 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Training-free Open-world Segmentation via Image Prompting Foundation Models
Oct 17, 2023

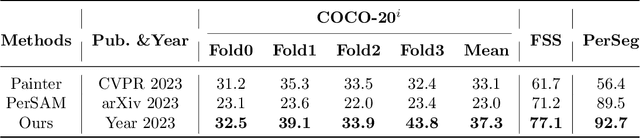
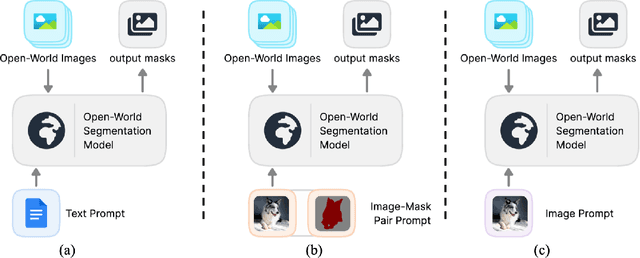
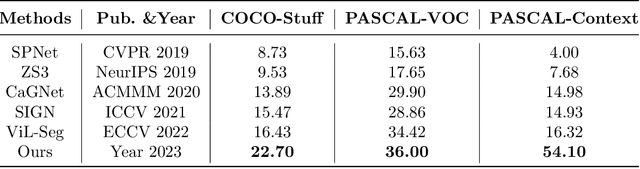
The realm of computer vision has witnessed a paradigm shift with the advent of foundational models, mirroring the transformative influence of large language models in the domain of natural language processing. This paper delves into the exploration of open-world segmentation, presenting a novel approach called Image Prompt Segmentation (IPSeg) that harnesses the power of vision foundational models. At the heart of IPSeg lies the principle of a training-free paradigm, which capitalizes on image prompting techniques. IPSeg utilizes a single image containing a subjective visual concept as a flexible prompt to query vision foundation models like DINOv2 and Stable Diffusion. Our approach extracts robust features for the prompt image and input image, then matches the input representations to the prompt representations via a novel feature interaction module to generate point prompts highlighting target objects in the input image. The generated point prompts are further utilized to guide the Segment Anything Model to segment the target object in the input image. The proposed method stands out by eliminating the need for exhaustive training sessions, thereby offering a more efficient and scalable solution. Experiments on COCO, PASCAL VOC, and other datasets demonstrate IPSeg's efficacy for flexible open-world segmentation using intuitive image prompts. This work pioneers tapping foundation models for open-world understanding through visual concepts conveyed in images.
Choroidalyzer: An open-source, end-to-end pipeline for choroidal analysis in optical coherence tomography
Dec 05, 2023Purpose: To develop Choroidalyzer, an open-source, end-to-end pipeline for segmenting the choroid region, vessels, and fovea, and deriving choroidal thickness, area, and vascular index. Methods: We used 5,600 OCT B-scans (233 subjects, 6 systemic disease cohorts, 3 device types, 2 manufacturers). To generate region and vessel ground-truths, we used state-of-the-art automatic methods following manual correction of inaccurate segmentations, with foveal positions manually annotated. We trained a U-Net deep-learning model to detect the region, vessels, and fovea to calculate choroid thickness, area, and vascular index in a fovea-centred region of interest. We analysed segmentation agreement (AUC, Dice) and choroid metrics agreement (Pearson, Spearman, mean absolute error (MAE)) in internal and external test sets. We compared Choroidalyzer to two manual graders on a small subset of external test images and examined cases of high error. Results: Choroidalyzer took 0.299 seconds per image on a standard laptop and achieved excellent region (Dice: internal 0.9789, external 0.9749), very good vessel segmentation performance (Dice: internal 0.8817, external 0.8703) and excellent fovea location prediction (MAE: internal 3.9 pixels, external 3.4 pixels). For thickness, area, and vascular index, Pearson correlations were 0.9754, 0.9815, and 0.8285 (internal) / 0.9831, 0.9779, 0.7948 (external), respectively (all p<0.0001). Choroidalyzer's agreement with graders was comparable to the inter-grader agreement across all metrics. Conclusions: Choroidalyzer is an open-source, end-to-end pipeline that accurately segments the choroid and reliably extracts thickness, area, and vascular index. Especially choroidal vessel segmentation is a difficult and subjective task, and fully-automatic methods like Choroidalyzer could provide objectivity and standardisation.
Adaptive Step Sizes for Preconditioned Stochastic Gradient Descent
Nov 28, 2023This paper proposes a novel approach to adaptive step sizes in stochastic gradient descent (SGD) by utilizing quantities that we have identified as numerically traceable -- the Lipschitz constant for gradients and a concept of the local variance in search directions. Our findings yield a nearly hyperparameter-free algorithm for stochastic optimization, which has provable convergence properties when applied to quadratic problems and exhibits truly problem adaptive behavior on classical image classification tasks. Our framework enables the potential inclusion of a preconditioner, thereby enabling the implementation of adaptive step sizes for stochastic second-order optimization methods.
