 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Camera-LiDAR Fusion with Latent Contact for Place Recognition in Challenging Cross-Scenes
Oct 16, 2023

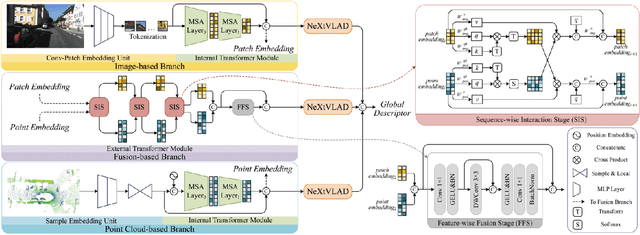
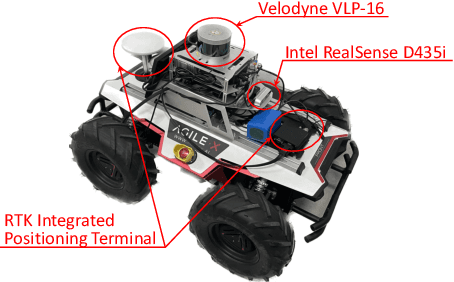

Although significant progress has been made, achieving place recognition in environments with perspective changes, seasonal variations, and scene transformations remains challenging. Relying solely on perception information from a single sensor is insufficient to address these issues. Recognizing the complementarity between cameras and LiDAR, multi-modal fusion methods have attracted attention. To address the information waste in existing multi-modal fusion works, this paper introduces a novel three-channel place descriptor, which consists of a cascade of image, point cloud, and fusion branches. Specifically, the fusion-based branch employs a dual-stage pipeline, leveraging the correlation between the two modalities with latent contacts, thereby facilitating information interaction and fusion. Extensive experiments on the KITTI, NCLT, USVInland, and the campus dataset demonstrate that the proposed place descriptor stands as the state-of-the-art approach, confirming its robustness and generality in challenging scenarios.
A Survey of Diffusion Based Image Generation Models: Issues and Their Solutions
Aug 25, 2023Recently, there has been significant progress in the development of large models. Following the success of ChatGPT, numerous language models have been introduced, demonstrating remarkable performance. Similar advancements have also been observed in image generation models, such as Google's Imagen model, OpenAI's DALL-E 2, and stable diffusion models, which have exhibited impressive capabilities in generating images. However, similar to large language models, these models still encounter unresolved challenges. Fortunately, the availability of open-source stable diffusion models and their underlying mathematical principles has enabled the academic community to extensively analyze the performance of current image generation models and make improvements based on this stable diffusion framework. This survey aims to examine the existing issues and the current solutions pertaining to image generation models.
VI-Diff: Unpaired Visible-Infrared Translation Diffusion Model for Single Modality Labeled Visible-Infrared Person Re-identification
Oct 06, 2023Visible-Infrared person re-identification (VI-ReID) in real-world scenarios poses a significant challenge due to the high cost of cross-modality data annotation. Different sensing cameras, such as RGB/IR cameras for good/poor lighting conditions, make it costly and error-prone to identify the same person across modalities. To overcome this, we explore the use of single-modality labeled data for the VI-ReID task, which is more cost-effective and practical. By labeling pedestrians in only one modality (e.g., visible images) and retrieving in another modality (e.g., infrared images), we aim to create a training set containing both originally labeled and modality-translated data using unpaired image-to-image translation techniques. In this paper, we propose VI-Diff, a diffusion model that effectively addresses the task of Visible-Infrared person image translation. Through comprehensive experiments, we demonstrate that VI-Diff outperforms existing diffusion and GAN models, making it a promising solution for VI-ReID with single-modality labeled data. Our approach can be a promising solution to the VI-ReID task with single-modality labeled data and serves as a good starting point for future study. Code will be available.
