 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LesionMix: A Lesion-Level Data Augmentation Method for Medical Image Segmentation
Aug 17, 2023
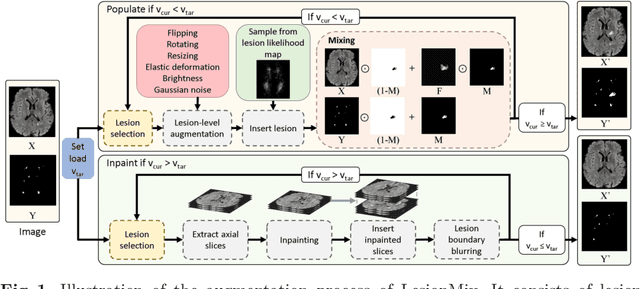

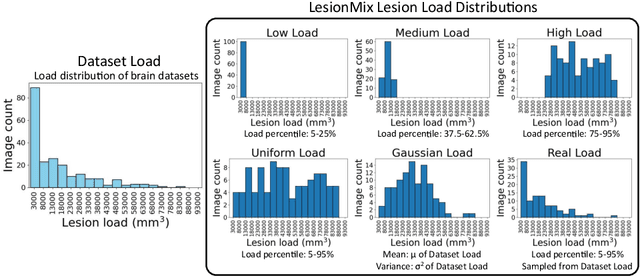
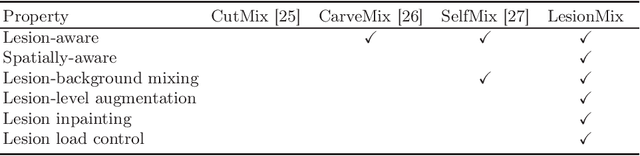
Data augmentation has become a de facto component of deep learning-based medical image segmentation methods. Most data augmentation techniques used in medical imaging focus on spatial and intensity transformations to improve the diversity of training images. They are often designed at the image level, augmenting the full image, and do not pay attention to specific abnormalities within the image. Here, we present LesionMix, a novel and simple lesion-aware data augmentation method. It performs augmentation at the lesion level, increasing the diversity of lesion shape, location, intensity and load distribution, and allowing both lesion populating and inpainting. Experiments on different modalities and different lesion datasets, including four brain MR lesion datasets and one liver CT lesion dataset, demonstrate that LesionMix achieves promising performance in lesion image segmentation, outperforming several recent Mix-based data augmentation methods. The code will be released at https://github.com/dogabasaran/lesionmix.
Multi-Depth Branches Network for Efficient Image Super-Resolution
Sep 29, 2023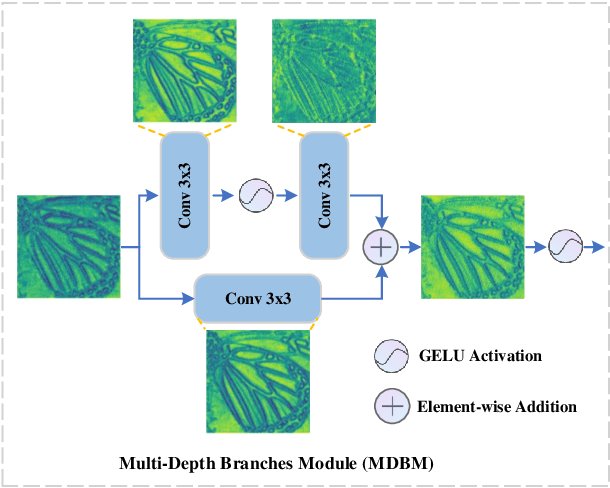
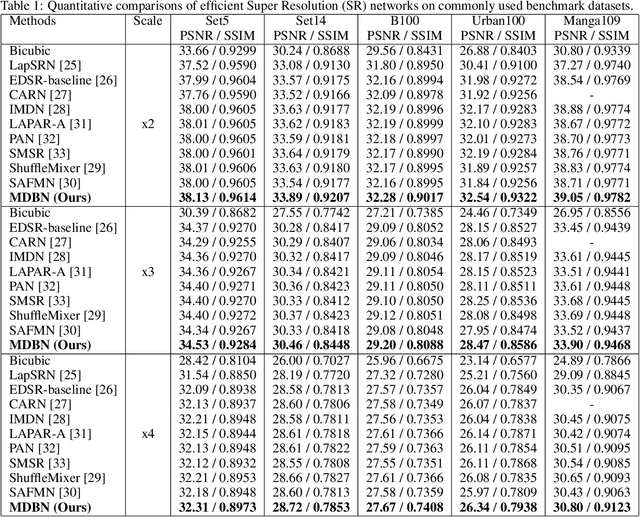
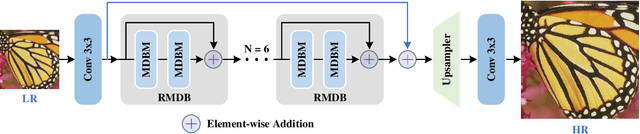
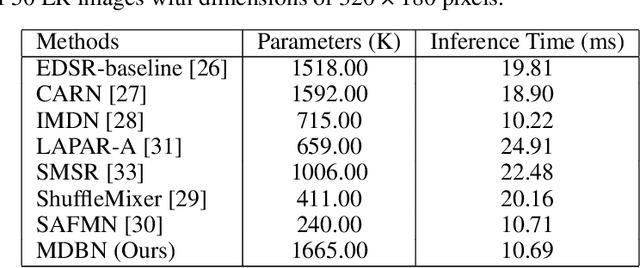
Significant progress has been made in the field of super-resolution (SR), yet many convolutional neural networks (CNNs) based SR models primarily focus on restoring high-frequency details, often overlooking crucial low-frequency contour information. Transformer-based SR methods, while incorporating global structural details, frequently come with an abundance of parameters, leading to high computational overhead. In this paper, we address these challenges by introducing a Multi-Depth Branches Network (MDBN). This framework extends the ResNet architecture by integrating an additional branch that captures vital structural characteristics of images. Our proposed multi-depth branches module (MDBM) involves the stacking of convolutional kernels of identical size at varying depths within distinct branches. By conducting a comprehensive analysis of the feature maps, we observe that branches with differing depths can extract contour and detail information respectively. By