 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Damage GAN: A Generative Model for Imbalanced Data
Dec 08, 2023
This study delves into the application of Generative Adversarial Networks (GANs) within the context of imbalanced datasets. Our primary aim is to enhance the performance and stability of GANs in such datasets. In pursuit of this objective, we introduce a novel network architecture known as Damage GAN, building upon the ContraD GAN framework which seamlessly integrates GANs and contrastive learning. Through the utilization of contrastive learning, the discriminator is trained to develop an unsupervised representation capable of distinguishing all provided samples. Our approach draws inspiration from the straightforward framework for contrastive learning of visual representations (SimCLR), leading to the formulation of a distinctive loss function. We also explore the implementation of self-damaging contrastive learning (SDCLR) to further enhance the optimization of the ContraD GAN model. Comparative evaluations against baseline models including the deep convolutional GAN (DCGAN) and ContraD GAN demonstrate the evident superiority of our proposed model, Damage GAN, in terms of generated image distribution, model stability, and image quality when applied to imbalanced datasets.
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
Dec 08, 2023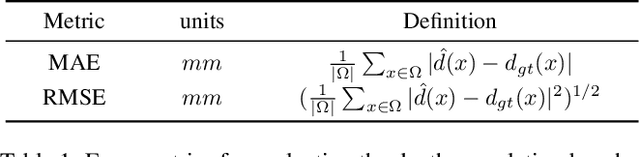

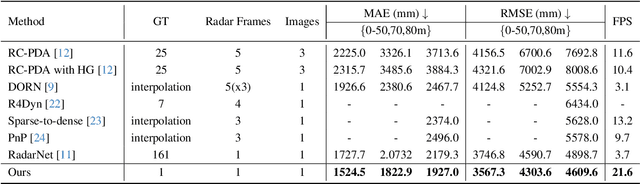
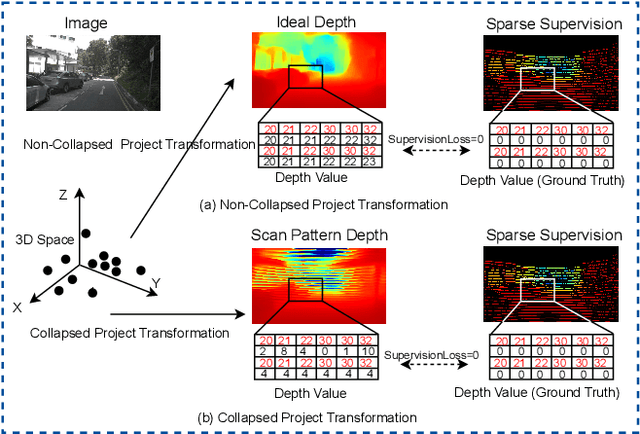
It is widely believed that the dense supervision is better than the sparse supervision in the field of depth completion, but the underlying reasons for this are rarely discussed. In this paper, we find that the challenge of using sparse supervision for training Radar-Camera depth prediction models is the Projection Transformation Collapse (PTC). The PTC implies that sparse supervision leads the model to learn unexpected collapsed projection transformations between Image/Radar/LiDAR spaces. Building on this insight, we propose a novel ``Disruption-Compensation" framework to handle the PTC, thereby relighting the use of sparse supervision in depth completion tasks. The disruption part deliberately discards position correspondences among Image/Radar/LiDAR, while the compensation part leverages 3D spatial and 2D semantic information to compensate for the discarded beneficial position correspondence. Extensive experimental results demonstrate that our framework (sparse supervision) outperforms the state-of-the-art (dense supervision) with 11.6$\%$ improvement in mean absolute error and $1.6 \times$ speedup. The code is available at ...
One-step Diffusion with Distribution Matching Distillation
Dec 05, 2023Diffusion models generate high-quality images but require dozens of forward passes. We introduce Distribution Matching Distillation (DMD), a procedure to transform a diffusion model into a one-step image generator with minimal impact on image quality. We enforce the one-step image generator match the diffusion model at distribution level, by minimizing an approximate KL divergence whose gradient can be expressed as the difference between 2 score functions, one of the target distribution and the other of the synthetic distribution being produced by our one-step generator. The score functions are parameterized as two diffusion models trained separately on each distribution. Combined with a simple regression loss matching the large-scale structure of the multi-step diffusion outputs, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model generates images at 20 FPS on modern hardware.