Boosting Weakly-Supervised Image Segmentation via Representation, Transform, and Compensator
Sep 02, 2023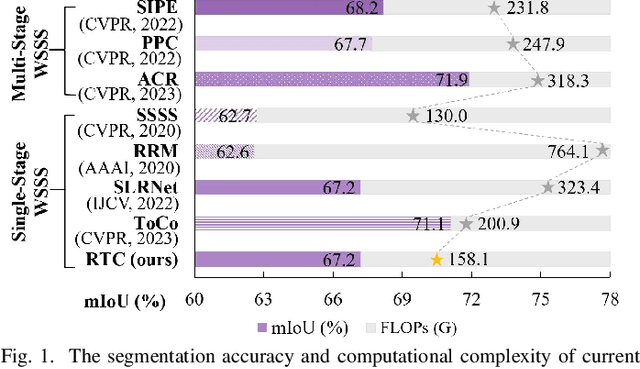

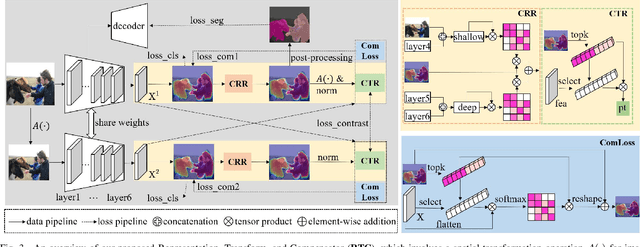
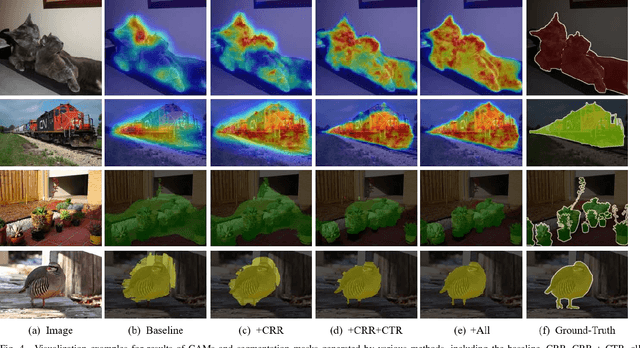
Weakly-supervised image segmentation (WSIS) is a critical task in computer vision that relies on image-level class labels. Multi-stage training procedures have been widely used in existing WSIS approaches to obtain high-quality pseudo-masks as ground-truth, resulting in significant progress. However, single-stage WSIS methods have recently gained attention due to their potential for simplifying training procedures, despite often suffering from low-quality pseudo-masks that limit their practical applications. To address this issue, we propose a novel single-stage WSIS method that utilizes a siamese network with contrastive learning to improve the quality of class activation maps (CAMs) and achieve a self-refinement process. Our approach employs a cross-representation refinement method that expands reliable object regions by utilizing different feature representations from the backbone. Additionally, we introduce a cross-transform regularization module that learns robust class prototypes for contrastive learning and captures global context information to feed back rough CAMs, thereby improving the quality of CAMs. Our final high-quality CAMs are used as pseudo-masks to supervise the segmentation result. Experimental results on the PASCAL VOC 2012 dataset demonstrate that our method significantly outperforms other state-of-the-art methods, achieving 67.2% and 68.76% mIoU on PASCAL VOC 2012 val set and test set, respectively. Furthermore, our method has been extended to weakly supervised object localization task, and experimental results demonstrate that our method continues to achieve very competitive results.
