 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost Your Style? Navigating with Semantic-Level Approach for Text-to-Outfit Retrieval
Nov 03, 2023



Fashion stylists have historically bridged the gap between consumers' desires and perfect outfits, which involve intricate combinations of colors, patterns, and materials. Although recent advancements in fashion recommendation systems have made strides in outfit compatibility prediction and complementary item retrieval, these systems rely heavily on pre-selected customer choices. Therefore, we introduce a groundbreaking approach to fashion recommendations: text-to-outfit retrieval task that generates a complete outfit set based solely on textual descriptions given by users. Our model is devised at three semantic levels-item, style, and outfit-where each level progressively aggregates data to form a coherent outfit recommendation based on textual input. Here, we leverage strategies similar to those in the contrastive language-image pretraining model to address the intricate-style matrix within the outfit sets. Using the Maryland Polyvore and Polyvore Outfit datasets, our approach significantly outperformed state-of-the-art models in text-video retrieval tasks, solidifying its effectiveness in the fashion recommendation domain. This research not only pioneers a new facet of fashion recommendation systems, but also introduces a method that captures the essence of individual style preferences through textual descriptions.
N-pad : Neighboring Pixel-based Industrial Anomaly Detection
Oct 17, 2022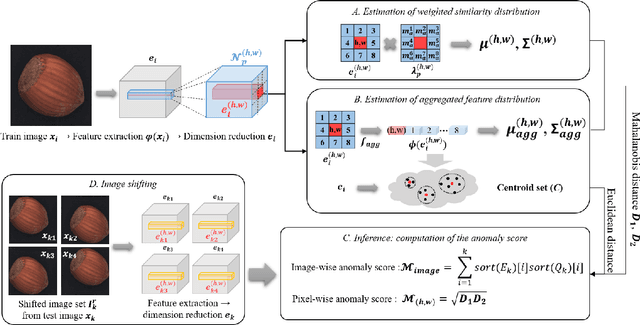
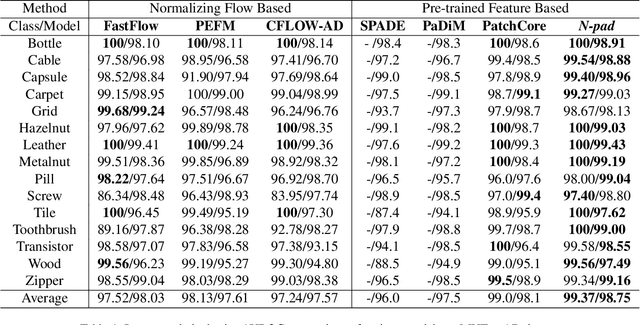