Deep learning based Image Compression for Microscopy Images: An Empirical Study
Nov 02, 2023With the fast development of modern microscopes and bioimaging techniques, an unprecedentedly large amount of imaging data are being generated, stored, analyzed, and even shared through networks. The size of the data poses great challenges for current data infrastructure. One common way to reduce the data size is by image compression. This present study analyzes classic and deep learning based image compression methods, and their impact on deep learning based image processing models. Deep learning based label-free prediction models (i.e., predicting fluorescent images from bright field images) are used as an example application for comparison and analysis. Effective image compression methods could help reduce the data size significantly without losing necessary information, and therefore reduce the burden on data management infrastructure and permit fast transmission through the network for data sharing or cloud computing. To compress images in such a wanted way, multiple classical lossy image compression techniques are compared to several AI-based compression models provided by and trained with the CompressAI toolbox using python. These different compression techniques are compared in compression ratio, multiple image similarity measures and, most importantly, the prediction accuracy from label-free models on compressed images. We found that AI-based compression techniques largely outperform the classic ones and will minimally affect the downstream label-free task in 2D cases. In the end, we hope the present study could shed light on the potential of deep learning based image compression and the impact of image compression on downstream deep learning based image analysis models.
BIRB: A Generalization Benchmark for Information Retrieval in Bioacoustics
Dec 13, 2023The ability for a machine learning model to cope with differences in training and deployment conditions--e.g. in the presence of distribution shift or the generalization to new classes altogether--is crucial for real-world use cases. However, most empirical work in this area has focused on the image domain with artificial benchmarks constructed to measure individual aspects of generalization. We present BIRB, a complex benchmark centered on the retrieval of bird vocalizations from passively-recorded datasets given focal recordings from a large citizen science corpus available for training. We propose a baseline system for this collection of tasks using representation learning and a nearest-centroid search. Our thorough empirical evaluation and analysis surfaces open research directions, suggesting that BIRB fills the need for a more realistic and complex benchmark to drive progress on robustness to distribution shifts and generalization of ML models.
InstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models
Dec 04, 2023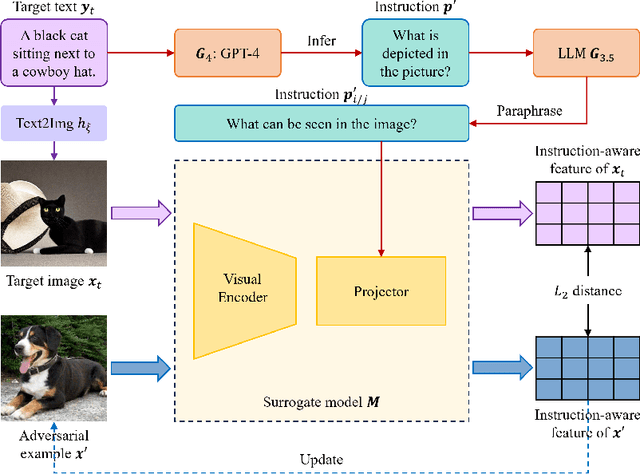
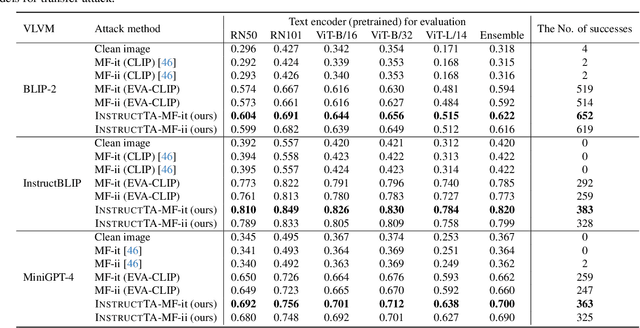
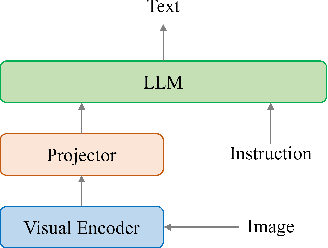
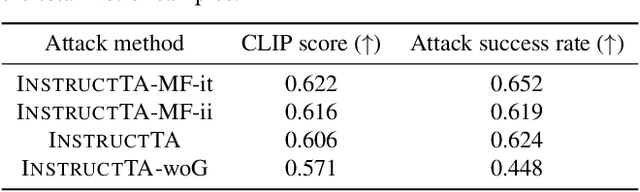
Large vision-language models (LVLMs) have demonstrated their incredible capability in image understanding and response generation. However, this rich visual interaction also makes LVLMs vulnerable to adversarial examples. In this paper, we formulate a novel and practical gray-box attack scenario that the adversary can only access the visual encoder of the victim LVLM, without the knowledge of its prompts (which are often proprietary for service providers and not publicly available) and its underlying large language model (LLM). This practical setting poses challenges to the cross-prompt and cross-model transferability of targeted adversarial attack, which aims to confuse the LVLM to output a response that is semantically similar to the attacker's chosen target text. To this end, we propose an instruction-tuned targeted attack (dubbed InstructTA) to deliver the targeted adversarial attack on LVLMs with high transferability. Initially, we utilize a public text-to-image generative model to "reverse" the target response into a target image, and employ GPT-4 to infer a reasonable instruction $\boldsymbol{p}^\prime$ from the target response. We then form a local surrogate model (sharing the same visual encoder with the victim LVLM) to extract instruction-aware features of an adversarial image example and the target image, and minimize the distance between these two features to optimize the adversarial example. To further improve the transferability, we augment the instruction $\boldsymbol{p}^\prime$ with instructions paraphrased from an LLM. Extensive experiments demonstrate the superiority of our proposed method in targeted attack performance and transferability.