MultiWay-Adapater: Adapting large-scale multi-modal models for scalable image-text retrieval
Sep 12, 2023As the size of Large Multi-Modal Models (LMMs) increases consistently, the adaptation of these pre-trained models to specialized tasks has become a computationally and memory-intensive challenge. Traditional fine-tuning methods require isolated, exhaustive retuning for each new task, limiting the models' versatility. Moreover, current efficient adaptation techniques often overlook modality alignment, focusing only on the knowledge extraction of new tasks. To tackle these issues, we introduce Multiway-Adapter, an innovative framework incorporating an 'Alignment Enhancer' to deepen modality alignment, enabling high transferability without tuning pre-trained parameters. Our method adds fewer than 1.25\% of additional parameters to LMMs, exemplified by the BEiT-3 model in our study. This leads to superior zero-shot image-text retrieval performance compared to fully fine-tuned models, while achieving up to a 57\% reduction in fine-tuning time. Our approach offers a resource-efficient and effective adaptation pathway for LMMs, broadening their applicability. The source code is publicly available at: \url{https://github.com/longkukuhi/MultiWay-Adapter}.
Adaptive Multi-head Contrastive Learning
Oct 09, 2023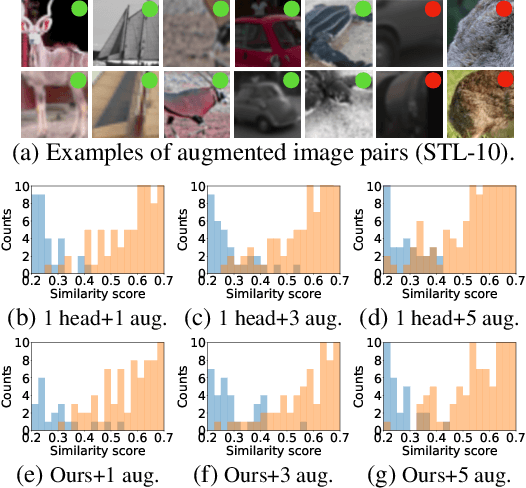
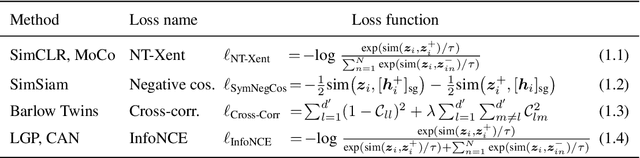
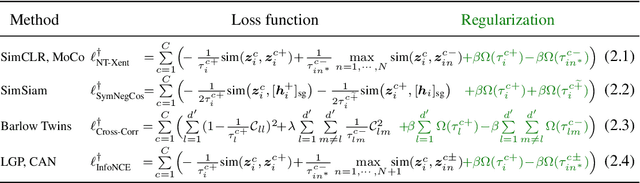
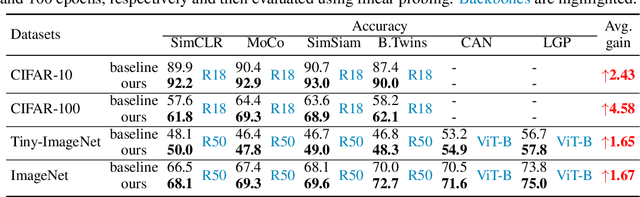
In contrastive learning, two views of an original image generated by different augmentations are considered as a positive pair whose similarity is required to be high. Moreover, two views of two different images are considered as a negative pair, and their similarity is encouraged to be low. Normally, a single similarity measure given by a single projection head is used to evaluate positive and negative sample pairs, respectively. However, due to the various augmentation strategies and varying intra-sample similarity, augmented views from the same image are often not similar. Moreover, due to inter-sample similarity, augmented views of two different images may be more similar than augmented views from the same image. As such, enforcing a high similarity for positive pairs and a low similarity for negative pairs may not always be achievable, and in the case of some pairs, forcing so may be detrimental to the performance. To address this issue, we propose to use multiple projection heads, each producing a separate set of features. Our loss function for pre-training emerges from a solution to the maximum likelihood estimation over head-wise posterior distributions of positive samples given observations. The loss contains the similarity measure over positive and negative pairs, each re-weighted by an individual adaptive temperature that is regularized to prevent ill solutions. Our adaptive multi-head contrastive learning (AMCL) can be applied to and experimentally improves several popular contrastive learning methods such as SimCLR, MoCo and Barlow Twins. Such improvement is consistent under various backbones and linear probing epoches and is more significant when multiple augmentation methods are used.
