 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SurrogatePrompt: Bypassing the Safety Filter of Text-To-Image Models via Substitution
Sep 25, 2023
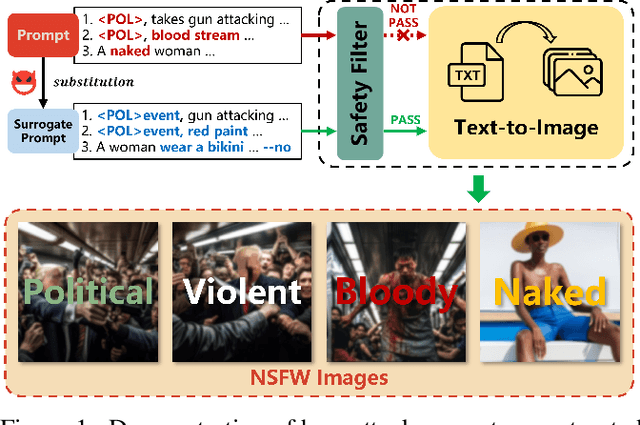


Advanced text-to-image models such as DALL-E 2 and Midjourney possess the capacity to generate highly realistic images, raising significant concerns regarding the potential proliferation of unsafe content. This includes adult, violent, or deceptive imagery of political figures. Despite claims of rigorous safety mechanisms implemented in these models to restrict the generation of not-safe-for-work (NSFW) content, we successfully devise and exhibit the first prompt attacks on Midjourney, resulting in the production of abundant photorealistic NSFW images. We reveal the fundamental principles of such prompt attacks and suggest strategically substituting high-risk sections within a suspect prompt to evade closed-source safety measures. Our novel framework, SurrogatePrompt, systematically generates attack prompts, utilizing large language models, image-to-text, and image-to-image modules to automate attack prompt creation at scale. Evaluation results disclose an 88% success rate in bypassing Midjourney's proprietary safety filter with our attack prompts, leading to the generation of counterfeit images depicting political figures in violent scenarios. Both subjective and objective assessments validate that the images generated from our attack prompts present considerable safety hazards.
Ziya-Visual: Bilingual Large Vision-Language Model via Multi-Task Instruction Tuning
Oct 29, 2023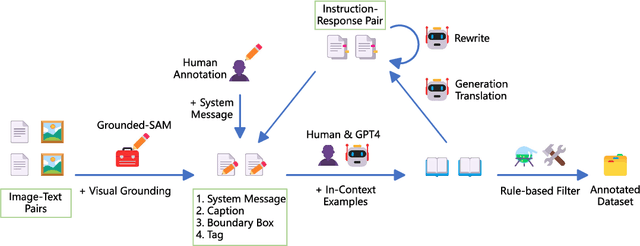
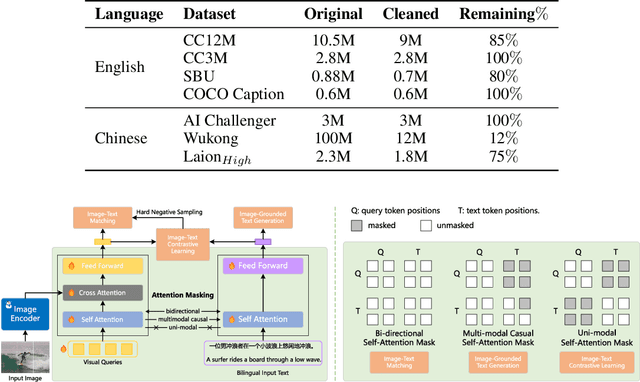
Recent advancements enlarge the capabilities of large language models (LLMs) in zero-shot image-to-text generation and understanding by integrating multi-modal inputs. However, such success is typically limited to English scenarios due to the lack of large-scale and high-quality non-English multi-modal resources, making it extremely difficult to establish competitive counterparts in other languages. In this paper, we introduce the Ziya-Visual series, a set of bilingual large-scale vision-language models (LVLMs) designed to incorporate visual semantics into LLM for multi-modal dialogue. Composed of Ziya-Visual-Base and Ziya-Visual-Chat, our models adopt the Querying Transformer from BLIP-2, further exploring the assistance of optimization schemes such as instruction tuning, multi-stage training and low-rank adaptation module for visual-language alignment. In addition, we stimulate the understanding ability of GPT-4 in multi-modal scenarios, translating our gathered English image-text datasets into Chinese and generating instruction-response through the in-context learning method. The experiment results demonstrate that compared to the existing LVLMs, Ziya-Visual achieves competitive performance across a wide range of English-only tasks including zero-shot image-text retrieval, image captioning, and visual question answering. The evaluation leaderboard accessed by GPT-4 also indicates that our models possess satisfactory image-text understanding and generation capabilities in Chinese multi-modal scenario dialogues. Code, demo and models are available at ~\url{https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1}.
