 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Emergent Communication in Interactive Sketch Question Answering
Oct 24, 2023
Vision-based emergent communication (EC) aims to learn to communicate through sketches and demystify the evolution of human communication. Ironically, previous works neglect multi-round interaction, which is indispensable in human communication. To fill this gap, we first introduce a novel Interactive Sketch Question Answering (ISQA) task, where two collaborative players are interacting through sketches to answer a question about an image in a multi-round manner. To accomplish this task, we design a new and efficient interactive EC system, which can achieve an effective balance among three evaluation factors, including the question answering accuracy, drawing complexity and human interpretability. Our experimental results including human evaluation demonstrate that multi-round interactive mechanism facilitates targeted and efficient communication between intelligent agents with decent human interpretability.
Histopathological Image Classification and Vulnerability Analysis using Federated Learning
Oct 11, 2023Healthcare is one of the foremost applications of machine learning (ML). Traditionally, ML models are trained by central servers, which aggregate data from various distributed devices to forecast the results for newly generated data. This is a major concern as models can access sensitive user information, which raises privacy concerns. A federated learning (FL) approach can help address this issue: A global model sends its copy to all clients who train these copies, and the clients send the updates (weights) back to it. Over time, the global model improves and becomes more accurate. Data privacy is protected during training, as it is conducted locally on the clients' devices. However, the global model is susceptible to data poisoning. We develop a privacy-preserving FL technique for a skin cancer dataset and show that the model is prone to data poisoning attacks. Ten clients train the model, but one of them intentionally introduces flipped labels as an attack. This reduces the accuracy of the global model. As the percentage of label flipping increases, there is a noticeable decrease in accuracy. We use a stochastic gradient descent optimization algorithm to find the most optimal accuracy for the model. Although FL can protect user privacy for healthcare diagnostics, it is also vulnerable to data poisoning, which must be addressed.
SAM-OCTA: Prompting Segment-Anything for OCTA Image Segmentation
Oct 11, 2023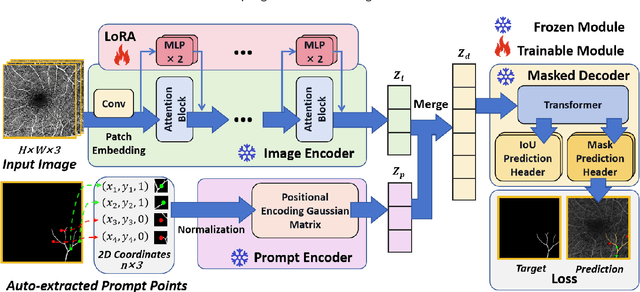
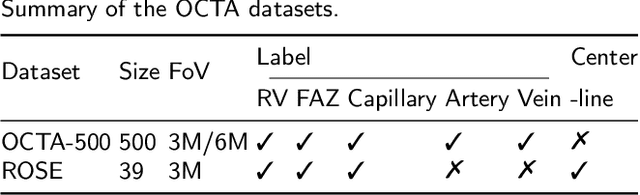
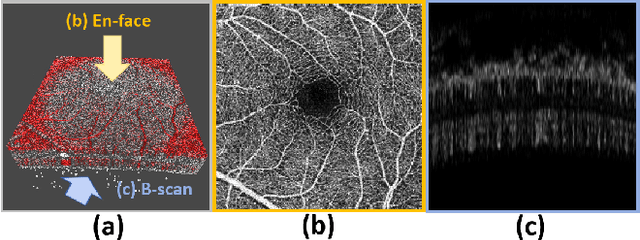
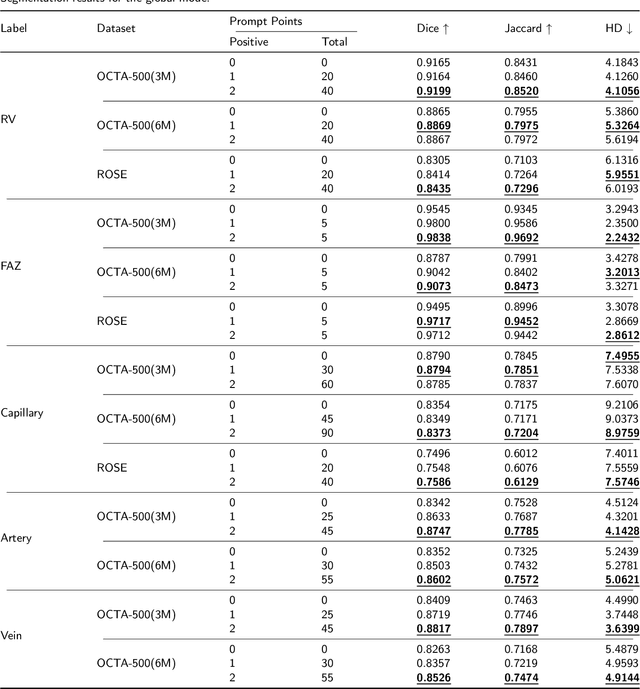
In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 and ROSE datasets. This method achieves or approaches state-of-the-art segmentation performance metrics. The effect and applicability of prompt points are discussed in detail for the retinal vessel, foveal avascular zone, capillary, artery, and vein segmentation tasks. Furthermore, SAM-OCTA accomplishes local vessel segmentation and effective artery-vein segmentation, which was not well-solved in previous works. The code is available at https://github.com/ShellRedia/SAM-OCTA.