S4C: Self-Supervised Semantic Scene Completion with Neural Fields
Oct 11, 2023


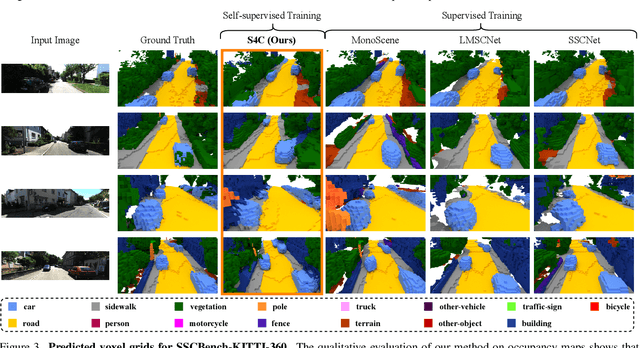
3D semantic scene understanding is a fundamental challenge in computer vision. It enables mobile agents to autonomously plan and navigate arbitrary environments. SSC formalizes this challenge as jointly estimating dense geometry and semantic information from sparse observations of a scene. Current methods for SSC are generally trained on 3D ground truth based on aggregated LiDAR scans. This process relies on special sensors and annotation by hand which are costly and do not scale well. To overcome this issue, our work presents the first self-supervised approach to SSC called S4C that does not rely on 3D ground truth data. Our proposed method can reconstruct a scene from a single image and only relies on videos and pseudo segmentation ground truth generated from off-the-shelf image segmentation network during training. Unlike existing methods, which use discrete voxel grids, we represent scenes as implicit semantic fields. This formulation allows querying any point within the camera frustum for occupancy and semantic class. Our architecture is trained through rendering-based self-supervised losses. Nonetheless, our method achieves performance close to fully supervised state-of-the-art methods. Additionally, our method demonstrates strong generalization capabilities and can synthesize accurate segmentation maps for far away viewpoints.
Cousins Of The Vendi Score: A Family Of Similarity-Based Diversity Metrics For Science And Machine Learning
Oct 19, 2023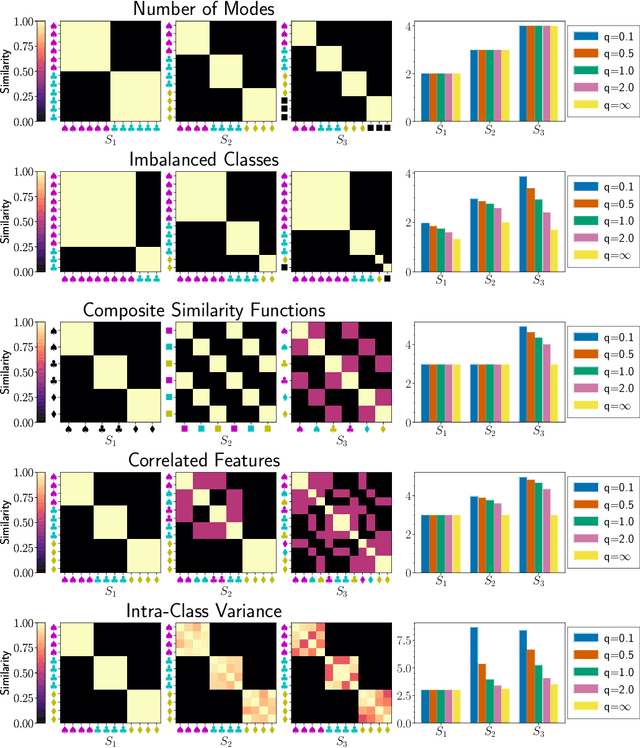
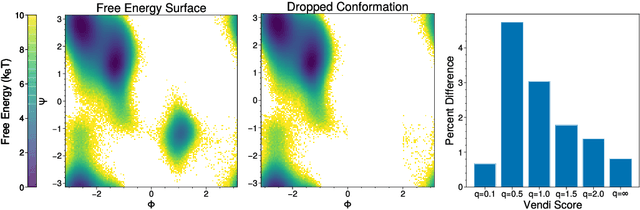
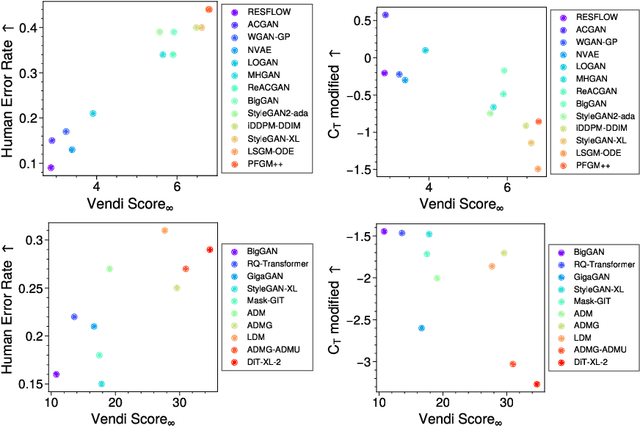
Measuring diversity accurately is important for many scientific fields, including machine learning (ML), ecology, and chemistry. The Vendi Score was introduced as a generic similarity-based diversity metric that extends the Hill number of order q=1 by leveraging ideas from quantum statistical mechanics. Contrary to many diversity metrics in ecology, the Vendi Score accounts for similarity and does not require knowledge of the prevalence of the