) techniques are used. Deep Learning (DL) algorithms in particular have been shown as potential approaches to pattern identification in healthcare systems. This thought has led to the contribution of this research, which examines deep learning methods used in healthcare systems via an examination of cutting-edge network designs, applications, and market trends. To connect deep learning methodologies and human healthcare interpretability, the initial objective is to provide in-depth insight into the deployment of deep learning models in healthcare solutions. And last, to outline the current unresolved issues and potential directions.
Towards a Neuronally Consistent Ontology for Robotic Agents
Sep 26, 2023The Collaborative Research Center for Everyday Activity Science & Engineering (CRC EASE) aims to enable robots to perform environmental interaction tasks with close to human capacity. It therefore employs a shared ontology to model the activity of both kinds of agents, empowering robots to learn from human experiences. To properly describe these human experiences, the ontology will strongly benefit from incorporating characteristics of neuronal information processing which are not accessible from a behavioral perspective alone. We, therefore, propose the analysis of human neuroimaging data for evaluation and validation of concepts and events defined in the ontology model underlying most of the CRC projects. In an exploratory analysis, we employed an Independent Component Analysis (ICA) on functional Magnetic Resonance Imaging (fMRI) data from participants who were presented with the same complex video stimuli of activities as robotic and human agents in different environments and contexts. We then correlated the activity patterns of brain networks represented by derived components with timings of annotated event categories as defined by the ontology model. The present results demonstrate a subset of common networks with stable correlations and specificity towards particular event classes and groups, associated with environmental and contextual factors. These neuronal characteristics will open up avenues for adapting the ontology model to be more consistent with human information processing.
A Structured Prediction Approach for Robot Imitation Learning
Sep 26, 2023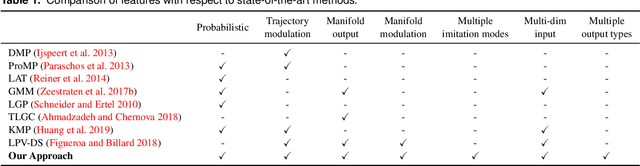
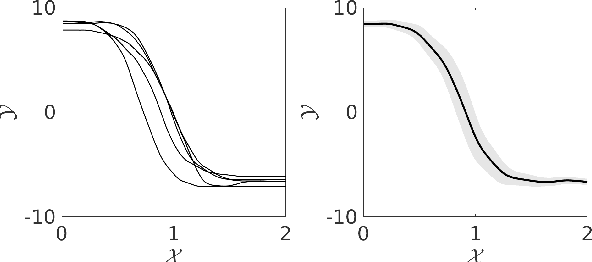
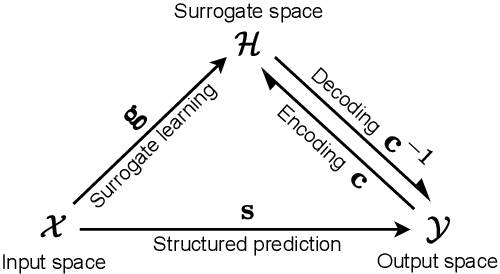

We propose a structured prediction approach for robot imitation learning from demonstrations. Among various tools for robot imitation learning, supervised learning has been observed to have a prominent role. Structured prediction is a form of supervised learning that enables learning models to operate on output spaces with complex structures. Through the lens of structured prediction, we show how robots can learn to imitate trajectories belonging to not only Euclidean spaces but also Riemannian manifolds. Exploiting ideas from information theory, we propose a class of loss functions based on the f-divergence to measure the information loss between the demonstrated and reproduced probabilistic trajectories. Different types of f-divergence will result in different policies, which we call imitation modes. Furthermore, our approach enables the incorporation of spatial and temporal trajectory modulation, which is necessary for robots to be adaptive to the change in working conditions. We benchmark our algorithm against state-of-the-art methods in terms of trajectory reproduction and adaptation. The quantitative evaluation shows that our approach outperforms other algorithms regarding both accuracy and efficiency. We also report real-world experimental results on learning manifold trajectories in a polishing task with a KUKA LWR robot arm, illustrating the effectiveness of our algorithmic framework.
ALEX: Towards Effective Graph Transfer Learning with Noisy Labels
Sep 26, 2023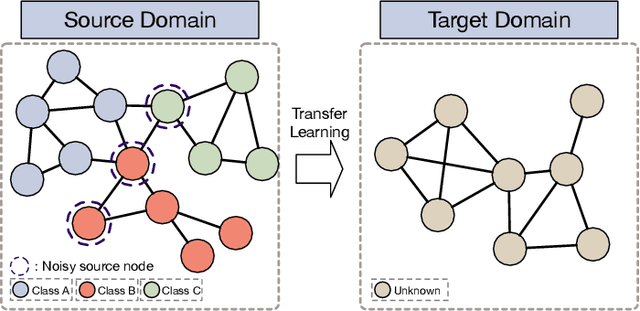
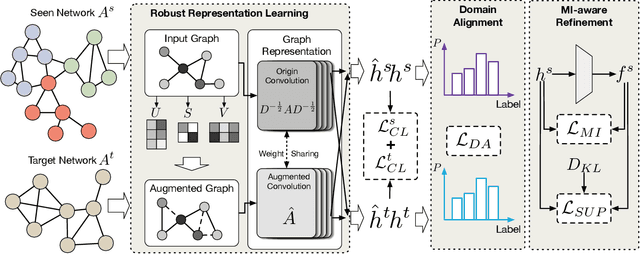
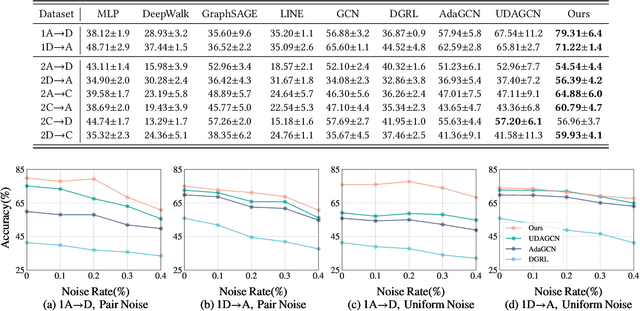
Graph Neural Networks (GNNs) have garnered considerable interest due to their exceptional performance in a wide range of graph machine learning tasks. Nevertheless, the majority of GNN-based approaches have been examined using well-annotated benchmark datasets, leading to suboptimal performance in real-world graph learning scenarios. To bridge this gap, the present paper investigates the problem of graph transfer learning in the presence of label noise, which transfers knowledge from a noisy source graph to an unlabeled target graph. We introduce a novel technique termed Balance Alignment and Information-aware Examination (ALEX) to address this challenge. ALEX first employs singular value decomposition to generate different views with crucial structural semantics, which help provide robust node representations using graph contrastive learning. To mitigate both label shift and domain shift, we estimate a prior distribution to build subgraphs with balanced label distributions. Building on this foundation, an adversarial domain discriminator is incorporated for the implicit domain alignment of complex multi-modal distributions. Furthermore, we project node representations into a different space, optimizing the mutual information between the projected features and labels. Subsequently, the inconsistency of similarity structures is evaluated to identify noisy samples with potential overfitting. Comprehensive experiments on various benchmark datasets substantiate the outstanding superiority of the proposed ALEX in different settings.
