 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Elucidating and Overcoming the Challenges of Label Noise in Supervised Contrastive Learning
Nov 25, 2023
Image classification datasets exhibit a non-negligible fraction of mislabeled examples, often due to human error when one class superficially resembles another. This issue poses challenges in supervised contrastive learning (SCL), where the goal is to cluster together data points of the same class in the embedding space while distancing those of disparate classes. While such methods outperform those based on cross-entropy, they are not immune to labeling errors. However, while the detrimental effects of noisy labels in supervised learning are well-researched, their influence on SCL remains largely unexplored. Hence, we analyse the effect of label errors and examine how they disrupt the SCL algorithm's ability to distinguish between positive and negative sample pairs. Our analysis reveals that human labeling errors manifest as easy positive samples in around 99% of cases. We, therefore, propose D-SCL, a novel Debiased Supervised Contrastive Learning objective designed to mitigate the bias introduced by labeling errors. We demonstrate that D-SCL consistently outperforms state-of-the-art techniques for representation learning across diverse vision benchmarks, offering improved robustness to label errors.
Resolution- and Stimulus-agnostic Super-Resolution of Ultra-High-Field Functional MRI: Application to Visual Studies
Nov 25, 2023High-resolution fMRI provides a window into the brain's mesoscale organization. Yet, higher spatial resolution increases scan times, to compensate for the low signal and contrast-to-noise ratio. This work introduces a deep learning-based 3D super-resolution (SR) method for fMRI. By incorporating a resolution-agnostic image augmentation framework, our method adapts to varying voxel sizes without retraining. We apply this innovative technique to localize fine-scale motion-selective sites in the early visual areas. Detection of these sites typically requires a resolution higher than 1 mm isotropic, whereas here, we visualize them based on lower resolution (2-3mm isotropic) fMRI data. Remarkably, the super-resolved fMRI is able to recover high-frequency detail of the interdigitated organization of these sites (relative to the color-selective sites), even with training data sourced from different subjects and experimental paradigms -- including non-visual resting-state fMRI, underscoring its robustness and versatility. Quantitative and qualitative results indicate that our method has the potential to enhance the spatial resolution of fMRI, leading to a drastic reduction in acquisition time.
Efficient-VQGAN: Towards High-Resolution Image Generation with Efficient Vision Transformers
Oct 09, 2023

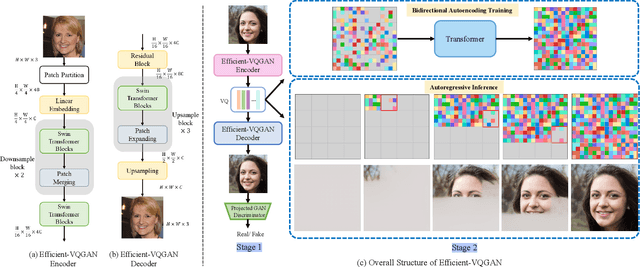
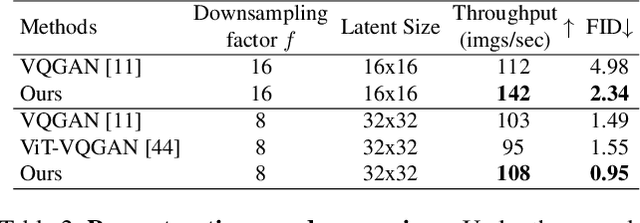
Vector-quantized image modeling has shown great potential in synthesizing high-quality images. However, generating high-resolution images remains a challenging task due to the quadratic computational overhead of the self-attention process. In this study, we seek to explore a more efficient two-stage framework for high-resolution image generation with improvements in the following three aspects. (1) Based on the observation that the first quantization stage has solid local property, we employ a local attention-based quantization model instead of the global attention mechanism used in previous methods, leading to better efficiency and reconstruction quality. (2) We emphasize the importance of multi-grained feature interaction during image generation and introduce an efficient attention mechanism that combines global attention (long-range semantic consistency within the whole image) and local attention (fined-grained details). This approach results in faster generation speed, higher generation fidelity, and improved resolution. (3) We propose a new generation pipeline incorporating autoencoding training and autoregressive generation strategy, demonstrating a better paradigm for image synthesis. Extensive experiments demonstrate the superiority of our approach in high-quality and high-resolution image reconstruction and generation.
