 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Modern Approaches in 3D Scene Reconstruction: NeRF vs Gaussian-Based Methods
Aug 08, 2024Exploring the capabilities of Neural Radiance Fields (NeRF) and Gaussian-based methods in the context of 3D scene reconstruction, this study contrasts these modern approaches with traditional Simultaneous Localization and Mapping (SLAM) systems. Utilizing datasets such as Replica and ScanNet, we assess performance based on tracking accuracy, mapping fidelity, and view synthesis. Findings reveal that NeRF excels in view synthesis, offering unique capabilities in generating new perspectives from existing data, albeit at slower processing speeds. Conversely, Gaussian-based methods provide rapid processing and significant expressiveness but lack comprehensive scene completion. Enhanced by global optimization and loop closure techniques, newer methods like NICE-SLAM and SplaTAM not only surpass older frameworks such as ORB-SLAM2 in terms of robustness but also demonstrate superior performance in dynamic and complex environments. This comparative analysis bridges theoretical research with practical implications, shedding light on future developments in robust 3D scene reconstruction across various real-world applications.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023



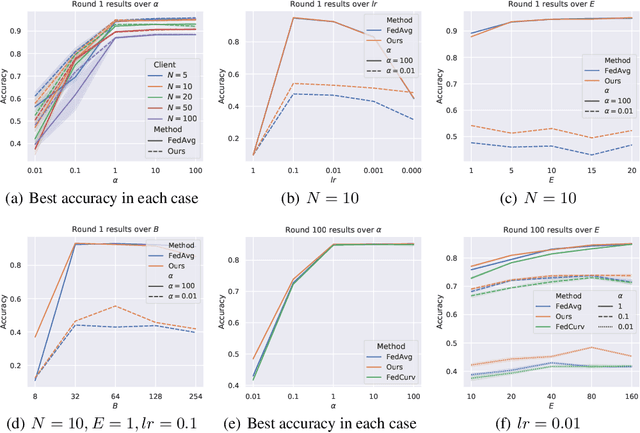
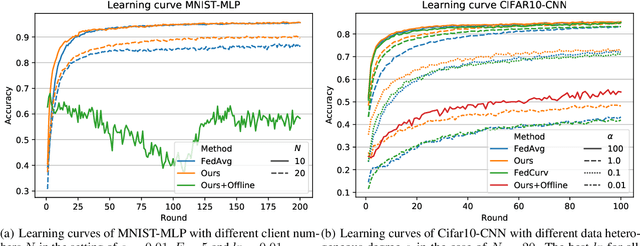
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
A Bayesian Federated Learning Framework with Multivariate Gaussian Product
Feb 03, 2021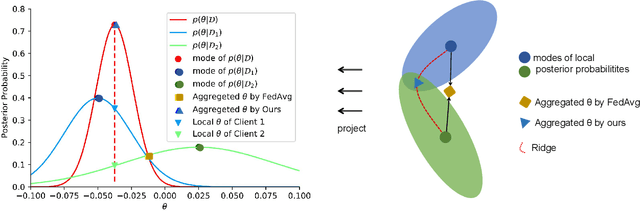
Federated learning (FL) allows multiple clients to collaboratively learn a globally shared model through cycles of model aggregation and local model training without the need to share data. In this paper, we comprehensively study a new problem named aggregation error (AE), arising from the model aggregation stage on a server, which is mainly induced by the heterogeneity of the client data. Due to the large discrepancies between local models, the accompanying large AE generally results in a slow convergence and an expected reduction of accuracy for FL. In order to reduce AE, we propose a novel federated learning framework from a Bayesian perspective, in which a multivariate Gaussian product mechanism is employed to aggregate the local models. It is worth noting that the product of Gaussians is still a Gaussian. This property allows us to directly aggregate local expectations and covariances in a definitely convex form, thereby greatly reducing the AE. Accordingly, on the clients, we develop a new Federated Online Laplace Approximation (FOLA) method, which can estimate the parameters of the local posterior by repeatedly accumulating priors. Specifically, in every round, the global posterior distributed from the server can be treated as the priors, and thus the local posterior can also be effectively approximated by a Gaussian using FOLA. Experimental results on benchmarks reach state-of-the-arts performance and clearly demonstrate the advantages of the proposed method.