 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Multi-Modality Learning for Multi-Label Skin Lesion Classification
Oct 28, 2023
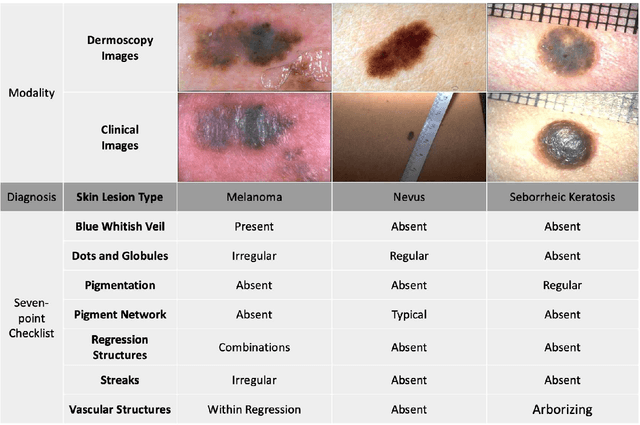
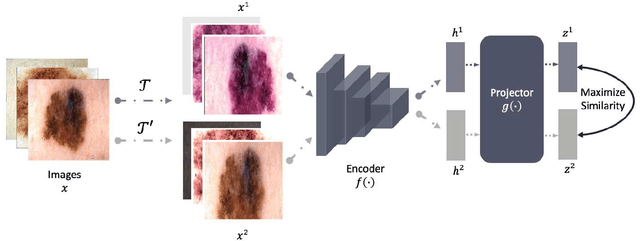
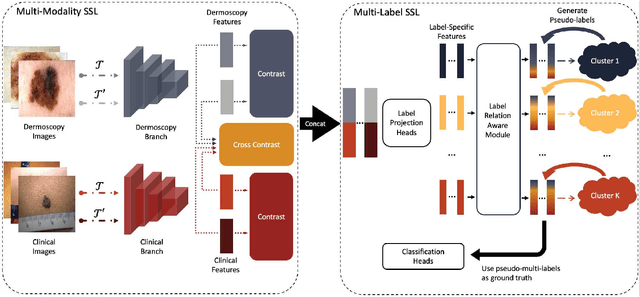
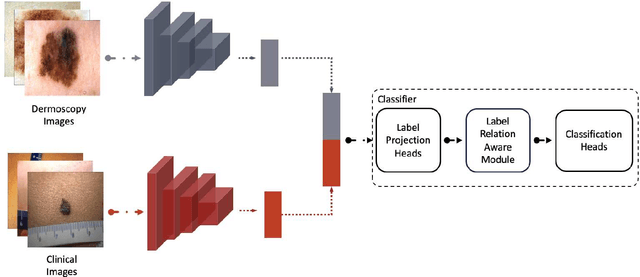
The clinical diagnosis of skin lesion involves the analysis of dermoscopic and clinical modalities. Dermoscopic images provide a detailed view of the surface structures whereas clinical images offer a complementary macroscopic information. The visual diagnosis of melanoma is also based on seven-point checklist which involves identifying different visual attributes. Recently, supervised learning approaches such as convolutional neural networks (CNNs) have shown great performances using both dermoscopic and clinical modalities (Multi-modality). The seven different visual attributes in the checklist are also used to further improve the the diagnosis. The performances of these approaches, however, are still reliant on the availability of large-scaled labeled data. The acquisition of annotated dataset is an expensive and time-consuming task, more so with annotating multi-attributes. To overcome this limitation, we propose a self-supervised learning (SSL) algorithm for multi-modality skin lesion classification. Our algorithm enables the multi-modality learning by maximizing the similarities between paired dermoscopic and clinical images from different views. In addition, we generate surrogate pseudo-multi-labels that represent seven attributes via clustering analysis. We also propose a label-relation-aware module to refine each pseudo-label embedding and capture the interrelationships between pseudo-multi-labels. We validated the effectiveness of our algorithm using well-benchmarked seven-point skin lesion dataset. Our results show that our algorithm achieved better performances than other state-of-the-art SSL counterparts.
