 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Domain Generalization in Magnetic Resonance-Based Assessment of Alzheimer's Disease
Jan 04, 2026Despite progress in deep learning for Alzheimer's disease (AD) diagnostics, models trained on structural magnetic resonance imaging (sMRI) often do not perform well when applied to new cohorts due to domain shifts from varying scanners, protocols and patient demographics. AD, the primary driver of dementia, manifests through progressive cognitive and neuroanatomical changes like atrophy and ventricular expansion, making robust, generalizable classification essential for real-world use. While convolutional neural networks and transformers have advanced feature extraction via attention and fusion techniques, single-domain generalization (SDG) remains underexplored yet critical, given the fragmented nature of AD datasets. To bridge this gap, we introduce Extended MixStyle (EM), a framework for blending higher-order feature moments (skewness and kurtosis) to mimic diverse distributional variations. Trained on sMRI data from the National Alzheimer's Coordinating Center (NACC; n=4,647) to differentiate persons with normal cognition (NC) from those with mild cognitive impairment (MCI) or AD and tested on three unseen cohorts (total n=3,126), EM yields enhanced cross-domain performance, improving macro-F1 on average by 2.4 percentage points over state-of-the-art SDG benchmarks, underscoring its promise for invariant, reliable AD detection in heterogeneous real-world settings. The source code will be made available upon acceptance at https://github.com/zobia111/Extended-Mixstyle.
MACL: Multi-Label Adaptive Contrastive Learning Loss for Remote Sensing Image Retrieval
Dec 18, 2025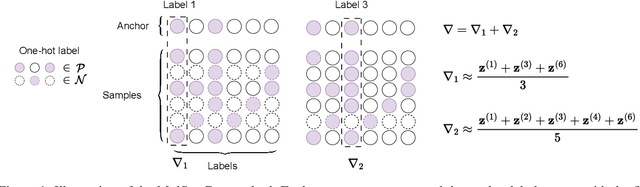

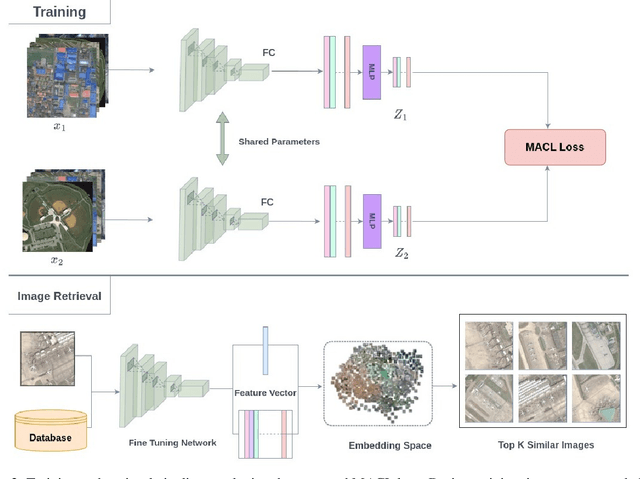
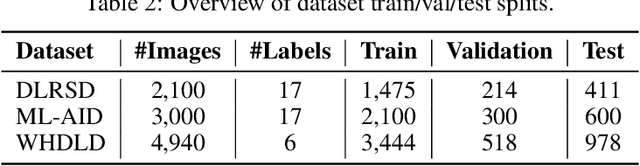
Semantic overlap among land-cover categories, highly imbalanced label distributions, and complex inter-class co-occurrence patterns constitute significant challenges for multi-label remote-sensing image retrieval. In this article, Multi-Label Adaptive Contrastive Learning (MACL) is introduced as an extension of contrastive learning to address them. It integrates label-aware sampling, frequency-sensitive weighting, and dynamic-temperature scaling to achieve balanced representation learning across both common and rare categories. Extensive experiments on three benchmark datasets (DLRSD, ML-AID, and WHDLD), show that MACL consistently outperforms contrastive-loss based baselines, effectively mitigating semantic imbalance and delivering more reliable retrieval performance in large-scale remote-sensing archives. Code, pretrained models, and evaluation scripts will be released at https://github.com/amna/MACL upon acceptance.