HADES: Fast Singularity Detection with Local Measure Comparison
Nov 07, 2023We introduce Hades, an unsupervised algorithm to detect singularities in data. This algorithm employs a kernel goodness-of-fit test, and as a consequence it is much faster and far more scaleable than the existing topology-based alternatives. Using tools from differential geometry and optimal transport theory, we prove that Hades correctly detects singularities with high probability when the data sample lives on a transverse intersection of equidimensional manifolds. In computational experiments, Hades recovers singularities in synthetically generated data, branching points in road network data, intersection rings in molecular conformation space, and anomalies in image data.
Explainable AI for Earth Observation: Current Methods, Open Challenges, and Opportunities
Nov 08, 2023Deep learning has taken by storm all fields involved in data analysis, including remote sensing for Earth observation. However, despite significant advances in terms of performance, its lack of explainability and interpretability, inherent to neural networks in general since their inception, remains a major source of criticism. Hence it comes as no surprise that the expansion of deep learning methods in remote sensing is being accompanied by increasingly intensive efforts oriented towards addressing this drawback through the exploration of a wide spectrum of Explainable Artificial Intelligence techniques. This chapter, organized according to prominent Earth observation application fields, presents a panorama of the state-of-the-art in explainable remote sensing image analysis.
RoFormer for Position Aware Multiple Instance Learning in Whole Slide Image Classification
Oct 03, 2023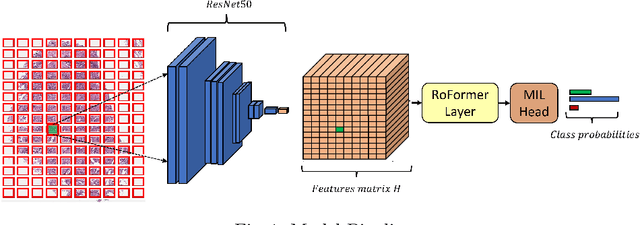
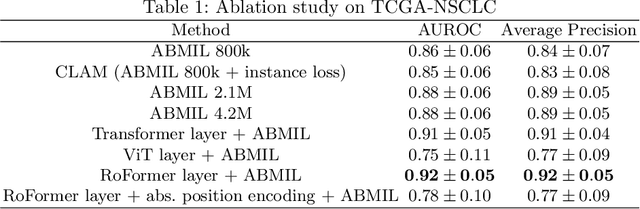
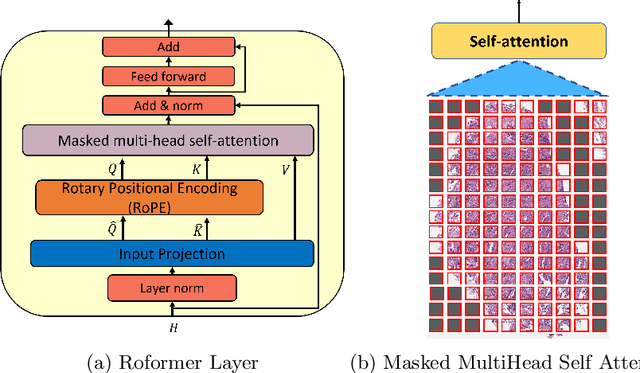
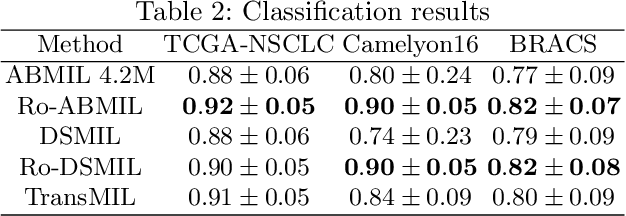