categories in the collection to be evaluated for diversity. However, the Vendi Score treats each item in a given collection with a level of sensitivity proportional to the item's prevalence. This is undesirable in settings where there is a significant imbalance in item prevalence. In this paper, we extend the other Hill numbers using similarity to provide flexibility in allocating sensitivity to rare or common items. This leads to a family of diversity metrics -- Vendi scores with different levels of sensitivity -- that can be used in a variety of applications. We study the properties of the scores in a synthetic controlled setting where the ground truth diversity is known. We then test their utility in improving molecular simulations via Vendi Sampling. Finally, we use the Vendi scores to better understand the behavior of image generative models in terms of memorization, duplication, diversity, and sample quality.
Diffusion Models for Image Restoration and Enhancement -- A Comprehensive Survey
Aug 18, 2023
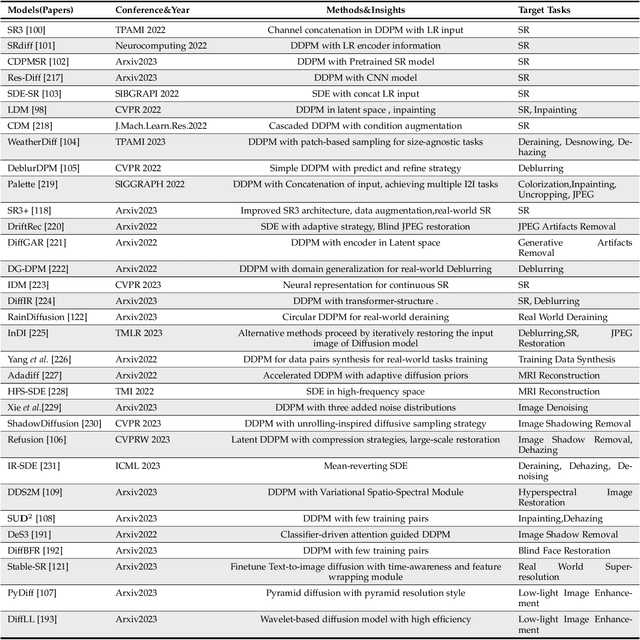
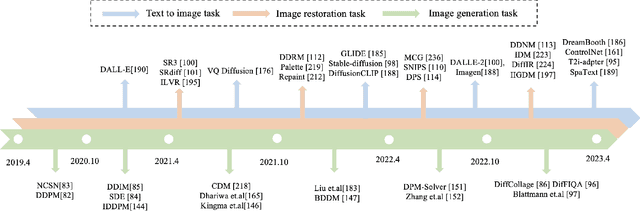
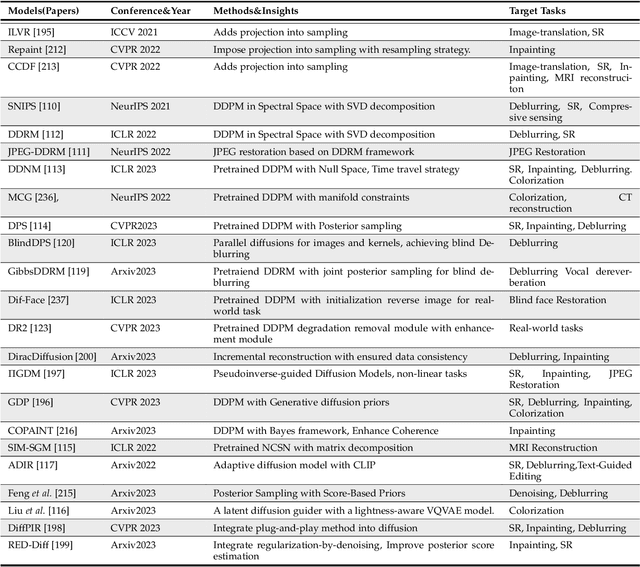
Image restoration (IR) has been an indispensable and challenging task in the low-level vision field, which strives to improve the subjective quality of images distorted by various forms of degradation. Recently, the diffusion model has achieved significant advancements in the visual generation of AIGC, thereby raising an intuitive question, "whether diffusion model can boost image restoration". To answer this, some pioneering studies attempt to integrate diffusion models into the image restoration task, resulting in superior performances than previous GAN-based methods. Despite that, a comprehensive and enlightening survey on diffusion model-based image restoration remains scarce. In this paper, we are the first to present a comprehensive review of recent diffusion model-based methods on image restoration, encompassing the learning paradigm, conditional strategy, framework design, modeling strategy, and evaluation. Concretely, we first introduce the background of the diffusion model briefly and then present two prevalent