integrating these branches, the overall architecture can preserve essential low-frequency semantic structural information during the restoration of high-frequency visual elements, which is more closely with human visual cognition. Compared to GoogLeNet-like models, our basic multi-depth branches structure has fewer parameters, higher computational efficiency, and improved performance. Our model outperforms state-of-the-art (SOTA) lightweight SR methods with less inference time. Our code is available at https://github.com/thy960112/MDBN
Predicting Ovarian Cancer Treatment Response in Histopathology using Hierarchical Vision Transformers and Multiple Instance Learning
Oct 19, 2023
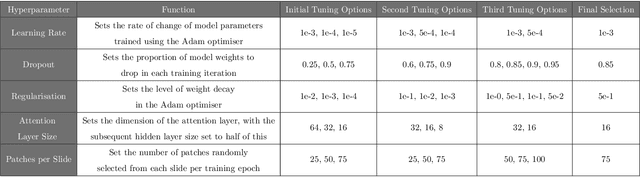
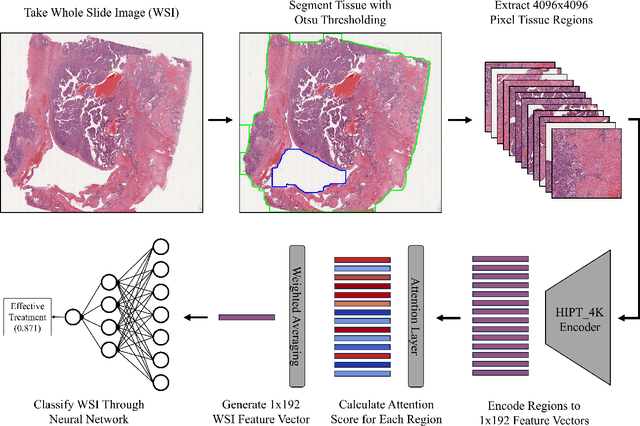

For many patients, current ovarian cancer treatments offer limited clinical benefit. For some therapies, it is not possible to predict patients' responses, potentially exposing them to the adverse effects of treatment without any therapeutic benefit. As part of the automated prediction of treatment effectiveness in ovarian cancer using histopathological images (ATEC23) challenge, we evaluated the effectiveness of deep learning to predict whether a course of treatment including the antiangiogenic drug bevacizumab could contribute to remission or prevent disease progression for at least 6 months in a set of 282 histopathology whole slide images (WSIs) from 78 ovarian cancer patients. Our approach used a pretrained Hierarchical Image Pyramid Transformer (HIPT) to extract region-level features and an attention-based multiple instance learning (ABMIL) model to aggregate features and classify whole slides. The optimal HIPT-ABMIL model had an internal balanced accuracy of 60.2% +- 2.9% and an AUC of 0.646 +- 0.033. Histopathology-specific model pretraining was found to be beneficial to classification performance, though hierarchical transformers were not, with a ResNet feature extractor achieving similar performance. Due to the dataset being small and highly heterogeneous, performance was variable across 5-fold cross-validation folds, and there were some extreme differences between validation and test set performance within folds. The model did not generalise well to tissue microarrays, with accuracy worse than random chance. It is not yet clear whether ovarian cancer WSIs contain information that can be used to accurately predict treatment response, with further validation using larger, higher-quality datasets required.
