 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CycleCL: Self-supervised Learning for Periodic Videos
Nov 05, 2023
Analyzing periodic video sequences is a key topic in applications such as automatic production systems, remote sensing, medical applications, or physical training. An example is counting repetitions of a physical exercise. Due to the distinct characteristics of periodic data, self-supervised methods designed for standard image datasets do not capture changes relevant to the progression of the cycle and fail to ignore unrelated noise. They thus do not work well on periodic data. In this paper, we propose CycleCL, a self-supervised learning method specifically designed to work with periodic data. We start from the insight that a good visual representation for periodic data should be sensitive to the phase of a cycle, but be invariant to the exact repetition, i.e. it should generate identical representations for a specific phase throughout all repetitions. We exploit the repetitions in videos to design a novel contrastive learning method based on a triplet loss that optimizes for these desired properties. Our method uses pre-trained features to sample pairs of frames from approximately the same phase and negative pairs of frames from different phases. Then, we iterate between optimizing a feature encoder and resampling triplets, until convergence. By optimizing a model this way, we are able to learn features that have the mentioned desired properties. We evaluate CycleCL on an industrial and multiple human actions datasets, where it significantly outperforms previous video-based self-supervised learning methods on all tasks.
Rotation Invariant Transformer for Recognizing Object in UAVs
Nov 05, 2023Recognizing a target of interest from the UAVs is much more challenging than the existing object re-identification tasks across multiple city cameras. The images taken by the UAVs usually suffer from significant size difference when generating the object bounding boxes and uncertain rotation variations. Existing methods are usually designed for city cameras, incapable of handing the rotation issue in UAV scenarios. A straightforward solution is to perform the image-level rotation augmentation, but it would cause loss of useful information when inputting the powerful vision transformer as patches. This motivates us to simulate the rotation operation at the patch feature level, proposing a novel rotation invariant vision transformer (RotTrans). This strategy builds on high-level features with the help of the specificity of the vision transformer structure, which enhances the robustness against large rotation differences. In addition, we design invariance constraint to establish the relationship between the original feature and the rotated features, achieving stronger rotation invariance. Our proposed transformer tested on the latest UAV datasets greatly outperforms the current state-of-the-arts, which is 5.9\% and 4.8\% higher than the highest mAP and Rank1. Notably, our model also performs competitively for the person re-identification task on traditional city cameras. In particular, our solution wins the first place in the UAV-based person re-recognition track in the Multi-Modal Video Reasoning and Analyzing Competition held in ICCV 2021. Code is available at https://github.com/whucsy/RotTrans.