Convolution and Attention Mixer for Synthetic Aperture Radar Image Change Detection
Sep 21, 2023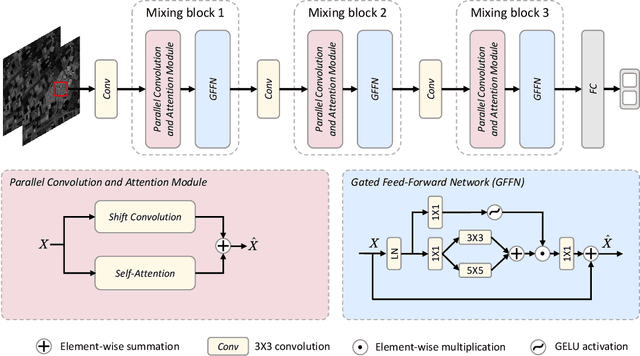
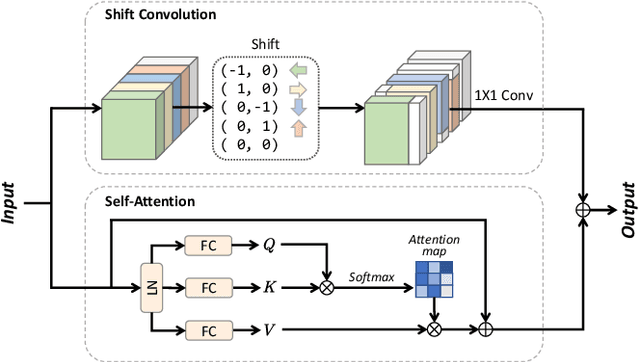
Synthetic aperture radar (SAR) image change detection is a critical task and has received increasing attentions in the remote sensing community. However, existing SAR change detection methods are mainly based on convolutional neural networks (CNNs), with limited consideration of global attention mechanism. In this letter, we explore Transformer-like architecture for SAR change detection to incorporate global attention. To this end, we propose a convolution and attention mixer (CAMixer). First, to compensate the inductive bias for Transformer, we combine self-attention with shift convolution in a parallel way. The parallel design effectively captures the global semantic information via the self-attention and performs local feature extraction through shift convolution simultaneously. Second, we adopt a gating mechanism in the feed-forward network to enhance the non-linear feature transformation. The gating mechanism is formulated as the element-wise multiplication of two parallel linear layers. Important features can be highlighted, leading to high-quality representations against speckle noise. Extensive experiments conducted on three SAR datasets verify the superior performance of the proposed CAMixer. The source codes will be publicly available at https://github.com/summitgao/CAMixer .