A General Framework for Robust G-Invariance in G-Equivariant Networks
Oct 28, 2023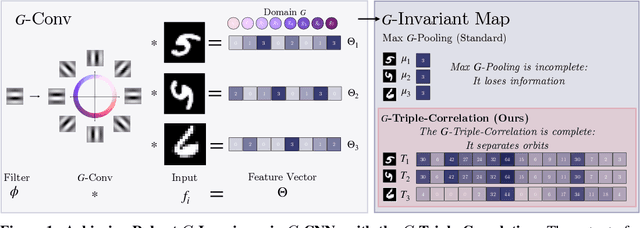
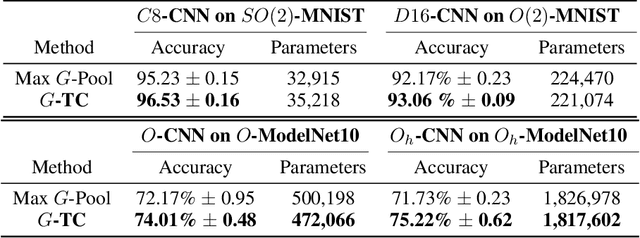


We introduce a general method for achieving robust group-invariance in group-equivariant convolutional neural networks ($G$-CNNs), which we call the $G$-triple-correlation ($G$-TC) layer. The approach leverages the theory of the triple-correlation on groups, which is the unique, lowest-degree polynomial invariant map that is also complete. Many commonly used invariant maps - such as the max - are incomplete: they remove both group and signal structure. A complete invariant, by contrast, removes only the variation due to the actions of the group, while preserving all information about the structure of the signal. The completeness of the triple correlation endows the $G$-TC layer with strong robustness, which can be observed in its resistance to invariance-based adversarial attacks. In addition, we observe that it yields measurable improvements in classification accuracy over standard Max $G$-Pooling in $G$-CNN architectures. We provide a general and efficient implementation of the method for any discretized group, which requires only a table defining the group's product structure. We demonstrate the benefits of this method for $G$-CNNs defined on both commutative and non-commutative groups - $SO(2)$, $O(2)$, $SO(3)$, and $O(3)$ (discretized as the cyclic $C8$, dihedral $D16$, chiral octahedral $O$ and full octahedral $O_h$ groups) - acting on $\mathbb{R}^2$ and $\mathbb{R}^3$ on both $G$-MNIST and $G$-ModelNet10 datasets.
Spacecraft Autonomous Decision-Planning for Collision Avoidance: a Reinforcement Learning Approach
Oct 29, 2023The space environment around the Earth is becoming increasingly populated by both active spacecraft and space debris. To avoid potential collision events, significant improvements in Space Situational Awareness (SSA) activities and Collision Avoidance (CA) technologies are allowing the tracking and maneuvering of spacecraft with increasing accuracy and reliability. However, these procedures still largely involve a high level of human intervention to make the necessary decisions. For an increasingly complex space environment, this decision-making strategy is not likely to be sustainable. Therefore, it is important to successfully introduce higher levels of automation for key Space Traffic Management (STM) processes to ensure the level of reliability needed for navigating a large number of spacecraft. These processes range from collision risk detection to the identification of the appropriate action to take and the execution of avoidance maneuvers. This work proposes an implementation of autonomous CA decision-making capabilities on spacecraft based on Reinforcement Learning (RL) techniques. A novel methodology based on a Partially Observable Markov Decision Process (POMDP) framework is developed to train the Artificial Intelligence (AI) system on board the spacecraft, considering epistemic and aleatory uncertainties. The proposed framework considers imperfect monitoring information about the status of the debris in orbit and allows the AI system to effectively learn stochastic policies to perform accurate Collision Avoidance Maneuvers (CAMs). The objective is to successfully delegate the decision-making process for autonomously implementing a CAM to the spacecraft without human intervention. This approach would allow for a faster response in the decision-making process and for highly decentralized operations.