PARF: Primitive-Aware Radiance Fusion for Indoor Scene Novel View Synthesis
Sep 29, 2023This paper proposes a method for fast scene radiance field reconstruction with strong novel view synthesis performance and convenient scene editing functionality. The key idea is to fully utilize semantic parsing and primitive extraction for constraining and accelerating the radiance field reconstruction process. To fulfill this goal, a primitive-aware hybrid rendering strategy was proposed to enjoy the best of both volumetric and primitive rendering. We further contribute a reconstruction pipeline conducts primitive parsing and radiance field learning iteratively for each input frame which successfully fuses semantic, primitive, and radiance information into a single framework. Extensive evaluations demonstrate the fast reconstruction ability, high rendering quality, and convenient editing functionality of our method.
Proposal for an Organic Web, The missing link between the Web and the Semantic Web, Part 1
Sep 19, 2023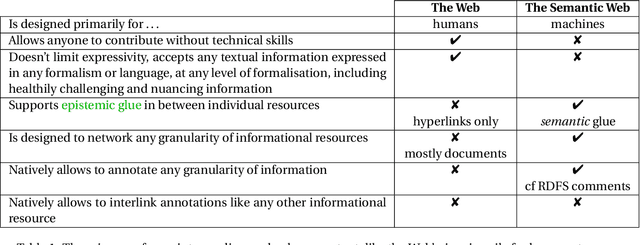
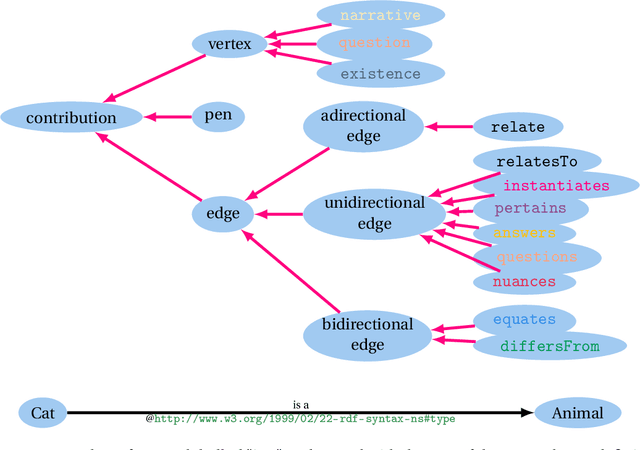
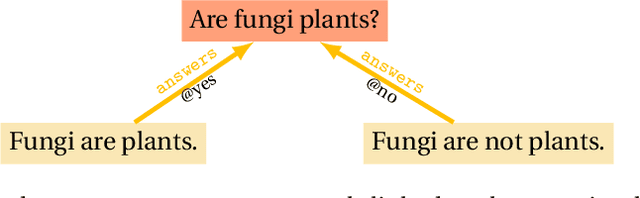
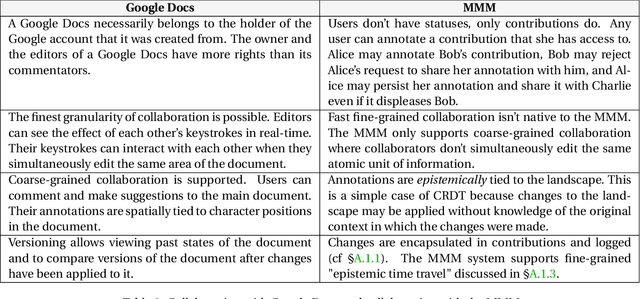
A huge amount of information is produced in digital form. The Semantic Web stems from the realisation that dealing efficiently with this production requires getting better at interlinking digital informational resources together. Its focus is on linking data. Linking data isn't enough. We need to provide infrastructural support for linking all sorts of informational resources including resources whose understanding and fine interlinking requires domain-specific human expertise. At times when many problems scale to planetary dimensions, it is essential to scale coordination of information processing and information production, without giving up on expertise and depth of analysis, nor forcing languages and formalisms onto thinkers, decision-makers and innovators that are only suitable to some forms of intelligence. This article makes a proposal in this direction and in line with the idea of interlinking championed by the Semantic Web.