Autoregressive Omni-Aware Outpainting for Open-Vocabulary 360-Degree Image Generation
Sep 07, 2023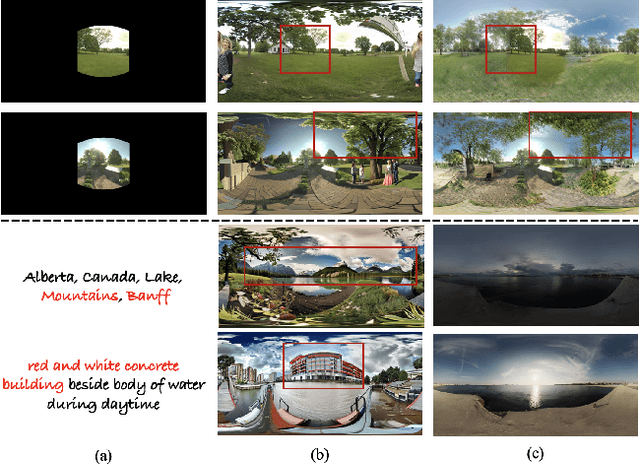
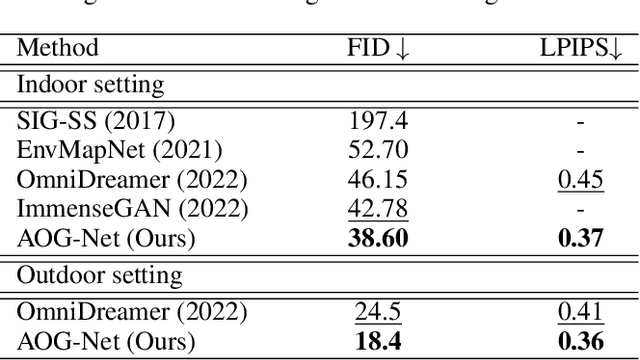
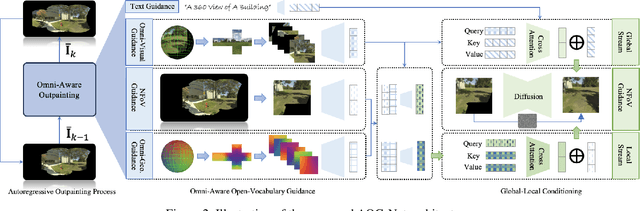
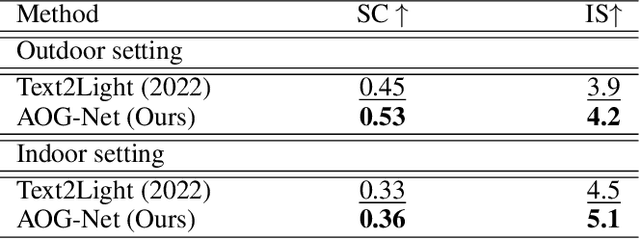
A 360-degree (omni-directional) image provides an all-encompassing spherical view of a scene. Recently, there has been an increasing interest in synthesising 360-degree images from conventional narrow field of view (NFoV) images captured by digital cameras and smartphones, for providing immersive experiences in various scenarios such as virtual reality. Yet, existing methods typically fall short in synthesizing intricate visual details or ensure the generated images align consistently with user-provided prompts. In this study, autoregressive omni-aware generative network (AOG-Net) is proposed for 360-degree image generation by out-painting an incomplete 360-degree image progressively with NFoV and text guidances joinly or individually. This autoregressive scheme not only allows for deriving finer-grained and text-consistent patterns by dynamically generating and adjusting the process but also offers users greater flexibility to edit their conditions throughout the generation process. A global-local conditioning mechanism is devised to comprehensively formulate the outpainting guidance in each autoregressive step. Text guidances, omni-visual cues, NFoV inputs and omni-geometry are encoded and further formulated with cross-attention based transformers into a global stream and a local stream into a conditioned generative backbone model. As AOG-Net is compatible to leverage large-scale models for the conditional encoder and the generative prior, it enables the generation to use extensive open-vocabulary text guidances. Comprehensive experiments on two commonly used 360-degree image datasets for both indoor and outdoor settings demonstrate the state-of-the-art performance of our proposed method. Our code will be made publicly available.
Is Deep Learning Network Necessary for Image Generation?