Improved Motor Imagery Classification Using Adaptive Spatial Filters Based on Particle Swarm Optimization Algorithm
Oct 29, 2023As a typical self-paced brain-computer interface (BCI) system, the motor imagery (MI) BCI has been widely applied in fields such as robot control, stroke rehabilitation, and assistance for patients with stroke or spinal cord injury. Many studies have focused on the traditional spatial filters obtained through the common spatial pattern (CSP) method. However, the CSP method can only obtain fixed spatial filters for specific input signals. Besides, CSP method only focuses on the variance difference of two types of electroencephalogram (EEG) signals, so the decoding ability of EEG signals is limited. To obtain more effective spatial filters for better extraction of spatial features that can improve classification to MI-EEG, this paper proposes an adaptive spatial filter solving method based on particle swarm optimization algorithm (PSO). A training and testing framework based on filter bank and spatial filters (FBCSP-ASP) is designed for MI EEG signal classification. Comparative experiments are conducted on two public datasets (2a and 2b) from BCI competition IV, which show the outstanding average recognition accuracy of FBCSP-ASP. The proposed method has achieved significant performance improvement on MI-BCI. The classification accuracy of the proposed method has reached 74.61% and 81.19% on datasets 2a and 2b, respectively. Compared with the baseline algorithm (FBCSP), the proposed algorithm improves 11.44% and 7.11% on two datasets respectively. Furthermore, the analysis based on mutual information, t-SNE and Shapley values further proves that ASP features have excellent decoding ability for MI-EEG signals, and explains the improvement of classification performance by the introduction of ASP features.
FusionU-Net: U-Net with Enhanced Skip Connection for Pathology Image Segmentation
Oct 17, 2023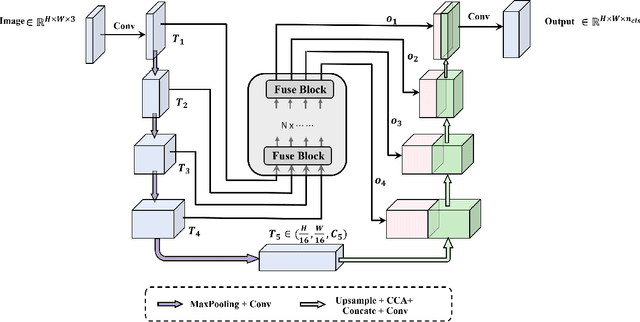
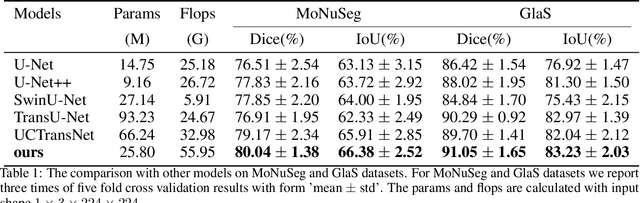
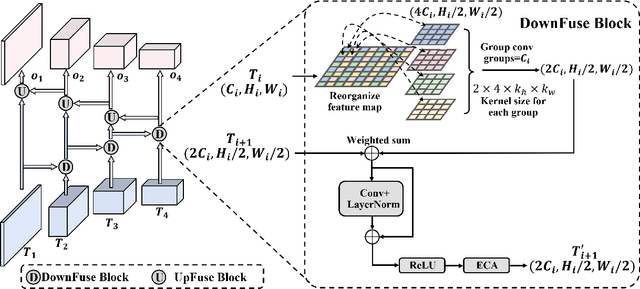
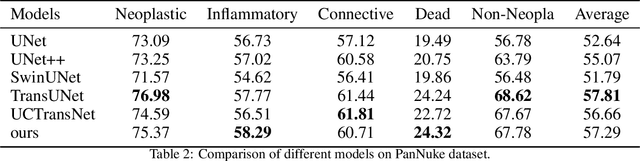
In recent years, U-Net and its variants have been widely used in pathology image segmentation tasks. One of the key designs of U-Net is the use of skip connections between the encoder and decoder, which helps to recover detailed information after upsampling. While most variations of U-Net adopt the original skip connection design, there is semantic gap between the encoder and decoder that can negatively impact model performance. Therefore, it is important to reduce this semantic gap before conducting skip connection. To address this issue, we propose a new segmentation network called FusionU-Net, which is based on U-Net structure and incorporates a fusion module to exchange information between different skip connections to reduce semantic gaps. Unlike the other fusion modules in existing networks, ours is based on a two-round fusion