A Survey of Emerging Applications of Diffusion Probabilistic Models in MRI
Nov 19, 2023Diffusion probabilistic models (DPMs) which employ explicit likelihood characterization and a gradual sampling process to synthesize data, have gained increasing research interest. Despite their huge computational burdens due to the large number of steps involved during sampling, DPMs are widely appreciated in various medical imaging tasks for their high-quality and diversity of generation. Magnetic resonance imaging (MRI) is an important medical imaging modality with excellent soft tissue contrast and superb spatial resolution, which possesses unique opportunities for diffusion models. Although there is a recent surge of studies exploring DPMs in MRI, a survey paper of DPMs specifically designed for MRI applications is still lacking. This review article aims to help researchers in the MRI community to grasp the advances of DPMs in different applications. We first introduce the theory of two dominant kinds of DPMs, categorized according to whether the diffusion time step is discrete or continuous, and then provide a comprehensive review of emerging DPMs in MRI, including reconstruction, image generation, image translation, segmentation, anomaly detection, and further research topics. Finally, we discuss the general limitations as well as limitations specific to the MRI tasks of DPMs and point out potential areas that are worth further exploration.
Data efficient deep learning for medical image analysis: A survey
Oct 10, 2023The rapid evolution of deep learning has significantly advanced the field of medical image analysis. However, despite these achievements, the further enhancement of deep learning models for medical image analysis faces a significant challenge due to the scarcity of large, well-annotated datasets. To address this issue, recent years have witnessed a growing emphasis on the development of data-efficient deep learning methods. This paper conducts a thorough review of data-efficient deep learning methods for medical image analysis. To this end, we categorize these methods based on the level of supervision they rely on, encompassing categories such as no supervision, inexact supervision, incomplete supervision, inaccurate supervision, and only limited supervision. We further divide these categories into finer subcategories. For example, we categorize inexact supervision into multiple instance learning and learning with weak annotations. Similarly, we categorize incomplete supervision into semi-supervised learning, active learning, and domain-adaptive learning and so on. Furthermore, we systematically summarize commonly used datasets for data efficient deep learning in medical image analysis and investigate future research directions to conclude this survey.
Learning Saliency From Fixations
Nov 23, 2023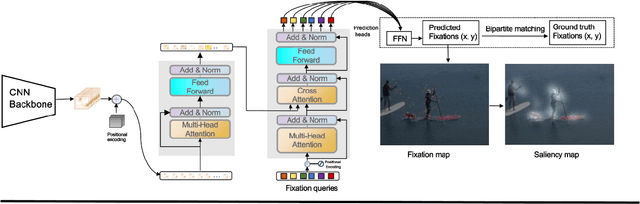
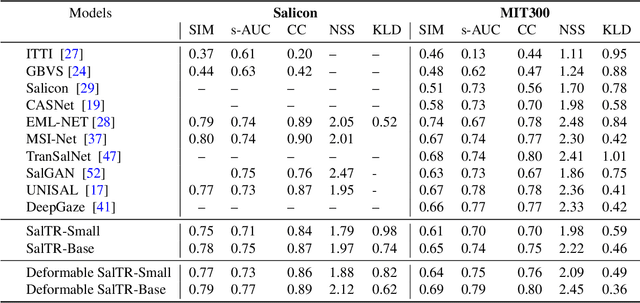

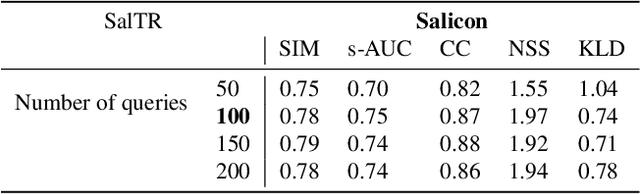
We present a novel approach for saliency prediction in images, leveraging parallel decoding in transformers to learn saliency solely from fixation maps. Models typically rely on continuous saliency maps, to overcome the difficulty of optimizing for the discrete fixation map. We attempt to replicate the experimental setup that generates saliency datasets. Our approach treats saliency prediction as a direct set prediction problem, via a global loss that enforces unique fixations prediction through bipartite matching and a transformer encoder-decoder architecture. By utilizing a fixed set of learned fixation queries, the cross-attention reasons over the image features to directly output the fixation points, distinguishing it from other modern saliency predictors. Our approach, named Saliency TRansformer (SalTR), achieves metric scores on par with state-of-the-art approaches on the Salicon and MIT300 benchmarks.
Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models
Oct 11, 2023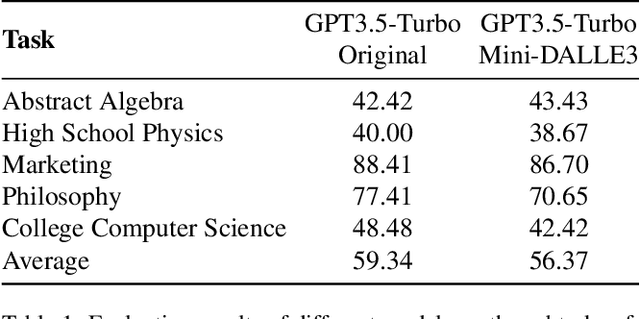
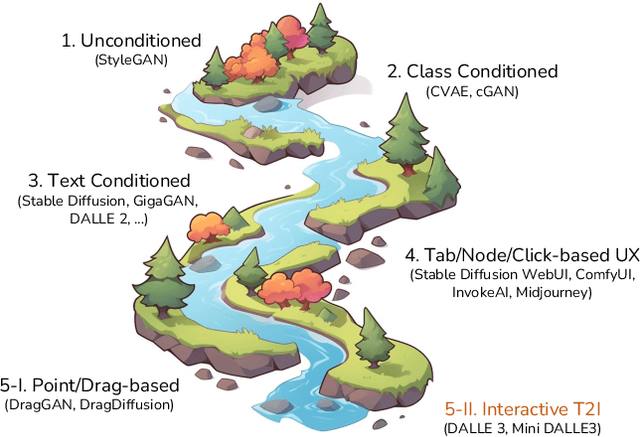
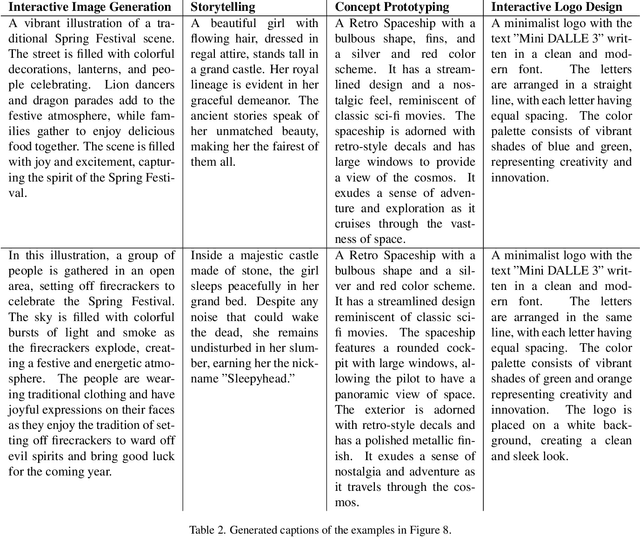

The revolution of artificial intelligence content generation has been rapidly accelerated with the booming text-to-image (T2I) diffusion models. Within just two years of development, it was unprecedentedly of high-quality, diversity, and creativity that the state-of-the-art models could generate. However, a prevalent limitation persists in the effective communication with these popular T2I models, such as Stable Diffusion, using natural language descriptions. This typically makes an engaging image hard to obtain without expertise in prompt engineering with complex word compositions, magic tags, and annotations. Inspired by the recently released DALLE3 - a T2I model directly built-in ChatGPT that talks human language, we revisit the existing T2I systems endeavoring to align human intent and introduce a new task - interactive text to image (iT2I), where people can interact with LLM for interleaved high-quality image generation/edit/refinement and question answering with stronger images and text correspondences using natural language. In addressing the iT2I problem, we present a simple approach that augments LLMs for iT2I with prompting techniques and off-the-shelf T2I models. We evaluate our approach for iT2I in a variety of common-used scenarios under different LLMs, e.g., ChatGPT, LLAMA, Baichuan, and InternLM. We demonstrate that our approach could be a convenient and low-cost way to introduce the iT2I ability for any existing LLMs and any text-to-image models without any training while bringing little degradation on LLMs' inherent capabilities in, e.g., question answering and code generation. We hope this work could draw broader attention and provide inspiration for boosting user experience in human-machine interactions alongside the image quality of the next-generation T2I systems.
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Oct 23, 2023In this work, we introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images.Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details.To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and reasonably good efficiency compared to prior works.
CalibFormer: A Transformer-based Automatic LiDAR-Camera Calibration Network
