 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EMIT-Diff: Enhancing Medical Image Segmentation via Text-Guided Diffusion Model
Oct 19, 2023
Large-scale, big-variant, and high-quality data are crucial for developing robust and successful deep-learning models for medical applications since they potentially enable better generalization performance and avoid overfitting. However, the scarcity of high-quality labeled data always presents significant challenges. This paper proposes a novel approach to address this challenge by developing controllable diffusion models for medical image synthesis, called EMIT-Diff. We leverage recent diffusion probabilistic models to generate realistic and diverse synthetic medical image data that preserve the essential characteristics of the original medical images by incorporating edge information of objects to guide the synthesis process. In our approach, we ensure that the synthesized samples adhere to medically relevant constraints and preserve the underlying structure of imaging data. Due to the random sampling process by the diffusion model, we can generate an arbitrary number of synthetic images with diverse appearances. To validate the effectiveness of our proposed method, we conduct an extensive set of medical image segmentation experiments on multiple datasets, including Ultrasound breast (+13.87%), CT spleen (+0.38%), and MRI prostate (+7.78%), achieving significant improvements over the baseline segmentation methods. For the first time, to our best knowledge, the promising results demonstrate the effectiveness of our EMIT-Diff for medical image segmentation tasks and show the feasibility of introducing a first-ever text-guided diffusion model for general medical image segmentation tasks. With carefully designed ablation experiments, we investigate the influence of various data augmentation ratios, hyper-parameter settings, patch size for generating random merging mask settings, and combined influence with different network architectures.
Unbalancedness in Neural Monge Maps Improves Unpaired Domain Translation
Nov 25, 2023In optimal transport (OT), a Monge map is known as a mapping that transports a source distribution to a target distribution in the most cost-efficient way. Recently, multiple neural estimators for Monge maps have been developed and applied in diverse unpaired domain translation tasks, e.g. in single-cell biology and computer vision. However, the classic OT framework enforces mass conservation, which makes it prone to outliers and limits its applicability in real-world scenarios. The latter can be particularly harmful in OT domain translation tasks, where the relative position of a sample within a distribution is explicitly taken into account. While unbalanced OT tackles this challenge in the discrete setting, its integration into neural Monge map estimators has received limited attention. We propose a theoretically grounded method to incorporate unbalancedness into any Monge map estimator. We improve existing estimators to model cell trajectories over time and to predict cellular responses to perturbations. Moreover, our approach seamlessly integrates with the OT flow matching (OT-FM) framework. While we show that OT-FM performs competitively in image translation, we further improve performance by incorporating unbalancedness (UOT-FM), which better preserves relevant features. We hence establish UOT-FM as a principled method for unpaired image translation.
Energy-Calibrated VAE with Test Time Free Lunch
Nov 21, 2023In this paper, we propose a novel generative model that utilizes a conditional Energy-Based Model (EBM) for enhancing Variational Autoencoder (VAE), termed Energy-Calibrated VAE (EC-VAE). Specifically, VAEs often suffer from blurry generated samples due to the lack of a tailored training on the samples generated in the generative direction. On the other hand, EBMs can generate high-quality samples but require expensive Markov Chain Monte Carlo (MCMC) sampling. To address these issues, we introduce a conditional EBM for calibrating the generative direction of VAE during training, without requiring it for the generation at test time. In particular, we train EC-VAE upon both the input data and the calibrated samples with adaptive weight to enhance efficacy while avoiding MCMC sampling at test time. Furthermore, we extend the calibration idea of EC-VAE to variational learning and normalizing flows, and apply EC-VAE to an additional application of zero-shot image restoration via neural transport prior and range-null theory. We evaluate the proposed method with two applications, including image generation and zero-shot image restoration, and the experimental results show that our method achieves the state-of-the-art performance over single-step non-adversarial generation.