Text-conditioned State Space Model For Domain-generalized Change Detection Visual Question Answering
Aug 12, 2025The Earth's surface is constantly changing, and detecting these changes provides valuable insights that benefit various aspects of human society. While traditional change detection methods have been employed to detect changes from bi-temporal images, these approaches typically require expert knowledge for accurate interpretation. To enable broader and more flexible access to change information by non-expert users, the task of Change Detection Visual Question Answering (CDVQA) has been introduced. However, existing CDVQA methods have been developed under the assumption that training and testing datasets share similar distributions. This assumption does not hold in real-world applications, where domain shifts often occur. In this paper, the CDVQA task is revisited with a focus on addressing domain shift. To this end, a new multi-modal and multi-domain dataset, BrightVQA, is introduced to facilitate domain generalization research in CDVQA. Furthermore, a novel state space model, termed Text-Conditioned State Space Model (TCSSM), is proposed. The TCSSM framework is designed to leverage both bi-temporal imagery and geo-disaster-related textual information in an unified manner to extract domain-invariant features across domains. Input-dependent parameters existing in TCSSM are dynamically predicted by using both bi-temporal images and geo-disaster-related description, thereby facilitating the alignment between bi-temporal visual data and the associated textual descriptions. Extensive experiments are conducted to evaluate the proposed method against state-of-the-art models, and superior performance is consistently demonstrated. The code and dataset will be made publicly available upon acceptance at https://github.com/Elman295/TCSSM.
Evidential Deep Learning with Spectral-Spatial Uncertainty Disentanglement for Open-Set Hyperspectral Domain Generalization
Jun 11, 2025Open-set domain generalization(OSDG) for hyperspectral image classification presents significant challenges due to the presence of unknown classes in target domains and the need for models to generalize across multiple unseen domains without target-specific adaptation. Existing domain adaptation methods assume access to target domain data during training and fail to address the fundamental issue of domain shift when unknown classes are present, leading to negative transfer and reduced classification performance. To address these limitations, we propose a novel open-set domain generalization framework that combines four key components: Spectrum-Invariant Frequency Disentanglement (SIFD) for domain-agnostic feature extraction, Dual-Channel Residual Network (DCRN) for robust spectral-spatial feature learning, Evidential Deep Learning (EDL) for uncertainty quantification, and Spectral-Spatial Uncertainty Disentanglement (SSUD) for reliable open-set classification. The SIFD module extracts domain-invariant spectral features in the frequency domain through attention-weighted frequency analysis and domain-agnostic regularization, while DCRN captures complementary spectral and spatial information via parallel pathways with adaptive fusion. EDL provides principled uncertainty estimation using Dirichlet distributions, enabling the SSUD module to make reliable open-set decisions through uncertainty-aware pathway weighting and adaptive rejection thresholding. Experimental results on three cross-scene hyperspectral classification tasks show that our approach achieves performance comparable to state-of-the-art domain adaptation methods while requiring no access to the target domain during training. The implementation will be made available at https://github.com/amir-khb/SSUDOSDG upon acceptance.
Single Domain Generalization for Alzheimer's Detection from 3D MRIs with Pseudo-Morphological Augmentations and Contrastive Learning
May 28, 2025Although Alzheimer's disease detection via MRIs has advanced significantly thanks to contemporary deep learning models, challenges such as class imbalance, protocol variations, and limited dataset diversity often hinder their generalization capacity. To address this issue, this article focuses on the single domain generalization setting, where given the data of one domain, a model is designed and developed with maximal performance w.r.t. an unseen domain of distinct distribution. Since brain morphology is known to play a crucial role in Alzheimer's diagnosis, we propose the use of learnable pseudo-morphological modules aimed at producing shape-aware, anatomically meaningful class-specific augmentations in combination with a supervised contrastive learning module to extract robust class-specific representations. Experiments conducted across three datasets show improved performance and generalization capacity, especially under class imbalance and imaging protocol variations. The source code will be made available upon acceptance at https://github.com/zobia111/SDG-Alzheimer.