workflows that exploit diffusion models in image restoration. Subsequently, we classify and emphasize the innovative designs using diffusion models for both IR and blind/real-world IR, intending to inspire future development. To evaluate existing methods thoroughly, we summarize the commonly-used dataset, implementation details, and evaluation metrics. Additionally, we present the objective comparison for open-sourced methods across three tasks, including image super-resolution, deblurring, and inpainting. Ultimately, informed by the limitations in existing works, we propose five potential and challenging directions for the future research of diffusion model-based IR, including sampling efficiency, model compression, distortion simulation and estimation, distortion invariant learning, and framework design.
Simulating room transfer functions between transducers mounted on audio devices using a modified image source method
Sep 07, 2023The image source method (ISM) is often used to simulate room acoustics due to its ease of use and computational efficiency. The standard ISM is limited to simulations of room impulse responses between point sources and omnidirectional receivers. In this work, the ISM is extended using spherical harmonic directivity coefficients to include acoustic diffraction effects due to source and receiver transducers mounted on physical devices, which are typically encountered in practical situations. The proposed method is verified using finite element simulations of various loudspeaker and microphone configurations in a rectangular room. It is shown that the accuracy of the proposed method is related to the sizes, shapes, number, and positions of the devices inside a room. A simplified version of the proposed method, which can significantly reduce computational effort, is also presented. The proposed method and its simplified version can simulate room transfer functions more accurately than currently available image source methods and can aid the development and evaluation of speech and acoustic signal processing algorithms, including speech enhancement, acoustic scene analysis, and acoustic parameter estimation.