rpcPRF: Generalizable MPI Neural Radiance Field for Satellite Camera
Oct 11, 2023Novel view synthesis of satellite images holds a wide range of practical applications. While recent advances in the Neural Radiance Field have predominantly targeted pin-hole cameras, and models for satellite cameras often demand sufficient input views. This paper presents rpcPRF, a Multiplane Images (MPI) based Planar neural Radiance Field for Rational Polynomial Camera (RPC). Unlike coordinate-based neural radiance fields in need of sufficient views of one scene, our model is applicable to single or few inputs and performs well on images from unseen scenes. To enable generalization across scenes, we propose to use reprojection supervision to induce the predicted MPI to learn the correct geometry between the 3D coordinates and the images. Moreover, we remove the stringent requirement of dense depth supervision from deep multiview-stereo-based methods by introducing rendering techniques of radiance fields. rpcPRF combines the superiority of implicit representations and the advantages of the RPC model, to capture the continuous altitude space while learning the 3D structure. Given an RGB image and its corresponding RPC, the end-to-end model learns to synthesize the novel view with a new RPC and reconstruct the altitude of the scene. When multiple views are provided as inputs, rpcPRF exerts extra supervision provided by the extra views. On the TLC dataset from ZY-3, and the SatMVS3D dataset with urban scenes from WV-3, rpcPRF outperforms state-of-the-art nerf-based methods by a significant margin in terms of image fidelity, reconstruction accuracy, and efficiency, for both single-view and multiview task.
Does resistance to Style-Transfer equal Shape Bias? Evaluating Shape Bias by Distorted Shape
Oct 11, 2023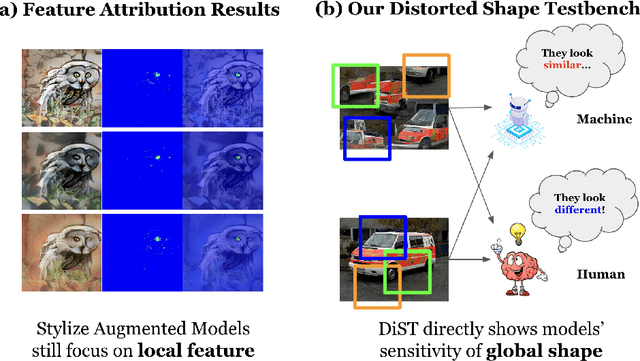
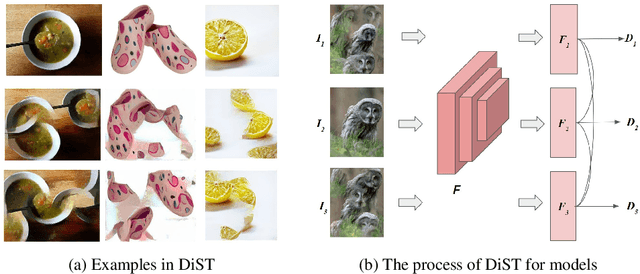
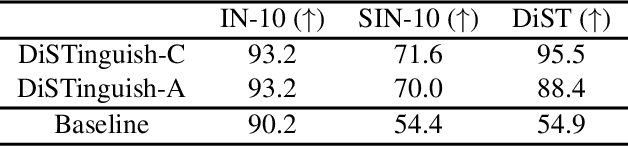
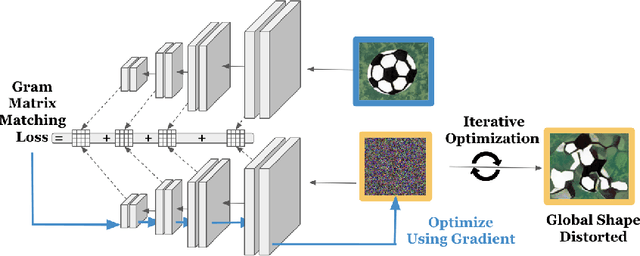
Deep learning models are known to exhibit a strong texture bias, while human tends to rely heavily on global shape for object recognition. The current benchmark for evaluating a model's shape bias is a set of style-transferred images with the assumption that resistance to the attack of style transfer is related to the development of shape sensitivity in the model. In this work, we show that networks trained with style-transfer images indeed learn to ignore style, but