EDiffSR: An Efficient Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Oct 30, 2023Recently, convolutional networks have achieved remarkable development in remote sensing image Super-Resoltuion (SR) by minimizing the regression objectives, e.g., MSE loss. However, despite achieving impressive performance, these methods often suffer from poor visual quality with over-smooth issues. Generative adversarial networks have the potential to infer intricate details, but they are easy to collapse, resulting in undesirable artifacts. To mitigate these issues, in this paper, we first introduce Diffusion Probabilistic Model (DPM) for efficient remote sensing image SR, dubbed EDiffSR. EDiffSR is easy to train and maintains the merits of DPM in generating perceptual-pleasant images. Specifically, different from previous works using heavy UNet for noise prediction, we develop an Efficient Activation Network (EANet) to achieve favorable noise prediction performance by simplified channel attention and simple gate operation, which dramatically reduces the computational budget. Moreover, to introduce more valuable prior knowledge into the proposed EDiffSR, a practical Conditional Prior Enhancement Module (CPEM) is developed to help extract an enriched condition. Unlike most DPM-based SR models that directly generate conditions by amplifying LR images, the proposed CPEM helps to retain more informative cues for accurate SR. Extensive experiments on four remote sensing datasets demonstrate that EDiffSR can restore visual-pleasant images on simulated and real-world remote sensing images, both quantitatively and qualitatively. The code of EDiffSR will be available at https://github.com/XY-boy/EDiffSR
Segmentation-Based Parametric Painting
Nov 24, 2023
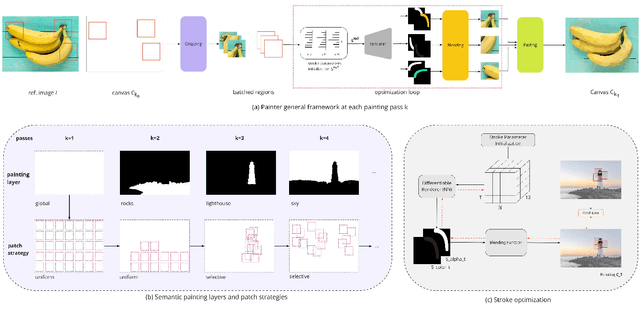
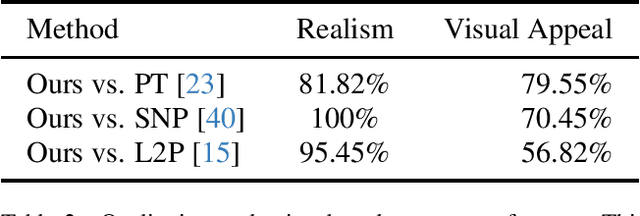

We introduce a novel image-to-painting method that facilitates the creation of large-scale, high-fidelity paintings with human-like quality and stylistic variation. To process large images and gain control over the painting process, we introduce a segmentation-based painting process and a dynamic attention map approach inspired by human painting strategies, allowing optimization of brush strokes to proceed in batches over different image regions, thereby capturing both large-scale structure and fine details, while also allowing stylistic control over detail. Our optimized batch processing and patch-based loss framework enable efficient handling of large canvases, ensuring our painted outputs are both aesthetically compelling and functionally superior as compared to previous methods, as confirmed by rigorous evaluations. Code available at: https://github.com/manuelladron/semantic\_based\_painting.git
D$^2$ST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
Dec 03, 2023Adapting large pre-trained image models to few-shot action recognition has proven to be an effective and efficient strategy for learning robust feature extractors, which is essential for few-shot learning. Typical fine-tuning based adaptation paradigm is prone to overfitting in the few-shot learning scenarios and offers little modeling flexibility for learning temporal features in video data. In this work we present the Disentangled-and-Deformable Spatio-Temporal Adapter (D$^2$ST-Adapter), a novel adapter tuning framework for few-shot action recognition, which is designed in a dual-pathway architecture to encode spatial and temporal features in a disentangled manner. Furthermore, we devise the Deformable Spatio-Temporal Attention module as the core component of D$^2$ST-Adapter, which can be tailored to model both spatial and temporal features in corresponding pathways, allowing our D$^2$ST-Adapter to encode features in a global view in 3D spatio-temporal space while maintaining a lightweight design. Extensive experiments with instantiations of our method on both pre-trained ResNet and ViT demonstrate the superiority of our method over state-of-the-art methods for few-shot action recognition. Our method is particularly well-suited to challenging scenarios where temporal dynamics are critical for action recognition.