Polyhedral Object Recognition by Indexing
Nov 21, 2023In computer vision, the indexing problem is the problem of recognizing a few objects in a large database of objects while avoiding the help of the classical image-feature-to-object-feature matching paradigm. In this paper we address the problem of recognizing 3-D polyhedral objects from 2-D images by indexing. Both the objects to be recognized and the images are represented by weighted graphs. The indexing problem is therefore the problem of determining whether a graph extracted from the image is present or absent in a database of model graphs. We introduce a novel method for performing this graph indexing process which is based both on polynomial characterization of binary and weighted graphs and on hashing. We describe in detail this polynomial characterization and then we show how it can be used in the context of polyhedral object recognition. Next we describe a practical recognition-by-indexing system that includes the organization of the database, the representation of polyhedral objects in terms of 2-D characteristic views, the representation of this views in terms of weighted graphs, and the associated image processing. Finally, some experimental results allow the evaluation of the system performance.
Explainable Image Similarity: Integrating Siamese Networks and Grad-CAM
Oct 11, 2023With the proliferation of image-based applications in various domains, the need for accurate and interpretable image similarity measures has become increasingly critical. Existing image similarity models often lack transparency, making it challenging to understand the reasons why two images are considered similar. In this paper, we propose the concept of explainable image similarity, where the goal is the development of an approach, which is capable of providing similarity scores along with visual factual and counterfactual explanations. Along this line, we present a new framework, which integrates Siamese Networks and Grad-CAM for providing explainable image similarity and discuss the potential benefits and challenges of adopting this approach. In addition, we provide a comprehensive discussion about factual and counterfactual explanations provided by the proposed framework for assisting decision making. The proposed approach has the potential to enhance the interpretability, trustworthiness and user acceptance of image-based systems in real-world image similarity applications. The implementation code can be found in https://github.com/ioannislivieris/Grad_CAM_Siamese.git.
Adversarial Purification of Information Masking
Nov 26, 2023Adversarial attacks meticulously generate minuscule, imperceptible perturbations to images to deceive neural networks. Counteracting these, adversarial purification methods seek to transform adversarial input samples into clean output images to defend against adversarial attacks. Nonetheless, extent generative models fail to effectively eliminate adversarial perturbations, yielding less-than-ideal purification results. We emphasize the potential threat of residual adversarial perturbations to target models, quantitatively establishing a relationship between perturbation scale and attack capability. Notably, the residual perturbations on the purified image primarily stem from the same-position patch and similar patches of the adversarial sample. We propose a novel adversarial purification approach named Information Mask Purification (IMPure), aims to extensively eliminate adversarial perturbations. To obtain an adversarial sample, we first mask part of the patches information, then reconstruct the patches to resist adversarial perturbations from the patches. We reconstruct all patches in parallel to obtain a cohesive image. Then, in order to protect the purified samples against potential similar regional perturbations, we simulate this risk by randomly mixing the purified samples with the input samples before inputting them into the feature extraction network. Finally, we establish a combined constraint of pixel loss and perceptual loss to augment the model's reconstruction adaptability. Extensive experiments on the ImageNet dataset with three classifier models demonstrate that our approach achieves state-of-the-art results against nine adversarial attack methods. Implementation code and pre-trained weights can be accessed at \textcolor{blue}{https://github.com/NoWindButRain/IMPure}.
