 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Cyclical Route Linking Fundamental Mechanism and AI Algorithm: An Example from Poisson's Ratio in Amorphous Networks
Dec 14, 2023
"AI for science" is widely recognized as a future trend in the development of scientific research. Currently, although machine learning algorithms have played a crucial role in scientific research with numerous successful cases, relatively few instances exist where AI assists researchers in uncovering the underlying physical mechanisms behind a certain phenomenon and subsequently using that mechanism to improve machine learning algorithms' efficiency. This article uses the investigation into the relationship between extreme Poisson's ratio values and the structure of amorphous networks as a case study to illustrate how machine learning methods can assist in revealing underlying physical mechanisms. Upon recognizing that the Poisson's ratio relies on the low-frequency vibrational modes of dynamical matrix, we can then employ a convolutional neural network, trained on the dynamical matrix instead of traditional image recognition, to predict the Poisson's ratio of amorphous networks with a much higher efficiency. Through this example, we aim to showcase the role that artificial intelligence can play in revealing fundamental physical mechanisms, which subsequently improves the machine learning algorithms significantly.
Color Agnostic Cross-Spectral Disparity Estimation
Dec 14, 2023Since camera modules become more and more affordable, multispectral camera arrays have found their way from special applications to the mass market, e.g., in automotive systems, smartphones, or drones. Due to multiple modalities, the registration of different viewpoints and the required cross-spectral disparity estimation is up to the present extremely challenging. To overcome this problem, we introduce a novel spectral image synthesis in combination with a color agnostic transform. Thus, any recently published stereo matching network can be turned to a cross-spectral disparity estimator. Our novel algorithm requires only RGB stereo data to train a cross-spectral disparity estimator and a generalization from artificial training data to camera-captured images is obtained. The theoretical examination of the novel color agnostic method is completed by an extensive evaluation compared to state of the art including self-recorded multispectral data and a reference implementation. The novel color agnostic disparity estimation improves cross-spectral as well as conventional color stereo matching by reducing the average end-point error by 41% for cross-spectral and by 22% for mono-modal content, respectively.
Class-Wise Buffer Management for Incremental Object Detection: An Effective Buffer Training Strategy
Dec 14, 2023Class incremental learning aims to solve a problem that arises when continuously adding unseen class instances to an existing model This approach has been extensively studied in the context of image classification; however its applicability to object detection is not well established yet. Existing frameworks using replay methods mainly collect replay data without considering the model being trained and tend to rely on randomness or the number of labels of each sample. Also, despite the effectiveness of the replay, it was not yet optimized for the object detection task. In this paper, we introduce an effective buffer training strategy (eBTS) that creates the optimized replay buffer on object detection. Our approach incorporates guarantee minimum and hierarchical sampling to establish the buffer customized to the trained model. %These methods can facilitate effective retrieval of prior knowledge. Furthermore, we use the circular experience replay training to optimally utilize the accumulated buffer data. Experiments on the MS COCO dataset demonstrate that our eBTS achieves state-of-the-art performance compared to the existing replay schemes.
VCISR: Blind Single Image Super-Resolution with Video Compression Synthetic Data
Nov 02, 2023

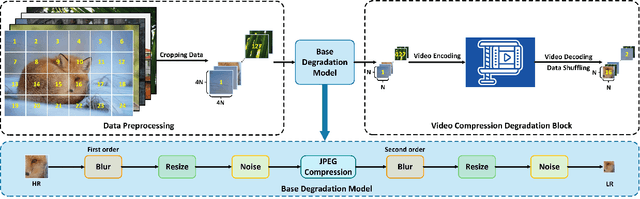

In the blind single image super-resolution (SISR) task, existing works have been successful in restoring image-level unknown degradations. However, when a single video frame becomes the input, these works usually fail to address degradations caused by video compression, such as mosquito noise, ringing, blockiness, and staircase noise. In this work, we for the first time, present a video compression-based degradation model to synthesize low-resolution image data in the blind SISR task. Our proposed image synthesizing method is widely applicable to existing image datasets, so that a single degraded image can contain distortions caused by the lossy video compression algorithms. This overcomes the leak of feature diversity in video data and thus retains the training efficiency. By introducing video coding artifacts to SISR degradation models, neural networks can super-resolve images with the ability to restore video compression degradations, and achieve better results on restoring generic distortions caused by image compression as well. Our proposed approach achieves superior performance in SOTA no-reference Image Quality Assessment, and shows better visual quality on various datasets. In addition, we evaluate the SISR neural network trained with our degradation model on video super-resolution (VSR) datasets. Compared to architectures specifically designed for the VSR purpose, our method exhibits similar or better performance, evidencing that the presented strategy on infusing video-based degradation is generalizable to address more complicated compression artifacts even without temporal cues.