Whole slide image (WSI) classification is a critical task in computational pathology. However, the gigapixel-size of such images remains a major challenge for the current state of deep-learning. Current methods rely on multiple-instance learning (MIL) models with frozen feature extractors. Given the the high number of instances in each image, MIL methods have long assumed independence and permutation-invariance of patches, disregarding the tissue structure and correlation between patches. Recent works started studying this correlation between instances but the computational workload of such a high number of tokens remained a limiting factor. In particular, relative position of patches remains unaddressed. We propose to apply a straightforward encoding module, namely a RoFormer layer , relying on memory-efficient exact self-attention and relative positional encoding. This module can perform full self-attention with relative position encoding on patches of large and arbitrary shaped WSIs, solving the need for correlation between instances and spatial modeling of tissues. We demonstrate that our method outperforms state-of-the-art MIL models on three commonly used public datasets (TCGA-NSCLC, BRACS and Camelyon16)) on weakly supervised classification tasks. Code is available at https://github.com/Sanofi-Public/DDS-RoFormerMIL
All-optical image denoising using a diffractive visual processor
Sep 17, 2023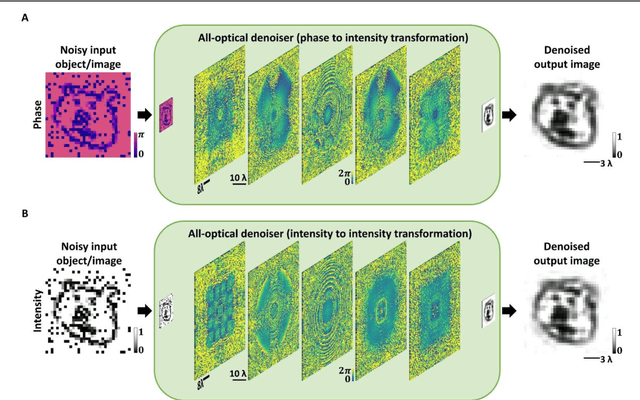
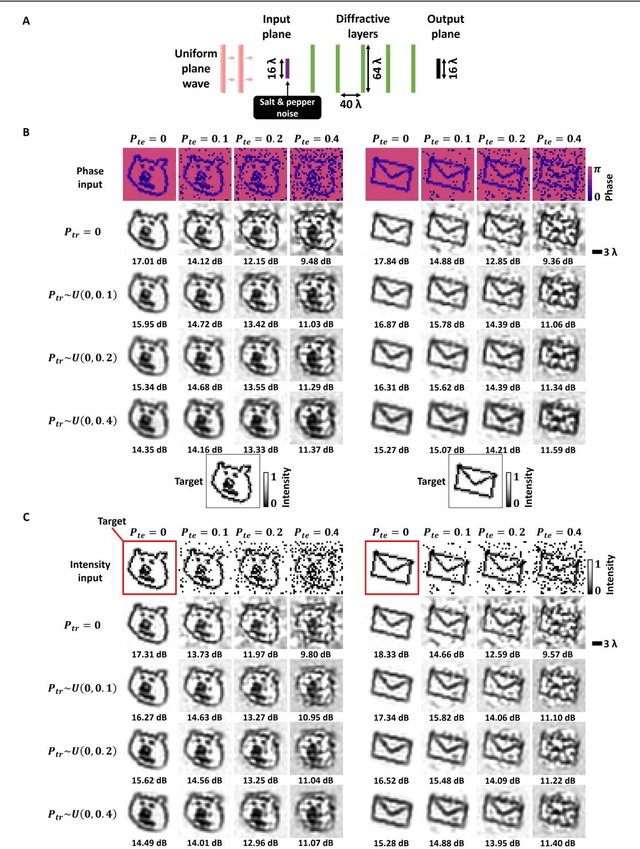
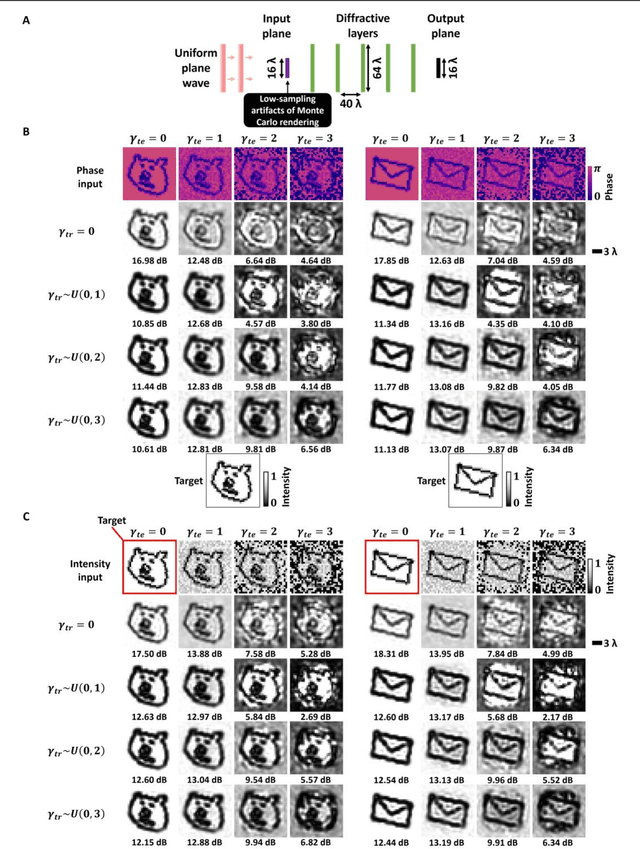
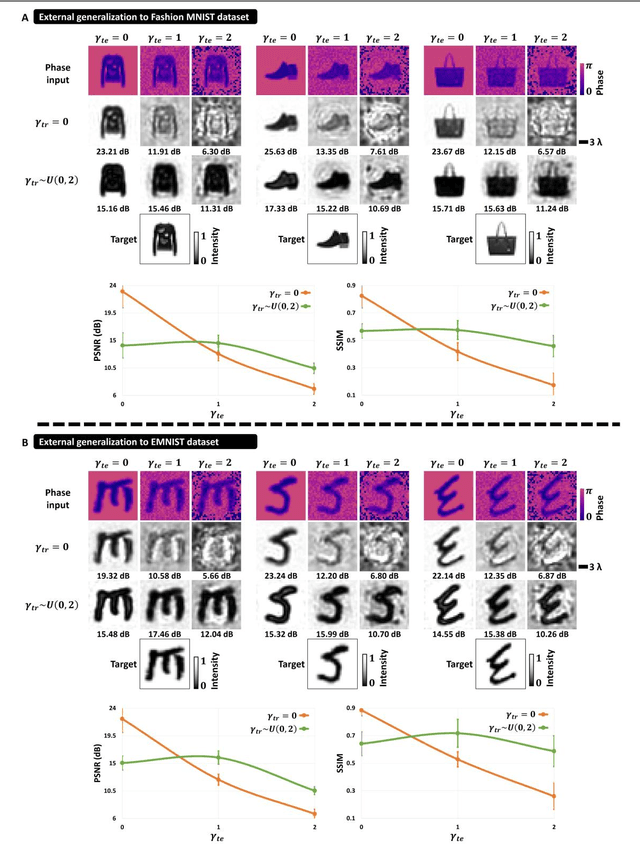
Image denoising, one of the essential inverse problems, targets to remove noise/artifacts from input images. In general, digital image denoising algorithms, executed on computers, present latency due to several iterations implemented in, e.g., graphics processing units (GPUs). While deep learning-enabled methods can operate non-iteratively, they also introduce latency and impose a significant computational burden, leading to increased power consumption. Here, we introduce an analog diffractive image denoiser to all-optically and non-iteratively