Aug 25, 2023
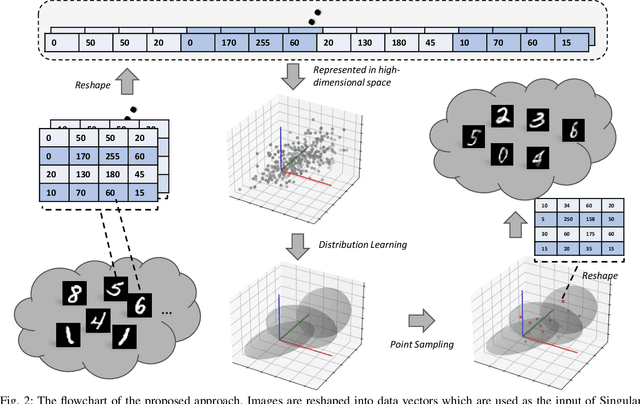


Recently, images are considered samples from a high-dimensional distribution, and deep learning has become almost synonymous with image generation. However, is a deep learning network truly necessary for image generation? In this paper, we investigate the possibility of image generation without using a deep learning network, motivated by validating the assumption that images follow a high-dimensional distribution. Since images are assumed to be samples from such a distribution, we utilize the Gaussian Mixture Model (GMM) to describe it. In particular, we employ a recent distribution learning technique named as Monte-Carlo Marginalization to capture the parameters of the GMM based on image samples. Moreover, we also use the Singular Value Decomposition (SVD) for dimensionality reduction to decrease computational complexity. During our evaluation experiment, we first attempt to model the distribution of image samples directly to verify the assumption that images truly follow a distribution. We then use the SVD for dimensionality reduction. The principal components, rather than raw image data, are used for distribution learning. Compared to methods relying on deep learning networks, our approach is more explainable, and its performance is promising. Experiments show that our images have a lower FID value compared to those generated by variational auto-encoders, demonstrating the feasibility of image generation without deep learning networks.
Efficient Annotation for Medical Image Analysis: A One-Pass Selective Annotation Approach