Ultra-Range Gesture Recognition using an RGB Camera in Human-Robot Interaction
Nov 26, 2023
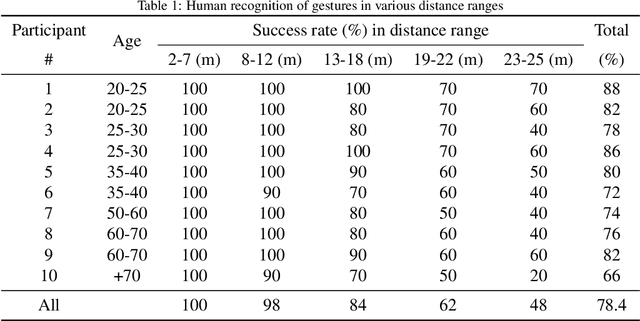

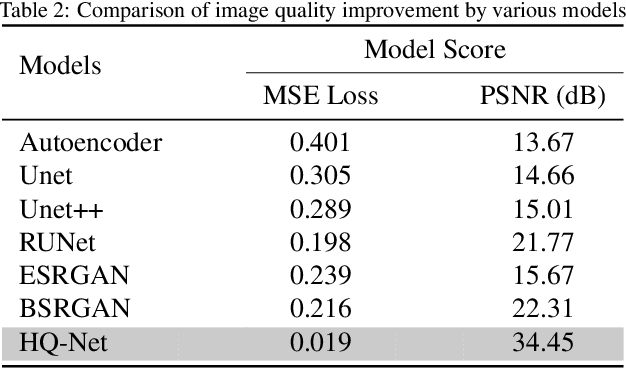
Hand gestures play a significant role in human interactions where non-verbal intentions, thoughts and commands are conveyed. In Human-Robot Interaction (HRI), hand gestures offer a similar and efficient medium for conveying clear and rapid directives to a robotic agent. However, state-of-the-art vision-based methods for gesture recognition have been shown to be effective only up to a user-camera distance of seven meters. Such a short distance range limits practical HRI with, for example, service robots, search and rescue robots and drones. In this work, we address the Ultra-Range Gesture Recognition (URGR) problem by aiming for a recognition distance of up to 25 meters and in the context of HRI. We propose a novel deep-learning framework for URGR using solely a simple RGB camera. First, a novel super-resolution model termed HQ-Net is used to enhance the low-resolution image of the user. Then, we propose a novel URGR classifier termed Graph Vision Transformer (GViT) which takes the enhanced image as input. GViT combines the benefits of a Graph Convolutional Network (GCN) and a modified Vision Transformer (ViT). Evaluation of the proposed framework over diverse test data yields a high recognition rate of 98.1%. The framework has also exhibited superior performance compared to human recognition in ultra-range distances. With the framework, we analyze and demonstrate the performance of an autonomous quadruped robot directed by human gestures in complex ultra-range indoor and outdoor environments.
BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP
Nov 26, 2023Contrastive Vision-Language Pre-training, known as CLIP, has shown promising effectiveness in addressing downstream image recognition tasks. However, recent works revealed that the CLIP model can be implanted with a downstream-oriented backdoor. On downstream tasks, one victim model performs well on clean samples but predicts a specific target class whenever a specific trigger is present. For injecting a backdoor, existing attacks depend on a large amount of additional data to maliciously fine-tune the entire pre-trained CLIP model, which makes them inapplicable to data-limited scenarios. In this work, motivated by the recent success of learnable prompts, we address this problem by injecting a backdoor into the CLIP model in the prompt learning stage. Our method named BadCLIP is built on a novel and effective mechanism in backdoor attacks on CLIP, i.e., influencing both the image and text encoders with the trigger. It consists of a learnable trigger applied to images and a trigger-aware context generator, such that the trigger can change text features via trigger-aware prompts, resulting in a powerful and generalizable attack. Extensive experiments conducted on 11 datasets verify that the clean accuracy of BadCLIP is similar to those of advanced prompt learning methods and the attack success rate is higher than 99% in most cases. BadCLIP is also generalizable to unseen classes, and shows a strong generalization capability under cross-dataset and cross-domain settings.