Distance Transform Guided Mixup for Alzheimer's Detection
May 28, 2025Alzheimer's detection efforts aim to develop accurate models for early disease diagnosis. Significant advances have been achieved with convolutional neural networks and vision transformer based approaches. However, medical datasets suffer heavily from class imbalance, variations in imaging protocols, and limited dataset diversity, which hinder model generalization. To overcome these challenges, this study focuses on single-domain generalization by extending the well-known mixup method. The key idea is to compute the distance transform of MRI scans, separate them spatially into multiple layers and then combine layers stemming from distinct samples to produce augmented images. The proposed approach generates diverse data while preserving the brain's structure. Experimental results show generalization performance improvement across both ADNI and AIBL datasets.
Change State Space Models for Remote Sensing Change Detection
Apr 15, 2025Despite their frequent use for change detection, both ConvNets and Vision transformers (ViT) exhibit well-known limitations, namely the former struggle to model long-range dependencies while the latter are computationally inefficient, rendering them challenging to train on large-scale datasets. Vision Mamba, an architecture based on State Space Models has emerged as an alternative addressing the aforementioned deficiencies and has been already applied to remote sensing change detection, though mostly as a feature extracting backbone. In this article the Change State Space Model is introduced, that has been specifically designed for change detection by focusing on the relevant changes between bi-temporal images, effectively filtering out irrelevant information. By concentrating solely on the changed features, the number of network parameters is reduced, enhancing significantly computational efficiency while maintaining high detection performance and robustness against input degradation. The proposed model has been evaluated via three benchmark datasets, where it outperformed ConvNets, ViTs, and Mamba-based counterparts at a fraction of their computational complexity. The implementation will be made available at https://github.com/Elman295/CSSM upon acceptance.
Adapting the Biological SSVEP Response to Artificial Neural Networks
Nov 15, 2024



Neuron importance assessment is crucial for understanding the inner workings of artificial neural networks (ANNs) and improving their interpretability and efficiency. This paper introduces a novel approach to neuron significance assessment inspired by frequency tagging, a technique from neuroscience. By applying sinusoidal contrast modulation to image inputs and analyzing resulting neuron activations, this method enables fine-grained analysis of a network's decision-making processes. Experiments conducted with a convolutional neural network for image classification reveal notable harmonics and intermodulations in neuron-specific responses under part-based frequency tagging. These findings suggest that ANNs exhibit behavior akin to biological brains in tuning to flickering frequencies, thereby opening avenues for neuron/filter importance assessment through frequency tagging. The proposed method holds promise for applications in network pruning, and model interpretability, contributing to the advancement of explainable artificial intelligence and addressing the lack of transparency in neural networks. Future research directions include developing novel loss functions to encourage biologically plausible behavior in ANNs.
Explainable AI for Earth Observation: Current Methods, Open Challenges, and Opportunities
Nov 08, 2023Deep learning has taken by storm all fields involved in data analysis, including remote sensing for Earth observation. However, despite significant advances in terms of performance, its lack of explainability and interpretability, inherent to neural networks in general since their inception, remains a major source of criticism. Hence it comes as no surprise that the expansion of deep learning methods in remote sensing is being accompanied by increasingly intensive efforts oriented towards addressing this drawback through the exploration of a wide spectrum of Explainable Artificial Intelligence techniques. This chapter, organized according to prominent Earth observation application fields, presents a panorama of the state-of-the-art in explainable remote sensing image analysis.
ADRMX: Additive Disentanglement of Domain Features with Remix Loss
Aug 12, 2023



The common assumption that train and test sets follow similar distributions is often violated in deployment settings. Given multiple source domains, domain generalization aims to create robust models capable of generalizing to new unseen domains. To this end, most of existing studies focus on extracting domain invariant features across the available source domains in order to mitigate the effects of inter-domain distributional changes. However, this approach may limit the model's generalization capacity by relying solely on finding common features among the source domains. It overlooks the potential presence of domain-specific characteristics that could be prevalent in a subset of domains, potentially containing valuable information. In this work, a novel architecture named Additive Disentanglement of Domain Features with Remix Loss (ADRMX) is presented, which addresses this limitation by incorporating domain variant features together with the domain invariant ones using an original additive disentanglement strategy. Moreover, a new data augmentation technique is introduced to further support the generalization capacity of ADRMX, where samples from different domains are mixed within the latent space. Through extensive experiments conducted on DomainBed under fair conditions, ADRMX is shown to achieve state-of-the-art performance. Code will be made available at GitHub after the revision process.