Sep 15, 2023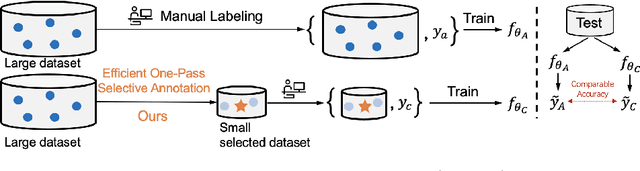
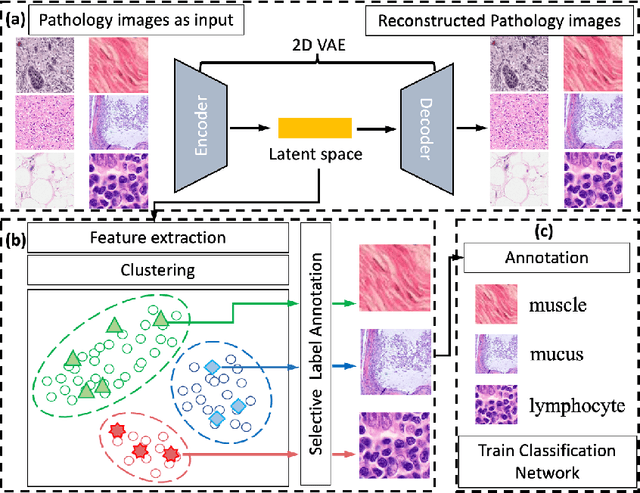
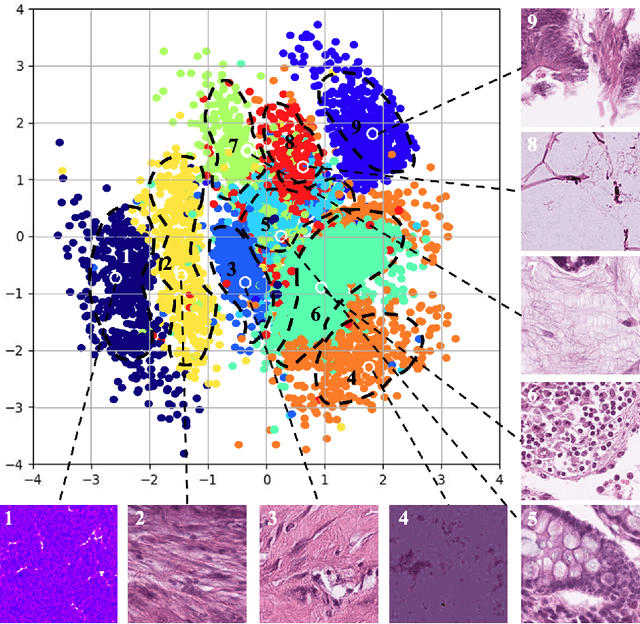
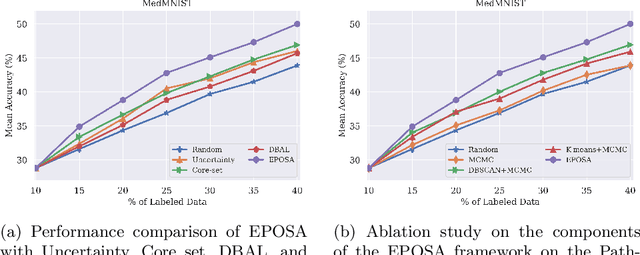
Annotating biomedical images for supervised learning is a complex and labor-intensive task due to data diversity and its intricate nature. In this paper, we propose an innovative method, the efficient one-pass selective annotation (EPOSA), that significantly reduces the annotation burden while maintaining robust model performance. Our approach employs a variational autoencoder (VAE) to extract salient features from unannotated images, which are subsequently clustered using the DBSCAN algorithm. This process groups similar images together, forming distinct clusters. We then use a two-stage sample selection algorithm, called representative selection (RepSel), to form a selected dataset. The first stage is a Markov Chain Monte Carlo (MCMC) sampling technique to select representative samples from each cluster for annotations. This selection process is the second stage, which is guided by the principle of maximizing intra-cluster mutual information and minimizing inter-cluster mutual information. This ensures a diverse set of features for model training and minimizes outlier inclusion. The selected samples are used to train a VGG-16 network for image classification. Experimental results on the Med-MNIST dataset demonstrate that our proposed EPOSA outperforms random selection and other state-of-the-art methods under the same annotation budget, presenting a promising direction for efficient and effective annotation in medical image analysis.