Sequential Semantic Generative Communication for Progressive Text-to-Image Generation
Sep 08, 2023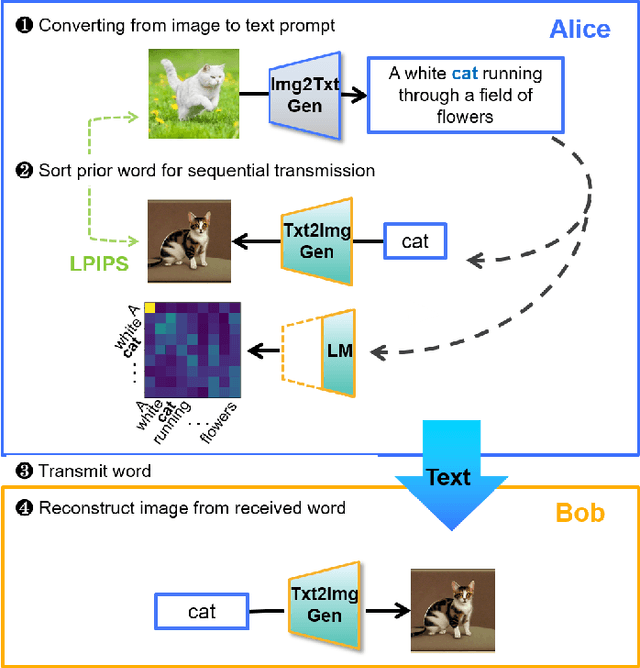
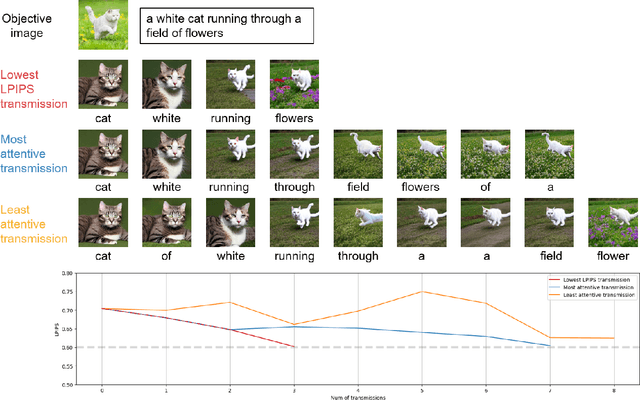
This paper proposes new framework of communication system leveraging promising generation capabilities of multi-modal generative models. Regarding nowadays smart applications, successful communication can be made by conveying the perceptual meaning, which we set as text prompt. Text serves as a suitable semantic representation of image data as it has evolved to instruct an image or generate image through multi-modal techniques, by being interpreted in a manner similar to human cognition. Utilizing text can also reduce the overload compared to transmitting the intact data itself. The transmitter converts objective image to text through multi-model generation process and the receiver reconstructs the image using reverse process. Each word in the text sentence has each syntactic role, responsible for particular piece of information the text contains. For further efficiency in communication load, the transmitter sequentially sends words in priority of carrying the most information until reaches successful communication. Therefore, our primary focus is on the promising design of a communication system based on image-to-text transformation and the proposed schemes for sequentially transmitting word tokens. Our work is expected to pave a new road of utilizing state-of-the-art generative models to real communication systems
Towards Practical and Efficient Image-to-Speech Captioning with Vision-Language Pre-training and Multi-modal Tokens
Sep 15, 2023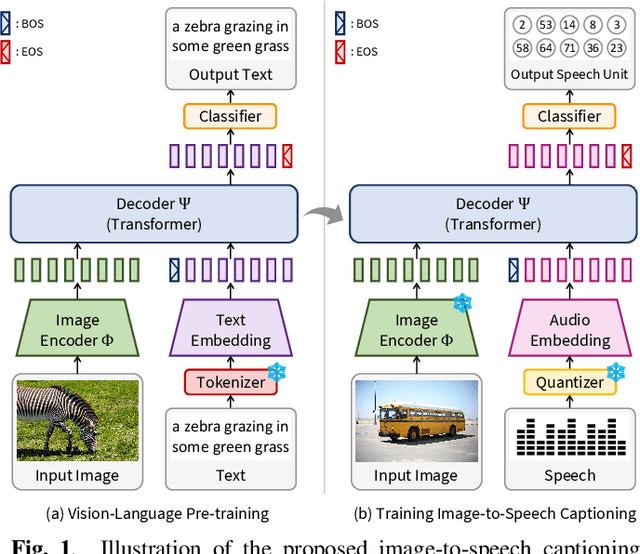

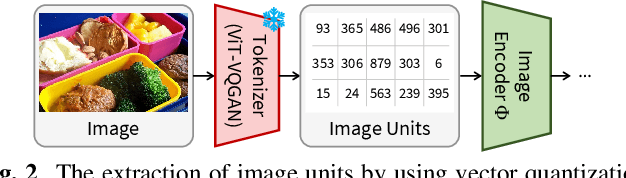

In this paper, we propose methods to build a powerful and efficient Image-to-Speech captioning (Im2Sp) model. To this end, we start with importing the rich knowledge related to image comprehension and language modeling from a large-scale pre-trained vision-language model into Im2Sp. We set the output of the proposed Im2Sp as discretized speech units, i.e., the quantized speech features of a self-supervised speech model. The speech units mainly contain linguistic information while suppressing other characteristics of speech. This allows us to incorporate the language modeling capability of the pre-trained vision-language model into the spoken language modeling of Im2Sp. With the vision-language pre-training strategy, we set new state-of-the-art Im2Sp performances on two widely used benchmark databases, COCO and Flickr8k. Then, we further improve the efficiency of the Im2Sp model. Similar to the speech unit case, we convert the original image into image units, which are derived through vector quantization of the raw image. With these image units, we can drastically reduce the required data storage for saving image data to just 0.8% when compared to the original image data in terms of bits. Demo page: https://ms-dot-k.github.io/Image-to-Speech-Captioning.