DiFace: Cross-Modal Face Recognition through Controlled Diffusion
Dec 03, 2023Diffusion probabilistic models (DPMs) have exhibited exceptional proficiency in generating visual media of outstanding quality and realism. Nonetheless, their potential in non-generative domains, such as face recognition, has yet to be thoroughly investigated. Meanwhile, despite the extensive development of multi-modal face recognition methods, their emphasis has predominantly centered on visual modalities. In this context, face recognition through textual description presents a unique and promising solution that not only transcends the limitations from application scenarios but also expands the potential for research in the field of cross-modal face recognition. It is regrettable that this avenue remains unexplored and underutilized, a consequence from the challenges mainly associated with three aspects: 1) the intrinsic imprecision of verbal descriptions; 2) the significant gaps between texts and images; and 3) the immense hurdle posed by insufficient databases.To tackle this problem, we present DiFace, a solution that effectively achieves face recognition via text through a controllable diffusion process, by establishing its theoretical connection with probability transport. Our approach not only unleashes the potential of DPMs across a broader spectrum of tasks but also achieves, to the best of our knowledge, a significant accuracy in text-to-image face recognition for the first time, as demonstrated by our experiments on verification and identification.
Few-shot Shape Recognition by Learning Deep Shape-aware Features
Dec 03, 2023Traditional shape descriptors have been gradually replaced by convolutional neural networks due to their superior performance in feature extraction and classification. The state-of-the-art methods recognize object shapes via image reconstruction or pixel classification. However , these methods are biased toward texture information and overlook the essential shape descriptions, thus, they fail to generalize to unseen shapes. We are the first to propose a fewshot shape descriptor (FSSD) to recognize object shapes given only one or a few samples. We employ an embedding module for FSSD to extract transformation-invariant shape features. Secondly, we develop a dual attention mechanism to decompose and reconstruct the shape features via learnable shape primitives. In this way, any shape can be formed through a finite set basis, and the learned representation model is highly interpretable and extendable to unseen shapes. Thirdly, we propose a decoding module to include the supervision of shape masks and edges and align the original and reconstructed shape features, enforcing the learned features to be more shape-aware. Lastly, all the proposed modules are assembled into a few-shot shape recognition scheme. Experiments on five datasets show that our FSSD significantly improves the shape classification compared to the state-of-the-art under the few-shot setting.
Cycle-consistent Generative Adversarial Network Synthetic CT for MR-only Adaptive Radiation Therapy on MR-Linac
Dec 03, 2023Purpose: This study assesses the effectiveness of Deep Learning (DL) for creating synthetic CT (sCT) images in MR-guided adaptive radiation therapy (MRgART). Methods: A Cycle-GAN model was trained with MRI and CT scan slices from MR-LINAC treatments, generating sCT volumes. The analysis involved retrospective treatment plan data from patients with various tumors. sCT images were compared with standard CT scans using mean absolute error in Hounsfield Units (HU) and image similarity metrics (SSIM, PSNR, NCC). sCT volumes were integrated into a clinical treatment system for dosimetric re-evaluation. Results: The model, trained on 8405 frames from 57 patients and tested on 357 sCT frames from 17 patients, showed sCTs comparable to dCTs in electron density and structural similarity with MRI scans. The MAE between sCT and dCT was 49.2 +/- 13.2 HU, with sCT NCC exceeding dCT by 0.06, and SSIM and PSNR at 0.97 +/- 0.01 and 19.9 +/- 1.6 respectively. Dosimetric evaluations indicated minimal differences between sCTs and dCTs, with sCTs showing better air-bubble reconstruction. Conclusions: DL-based sCT generation on MR-Linacs is accurate for dose calculation and optimization in MRgART. This could facilitate MR-only treatment planning, enhancing simulation and adaptive planning efficiency on MR-Linacs.
Contrastive Learning-Based Spectral Knowledge Distillation for Multi-Modality and Missing Modality Scenarios in Semantic Segmentation
Dec 04, 2023Improving the performance of semantic segmentation models using multispectral information is crucial, especially for environments with low-light and adverse conditions. Multi-modal fusion techniques pursue either the learning of cross-modality features to generate a fused image or engage in knowledge distillation but address multimodal and missing modality scenarios as distinct issues, which is not an optimal approach for multi-sensor models. To address this, a novel multi-modal fusion approach called CSK-Net is proposed, which uses a contrastive learning-based spectral knowledge distillation technique along with an automatic mixed feature exchange mechanism for semantic segmentation in optical (EO) and infrared (IR) images. The distillation scheme extracts detailed textures from the optical images and distills them into the optical branch of CSK-Net. The model encoder consists of shared convolution weights with separate batch norm (BN) layers for both modalities, to capture the multi-spectral information from different modalities of the same objects. A Novel Gated Spectral Unit (GSU) and mixed feature exchange strategy are proposed to increase the correlation of modality-shared information and decrease the modality-specific information during the distillation process. Comprehensive experiments show that CSK-Net surpasses state-of-the-art models in multi-modal tasks and for missing modalities when exclusively utilizing IR data for inference across three public benchmarking datasets. For missing modality scenarios, the performance increase is achieved without additional computational costs compared to the baseline segmentation models.