Exploring Semantic Consistency in Unpaired Image Translation to Generate Data for Surgical Applications
Sep 06, 2023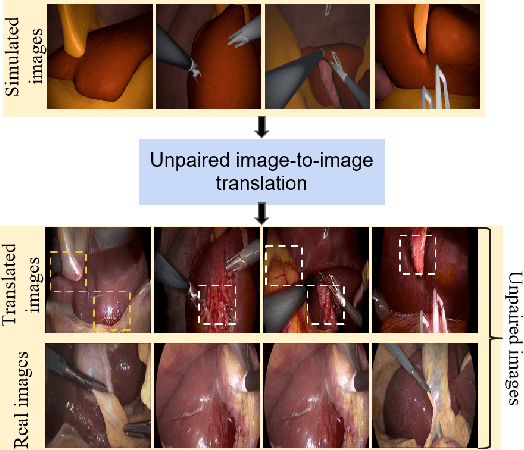
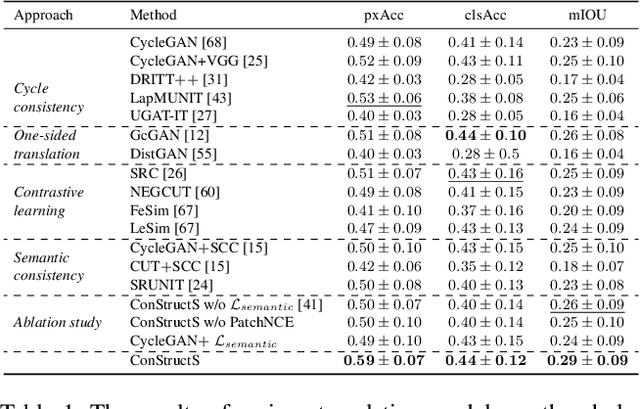
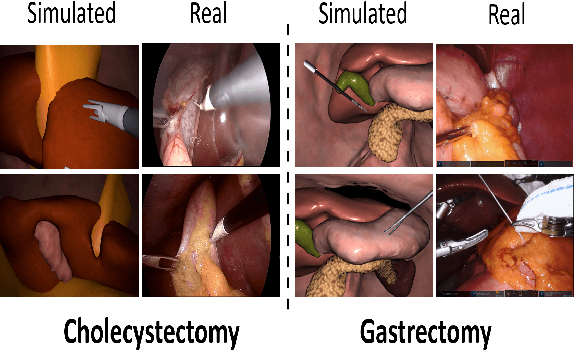
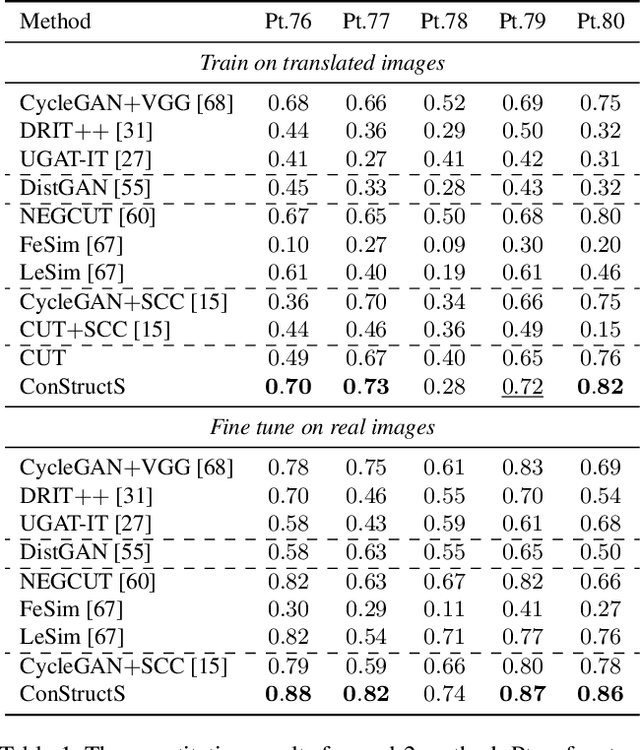
In surgical computer vision applications, obtaining labeled training data is challenging due to data-privacy concerns and the need for expert annotation. Unpaired image-to-image translation techniques have been explored to automatically generate large annotated datasets by translating synthetic images to the realistic domain. However, preserving the structure and semantic consistency between the input and translated images presents significant challenges, mainly when there is a distributional mismatch in the semantic characteristics of the domains. This study empirically investigates unpaired image translation methods for generating suitable data in surgical applications, explicitly focusing on semantic consistency. We extensively evaluate various state-of-the-art image translation models on two challenging surgical datasets and downstream semantic segmentation tasks. We find that a simple combination of structural-similarity loss and contrastive learning yields the most promising results. Quantitatively, we show that the data generated with this approach yields higher semantic consistency and can be used more effectively as training data.
Leveraging Pretrained Image-text Models for Improving Audio-Visual Learning
Sep 08, 2023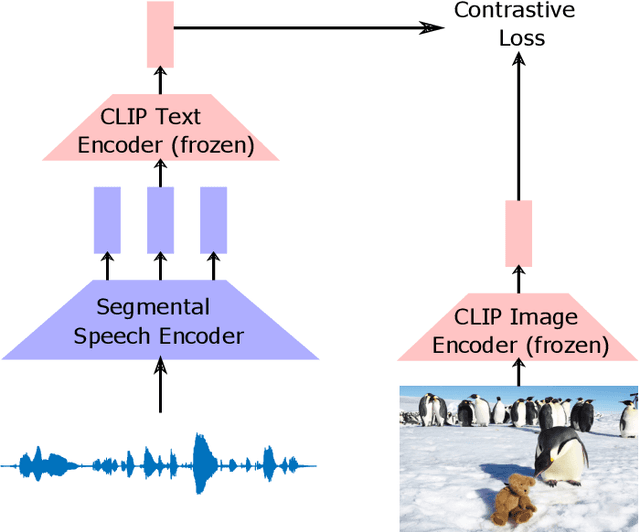
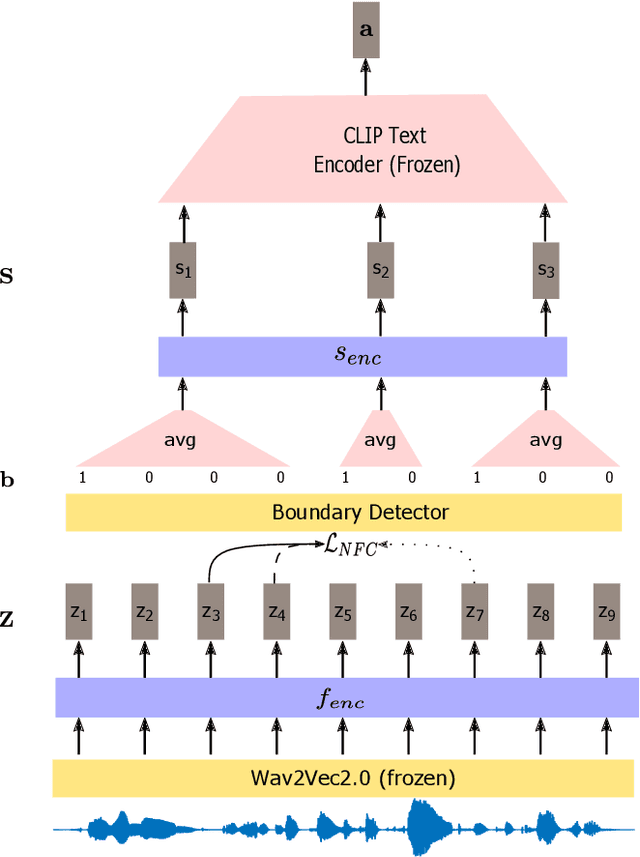
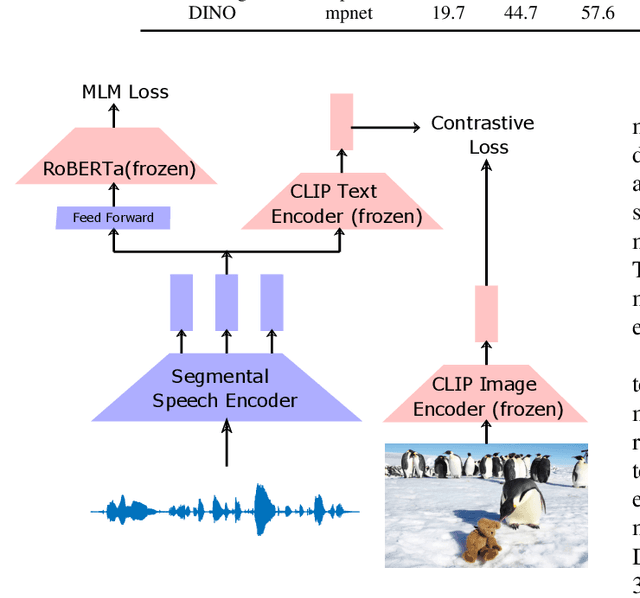