its shape bias arises primarily from local shapes. We provide a Distorted Shape Testbench (DiST) as an alternative measurement of global shape sensitivity. Our test includes 2400 original images from ImageNet-1K, each of which is accompanied by two images with the global shapes of the original image distorted while preserving its texture via the texture synthesis program. We found that (1) models that performed well on the previous shape bias evaluation do not fare well in the proposed DiST; (2) the widely adopted ViT models do not show significant advantages over Convolutional Neural Networks (CNNs) on this benchmark despite that ViTs rank higher on the previous shape bias tests. (3) training with DiST images bridges the significant gap between human and existing SOTA models' performance while preserving the models' accuracy on standard image classification tasks; training with DiST images and style-transferred images are complementary, and can be combined to train network together to enhance both the global and local shape sensitivity of the network. Our code will be host at: https://github.com/leelabcnbc/DiST
GPS Attack Detection and Mitigation for Safe Autonomous Driving using Image and Map based Lateral Direction Localization
Oct 09, 2023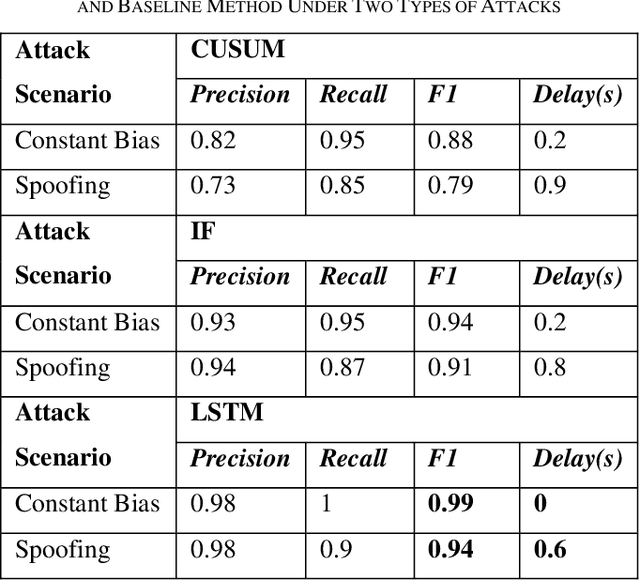
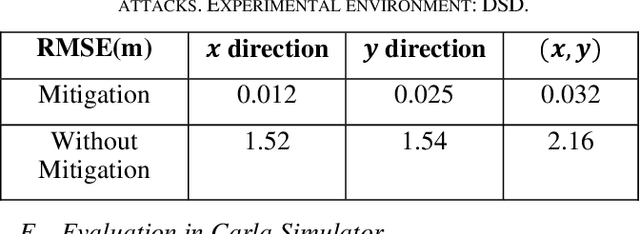
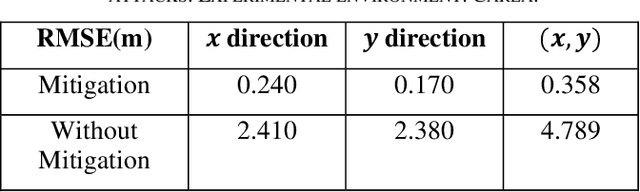
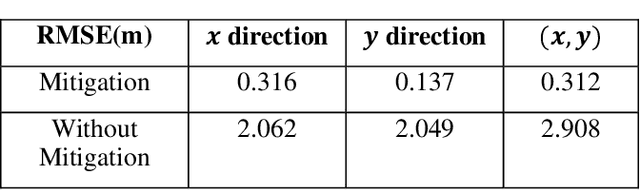
The accuracy and robustness of vehicle localization are critical for achieving safe and reliable high-level autonomy. Recent results show that GPS is vulnerable to spoofing attacks, which is one major threat to autonomous driving. In this paper, a novel anomaly detection and mitigation method against GPS attacks that utilizes onboard camera and high-precision maps is proposed to ensure accurate vehicle localization. First, lateral direction localization in driving lanes is calculated by camera-based lane detection and map matching respectively. Then, a real-time detector for GPS spoofing attack is developed to evaluate the localization data. When the attack is detected, a multi-source fusion-based localization method using Unscented Kalman filter is derived to mitigate GPS attack and improve the localization accuracy. The proposed method is validated in various scenarios in Carla simulator and open-source public dataset to demonstrate its effectiveness in timely GPS attack detection and data recovery.