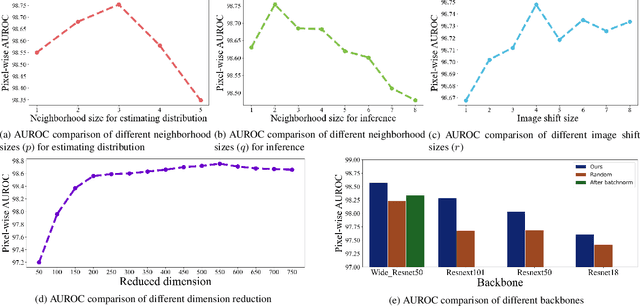
Identifying defects in the images of industrial products has been an important task to enhance quality control and reduce maintenance costs. In recent studies, industrial anomaly detection models were developed using pre-trained networks to learn nominal representations. To employ the relative positional information of each pixel, we present \textit{\textbf{N-pad}}, a novel method for anomaly detection and segmentation in a one-class learning setting that includes the neighborhood of the target pixel for model training and evaluation. Within the model architecture, pixel-wise nominal distributions are estimated by using the features of neighboring pixels with the target pixel to allow possible marginal misalignment. Moreover, the centroids from clusters of nominal features are identified as a representative nominal set. Accordingly, anomaly scores are inferred based on the Mahalanobis distances and Euclidean distances between the target pixel and the estimated distributions or the centroid set, respectively. Thus, we have achieved state-of-the-art performance in MVTec-AD with AUROC of 99.37 for anomaly detection and 98.75 for anomaly segmentation, reducing the error by 34\% compared to the next best performing model. Experiments in various settings further validate our model.
HAGCN : Network Decentralization Attention Based Heterogeneity-Aware Spatiotemporal Graph Convolution Network for Traffic Signal Forecasting
Sep 05, 2022The construction of spatiotemporal networks using graph convolution networks (GCNs) has become one of the most popular methods for predicting traffic signals. However, when using a GCN for traffic speed prediction, the conventional approach generally assumes the relationship between the sensors as a homogeneous graph and learns an adjacency matrix using the data accumulated by the sensors. However, the spatial correlation between sensors is not specified as one but defined differently from various viewpoints. To this end, we aim to study the heterogeneous characteristics inherent in traffic signal data to learn the hidden relationships between sensors in various ways. Specifically, we designed a method to construct a heterogeneous graph for each module by dividing the spatial relationship between sensors into static and dynamic modules. We propose a network decentralization attention based heterogeneity-aware graph convolution network (HAGCN) method that aggregates the hidden states of adjacent nodes by considering the importance of each channel in a heterogeneous graph. Experimental results on real traffic datasets verified the effectiveness of the proposed method, achieving a 6.35% improvement over the existing model and realizing state-of-the-art prediction performance.
A Multi-View Learning Approach to Enhance Automatic 12-Lead ECG Diagnosis Performance
Jul 30, 2022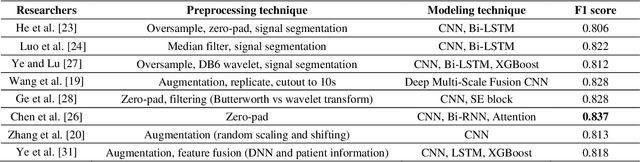
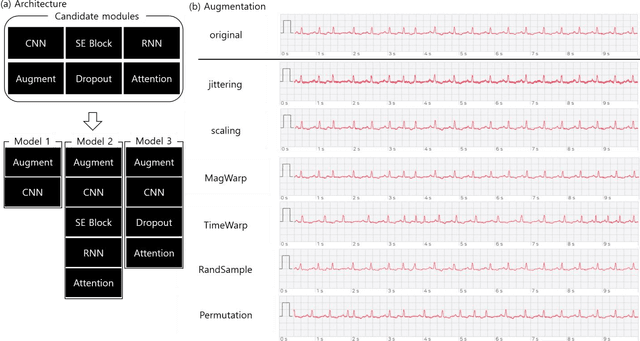
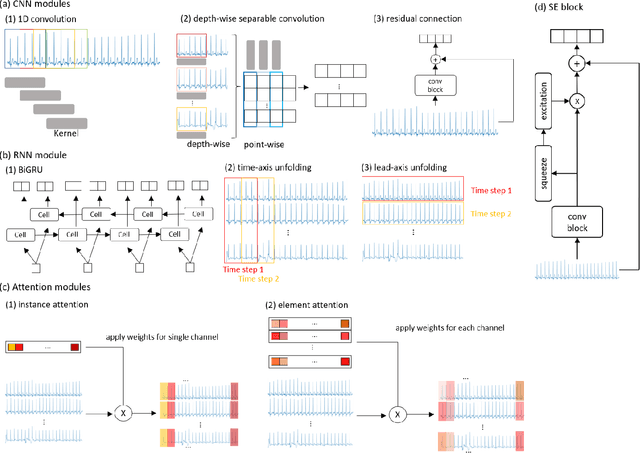

The performances of commonly used electrocardiogram (ECG) diagnosis models have recently improved with the introduction of deep learning (DL). However, the impact of various combinations of multiple DL components and/or the role of data augmentation techniques on the diagnosis have not been sufficiently investigated. This study proposes an ensemble-based multi-view learning approach with an ECG augmentation technique to achieve a higher performance than traditional automatic 12-lead ECG diagnosis methods. The data analysis results show that the proposed model reports an F1 score of 0.840, which outperforms existing state-ofthe-art methods in the literature.