CHITNet: A Complementary to Harmonious Information Transfer Network for Infrared and Visible Image Fusion
Sep 26, 2023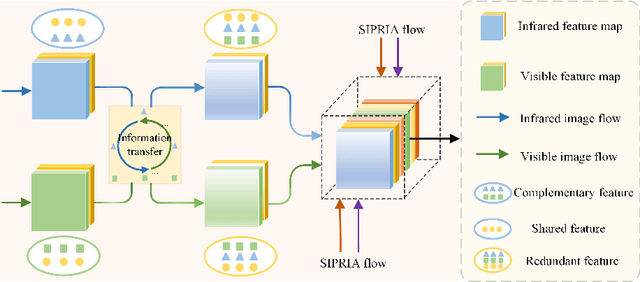

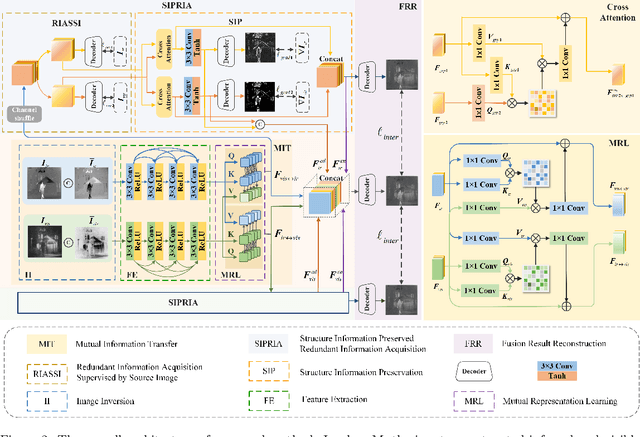
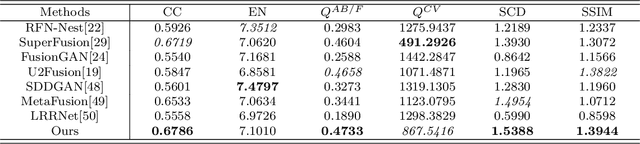
Current infrared and visible image fusion (IVIF) methods go to great lengths to excavate complementary features and design complex fusion strategies, which is extremely challenging. To this end, we rethink the IVIF outside the box, proposing a complementary to harmonious information transfer network (CHITNet). It reasonably transfers complementary information into harmonious one, which integrates both the shared and complementary features from two modalities. Specifically, to skillfully sidestep aggregating complementary information in IVIF, we design a mutual information transfer (MIT) module to mutually represent features from two modalities, roughly transferring complementary information into harmonious one. Then, a harmonious information acquisition supervised by source image (HIASSI) module is devised to further ensure the complementary to harmonious information transfer after MIT. Meanwhile, we also propose a structure information preservation (SIP) module to guarantee that the edge structure information of the source images can be transferred to the fusion results. Moreover, a mutual promotion training paradigm (MPTP) with interaction loss is adopted to facilitate better collaboration among MIT, HIASSI and SIP. In this way, the proposed method is able to generate fused images with higher qualities. Extensive experimental results demonstrate the superiority of our CHITNet over state-of-the-art algorithms in terms of visual quality and quantitative evaluations.
Prototypical Contrastive Learning-based CLIP Fine-tuning for Object Re-identification
Oct 26, 2023This work aims to adapt large-scale pre-trained vision-language models, such as contrastive language-image pretraining (CLIP), to enhance the performance of object reidentification (Re-ID) across various supervision settings. Although prompt learning has enabled a recent work named CLIP-ReID to achieve promising performance, the underlying mechanisms and the necessity of prompt learning remain unclear due to the absence of semantic labels in ReID tasks. In this work, we first analyze the role prompt learning in CLIP-ReID and identify its limitations. Based on our investigations, we propose a simple yet effective approach to adapt CLIP for supervised object Re-ID. Our approach directly fine-tunes the image encoder of CLIP using a prototypical contrastive learning (PCL) loss, eliminating the need for prompt learning. Experimental results on both person and vehicle Re-ID datasets demonstrate the competitiveness of our method compared to CLIP-ReID. Furthermore, we extend our PCL-based CLIP fine-tuning approach to unsupervised scenarios, where we achieve state-of-the art performance.