Nov 26, 2023The fusion of LiDARs and cameras has been increasingly adopted in autonomous driving for perception tasks. The performance of such fusion-based algorithms largely depends on the accuracy of sensor calibration, which is challenging due to the difficulty of identifying common features across different data modalities. Previously, many calibration methods involved specific targets and/or manual intervention, which has proven to be cumbersome and costly. Learning-based online calibration methods have been proposed, but their performance is barely satisfactory in most cases. These methods usually suffer from issues such as sparse feature maps, unreliable cross-modality association, inaccurate calibration parameter regression, etc. In this paper, to address these issues, we propose CalibFormer, an end-to-end network for automatic LiDAR-camera calibration. We aggregate multiple layers of camera and LiDAR image features to achieve high-resolution representations. A multi-head correlation module is utilized to identify correlations between features more accurately. Lastly, we employ transformer architectures to estimate accurate calibration parameters from the correlation information. Our method achieved a mean translation error of $0.8751 \mathrm{cm}$ and a mean rotation error of $0.0562 ^{\circ}$ on the KITTI dataset, surpassing existing state-of-the-art methods and demonstrating strong robustness, accuracy, and generalization capabilities.
meta4: semantically-aligned generation of metaphoric gestures using self-supervised text and speech representation
Nov 09, 2023Image Schemas are repetitive cognitive patterns that influence the way we conceptualize and reason about various concepts present in speech. These patterns are deeply embedded within our cognitive processes and are reflected in our bodily expressions including gestures. Particularly, metaphoric gestures possess essential characteristics and semantic meanings that align with Image Schemas, to visually represent abstract concepts. The shape and form of gestures can convey abstract concepts, such as extending the forearm and hand or tracing a line with hand movements to visually represent the image schema of PATH. Previous behavior generation models have primarily focused on utilizing speech (acoustic features and text) to drive the generation model of virtual agents. They have not considered key semantic information as those carried by Image Schemas to effectively generate metaphoric gestures. To address this limitation, we introduce META4, a deep learning approach that generates metaphoric gestures from both speech and Image Schemas. Our approach has two primary goals: computing Image Schemas from input text to capture the underlying semantic and metaphorical meaning, and generating metaphoric gestures driven by speech and the computed image schemas. Our approach is the first method for generating speech driven metaphoric gestures while leveraging the potential of Image Schemas. We demonstrate the effectiveness of our approach and highlight the importance of both speech and image schemas in modeling metaphoric gestures.