CLIPSyntel: CLIP and LLM Synergy for Multimodal Question Summarization in Healthcare
Dec 16, 2023In the era of modern healthcare, swiftly generating medical question summaries is crucial for informed and timely patient care. Despite the increasing complexity and volume of medical data, existing studies have focused solely on text-based summarization, neglecting the integration of visual information. Recognizing the untapped potential of combining textual queries with visual representations of medical conditions, we introduce the Multimodal Medical Question Summarization (MMQS) Dataset. This dataset, a major contribution to our work, pairs medical queries with visual aids, facilitating a richer and more nuanced understanding of patient needs. We also propose a framework, utilizing the power of Contrastive Language Image Pretraining(CLIP) and Large Language Models(LLMs), consisting of four modules that identify medical disorders, generate relevant context, filter medical concepts, and craft visually aware summaries. Our comprehensive framework harnesses the power of CLIP, a multimodal foundation model, and various general-purpose LLMs, comprising four main modules: the medical disorder identification module, the relevant context generation module, the context filtration module for distilling relevant medical concepts and knowledge, and finally, a general-purpose LLM to generate visually aware medical question summaries. Leveraging our MMQS dataset, we showcase how visual cues from images enhance the generation of medically nuanced summaries. This multimodal approach not only enhances the decision-making process in healthcare but also fosters a more nuanced understanding of patient queries, laying the groundwork for future research in personalized and responsive medical care
Customizing 360-Degree Panoramas through Text-to-Image Diffusion Models
Nov 07, 2023Personalized text-to-image (T2I) synthesis based on diffusion models has attracted significant attention in recent research. However, existing methods primarily concentrate on customizing subjects or styles, neglecting the exploration of global geometry. In this study, we propose an approach that focuses on the customization of 360-degree panoramas, which inherently possess global geometric properties, using a T2I diffusion model. To achieve this, we curate a paired image-text dataset specifically designed for the task and subsequently employ it to fine-tune a pre-trained T2I diffusion model with LoRA. Nevertheless, the fine-tuned model alone does not ensure the continuity between the leftmost and rightmost sides of the synthesized images, a crucial characteristic of 360-degree panoramas. To address this issue, we propose a method called StitchDiffusion. Specifically, we perform pre-denoising operations twice at each time step of the denoising process on the stitch block consisting of the leftmost and rightmost image regions. Furthermore, a global cropping is adopted to synthesize seamless 360-degree panoramas. Experimental results demonstrate the effectiveness of our customized model combined with the proposed StitchDiffusion in generating high-quality 360-degree panoramic images. Moreover, our customized model exhibits exceptional generalization ability in producing scenes unseen in the fine-tuning dataset. Code is available at https://github.com/littlewhitesea/StitchDiffusion.
Investigating the Design Space of Diffusion Models for Speech Enhancement
Dec 07, 2023Diffusion models are a new class of generative models that have shown outstanding performance in image generation literature. As a consequence, studies have attempted to apply diffusion models to other tasks, such as speech enhancement. A popular approach in adapting diffusion models to speech enhancement consists in modelling a progressive transformation between the clean and noisy speech signals. However, one popular diffusion model framework previously laid in image generation literature did not account for such a transformation towards the system input, which prevents from relating the existing diffusion-based speech enhancement systems with the aforementioned diffusion model framework. To address this, we extend this framework to account for the progressive transformation between the clean and noisy speech signals. This allows us to apply recent developments from image generation literature, and to systematically investigate design aspects of diffusion models that remain largely unexplored for speech enhancement, such as the neural network preconditioning, the training loss weighting, the stochastic differential equation (SDE), or the amount of stochasticity injected in the reverse process. We show that the performance of previous diffusion-based speech enhancement systems cannot be attributed to the progressive transformation between the clean and noisy speech signals. Moreover, we show that a proper choice of preconditioning, training loss weighting, SDE and sampler allows to outperform a popular diffusion-based speech enhancement system in terms of perceptual metrics while using fewer sampling steps, thus reducing the computational cost by a factor of four.
Towards a Perceptual Evaluation Framework for Lighting Estimation
Dec 13, 2023Progress in lighting estimation is tracked by computing existing image quality assessment (IQA) metrics on images from standard datasets. While this may appear to be a reasonable approach, we demonstrate that doing so does not correlate to human preference when the estimated lighting is used to relight a virtual scene into a real photograph. To study this, we design a controlled psychophysical experiment where human observers must choose their preference amongst rendered scenes lit using a set of lighting estimation algorithms selected from the recent literature, and use it to analyse how these algorithms perform according to human perception. Then, we demonstrate that none of the most popular IQA metrics from the literature, taken individually, correctly represent human perception. Finally, we show that by learning a combination of existing IQA metrics, we can more accurately represent human preference. This provides a new perceptual framework to help evaluate future lighting estimation algorithms.
PerMod: Perceptually Grounded Voice Modification with Latent Diffusion Models
Dec 13, 2023Perceptual modification of voice is an elusive goal. While non-experts can modify an image or sentence perceptually with available tools, it is not clear how to similarly modify speech along perceptual axes. Voice conversion does make it possible to convert one voice to another, but these modifications are handled by black box models, and the specifics of what perceptual qualities to modify and how to modify them are unclear. Towards allowing greater perceptual control over voice, we introduce PerMod, a conditional latent diffusion model that takes in an input voice and a perceptual qualities vector, and produces a voice with the matching perceptual qualities. Unlike prior work, PerMod generates a new voice corresponding to specific perceptual modifications. Evaluating perceptual quality vectors with RMSE from both human and predicted labels, we demonstrate that PerMod produces voices with the desired perceptual qualities for typical voices, but performs poorly on atypical voices.
$ρ$-Diffusion: A diffusion-based density estimation framework for computational physics
Dec 13, 2023In physics, density $\rho(\cdot)$ is a fundamentally important scalar function to model, since it describes a scalar field or a probability density function that governs a physical process. Modeling $\rho(\cdot)$ typically scales poorly with parameter space, however, and quickly becomes prohibitively difficult and computationally expensive. One promising avenue to bypass this is to leverage the capabilities of denoising diffusion models often used in high-fidelity image generation to parameterize $\rho(\cdot)$ from existing scientific data, from which new samples can be trivially sampled from. In this paper, we propose $\rho$-Diffusion, an implementation of denoising diffusion probabilistic models for multidimensional density estimation in physics, which is currently in active development and, from our results, performs well on physically motivated 2D and 3D density functions. Moreover, we propose a novel hashing technique that allows $\rho$-Diffusion to be conditioned by arbitrary amounts of physical parameters of interest.