LiLO: Lightweight and low-bias LiDAR Odometry method based on spherical range image filtering
Nov 13, 2023In unstructured outdoor environments, robotics requires accurate and efficient odometry with low computational time. Existing low-bias LiDAR odometry methods are often computationally expensive. To address this problem, we present a lightweight LiDAR odometry method that converts unorganized point cloud data into a spherical range image (SRI) and filters out surface, edge, and ground features in the image plane. This substantially reduces computation time and the required features for odometry estimation in LOAM-based algorithms. Our odometry estimation method does not rely on global maps or loop closure algorithms, which further reduces computational costs. Experimental results generate a translation and rotation error of 0.86\% and 0.0036{\deg}/m on the KITTI dataset with an average runtime of 78ms. In addition, we tested the method with our data, obtaining an average closed-loop error of 0.8m and a runtime of 27ms over eight loops covering 3.5Km.
HuRef: HUman-REadable Fingerprint for Large Language Models
Dec 08, 2023Protecting the copyright of large language models (LLMs) has become crucial due to their resource-intensive training and accompanying carefully designed licenses. However, identifying the original base model of an LLM is challenging due to potential parameter alterations through fine-tuning or continued pretraining. In this study, we introduce HuRef, a human-readable fingerprint for LLMs that uniquely identifies the base model without exposing model parameters or interfering with training. We first observe that the vector direction of LLM parameters remains stable after the model has converged during pretraining, showing negligible perturbations through subsequent training steps, including continued pretraining, supervised fine-tuning (SFT), and RLHF, which makes it a sufficient condition to identify the base model. The necessity is validated by continuing to train an LLM with an extra term to drive away the model parameters' direction and the model becomes damaged. However, this direction is vulnerable to simple attacks like dimension permutation or matrix rotation, which significantly change it without affecting performance. To address this, leveraging the Transformer structure, we systematically analyze potential attacks and define three invariant terms that identify an LLM's base model. We make these invariant terms human-readable by mapping them to a Gaussian vector using a convolutional encoder and then converting it into a natural image with StyleGAN2. Our method generates a dog image as an identity fingerprint for an LLM, where the dog's appearance strongly indicates the LLM's base model. Experimental results across various LLMs demonstrate the effectiveness of our method, the generated dog image remains invariant to different training steps, including SFT, RLHF, or even continued pretraining with augmented vocabulary in a new language.
Partition-based K-space Synthesis for Multi-contrast Parallel Imaging
Dec 01, 2023Multi-contrast magnetic resonance imaging is a significant and essential medical imaging technique.However, multi-contrast imaging has longer acquisition time and is easy to cause motion artifacts. In particular, the acquisition time for a T2-weighted image is prolonged due to its longer repetition time (TR). On the contrary, T1-weighted image has a shorter TR. Therefore,utilizing complementary information across T1 and T2-weighted image is a way to decrease the overall imaging time. Previous T1-assisted T2 reconstruction methods have mostly focused on image domain using whole-based image fusion approaches. The image domain reconstruction method has the defects of high computational complexity and limited flexibility. To address this issue, we propose a novel multi-contrast imaging method called partition-based k-space synthesis (PKS) which can achieve super reconstruction quality of T2-weighted image by feature fusion. Concretely, we first decompose fully-sampled T1 k-space data and under-sampled T2 k-space data into two sub-data, separately. Then two new objects are constructed by combining the two sub-T1/T2 data. After that, the two new objects as the whole data to realize the reconstruction of T2-weighted image. Finally, the objective T2 is synthesized by extracting the sub-T2 data of each part. Experimental results showed that our combined technique can achieve comparable or better results than using traditional k-space parallel imaging(SAKE) that processes each contrast independently.
MixerFlow for Image Modelling
Oct 25, 2023Normalising flows are statistical models that transform a complex density into a simpler density through the use of bijective transformations enabling both density estimation and data generation from a single model. In the context of image modelling, the predominant choice has been the Glow-based architecture, whereas alternative architectures remain largely unexplored in the research community. In this work, we propose a novel architecture called MixerFlow, based on the MLP-Mixer architecture, further unifying the generative and discriminative modelling architectures. MixerFlow offers an effective mechanism for weight sharing for flow-based models. Our results demonstrate better density estimation on image datasets under a fixed computational budget and scales well as the image resolution increases, making MixeFlow a powerful yet simple alternative to the Glow-based architectures. We also show that MixerFlow provides more informative embeddings than Glow-based architectures.