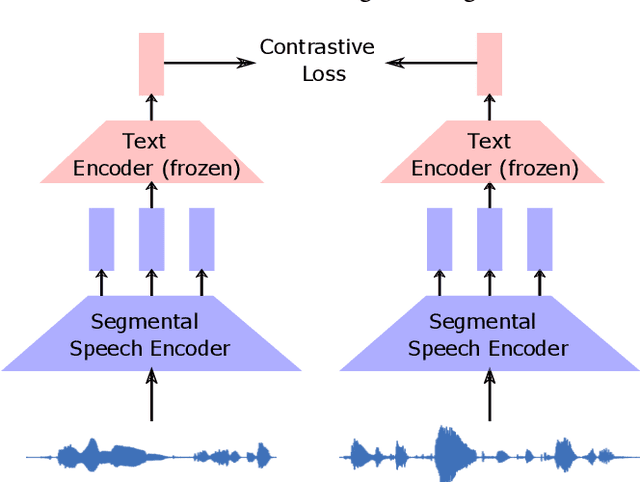
Visually grounded speech systems learn from paired images and their spoken captions. Recently, there have been attempts to utilize the visually grounded models trained from images and their corresponding text captions, such as CLIP, to improve speech-based visually grounded models' performance. However, the majority of these models only utilize the pretrained image encoder. Cascaded SpeechCLIP attempted to generate localized word-level information and utilize both the pretrained image and text encoders. Despite using both, they noticed a substantial drop in retrieval performance. We proposed Segmental SpeechCLIP which used a hierarchical segmental speech encoder to generate sequences of word-like units. We used the pretrained CLIP text encoder on top of these word-like unit representations and showed significant improvements over the cascaded variant of SpeechCLIP. Segmental SpeechCLIP directly learns the word embeddings as input to the CLIP text encoder bypassing the vocabulary embeddings. Here, we explore mapping audio to CLIP vocabulary embeddings via regularization and quantization. As our objective is to distill semantic information into the speech encoders, we explore the usage of large unimodal pretrained language models as the text encoders. Our method enables us to bridge image and text encoders e.g. DINO and RoBERTa trained with uni-modal data. Finally, we extend our framework in audio-only settings where only pairs of semantically related audio are available. Experiments show that audio-only systems perform close to the audio-visual system.