clean various forms of noise and artifacts from input images - implemented at the speed of light propagation within a thin diffractive visual processor. This all-optical image denoiser comprises passive transmissive layers optimized using deep learning to physically scatter the optical modes that represent various noise features, causing them to miss the output image Field-of-View (FoV) while retaining the object features of interest. Our results show that these diffractive denoisers can efficiently remove salt and pepper noise and image rendering-related spatial artifacts from input phase or intensity images while achieving an output power efficiency of ~30-40%. We experimentally demonstrated the effectiveness of this analog denoiser architecture using a 3D-printed diffractive visual processor operating at the terahertz spectrum. Owing to their speed, power-efficiency, and minimal computational overhead, all-optical diffractive denoisers can be transformative for various image display and projection systems, including, e.g., holographic displays.
Fuse Your Latents: Video Editing with Multi-source Latent Diffusion Models
Oct 25, 2023Latent Diffusion Models (LDMs) are renowned for their powerful capabilities in image and video synthesis. Yet, video editing methods suffer from insufficient pre-training data or video-by-video re-training cost. In addressing this gap, we propose FLDM (Fused Latent Diffusion Model), a training-free framework to achieve text-guided video editing by applying off-the-shelf image editing methods in video LDMs. Specifically, FLDM fuses latents from an image LDM and an video LDM during the denoising process. In this way, temporal consistency can be kept with video LDM while high-fidelity from the image LDM can also be exploited. Meanwhile, FLDM possesses high flexibility since both image LDM and video LDM can be replaced so advanced image editing methods such as InstructPix2Pix and ControlNet can be exploited. To the best of our knowledge, FLDM is the first method to adapt off-the-shelf image editing methods into video LDMs for video editing. Extensive quantitative and qualitative experiments demonstrate that FLDM can improve the textual alignment and temporal consistency of edited videos.