design that fully considers the local relevance between adjacent encoder layer outputs and the need for bi-directional information exchange across multiple layers. We conducted extensive experiments on multiple pathology image datasets to evaluate our model and found that FusionU-Net achieves better performance compared to other competing methods. We argue our fusion module is more effective than the designs of existing networks, and it could be easily embedded into other networks to further enhance the model performance.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 16, 2023Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
Gold: A Global and Local-aware Denoising Framework for Commonsense Knowledge Graph Noise Detection
Oct 18, 2023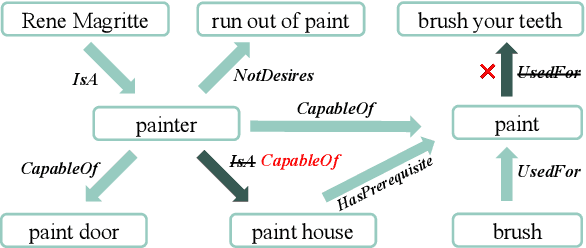
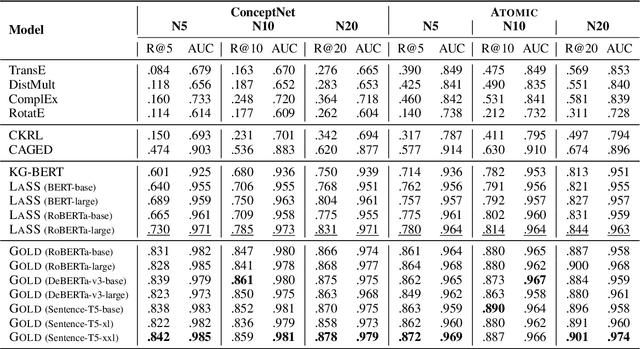
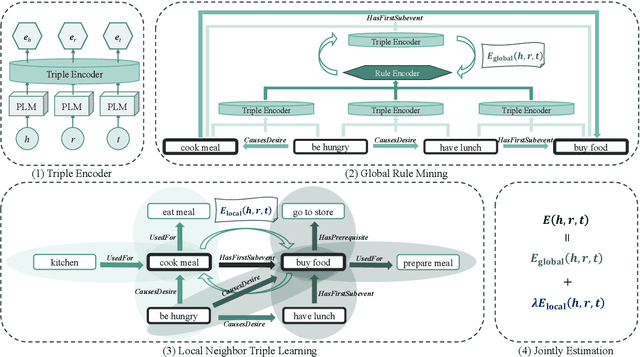
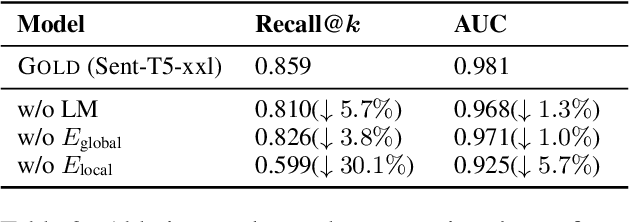
Commonsense Knowledge Graphs (CSKGs) are crucial for commonsense reasoning, yet constructing them through human annotations can be costly. As a result, various automatic methods have been proposed to construct CSKG with larger semantic coverage. However, these unsupervised approaches introduce spurious noise that can lower the quality of the resulting CSKG, which cannot be tackled easily by existing denoising algorithms due to the unique characteristics of nodes and structures in CSKGs. To address this issue, we propose Gold (Global and Local-aware Denoising), a denoising framework for CSKGs that incorporates entity semantic information, global rules, and local structural information from the CSKG. Experiment results demonstrate that Gold outperforms all baseline methods in noise detection tasks on synthetic noisy CSKG benchmarks. Furthermore, we show that denoising a real-world CSKG is effective and even benefits the downstream zero-shot commonsense question-answering task.
A New Multimodal Medical Image Fusion based on Laplacian Autoencoder with Channel Attention
Oct 18, 2023Medical image fusion combines the complementary information of multimodal medical images to assist medical professionals in the clinical diagnosis of patients' disorders and provide guidance during preoperative and intra-operative procedures. Deep learning (DL) models have achieved end-to-end image fusion with highly robust and accurate fusion performance. However, most DL-based fusion models perform down-sampling on the input images to minimize the number of learnable parameters and computations. During this process, salient features of the source images become irretrievable leading to the loss of crucial diagnostic edge details and contrast of various brain tissues. In this paper, we propose a new multimodal medical image fusion model is proposed that is based on integrated Laplacian-Gaussian concatenation with attention pooling (LGCA). We prove that our model preserves effectively complementary information and important tissue structures.