CNN Injected Transformer for Image Exposure Correction
Sep 08, 2023

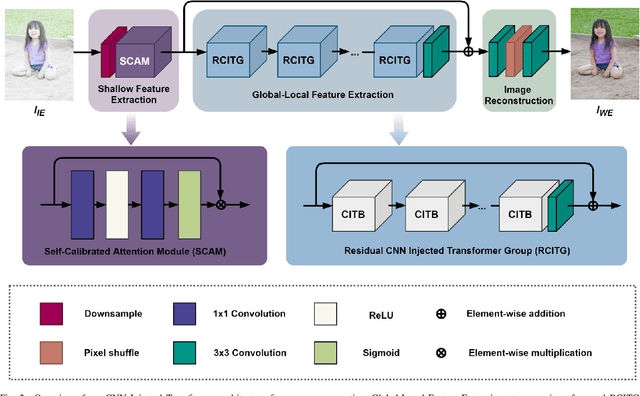
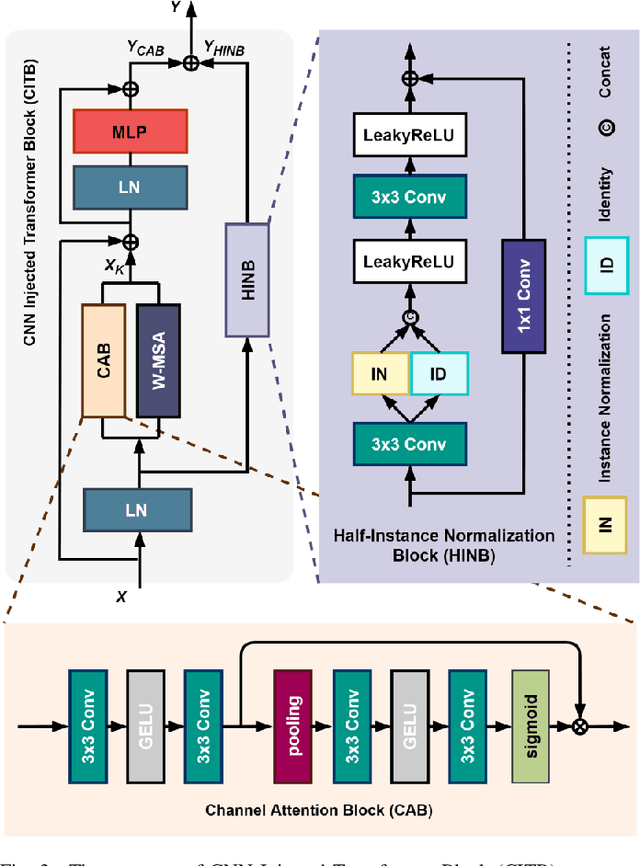
Capturing images with incorrect exposure settings fails to deliver a satisfactory visual experience. Only when the exposure is properly set, can the color and details of the images be appropriately preserved. Previous exposure correction methods based on convolutions often produce exposure deviation in images as a consequence of the restricted receptive field of convolutional kernels. This issue arises because convolutions are not capable of capturing long-range dependencies in images accurately. To overcome this challenge, we can apply the Transformer to address the exposure correction problem, leveraging its capability in modeling long-range dependencies to capture global representation. However, solely relying on the window-based Transformer leads to visually disturbing blocking artifacts due to the application of self-attention in small patches. In this paper, we propose a CNN Injected Transformer (CIT) to harness the individual strengths of CNN and Transformer simultaneously. Specifically, we construct the CIT by utilizing a window-based Transformer to exploit the long-range interactions among different regions in the entire image. Within each CIT block, we incorporate a channel attention block (CAB) and a half-instance normalization block (HINB) to assist the window-based self-attention to acquire the global statistics and refine local features. In addition to the hybrid architecture design for exposure correction, we apply a set of carefully formulated loss functions to improve the spatial coherence and rectify potential color deviations. Extensive experiments demonstrate that our image exposure correction method outperforms state-of-the-art approaches in terms of both quantitative and qualitative metrics.