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
Oct 26, 2023The emergence of Deep Neural Networks (DNNs) has revolutionized various domains, enabling the resolution of complex tasks spanning image recognition, natural language processing, and scientific problem-solving. However, this progress has also exposed a concerning vulnerability: adversarial examples. These crafted inputs, imperceptible to humans, can manipulate machine learning models into making erroneous predictions, raising concerns for safety-critical applications. An intriguing property of this phenomenon is the transferability of adversarial examples, where perturbations crafted for one model can deceive another, often with a different architecture. This intriguing property enables "black-box" attacks, circumventing the need for detailed knowledge of the target model. This survey explores the landscape of the adversarial transferability of adversarial examples. We categorize existing methodologies to enhance adversarial transferability and discuss the fundamental principles guiding each approach. While the predominant body of research primarily concentrates on image classification, we also extend our discussion to encompass other vision tasks and beyond. Challenges and future prospects are discussed, highlighting the importance of fortifying DNNs against adversarial vulnerabilities in an evolving landscape.
Lost Your Style? Navigating with Semantic-Level Approach for Text-to-Outfit Retrieval
Nov 03, 2023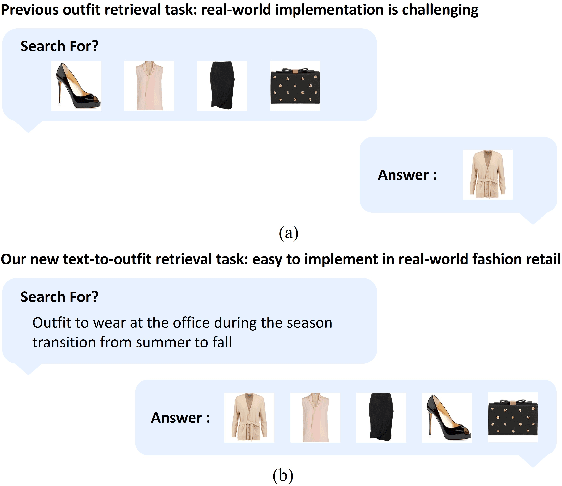
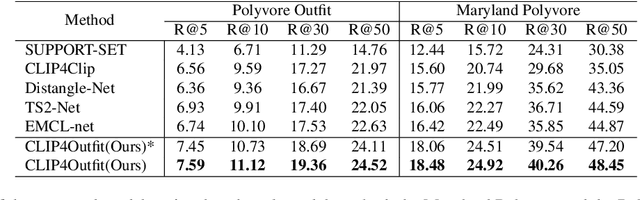


Fashion stylists have historically bridged the gap between consumers' desires and perfect outfits, which involve intricate combinations of colors, patterns, and materials. Although recent advancements in fashion recommendation systems have made strides in outfit compatibility prediction and complementary item retrieval, these systems rely heavily on pre-selected customer choices. Therefore, we introduce a groundbreaking approach to fashion recommendations: text-to-outfit retrieval task that generates a complete outfit set based solely on textual descriptions given by users. Our model is devised at three semantic levels-item, style, and outfit-where each level progressively aggregates data to form a coherent outfit recommendation based on textual input. Here, we leverage strategies similar to those in the contrastive language-image pretraining model to address the intricate-style matrix within the outfit sets. Using the Maryland Polyvore and Polyvore Outfit datasets, our approach significantly outperformed state-of-the-art models in text-video retrieval tasks, solidifying its effectiveness in the fashion recommendation domain. This research not only pioneers a new facet of fashion recommendation systems, but also introduces a method that captures the essence of individual style preferences through textual descriptions.