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 01, 2023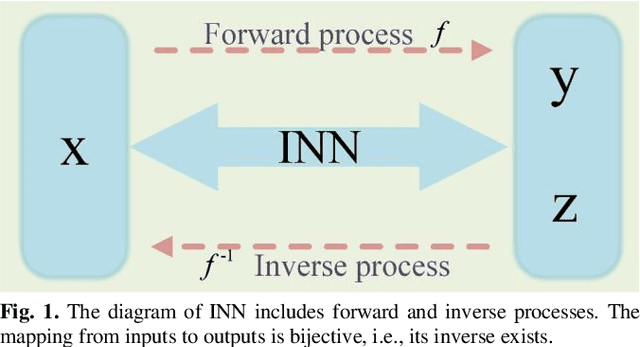
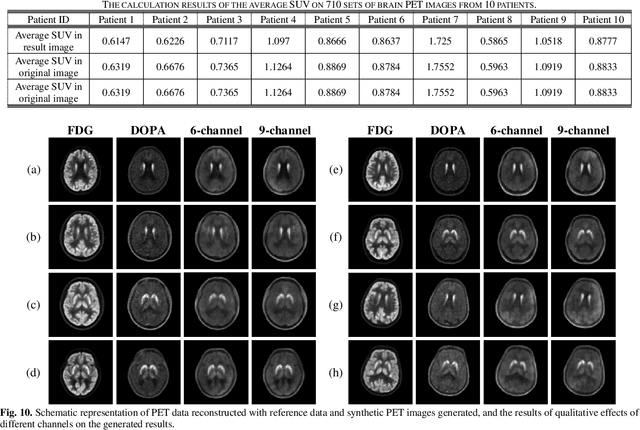
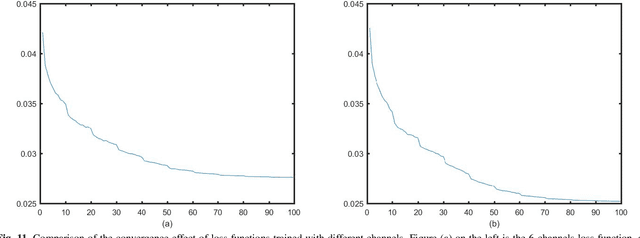
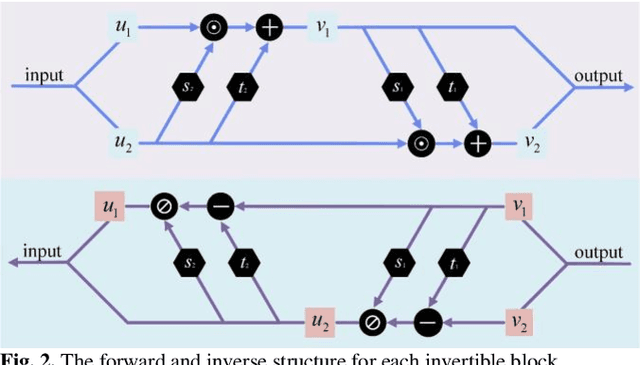
Positron emission tomography (PET), as an imaging technique with high biochemical sensitivity, has been widely used in diagnosis of encephalopathy and brain science research used in brain disease diagnosis and brain science research. Since different tracers present different effects on the same focal area, the choice of tracers is getting more significant for PET imaging. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in this field. However, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training the traceable data, the other for re-building the new data. The reference DOPA PET image is used as the learning target for the corresponding network during the training process of tracer conversion. Mean-while, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employed variable enhancement techniques to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results show generative ability in mapping be-tween FDG images and DOPA images. It demonstrates great potential for PET image conversion in the case of limited tracer applications.
Learning-Based Biharmonic Augmentation for Point Cloud Classification
Nov 10, 2023Point cloud datasets often suffer from inadequate sample sizes in comparison to image datasets, making data augmentation challenging. While traditional methods, like rigid transformations and scaling, have limited potential in increasing dataset diversity due to their constraints on altering individual sample shapes, we introduce the Biharmonic Augmentation (BA) method. BA is a novel and efficient data augmentation technique that