Efficient Encoding of Graphics Primitives with Simplex-based Structures
Nov 26, 2023Grid-based structures are commonly used to encode explicit features for graphics primitives such as images, signed distance functions (SDF), and neural radiance fields (NeRF) due to their simple implementation. However, in $n$-dimensional space, calculating the value of a sampled point requires interpolating the values of its $2^n$ neighboring vertices. The exponential scaling with dimension leads to significant computational overheads. To address this issue, we propose a simplex-based approach for encoding graphics primitives. The number of vertices in a simplex-based structure increases linearly with dimension, making it a more efficient and generalizable alternative to grid-based representations. Using the non-axis-aligned simplicial structure property, we derive and prove a coordinate transformation, simplicial subdivision, and barycentric interpolation scheme for efficient sampling, which resembles transformation procedures in the simplex noise algorithm. Finally, we use hash tables to store multiresolution features of all interest points in the simplicial grid, which are passed into a tiny fully connected neural network to parameterize graphics primitives. We implemented a detailed simplex-based structure encoding algorithm in C++ and CUDA using the methods outlined in our approach. In the 2D image fitting task, the proposed method is capable of fitting a giga-pixel image with 9.4% less time compared to the baseline method proposed by instant-ngp, while maintaining the same quality and compression rate. In the volumetric rendering setup, we observe a maximum 41.2% speedup when the samples are dense enough.
On the Adversarial Robustness of Graph Contrastive Learning Methods
Nov 29, 2023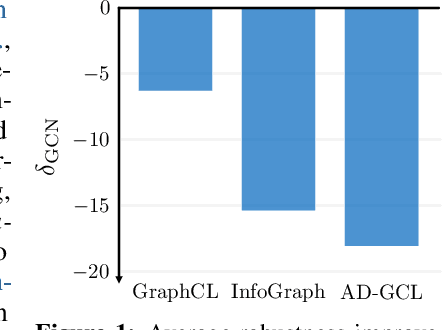
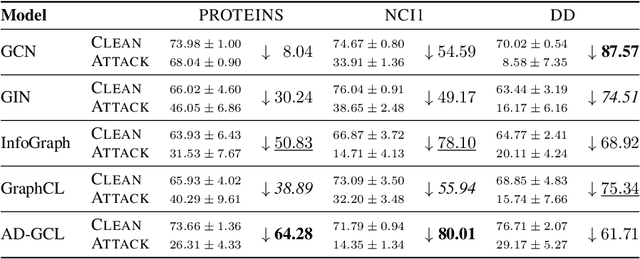
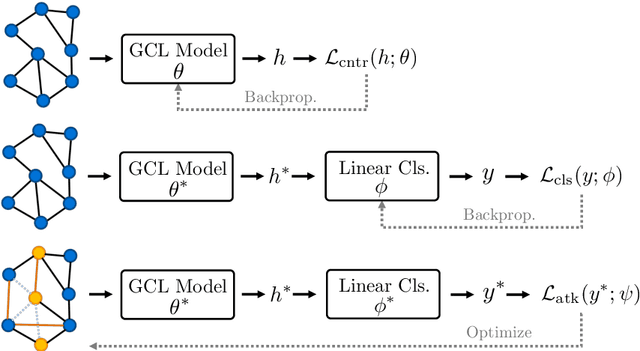
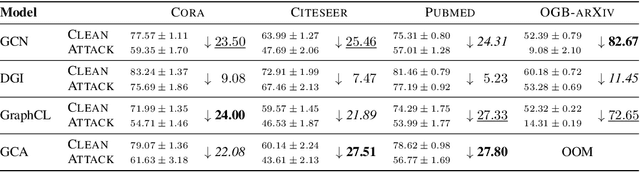
Contrastive learning (CL) has emerged as a powerful framework for learning representations of images and text in a self-supervised manner while enhancing model robustness against adversarial attacks. More recently, researchers have extended the principles of contrastive learning to graph-structured data, giving birth to the field of graph contrastive learning (GCL). However, whether GCL methods can deliver the same advantages in adversarial robustness as their counterparts in the image and text domains remains an open question. In this paper, we introduce a comprehensive robustness evaluation protocol tailored to assess the robustness of GCL models. We subject these models to adaptive adversarial attacks targeting the graph structure, specifically in the evasion scenario. We evaluate node and graph classification tasks using diverse real-world datasets and attack strategies. With our work, we aim to offer insights into the robustness of GCL methods and hope to open avenues for potential future research directions.