Technical Report for ICCV 2023 Visual Continual Learning Challenge: Continuous Test-time Adaptation for Semantic Segmentation
Oct 20, 2023The goal of the challenge is to develop a test-time adaptation (TTA) method, which could adapt the model to gradually changing domains in video sequences for semantic segmentation task. It is based on a synthetic driving video dataset - SHIFT. The source model is trained on images taken during daytime in clear weather. Domain changes at test-time are mainly caused by varying weather conditions and times of day. The TTA methods are evaluated in each image sequence (video) separately, meaning the model is reset to the source model state before the next sequence. Images come one by one and a prediction has to be made at the arrival of each frame. Each sequence is composed of 401 images and starts with the source domain, then gradually drifts to a different one (changing weather or time of day) until the middle of the sequence. In the second half of the sequence, the domain gradually shifts back to the source one. Ground truth data is available only for the validation split of the SHIFT dataset, in which there are only six sequences that start and end with the source domain. We conduct an analysis specifically on those sequences. Ground truth data for test split, on which the developed TTA methods are evaluated for leader board ranking, are not publicly available. The proposed solution secured a 3rd place in a challenge and received an innovation award. Contrary to the solutions that scored better, we did not use any external pretrained models or specialized data augmentations, to keep the solutions as general as possible. We have focused on analyzing the distributional shift and developing a method that could adapt to changing data dynamics and generalize across different scenarios.
MosaiQ: Quantum Generative Adversarial Networks for Image Generation on NISQ Computers
Aug 22, 2023Quantum machine learning and vision have come to the fore recently, with hardware advances enabling rapid advancement in the capabilities of quantum machines. Recently, quantum image generation has been explored with many potential advantages over non-quantum techniques; however, previous techniques have suffered from poor quality and robustness. To address these problems, we introduce, MosaiQ, a high-quality quantum image generation GAN framework that can be executed on today's Near-term Intermediate Scale Quantum (NISQ) computers.
Balance Act: Mitigating Hubness in Cross-Modal Retrieval with Query and Gallery Banks
Oct 17, 2023In this work, we present a post-processing solution to address the hubness problem in cross-modal retrieval, a phenomenon where a small number of gallery data points are frequently retrieved, resulting in a decline in retrieval performance. We first theoretically demonstrate the necessity of incorporating both the gallery and query data for addressing hubness as hubs always exhibit high similarity with gallery and query data. Second, building on our theoretical results, we propose a novel framework, Dual Bank Normalization (DBNorm). While previous work has attempted to alleviate hubness by only utilizing the query samples, DBNorm leverages two banks constructed from the query and gallery samples to reduce the occurrence of hubs during inference. Next, to complement DBNorm, we introduce two novel methods, dual inverted softmax and dual dynamic inverted softmax, for normalizing similarity based on the two banks. Specifically, our proposed methods reduce the similarity between hubs and queries while improving the similarity between non-hubs and queries. Finally, we present extensive experimental results on diverse language-grounded benchmarks, including text-image, text-video, and text-audio, demonstrating the superior performance of our approaches compared to previous methods in addressing hubness and boosting retrieval performance. Our code is available at https://github.com/yimuwangcs/Better_Cross_Modal_Retrieval.
Elucidating The Design Space of Classifier-Guided Diffusion Generation
Oct 17, 2023Guidance in conditional diffusion generation is of great importance for sample quality and controllability. However, existing guidance schemes are to be desired. On one hand, mainstream methods such as classifier guidance and classifier-free guidance both require extra training with labeled data, which is time-consuming and unable to adapt to new conditions. On the other hand, training-free methods such as universal guidance, though more flexible, have yet to demonstrate comparable performance. In this work, through a comprehensive investigation into the design space, we show that it is possible to achieve significant performance improvements over existing guidance schemes by leveraging off-the-shelf classifiers in a training-free fashion, enjoying the best of both worlds. Employing calibration as a general guideline, we propose several pre-conditioning techniques to better exploit pretrained off-the-shelf classifiers for guiding diffusion generation. Extensive experiments on ImageNet validate our proposed method, showing that state-of-the-art diffusion models (DDPM, EDM, DiT) can be further improved (up to 20%) using off-the-shelf classifiers with barely any extra computational cost. With the proliferation of publicly available pretrained classifiers, our proposed approach has great potential and can be readily scaled up to text-to-image generation tasks. The code is available at https://github.com/AlexMaOLS/EluCD/tree/main.