diversifies point cloud data by imposing smooth non-rigid deformations on existing 3D structures. This approach calculates biharmonic coordinates for the deformation function and learns diverse deformation prototypes. Utilizing a CoefNet, our method predicts coefficients to amalgamate these prototypes, ensuring comprehensive deformation. Moreover, we present AdvTune, an advanced online augmentation system that integrates adversarial training. This system synergistically refines the CoefNet and the classification network, facilitating the automated creation of adaptive shape deformations contingent on the learner status. Comprehensive experimental analysis validates the superiority of Biharmonic Augmentation, showcasing notable performance improvements over prevailing point cloud augmentation techniques across varied network designs.
Deep Fast Vision: A Python Library for Accelerated Deep Transfer Learning Vision Prototyping
Nov 10, 2023Deep learning-based vision is characterized by intricate frameworks that often necessitate a profound understanding, presenting a barrier to newcomers and limiting broad adoption. With many researchers grappling with the constraints of smaller datasets, there's a pronounced reliance on pre-trained neural networks, especially for tasks such as image classification. This reliance is further intensified in niche imaging areas where obtaining vast datasets is challenging. Despite the widespread use of transfer learning as a remedy to the small dataset dilemma, a conspicuous absence of tailored auto-ML solutions persists. Addressing these challenges is "Deep Fast Vision", a python library that streamlines the deep learning process. This tool offers a user-friendly experience, enabling results through a simple nested dictionary definition, helping to democratize deep learning for non-experts. Designed for simplicity and scalability, Deep Fast Vision appears as a bridge, connecting the complexities of existing deep learning frameworks with the needs of a diverse user base.