Batch-less stochastic gradient descent for compressive learning of deep regularization for image denoising
Oct 02, 2023We consider the problem of denoising with the help of prior information taken from a database of clean signals or images. Denoising with variational methods is very efficient if a regularizer well adapted to the nature of the data is available. Thanks to the maximum a posteriori Bayesian framework, such regularizer can be systematically linked with the distribution of the data. With deep neural networks (DNN), complex distributions can be recovered from a large training database.To reduce the computational burden of this task, we adapt the compressive learning framework to the learning of regularizers parametrized by DNN. We propose two variants of stochastic gradient descent (SGD) for the recovery of deep regularization parameters from a heavily compressed database. These algorithms outperform the initially proposed method that was limited to low-dimensional signals, each iteration using information from the whole database. They also benefit from classical SGD convergence guarantees. Thanks to these improvements we show that this method can be applied for patch based image denoising.}
COMPASS: High-Efficiency Deep Image Compression with Arbitrary-scale Spatial Scalability
Sep 11, 2023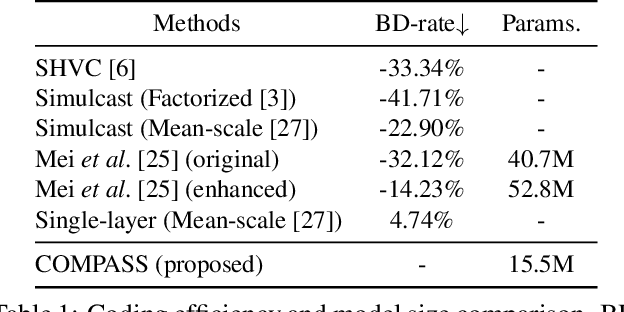
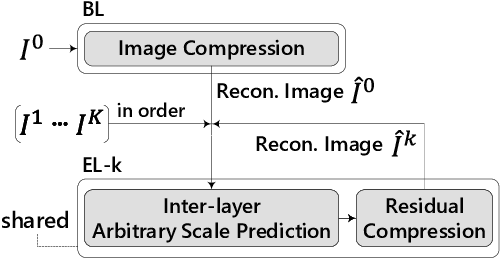
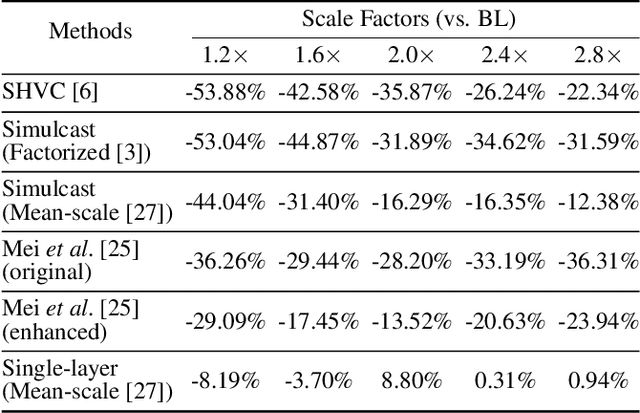
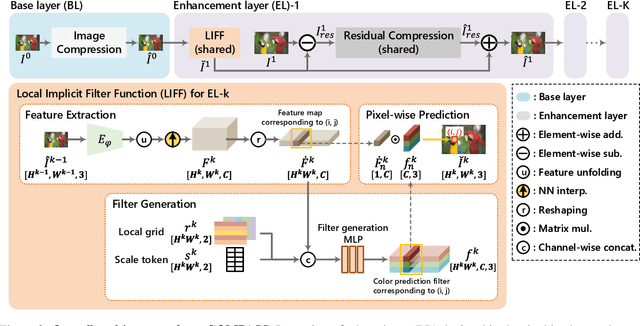
Recently, neural network (NN)-based image compression studies have actively been made and has shown impressive performance in comparison to traditional methods. However, most of the works have focused on non-scalable image compression (single-layer coding) while spatially scalable image compression has drawn less attention although it has many applications. In this paper, we propose a novel NN-based spatially scalable image compression method, called COMPASS, which supports arbitrary-scale spatial scalability. Our proposed COMPASS has a very flexible structure where the number of layers and their respective scale factors can be arbitrarily determined during inference. To reduce the spatial redundancy between adjacent layers for arbitrary scale factors, our COMPASS adopts an inter-layer arbitrary scale prediction method, called LIFF, based on implicit neural representation. We propose a combined RD loss function to effectively train multiple layers. Experimental results show that our COMPASS achieves BD-rate gain of -58.33% and -47.17% at maximum compared to SHVC and the state-of-the-art NN-based spatially scalable image compression method, respectively, for various combinations of scale factors. Our COMPASS also shows comparable or even better coding efficiency than the single-layer coding for various scale factors.