An Improved Artificial Fish Swarm Algorithm for Solving the Problem of Investigation Path Planning
Oct 20, 2023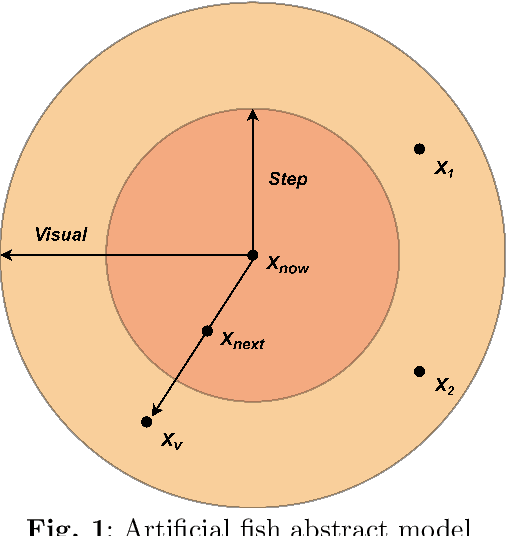

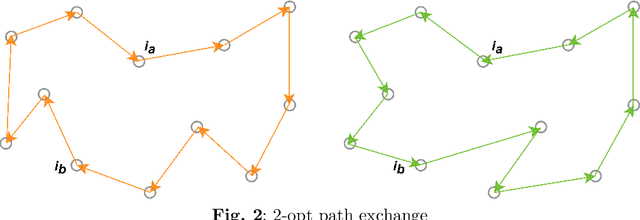

Informationization is a prevailing trend in today's world. The increasing demand for information in decision-making processes poses significant challenges for investigation activities, particularly in terms of effectively allocating limited resources to plan investigation programs. This paper addresses the investigation path planning problem by formulating it as a multi-traveling salesman problem (MTSP). Our objective is to minimize costs, and to achieve this, we propose a chaotic artificial fish swarm algorithm based on multiple population differential evolution (DE-CAFSA). To overcome the limitations of the artificial fish swarm algorithm, such as low optimization accuracy and the inability to consider global and local information, we incorporate adaptive field of view and step size adjustments, replace random behavior with the 2-opt operation, and introduce chaos theory and sub-optimal solutions to enhance optimization accuracy and search performance. Additionally, we integrate the differential evolution algorithm to create a hybrid algorithm that leverages the complementary advantages of both approaches. Experimental results demonstrate that DE-CAFSA outperforms other algorithms on various public datasets of different sizes, as well as showcasing excellent performance on the examples proposed in this study.
Weighted Joint Maximum Mean Discrepancy Enabled Multi-Source-Multi-Target Unsupervised Domain Adaptation Fault Diagnosis
Oct 20, 2023Despite the remarkable results that can be achieved by data-driven intelligent fault diagnosis techniques, they presuppose the same distribution of training and test data as well as sufficient labeled data. Various operating states often exist in practical scenarios, leading to the problem of domain shift that hinders the effectiveness of fault diagnosis. While recent unsupervised domain adaptation methods enable cross-domain fault diagnosis, they struggle to effectively utilize information from multiple source domains and achieve effective diagnosis faults in multiple target domains simultaneously. In this paper, we innovatively proposed a weighted joint maximum mean discrepancy enabled multi-source-multi-target unsupervised domain adaptation (WJMMD-MDA), which realizes domain adaptation under multi-source-multi-target scenarios in the field of fault diagnosis for the first time. The proposed method extracts sufficient information from multiple labeled source domains and achieves domain alignment between source and target domains through an improved weighted distance loss. As a result, domain-invariant and discriminative features between multiple source and target domains are learned with cross-domain fault diagnosis realized. The performance of the proposed method is evaluated in comprehensive comparative experiments on three datasets, and the experimental results demonstrate the superiority of this method.